-
大数据项目 --- 电商数仓(一)
这个项目实在数据采集基础使用的,需要提前复习之前学的东西,否则的话就是很难继续学习.详见博客数据项目一 ---数据采集项目.大数据项目 --- 数据采集项目_YllasdW的博客-CSDN博客大数据第一个项目笔记整理
https://blog.csdn.net/m0_47489229/article/details/127477626
目录
二.配置spark的环境变量$ sudo vim /etc/profile.d/my_env.sh
三.新建spark配置文件,因为我们这里使用的是hive on spark$ vim /opt/module/hive/conf/spark-defaults.conf
五.修改hive-site.xml文件 --- 真正的将hive和spark进行关联
二十二.DWD层_get_json_object --- 工薪阶层
四十九.DWD_业务_系统函数(concat、concat_ws、collect_set、STR_TO_MAP)
七十二.多表join出现的问题_使用COALESCE函数解决
一. 采集项目架构
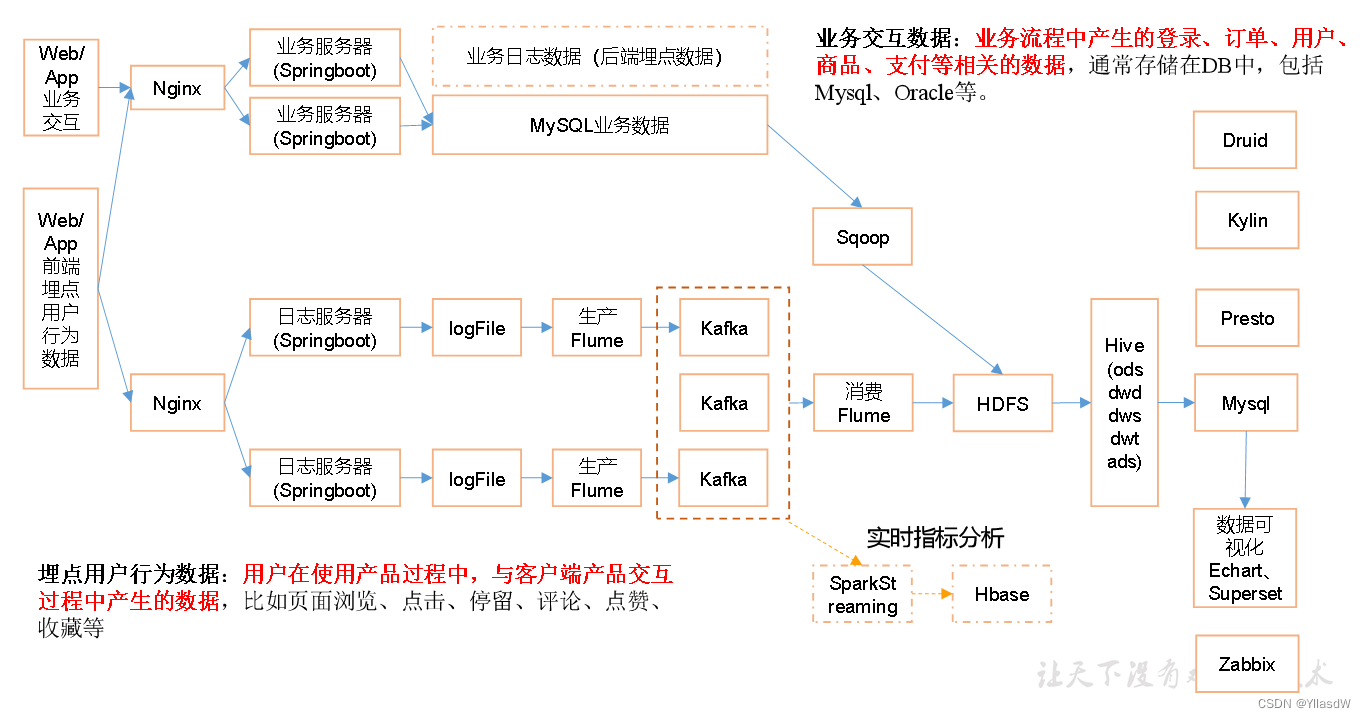
我们使用的体系是Hadoop体系,是属于这个生态的.
为什么要使用数据仓库,因为后面使用机器学习的来源是使用数据仓库的,以及后面学习的用户画像.传统的公司收集的数据都是来自于业务数据,但是大数据体系还是要收集来自于用户产生的实时,解决问题需要考虑业务思维.
如何采集用户数据 --- 埋点方法(行为会被记录下来),将其使用日志服务器Springboot进行采集,得到logFile,再通过Flume进行采集.Flume采集logFile文件的时候,它的源于源之间是不同的,Flume可以保证数据的原子性和一致性,翻译成人话就是可以保证数据不丢失.
面试的一些问题,架构设计原因(防止压价,要钱):
①Exec Source在生产环境是不会使用这个的,因为这个Source是不能够保证put完全成功的,一旦要是失败会出现丢失数据的情况,为了更强的保证性,可以使用Taildir Source.Flume事务的代码是根据相应的channal决定的,生产环境一般是不使用Exec Source,也就是相应的logFile使用的是Taildir Source.
Exec Source的父类是Event Driven,但是Taildir Source的父类是Puable Source,后者的可靠性是比原来的可靠性高的,因此,这里的用户数据是使用的Taildir Source.
②这里加入Kafka的原因是因为HDFS的吞吐量是不如Kafka高.因此这里放入Kafka的方法是可以直接使用SparkStreaming将相应的数据进行实时指标分析;另一个原因还Kafka是可以一对多,在这个领域是比较出色的,方便多个源使用同一个数据.
③Kafka是个消息队列,是用来存储数据.Flume是主要的采集部分.如果要是没有Flume,也是可以读进Kafka,那为什么还要使用Flume?Flume做的最多的是Source和Sink,用户数据采集的地方,第一个Flume和第二个Flume是可以不用的.那为什么要使用呢?为啥不用现成的的Flume,要自己重复造个轮子呢,是完全没有必要的.二. 用户采集平台
继续深挖刚才的细节:
①第一个(上游)Flume使用的Taildir Source - Kafka Channal,第二个(下游)Flume使用的是相应的Kafka Source - File Channal - HDFS Sink.第一个Flume也可以使用Taildir Sourc - File Channal - Kafka Sink,但是为什么我们没有使用这个架构,因为中间多了一层,不如是直接将上面的那一层进行省略掉.(复杂度上升,并且会变得复杂,吃资源,尤其是Channal这个部分).
那为啥下游不使用Kafka Source - HDFS Channal,因为拦截器的使用.上游是ETL拦截器,为了过滤不合格的json格式的文件.下游是使用的timeStamp拦截器,这个作用是为了解决相应的零点漂移(人话:防止昨天的数据,出现在今天采集的数据之中).这里的是时间戳timeStamp拦截器可以是放在上游的,但是不太好,如果要是在上游的时候使用了,就会产生相应的带有Header部分,导致在写入Kafka的时候,处理的数据是EVENT格式的文件,并不是JSON格式(恍然大悟).
②上面的问题解决方式,使用Kafka时间戳拦截器,会在执行的过程中产生大量的冗余.
③下游的Flume为什么搞一个File Channal?回答:我们想过很多的方案,这里的拦截器是不能够写在上游的Flume之中.使用Kafka Channal会导致大量的对象的生成,会出现大量的垃圾回收,这里的性能是不能采用这个方式进行相应的采集的,因此没有使用Kafka Channal.使用File Channal的性能还是过的去的,就是这样回答.三. 业务采集架构

问题这里为什么使用Sqoop?
Sqoop是使用的阿里云啥的,基本是一天一采集,直接放到相应的HDFS之中.为什么要使用Sqoop为什么要用它,因为它虽然不是最先进的,但是使用了那么长的时间,它的性能是完全够用的.现在也在考虑将这个地方进行升级,但是没有充足的测试.四. 后台商品管理表格

这里的C位表一定是相应的订单表 用户表 商品表. 商品表这个东西分为SPU和SKU,这里的SPU指一个完整的整体,以SKU为单位,以IPHONE14为例子.

5. 电商业务表格
这里的电商数据业务表格的说明,是需要将之前学习过的东西,也就是所谓的sql之中的东西放入到IDEA之中进行查看。对于项目一之中的东西进行复习。
就是实际之中的表并不是那么少的,会很多的。
6.采集项目压缩编码修改
原来的Flume我们是使用的lzo进行的压缩,这里需要改成相应的gzip进行压缩。
1)这里我之前设置的路径是$ /opt/module/flume-1.9.0/jobs/gmall
$ vim kafka-flume-hdfs.conf --- 将里面的配置进行修改,如下所示: lzop-gzip
2)将sqoop之中的东西采用gzip进行压缩

在根目录下的bin目录之中的mysql_to_hdfs_init.sh 脚本进行修改,将lzop ------org.apache.hadoop.io.compress.GzipCodec

将上图之中的这句话给删除。在mysql_to_hdfs.sh脚本之中进行与上述操作相同的操作。
为什么要用lzop而不用snap?学一下依赖的使用,并且lzop会产生相应的切片。flume采集过程使用lzop没有问题,snap使用flume。sqoop使用lzop文件不会大的离谱。snap不会产生相应的切片。
七.数仓简介

数仓分层如下所示:

ODS层:原始数据层,直接加载原始的数据、日志,数据保持原貌,不作处理。
DWD层:对ODS层的数据进行相应的清洗(去除空值、脏数据等),保存业务事实明细。一行的数据代表一次业务行为,例如一次下单。
DIM层:维度层,保存维度数据,主要是对业务事实的描述信息,例如何人、何时、何地等。我早上在宿舍11点醒的,12点半吃的饭。
DWS层:对于DWD层做一个汇总。一行信息代表一个主题对象一天的汇总行为,例如:一个用户一天的下单次数。
DWT层:对于DWS层的一个汇总。一行的信息代表一个主题对象的累积行为,例如一个用户从注册那一天开始到现在一共下了多少单。
ADS层:为各种统计报表提供的数据。数据仓库为什么要进行分层?
①复杂的问题简单化
②减少重复数据的开发
③隔离原始数据基本的概念(先是把相应的概念进行炒作,接下来就是进行赚钱)
数据海 数据仓库 数据集[这里的几个概念就是数据大小的区别,总而言之都是数据]表名命名规范
- ODS层命名为ods_表名
- DIM层命名为dim_表名
- DWD层命名为dwd_表名
- DWS层命名为dws_表名
- DWT层命名为dwt_表名
- ADS层命名为ads_表名
- 临时表命名为tmp_表名
表字段类型命名规范
- 数量类型为bigint
- 金额类型为decimal(16, 2),表示:16位有效数字,其中小数部分2位(double不够精确的)
- 字符串(名字,描述信息等)类型为string
- 主键外键类型为string
- 时间戳类型为bigint
八.范式
数据建模必须遵循一定的规则,在关系数建模中,这种规则就是范式。优点:可以减少数据的冗余性。缺点:获取数据时,需要通过Join拼接出最后的数据。分类:范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
建模的含义就是创建一个数学模型或者理论模型用来模拟现实生活之中的一些数据。
函数依赖:概念麻烦,用人话表示。

上面的分数是需要使用学号和课名表示才能够得知,这叫做完全函数依赖。
由学号和课名可以推导出一个人的姓名,但是只是知道学号也是可以知道姓名,这就是所谓的部分函数依赖。
学号-系名-系主任------传递函数依赖第一范式
原则:属性不可分割

上述的表格并不是符合第一范式的,商品之中的数据并不是原子数据项,是可以进行分割的。将上述的表变成是符合第一范式的类型是如下所示:

实际上,1NF是所有关系型数据库的最基本的要求,如果一个表设计不是符合第一范式的,那么一定是有问题的。
第二范式
原则:不存在“部分函数依赖”

上面的表格是明显存在部分依赖的,分数是依赖于学号和课名,但是姓名并不是依赖于学号和课名的。因此,将上述的表进行拆开,分成两个表进行分析。


上述的两个表示没有部分依赖的,因此就是将上述的表格二范式化了。将一张大表分成了两个小表。
第三范式
原则:不能存在传递函数依赖

上面的表示学号 -> 系名 -> 系主任,将上述的表格进行相应的拆分。

进而符合第三范式过程。
小小总结:范式越高,数据越是清晰一些,一致性越是好一些 ------- 容易差错。时间代价降低,空间代价会上升。【空间换取时间】
九.维度建模和关系建模
为了降低查询时所消耗的时间代价,减少使用join,一般是范式一应用于数据仓库之中。
关系建模和维度建模是两种数据仓库的建模技术。关系建模由Bill Inmon所倡导,维度建模由Ralph Kimball所倡导。
关系建模
关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。

关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
数据仓库一般是不使用这种范式建模的,因为这里的东西太碎了,代价太高了。(要写很多的join)维度建模

上图之中所有的信息是围绕中间的事实进行联系,进而得到相应的维度建模。
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。在大数据之中应用是比较多的。
数据仓库的第一步是进行数据规划,确定数据仓库需要哪些表格。维度建模,用来提高查询效率,发生在DWD和DIM层之中。
维度表和事实表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。维度一定是一个抽象的东西,例如:用户、商品、日期、地区等。煎饼果子就不是维度表。
维表的特征:①维表的范围很宽(具有多个属性、列比较多)②跟事实表相比,行数相对较小:通常< 10万条 ③内容相对固定:编码表
时间维度表:
日期ID
day of week
day of year
季度
节假日
2022-11-07
2
1
1
元旦
2022-11-08
3
2
1
无
2022-11-09
4
3
1
无
2022-11-10
5
4
1
无
2022-11-11
6
5
1
无
事实表:事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等)。也就是将上面的维度变成id,其余的信息变成度量值。例如:2022年11月7日,姚毅伟同学(哈哈哈)在遵义的某团偷偷花了250块钱买了八瓶六味地黄丸。维度表:时间、用户、商品、商家。事实表:250块钱、八瓶。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键,通常具有两个和两个以上的外键。
事实表的特征:①非常的大 ②内容相对的窄:列数较少(主要是外键id和度量值)③经常发生变化,每天会新增加很多。
分类:
1)事务型事实表
以每个事务或事件为单位,事件一旦被提交不能更改,只能增加。2)周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。3)累积型快照事实表
累计快照事实表用于跟踪业务事实的变化。例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。十.维度建模分类
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
1.星型模型

2.雪花模型

雪花模型更加靠近于范式三类型,相对而言,星型模型是更加接近于范式一类型的。一般我们是使用星型模型进行数据分析。
3.星座模型

星座表与前面的两个情况的区别是事实表的数量,星座模型是基于多个事实表。
十一.数仓建模全过程(绝对重点)
一.ODS层 --- 用户存放的数据
1)HDFS 用户行为数据
2)HDFS 业务数据针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
(1)保持数据原貌不做任何修改,起到备份数据的作用。
(2)数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右。一般我们这部分数据访问的频率是非常低的)
(3)创建分区表,防止后续的全表扫描二.DIM层和DWD层
DIM层DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程:在业务系统中,挑选我们感兴趣的业务线。
(2)声明粒度:数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。粒度粗,数据量小,统计信息就是不会那么细的。粒度细,数据量大,统计的信息就是会非常的多。
(3)确认维度:维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
(4)确定事实:此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
上面的过程就是比较绕的,过程但是容易理解的。
事实表\维度
时间
用户
地区
商品
优惠券
活动
度量值
订单
√
√
√
运费/优惠金额/原始金额/最终金额
订单详情
√
√
√
√
√
√
件数/优惠金额/原始金额/最终金额
支付
√
√
√
支付金额
加购
√
√
√
件数/金额
收藏
√
√
√
次数
评价
√
√
√
次数
退单
√
√
√
√
件数/金额
退款
√
√
√
√
件数/金额
优惠券领用
√
√
√
次数
由上面的表可以得知,事实表存在,不一定有相应的维度对应。优惠券和活动关联到的事实表是比较少的。
数据仓库的维度建模已经完毕,DWD层是以业务过程为驱动。
DWS层、DWT层和ADS层都是以需求为驱动,和维度建模已经没有关系了。
DWS和DWT都是建宽表,按照主题去建表。主题相当于观察问题的角度。对应着维度表。三.DWS层与DWT层

对于上面的维度可以进行两个两个组合啥的,进而得到最终的结果。
DWS层和DWT层统称宽表层,这两层的设计思想大致相同,通过以下案例进行阐述。
1)问题引出:两个需求,统计每个省份订单的个数、统计每个省份订单的总金额
2)处理办法:都是将省份表和订单表进行join,group by省份,然后计算。同样数据被计算了两次,实际上类似的场景还会更多。那怎么设计能避免重复计算呢?
针对上述场景,可以设计一张地区宽表,其主键为地区ID,字段包含为:下单次数、下单金额、支付次数、支付金额等。上述所有指标都统一进行计算,并将结果保存在该宽表中,这样就能有效避免数据的重复计算。
DWS层是每天,DWT是迄今为止。
十二.Hive搭建
一.架构说明
Hive引擎包括:默认MR(每执行一次map reduce就是要落一次盘)、tez(有向图进行计算,理解为弱化版的spark)、spark(可以是map map ,然后再进行reduce)
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。本质是hive,但是执行的引擎是spark,速度是比较快的。(原来是MR)------ 这里我们使用的是
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法。
二.hive配置
懵了(看的课程没有对应上,重新查找课程)
面试问题:你在开发的时候有没有遇到版本兼容问题?经常会问
后面是如何配置会说十三.HiveOnSpark搭建
一.上传包
$ cd /opt/software --- 上传自己的两个jar包
$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
$ mv spark-3.0.0-bin-hadoop3.2/ spark二.配置spark的环境变量
$ sudo vim /etc/profile.d/my_env.sh- # SPARK_HOME
- export SPARK_HOME=/opt/module/spark
- export PATH=$PATH:$SPARK_HOME/bin
$ source /etc/profile.d/my_env.sh
三.新建spark配置文件,因为我们这里使用的是hive on spark
$ vim /opt/module/hive/conf/spark-defaults.conf- spark.master yarn
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://hadoop102:8020/spark-history
- spark.executor.memory 1g
- spark.driver.memory 1g
创建一个存放日志的东西:$ hadoop fs -mkdir /spark-history
四.向HDFS上传Spark纯净版jar包
说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
(1)上传并解压spark-3.0.0-bin-without-hadoop.tgz
[atguigu@hadoop102 software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
(2)上传Spark纯净版jar包到HDFS
[atguigu@hadoop102 software]$ hadoop fs -mkdir /spark-jars
[atguigu@hadoop102 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
讲上述的所有的解压之后的东西进行上传.
五.修改hive-site.xml文件 --- 真正的将hive和spark进行关联
[atguigu@hadoop102 software]$ vim /opt/module/hive/conf/hive-site.xml
- <!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
- <property>
- <name>spark.yarn.jars</name>
- <value>hdfs://hadoop102:8020/spark-jars/*</value>
- </property>
- <!--Hive执行引擎-->
- <property>
- <name>hive.execution.engine</name>
- <value>spark</value>
- </property>
- <!--Hive和Spark连接超时时间,电脑比较好就不用改-->
- <property>
- <name>hive.spark.client.connect.timeout</name>
- <value>10000ms</value>
- </property>
注意:hive.spark.client.connect.timeout的默认值是1000ms,如果执行hive的insert语句时,抛如下异常,可以调大该参数到10000ms
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session d9e0224c-3d14-4bf4-95bc-ee3ec56df48e六.Hive on Spark测试
(1)启动hive客户端
[atguigu@hadoop102 hive]$ bin/hive
(2)创建一张测试表
hive (default)> create table student(id int, name string);
(3)通过insert测试效果
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功

我的电脑耗费的时间很多. 但是运行成功了. 家境贫寒,换不起电脑.

为什么这个地方还是卡着的?
再次执行一个任务
[atguigu@hadoop102 software]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1
关闭第一个任务,可以观察到如下的现象.

 上面现象说明还开启spark,开启MR,MR就会进入等待的状态,但是当将spark进行关闭的时候,MR就是可以开始正常运行.------说明这里的并发度是不可以的
上面现象说明还开启spark,开启MR,MR就会进入等待的状态,但是当将spark进行关闭的时候,MR就是可以开始正常运行.------说明这里的并发度是不可以的
解决方式:1.增加ApplicationMaster资源比例容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配10%的资源给Application Master,则可能出现,同一时刻只能运行一个Job的情况,因为一个Application Master使用的资源就可能已经达到10%的上限了。故此处可将该值适当调大。
1)修改配置
$ vim /opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml
2)对于上面的数值可以进行更改.对于上面配置进行分发
[atguigu@hadoop102 hadoop]$ rsync.sh capacity-scheduler.xml3)关闭正在运行的任务,重新启动yarn集

可以观察到这样的情况是正常的.MR是能够执行完成的,但是hive是没有关掉,当关掉的时候才能够执行完成.
2.创建多个队列,比如增加一个hive队列
十四.创建多队列的好处
增加Yarn容量调度器队列,也可以增加容量调度器的并发度.
按照计算引擎创建队列:hive spark flink
按照业务创建队列:下单 支付 点赞 评论 收藏(用户 活动等)
不创建多个队列时候,就是在一个default之中执行.有什么好处?
(1)假如公司来了一个菜鸟,写了一个死循环,公司资源耗尽,大数据全部瘫痪.---解耦
(2)假如双11数据量是非常大的,任务是非常的多,如果所有的任务都参与执行,一定是执行不完的,怎么办?将任务分为几个优先级,---支持降级运行 下单(必须完成) - 支付(必须完成) - 点赞(不完成也是可以的) - 评论 - 收藏十五.创建hive队列
还是进入到刚才修改的配置文件之中添加hive选项

将文件之中的值修改为50

同时要给队列增加如下新的一些属性:
这里的配置过程和文件之中default的默认配置是相同的,就是需要进行理解与消化.最大容量的含义就是当default是不够的时候,需要使用hive进行.

将上述的文件进行改正与保存之后,进行同步的分发,重启yarn.有钱就是换64G2T的电脑,努力吧.(吐槽一下)
重新开启hive,进行插入方式.
开启成功.再次进行执行如下的代码:
[atguigu@hadoop102 hadoop]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1
卡死,原因?
由调度起可以知道,没有给到hive的机会,因此,这里我们是要进行指定hive进行工作的.
[atguigu@hadoop102 hadoop]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -Dmapreduce.job.queuename=hive 1 1 可以见到这里的hive就是非常正常的了.
可以见到这里的hive就是非常正常的了.十六.datagrip工具安装
真无语,找了半天找不到破解文件,咋那莫多的钓鱼网站,浪费了好长时间.国内学术为啥那么不真诚........
首先进入网站:其他版本 - DataGrip
安装破解:
链接:https://pan.baidu.com/s/1Z86cQkbN8Aref8hvsmG-GQ?pwd=1111
提取码:1111 ---具体方法看里面的txt文件,比较好操作。打开已经安装好的软件,将其进行连接hive。


上述之中在进行Test之前是需要进行连接hiveserver2的。
$ hiveserver2
至少出现四条数据的时候,进行数据库的连接.
 上面是进行数据库连接成功的画面.
上面是进行数据库连接成功的画面.
十七.ODS层用户行为日志(建表+加载数据)

要求:保持原有的数据,分区不发生改变,lzo压缩.
创建表
1.如果要创建的表已经存在,是要删除掉这个表;
drop table if exists ods_log;
2.创建外部表
什么时候创建外部表? 在数据仓库之中,绝大多数都是外部表,只有自己临时使用的表示内部表.
删除数据:元数据 原始数据, 内部表删除数据: 元数据 原始数据, 外部表删除数据:元数据
CREATE EXTERNAL TABLE ods_log(line string)
3.按照表的日期进行分区
PARTITIONED BY (`dt` string)
4.LZO压缩格式处理
说明Hive的LZO压缩:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
5.设置数据存储位置
LOCATION `/warehouse/gmall/ods/ods_log`;- CREATE EXTERNAL TABLE ods_log (`line` string)
- PARTITIONED BY (`dt` string) -- 按照时间创建分区
- STORED AS
- INPUTFORMAT
- "com.hadoop.mapred.DeprecatedLzoTextInputFormat"
- OUTPUTFORMAT
- "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
- LOCATION
- '/warehouse/gmall/ods/ods_log' -- 指定数据在hdfs上的存储位置
- ;
上面的代码我组合了好多次,都是存在问题的,因此,就看最后这一个黑框框之中的就可以.
加载数据
在进行加载数据之前我发现我的电脑之中并没有相关的数据.
首先将之前改的压缩过程,重新变成lzop压缩,具体的过程见第六节。
如何生成相应的6月14号的数据呢?见下面的操作
我发现这个地方就是我的第二层flume没有进行配置,就是导致这个数据没有生成的原因.(先去配置第二层的flume)
这个地方调了一下午,最终第一层是没有问题了,开始调制第二层,就是配置了很多遍总数存在问题,但是最终终于出来了.(耗费了很长时间,里面我也不知道出现了什么错误,就是解决不了,只能是把环境删除之后,重新进行配置)
这个地方的东西就是我想要的数据,最后终于啊是出来了.(真的是捣鼓了半天)

数据加载成功.
 发现原来的在2020-06-14日的数据没了,这个数据就是到了下面图片的地方就是一个进行加载移动的过程.
发现原来的在2020-06-14日的数据没了,这个数据就是到了下面图片的地方就是一个进行加载移动的过程.
加载脚本的定义:
$ vim hdfs_to_ods_log.sh- #!/bin/bash
- # 定义变量方便修改
- APP=gmall
- hive=/opt/module/hive/bin/hive
- hadoop=/opt/module/hadoop-3.1.3/bin/hadoop
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$1" ] ;then
- do_date=$1
- else
- do_date=`date -d "-1 day" +%F`
- fi
- echo ================== 日志日期为 $do_date ==================
- sql="
- load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log partition(dt='$do_date');
- "
- $hive -e "$sql"
$ chmod 777 hdfs_to_ods_log.sh
$ hdfs_to_ods_log.sh 2020-06-15
上面是进行将2020-06-15日的数据进行导入的过程,但是我不知道为什么有的时候会导入不成功需要重新导入.十八.脚本之中单引号和双引号之间的区别
$ vim test.sh
- #!/bin/bash
- do_date=$1
- echo '$do_date'
- echo "$do_date"
- echo "'$do_date'"
- echo '"$do_date"'
- echo `date`

(1)单引号不取变量值
(2)双引号取变量值
(3)反引号`,执行引号中命令
(4)双引号内部嵌套单引号,取出变量值
(5)单引号内部嵌套双引号,不取出变量值十九.ODS_业务数据建表

将上述数据导入hive之中。


上述过程之中\t是不可以被省略的。
ODS层业务数据建表- --ods层业务数据页面
- --3.3.1 订单表(增量及更新)
- --hive (gmall)>
- drop table if exists ods_order_info;
- create external table ods_order_info (
- `id` string COMMENT '订单号',
- `final_total_amount` decimal(16,2) COMMENT '订单金额',
- `order_status` string COMMENT '订单状态',
- `user_id` string COMMENT '用户id',
- `out_trade_no` string COMMENT '支付流水号',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '操作时间',
- `province_id` string COMMENT '省份ID',
- `benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',
- `original_total_amount` decimal(16,2) COMMENT '原价金额',
- `feight_fee` decimal(16,2) COMMENT '运费'
- ) COMMENT '订单表'
- PARTITIONED BY (`dt` string) -- 按照时间创建分区
- row format delimited fields terminated by '\t' -- 指定分割符为\t
- STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;输出数据采用TextOutputFormat
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_order_info/' -- 指定数据在hdfs上的存储位置
- ;
- --3.3.2 订单详情表(增量)
- --hive (gmall)>
- drop table if exists ods_order_detail;
- create external table ods_order_detail(
- `id` string COMMENT '编号',
- `order_id` string COMMENT '订单号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT '商品id',
- `sku_name` string COMMENT '商品名称',
- `order_price` decimal(16,2) COMMENT '商品价格',
- `sku_num` bigint COMMENT '商品数量',
- `create_time` string COMMENT '创建时间',
- `source_type` string COMMENT '来源类型',
- `source_id` string COMMENT '来源编号'
- ) COMMENT '订单详情表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_order_detail/';
- --3.3.3 SKU商品表(全量)
- --hive (gmall)>
- drop table if exists ods_sku_info;
- create external table ods_sku_info(
- `id` string COMMENT 'skuId',
- `spu_id` string COMMENT 'spuid',
- `price` decimal(16,2) COMMENT '价格',
- `sku_name` string COMMENT '商品名称',
- `sku_desc` string COMMENT '商品描述',
- `weight` string COMMENT '重量',
- `tm_id` string COMMENT '品牌id',
- `category3_id` string COMMENT '品类id',
- `create_time` string COMMENT '创建时间'
- ) COMMENT 'SKU商品表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_sku_info/';
- --3.3.4 用户表(增量及更新)
- --hive (gmall)>
- drop table if exists ods_user_info;
- create external table ods_user_info(
- `id` string COMMENT '用户id',
- `name` string COMMENT '姓名',
- `birthday` string COMMENT '生日',
- `gender` string COMMENT '性别',
- `email` string COMMENT '邮箱',
- `user_level` string COMMENT '用户等级',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '操作时间'
- ) COMMENT '用户表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_user_info/';
- --3.3.5 商品一级分类表(全量)
- --hive (gmall)>
- drop table if exists ods_base_category1;
- create external table ods_base_category1(
- `id` string COMMENT 'id',
- `name` string COMMENT '名称'
- ) COMMENT '商品一级分类表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_category1/';
- --3.3.6 商品二级分类表(全量)
- --hive (gmall)>
- drop table if exists ods_base_category2;
- create external table ods_base_category2(
- `id` string COMMENT ' id',
- `name` string COMMENT '名称',
- category1_id string COMMENT '一级品类id'
- ) COMMENT '商品二级分类表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_category2/';
- --3.3.7 商品三级分类表(全量)
- --hive (gmall)>
- drop table if exists ods_base_category3;
- create external table ods_base_category3(
- `id` string COMMENT ' id',
- `name` string COMMENT '名称',
- category2_id string COMMENT '二级品类id'
- ) COMMENT '商品三级分类表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_category3/';
- --3.3.8 支付流水表(增量)
- --hive (gmall)>
- drop table if exists ods_payment_info;
- create external table ods_payment_info(
- `id` bigint COMMENT '编号',
- `out_trade_no` string COMMENT '对外业务编号',
- `order_id` string COMMENT '订单编号',
- `user_id` string COMMENT '用户编号',
- `alipay_trade_no` string COMMENT '支付宝交易流水编号',
- `total_amount` decimal(16,2) COMMENT '支付金额',
- `subject` string COMMENT '交易内容',
- `payment_type` string COMMENT '支付类型',
- `payment_time` string COMMENT '支付时间'
- ) COMMENT '支付流水表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_payment_info/';
- --3.3.9 省份表(特殊)
- --hive (gmall)>
- drop table if exists ods_base_province;
- create external table ods_base_province (
- `id` bigint COMMENT '编号',
- `name` string COMMENT '省份名称',
- `region_id` string COMMENT '地区ID',
- `area_code` string COMMENT '地区编码',
- `iso_code` string COMMENT 'iso编码,superset可视化使用'
- ) COMMENT '省份表'
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_province/';
- --3.3.10 地区表(特殊)
- --hive (gmall)>
- drop table if exists ods_base_region;
- create external table ods_base_region (
- `id` string COMMENT '编号',
- `region_name` string COMMENT '地区名称'
- ) COMMENT '地区表'
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_region/';
- --3.3.11 品牌表(全量)
- --hive (gmall)>
- drop table if exists ods_base_trademark;
- create external table ods_base_trademark (
- `tm_id` string COMMENT '编号',
- `tm_name` string COMMENT '品牌名称'
- ) COMMENT '品牌表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_trademark/';
- --3.3.12 订单状态表(增量)
- --hive (gmall)>
- drop table if exists ods_order_status_log;
- create external table ods_order_status_log (
- `id` string COMMENT '编号',
- `order_id` string COMMENT '订单ID',
- `order_status` string COMMENT '订单状态',
- `operate_time` string COMMENT '修改时间'
- ) COMMENT '订单状态表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_order_status_log/';
- --3.3.13 SPU商品表(全量)
- --hive (gmall)>
- drop table if exists ods_spu_info;
- create external table ods_spu_info(
- `id` string COMMENT 'spuid',
- `spu_name` string COMMENT 'spu名称',
- `category3_id` string COMMENT '品类id',
- `tm_id` string COMMENT '品牌id'
- ) COMMENT 'SPU商品表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_spu_info/';
- --3.3.14 商品评论表(增量)
- --hive (gmall)>
- drop table if exists ods_comment_info;
- create external table ods_comment_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户ID',
- `sku_id` string COMMENT '商品sku',
- `spu_id` string COMMENT '商品spu',
- `order_id` string COMMENT '订单ID',
- `appraise` string COMMENT '评价',
- `create_time` string COMMENT '评价时间'
- ) COMMENT '商品评论表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_comment_info/';
- --3.3.15 退单表(增量)
- --hive (gmall)>
- drop table if exists ods_order_refund_info;
- create external table ods_order_refund_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户ID',
- `order_id` string COMMENT '订单ID',
- `sku_id` string COMMENT '商品ID',
- `refund_type` string COMMENT '退款类型',
- `refund_num` bigint COMMENT '退款件数',
- `refund_amount` decimal(16,2) COMMENT '退款金额',
- `refund_reason_type` string COMMENT '退款原因类型',
- `create_time` string COMMENT '退款时间'
- ) COMMENT '退单表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_order_refund_info/';
- --3.3.16 加购表(全量)
- --hive (gmall)>
- drop table if exists ods_cart_info;
- create external table ods_cart_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT 'skuid',
- `cart_price` decimal(16,2) COMMENT '放入购物车时价格',
- `sku_num` bigint COMMENT '数量',
- `sku_name` string COMMENT 'sku名称 (冗余)',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '修改时间',
- `is_ordered` string COMMENT '是否已经下单',
- `order_time` string COMMENT '下单时间',
- `source_type` string COMMENT '来源类型',
- `source_id` string COMMENT '来源编号'
- ) COMMENT '加购表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_cart_info/';
- --3.3.17 商品收藏表(全量)
- --hive (gmall)>
- drop table if exists ods_favor_info;
- create external table ods_favor_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT 'skuid',
- `spu_id` string COMMENT 'spuid',
- `is_cancel` string COMMENT '是否取消',
- `create_time` string COMMENT '收藏时间',
- `cancel_time` string COMMENT '取消时间'
- ) COMMENT '商品收藏表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_favor_info/';
- --3.3.18 优惠券领用表(新增及变化)
- --hive (gmall)>
- drop table if exists ods_coupon_use;
- create external table ods_coupon_use(
- `id` string COMMENT '编号',
- `coupon_id` string COMMENT '优惠券ID',
- `user_id` string COMMENT 'skuid',
- `order_id` string COMMENT 'spuid',
- `coupon_status` string COMMENT '优惠券状态',
- `get_time` string COMMENT '领取时间',
- `using_time` string COMMENT '使用时间(下单)',
- `used_time` string COMMENT '使用时间(支付)'
- ) COMMENT '优惠券领用表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_coupon_use/';
- --3.3.19 优惠券表(全量)
- --hive (gmall)>
- drop table if exists ods_coupon_info;
- create external table ods_coupon_info(
- `id` string COMMENT '购物券编号',
- `coupon_name` string COMMENT '购物券名称',
- `coupon_type` string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
- `condition_amount` decimal(16,2) COMMENT '满额数',
- `condition_num` bigint COMMENT '满件数',
- `activity_id` string COMMENT '活动编号',
- `benefit_amount` decimal(16,2) COMMENT '减金额',
- `benefit_discount` decimal(16,2) COMMENT '折扣',
- `create_time` string COMMENT '创建时间',
- `range_type` string COMMENT '范围类型 1、商品 2、品类 3、品牌',
- `spu_id` string COMMENT '商品id',
- `tm_id` string COMMENT '品牌id',
- `category3_id` string COMMENT '品类id',
- `limit_num` bigint COMMENT '最多领用次数',
- `operate_time` string COMMENT '修改时间',
- `expire_time` string COMMENT '过期时间'
- ) COMMENT '优惠券表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_coupon_info/';
- --3.3.20 活动表(全量)
- --hive (gmall)>
- drop table if exists ods_activity_info;
- create external table ods_activity_info(
- `id` string COMMENT '编号',
- `activity_name` string COMMENT '活动名称',
- `activity_type` string COMMENT '活动类型',
- `start_time` string COMMENT '开始时间',
- `end_time` string COMMENT '结束时间',
- `create_time` string COMMENT '创建时间'
- ) COMMENT '活动表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_activity_info/';
- --3.3.21 活动订单关联表(增量)
- --hive (gmall)>
- drop table if exists ods_activity_order;
- create external table ods_activity_order(
- `id` string COMMENT '编号',
- `activity_id` string COMMENT '优惠券ID',
- `order_id` string COMMENT 'skuid',
- `create_time` string COMMENT '领取时间'
- ) COMMENT '活动订单关联表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_activity_order/';
- --3.3.22 优惠规则表(全量)
- --hive (gmall)>
- drop table if exists ods_activity_rule;
- create external table ods_activity_rule(
- `id` string COMMENT '编号',
- `activity_id` string COMMENT '活动ID',
- `condition_amount` decimal(16,2) COMMENT '满减金额',
- `condition_num` bigint COMMENT '满减件数',
- `benefit_amount` decimal(16,2) COMMENT '优惠金额',
- `benefit_discount` decimal(16,2) COMMENT '优惠折扣',
- `benefit_level` string COMMENT '优惠级别'
- ) COMMENT '优惠规则表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_activity_rule/';
- --3.3.23 编码字典表(全量)
- --hive (gmall)>
- drop table if exists ods_base_dic;
- create external table ods_base_dic(
- `dic_code` string COMMENT '编号',
- `dic_name` string COMMENT '编码名称',
- `parent_code` string COMMENT '父编码',
- `create_time` string COMMENT '创建日期',
- `operate_time` string COMMENT '操作日期'
- ) COMMENT '编码字典表'
- PARTITIONED BY (`dt` string)
- row format delimited fields terminated by '\t'
- STORED AS
- INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
- OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- location '/warehouse/gmall/ods/ods_base_dic/';

加载完成。
二十.ODS_业务数据脚本
$ vim hdfs_to_ods_db.sh
- #!/bin/bash
- APP=gmall
- hive=/opt/module/hive/bin/hive
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$2" ] ;then
- do_date=$2
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql1="
- load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table ${APP}.ods_sku_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table ${APP}.ods_user_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table ${APP}.ods_payment_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table ${APP}.ods_base_category1 partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table ${APP}.ods_base_category2 partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table ${APP}.ods_base_category3 partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/base_trademark/$do_date' OVERWRITE into table ${APP}.ods_base_trademark partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/activity_info/$do_date' OVERWRITE into table ${APP}.ods_activity_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/activity_order/$do_date' OVERWRITE into table ${APP}.ods_activity_order partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/cart_info/$do_date' OVERWRITE into table ${APP}.ods_cart_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/comment_info/$do_date' OVERWRITE into table ${APP}.ods_comment_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/coupon_info/$do_date' OVERWRITE into table ${APP}.ods_coupon_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/coupon_use/$do_date' OVERWRITE into table ${APP}.ods_coupon_use partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/favor_info/$do_date' OVERWRITE into table ${APP}.ods_favor_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/order_refund_info/$do_date' OVERWRITE into table ${APP}.ods_order_refund_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/order_status_log/$do_date' OVERWRITE into table ${APP}.ods_order_status_log partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/spu_info/$do_date' OVERWRITE into table ${APP}.ods_spu_info partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/activity_rule/$do_date' OVERWRITE into table ${APP}.ods_activity_rule partition(dt='$do_date');
- load data inpath '/origin_data/$APP/db/base_dic/$do_date' OVERWRITE into table ${APP}.ods_base_dic partition(dt='$do_date');
- "
- sql2="
- load data inpath '/origin_data/$APP/db/base_province/$do_date' OVERWRITE into table ${APP}.ods_base_province;
- load data inpath '/origin_data/$APP/db/base_region/$do_date' OVERWRITE into table ${APP}.ods_base_region;
- "
- case $1 in
- "first"){
- $hive -e "$sql1$sql2"
- };;
- "all"){
- $hive -e "$sql1"
- };;
- esac
注意上面的sql2,它是一般只加载一次的.
1)初次导入
初次导入时,脚本的第一个参数应为first,线上环境不传第二个参数,自动获取前一天日期
$ hdfs_to_ods_db.sh first 2020-06-142)每日导入
每日重复导入,脚本的第一个参数应为all,线上环境不传第二个参数,自动获取前一天日期。
$ hdfs_to_ods_db.sh all 2020-06-15spark3.0.0 => hive2.3.7 =>hadoop2.0
hive3.1.2 => spark2.4.5(不行,改为spark3.0-纯净版) =>hadoop3.0以上,hive和hadoop对应要使用纯净版的spark,为什么还要上传非纯净版的spark?
纯净版的spark用来放到yarn上面进行计算.
非纯净版的spark,用来hive通信,创建spark session会话.二十一.ODS_索引问题
在原来的hdfs_***_log.sh后面增加如下所示:

$ [hadoop-3.1.3/bin]hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2020-06-14
$ [hadoop-3.1.3/bin]hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2020-06-15
上面是进行创建6-14和6-15的索引.二十二.DWD层_get_json_object --- 工薪阶层
1)对用户行为数据解析。
2)对核心数据进行判空过滤。
3)对业务数据采用维度模型重新建模。页面埋点数据:

埋点:
在企业中页面里非常多:(中大型公司)动作 曝光 错误 页面 公共信息
中小型公司(页面比较少):一个页面一张表 (商品列表 商品点击 广告 故障 后台活跃 通知 点赞 评论 收藏)启动日志:

通过启动日志查看用户是否活跃.
1)数据
[{"name":"姚大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]
2)取出第一个json对象
hive (gmall)>
select get_json_object('[{"name":"姚大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]','$[0]'); ---第一个是代表的是要进行处理的对象,$[0]代表是全部对象
结果是:{"name":"姚大郎","sex":"男","age":"25"}
3)取出第一个json的age字段的值
hive (gmall)>
SELECT get_json_object('[{"name":"姚大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]',"$[0].age");----获取值
结果是:25
英年早逝的姚大郎同志,哈哈哈哈哈哈哈哈哈.
运行示意图:
上面的这个函数的使用是非常重要的.
二十三.创建启动日志

上面的启动日志和事件日志都是存在与ods_log之中.将上面之中的这两个日志进行相应的分离.
hive-gmall操作
- drop table if exists dwd_start_log;
- CREATE EXTERNAL TABLE dwd_start_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `entry` string COMMENT ' icon手机图标 notice 通知 install 安装后启动',
- `loading_time` bigint COMMENT '启动加载时间',
- `open_ad_id` string COMMENT '广告页ID ',
- `open_ad_ms` bigint COMMENT '广告总共播放时间',
- `open_ad_skip_ms` bigint COMMENT '用户跳过广告时点',
- `ts` bigint COMMENT '时间'
- ) COMMENT '启动日志表'
- PARTITIONED BY (dt string) -- 按照时间创建分区
- stored as parquet -- 采用parquet列式存储
- LOCATION '/warehouse/gmall/dwd/dwd_start_log' -- 指定在HDFS上存储位置
- TBLPROPERTIES('parquet.compression'='lzo') -- 采用LZO压缩
- ;
为什么在DWD层采用列式存储,ODS之中的数据是进行load剪切过来的,最原始的数据是在hdfs之中剪切过来的.

parque进行列式存储:
列式存储的好处:
在进行查询的时候,select name from user(查询速度快);列式存储配合压缩,压缩比会更小,减少磁盘使用空间.
说明:数据采用parquet存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的text方式存储数据,需要采用支持切片的,lzop压缩方式并创建索引。
二十四.加载数据
hive
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_start_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.ts')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.start') is not null;
hive (gmall)> select * from dwd_start_log where dt='2020-06-14' limit 2;

执行是没有问题的.
二十五.hive读取文件
select * from ods_log;---不执行MR
select count(*) from ods_log;---执行MR


原因是select * from ods_log不执行MR操作,默认采用的是ods_log建表语句中指定的DeprecatedLzoTextInputFormat,能够识别lzo.index为索引文件。
select count(*) from ods_log执行MR操作,默认采用的是CombineHiveInputFormat,不能识别lzo.index为索引文件,将索引文件当做普通文件处理。更严重的是,这会导致LZO文件无法切片。
解决办法:修改CombineHiveInputFormat为HiveInputFormat
再次测试
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
hive (gmall)> select * from ods_log;
Time taken: 0.706 seconds, Fetched: 2955 row(s)
hive (gmall)> select count(*) from ods_log;
2955
二十六.页面日志解析

1)进行建表
- hive (gmall)>
- drop table if exists dwd_page_log;
- CREATE EXTERNAL TABLE dwd_page_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `during_time` bigint COMMENT '持续时间毫秒',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面ID ',
- `source_type` string COMMENT '来源类型',
- `ts` bigint
- ) COMMENT '页面日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_page_log'
- TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
- insert overwrite table dwd_page_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.ts')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.page') is not null;
3)查看数据
- hive (gmall)>
- select * from dwd_page_log where dt='2020-06-14' limit 2;
二十七.动作日志建表
动作日志解析思路:动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含action字段的日志过滤出来,然后通过UDTF函数,将action数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

1)建表语句
- hive (gmall)>
- drop table if exists dwd_action_log;
- CREATE EXTERNAL TABLE dwd_action_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `during_time` bigint COMMENT '持续时间毫秒',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面id ',
- `source_type` string COMMENT '来源类型',
- `action_id` string COMMENT '动作id',
- `item` string COMMENT '目标id ',
- `item_type` string COMMENT '目标类型',
- `ts` bigint COMMENT '时间'
- ) COMMENT '动作日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_action_log'
- TBLPROPERTIES('parquet.compression'='lzo');
二十八.UDTF函数思想
2)创建UDTF函数——设计思路(下面的这张表特别需要进行注意)


3)创建UDTF函数——编写代码
(1)创建一个maven工程:hivefunction

电脑炸了!
(2)创建包名:com.atguigu.hive.udtf
(3)引入如下依赖
- <dependencies>
- <!--添加hive依赖-->
- <dependency>
- <groupId>org.apache.hive</groupId>
- <artifactId>hive-exec</artifactId>
- <version>3.1.2</version>
- </dependency>
- </dependencies>
(4)编码
- package com.atguigu.hive.udtf;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
- import org.apache.hadoop.hive.ql.metadata.HiveException;
- import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
- import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
- import org.json.JSONArray;
- import java.util.ArrayList;
- import java.util.List;
- public class ExplodeJSONArray extends GenericUDTF {
- @Override
- public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
- // 1 参数合法性检查:如果要是传入的参数不是一个的话,抛出一个异常 action
- if (argOIs.getAllStructFieldRefs().size() != 1){
- throw new UDFArgumentException("ExplodeJSONArray 只需要一个参数");
- }
- // 2 第一个参数必须为string
- if(!"string".equals(argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector().getTypeName())){
- throw new UDFArgumentException("json_array_to_struct_array的第1个参数应为string类型");
- }
- // 3 定义返回值名称和类型
- List
fieldNames = new ArrayList (); - List
fieldOIs = new ArrayList (); - fieldNames.add("items");//这个名字可以随便起
- fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);//校验上面的名称,判断其是不是string类型
- return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
- }
- public void process(Object[] objects) throws HiveException {
- //object=>aaction => 多进多出(多行进多行出)
- // 1 获取传入的数据
- String jsonArray = objects[0].toString();
- // 2 将string转换为json数组
- JSONArray actions = new JSONArray(jsonArray);
- // 3 循环一次,取出数组中的一个json,并写出----就是将JSON之中的东西依次进行导出的过程.进行循环遍历,一次一次进行相应的写出
- for (int i = 0; i < actions.length(); i++) {
- String[] result = new String[1];
- result[0] = actions.getString(i);
- forward(result);
- }
- }
- public void close() throws HiveException {
- }
- }
二十九.DWD_创建永久UDTF函数
4)创建函数
(1)打包(package)
将上面的包进行右键,Show in Explorer.
(2)将hivefunction-1.0-SNAPSHOT.jar上传到hadoop102的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
[atguigu@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars
[atguigu@hadoop102 module]$ hadoop fs -put hivefunction-1.0-SNAPSHOT.jar /user/hive/jars
上传成功.
(3)创建永久函数与开发好的java class关联---下面的explode_json_array是相应的一个函数
hive (gmall)>
create function explode_json_array as 'com.atguigu.hive.udtf.ExplodeJSONArray' using jar 'hdfs://hadoop102:8020/user/hive/jars/hivefunction-1.0-SNAPSHOT.jar';
(4)注意:如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
三十.DWD_动作日志解析完成
5)数据导入
hive (gmall)>
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_action_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(action,'$.action_id'),
- get_json_object(action,'$.item'),
- get_json_object(action,'$.item_type'),
- get_json_object(action,'$.ts')
- from ods_log lateral view explode_json_array(get_json_object(line,'$.actions')) tmp as action
- where dt='2020-06-14'
- and get_json_object(line,'$.actions') is not null;
3)查看数据
hive (gmall)>
select * from dwd_action_log where dt='2020-06-14' limit 2;
三十一.DWD_曝光日志
曝光日志解析思路:曝光日志表中每行数据对应一个曝光记录,一个曝光记录应当包含公共信息、页面信息以及曝光信息。先将包含display字段的日志过滤出来,然后通过UDTF函数,将display数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

1)建表语句
- hive (gmall)>
- drop table if exists dwd_display_log;
- CREATE EXTERNAL TABLE dwd_display_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `during_time` bigint COMMENT 'app版本号',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面ID ',
- `source_type` string COMMENT '来源类型',
- `ts` bigint COMMENT 'app版本号',
- `display_type` string COMMENT '曝光类型',
- `item` string COMMENT '曝光对象id ',
- `item_type` string COMMENT 'app版本号',
- `order` bigint COMMENT '出现顺序'
- ) COMMENT '曝光日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_display_log'
- TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_display_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.ts'),
- get_json_object(display,'$.displayType'),
- get_json_object(display,'$.item'),
- get_json_object(display,'$.item_type'),
- get_json_object(display,'$.order')
- from ods_log lateral view explode_json_array(get_json_object(line,'$.displays')) tmp as display
- where dt='2020-06-14'
- and get_json_object(line,'$.displays') is not null;
3)查看数据
hive (gmall)> select * from dwd_display_log where dt='2020-06-14' limit 2;
三十二.页面信息解释
比如说:我们进入一个页面点击了支付,在另一个页面也点击了支付,如何查看在哪个页面进行了点击
三十三.错误日志表分析

错误日志解析思路:错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含err字段的日志过滤出来,然后使用get_json_object函数解析所有字段。
1)建表语句
- hive (gmall)>
- drop table if exists dwd_error_log;
- CREATE EXTERNAL TABLE dwd_error_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面ID ',
- `source_type` string COMMENT '来源类型',
- `entry` string COMMENT ' icon手机图标 notice 通知 install 安装后启动',
- `loading_time` string COMMENT '启动加载时间',
- `open_ad_id` string COMMENT '广告页ID ',
- `open_ad_ms` string COMMENT '广告总共播放时间',
- `open_ad_skip_ms` string COMMENT '用户跳过广告时点',
- `actions` string COMMENT '动作',
- `displays` string COMMENT '曝光',
- `ts` string COMMENT '时间',
- `error_code` string COMMENT '错误码',
- `msg` string COMMENT '错误信息'
- ) COMMENT '错误日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_error_log'
- TBLPROPERTIES('parquet.compression'='lzo');
说明:此处为对动作数组和曝光数组做处理,如需分析错误与单个动作或曝光的关联,可先使用explode_json_array函数将数组“炸开”,再使用get_json_object函数获取具体字段。
2)数据导入
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_error_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.actions'),
- get_json_object(line,'$.displays'),
- get_json_object(line,'$.ts'),
- get_json_object(line,'$.err.error_code'),
- get_json_object(line,'$.err.msg')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.err') is not null;
3)查看数据
hive (gmall)>
select * from dwd_error_log where dt='2020-06-14' limit 2;DWD层用户行为数据加载脚本
1)在hadoop102的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop102 bin]$ vim ods_to_dwd_log.sh- #!/bin/bash
- hive=/opt/module/hive/bin/hive
- APP=gmall
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$1" ] ;then
- do_date=$1
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql="
- SET mapreduce.job.queuename=hive;
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table ${APP}.dwd_start_log partition(dt='$do_date')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.ts')
- from ${APP}.ods_log
- where dt='$do_date'
- and get_json_object(line,'$.start') is not null;
- insert overwrite table ${APP}.dwd_action_log partition(dt='$do_date')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(action,'$.action_id'),
- get_json_object(action,'$.item'),
- get_json_object(action,'$.item_type'),
- get_json_object(action,'$.ts')
- from ${APP}.ods_log lateral view ${APP}.explode_json_array(get_json_object(line,'$.actions')) tmp as action
- where dt='$do_date'
- and get_json_object(line,'$.actions') is not null;
- insert overwrite table ${APP}.dwd_display_log partition(dt='$do_date')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.ts'),
- get_json_object(display,'$.displayType'),
- get_json_object(display,'$.item'),
- get_json_object(display,'$.item_type'),
- get_json_object(display,'$.order')
- from ${APP}.ods_log lateral view ${APP}.explode_json_array(get_json_object(line,'$.displays')) tmp as display
- where dt='$do_date'
- and get_json_object(line,'$.displays') is not null;
- insert overwrite table ${APP}.dwd_page_log partition(dt='$do_date')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.ts')
- from ${APP}.ods_log
- where dt='$do_date'
- and get_json_object(line,'$.page') is not null;
- insert overwrite table ${APP}.dwd_error_log partition(dt='$do_date')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.actions'),
- get_json_object(line,'$.displays'),
- get_json_object(line,'$.ts'),
- get_json_object(line,'$.err.error_code'),
- get_json_object(line,'$.err.msg')
- from ${APP}.ods_log
- where dt='$do_date'
- and get_json_object(line,'$.err') is not null;
- "
- $hive -e "$sql"
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 ods_to_dwd_log.sh3)脚本使用
[atguigu@hadoop102 module]$ ods_to_dwd_log.sh 2020-06-154)查询导入结果
hive (gmall)>
select * from dwd_start_log where dt='2020-06-15' limit 2;
5)脚本执行时间
企业开发中一般在每日凌晨30分~1点
三十四.DWD_商品维度解析
业务数据方面DWD层的搭建主要注意点在于维度的退化,减少后续大量Join操作。

商品维度表
商品维度表主要是将商品表SKU表、商品一级分类、商品二级分类、商品三级分类、商品品牌表和商品SPU表退化为商品表。

1)建表语句
- DROP TABLE IF EXISTS `dwd_dim_sku_info`;
- CREATE EXTERNAL TABLE `dwd_dim_sku_info` (
- `id` string COMMENT '商品id',
- `spu_id` string COMMENT 'spuid',
- `price` decimal(16,2) COMMENT '商品价格',
- `sku_name` string COMMENT '商品名称',
- `sku_desc` string COMMENT '商品描述',
- `weight` decimal(16,2) COMMENT '重量',
- `tm_id` string COMMENT '品牌id',
- `tm_name` string COMMENT '品牌名称',
- `category3_id` string COMMENT '三级分类id',
- `category2_id` string COMMENT '二级分类id',
- `category1_id` string COMMENT '一级分类id',
- `category3_name` string COMMENT '三级分类名称',
- `category2_name` string COMMENT '二级分类名称',
- `category1_name` string COMMENT '一级分类名称',
- `spu_name` string COMMENT 'spu名称',
- `create_time` string COMMENT '创建时间'
- ) COMMENT '商品维度表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_sku_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_sku_info partition(dt='2020-06-14')
- select
- sku.id, --- 通过下面起别名的方式取出id
- sku.spu_id, --- 通过下面起别名的方式取出spu_id
- sku.price,
- sku.sku_name,
- sku.sku_desc, --- 描述
- sku.weight, --- 重量
- sku.tm_id, --- 品牌id
- ob.tm_name, --- 品牌名称
- sku.category3_id,
- c2.id category2_id,
- c1.id category1_id,
- c3.name category3_name,
- c2.name category2_name,
- c1.name category1_name,
- spu.spu_name,
- sku.create_time
- from
- (
- select * from ods_sku_info where dt='2020-06-14'
- )sku --- 以sku为主,sku是个别名
- join
- (
- select * from ods_base_trademark where dt='2020-06-14'
- )ob on sku.tm_id=ob.tm_id 后面就是一个进行join的过程,需要谁就是与谁进行join,ob是一个别名
- join
- (
- select * from ods_spu_info where dt='2020-06-14'
- )spu on spu.id = sku.spu_id 需要谁和谁进行join
- join
- (
- select * from ods_base_category3 where dt='2020-06-14'
- )c3 on sku.category3_id=c3.id
- join
- (
- select * from ods_base_category2 where dt='2020-06-14'
- )c2 on c3.category2_id=c2.id
- join
- (
- select * from ods_base_category1 where dt='2020-06-14'
- )c1 on c2.category1_id=c1.id;
3)查询加载结果
hive (gmall)> select * from dwd_dim_sku_info where dt='2020-06-14' limit 2;三十五.DWD_优惠券维度表
把ODS层ods_coupon_info表数据导入到DWD层优惠卷维度表,在导入过程中可以做适当的清洗。
1)建表语句
- drop table if exists dwd_dim_coupon_info;
- create external table dwd_dim_coupon_info(
- `id` string COMMENT '购物券编号',
- `coupon_name` string COMMENT '购物券名称',
- `coupon_type` string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
- `condition_amount` decimal(16,2) COMMENT '满额数',
- `condition_num` bigint COMMENT '满件数',
- `activity_id` string COMMENT '活动编号',
- `benefit_amount` decimal(16,2) COMMENT '减金额',
- `benefit_discount` decimal(16,2) COMMENT '折扣',
- `create_time` string COMMENT '创建时间',
- `range_type` string COMMENT '范围类型 1、商品 2、品类 3、品牌',
- `spu_id` string COMMENT '商品id',
- `tm_id` string COMMENT '品牌id',
- `category3_id` string COMMENT '品类id',
- `limit_num` bigint COMMENT '最多领用次数',
- `operate_time` string COMMENT '修改时间',
- `expire_time` string COMMENT '过期时间'
- ) COMMENT '优惠券维度表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_coupon_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_coupon_info partition(dt='2020-06-14')
- select
- id,
- coupon_name,
- coupon_type,
- condition_amount,
- condition_num,
- activity_id,
- benefit_amount,
- benefit_discount,
- create_time,
- range_type,
- spu_id,
- tm_id,
- category3_id,
- limit_num,
- operate_time,
- expire_time
- from ods_coupon_info
- where dt='2020-06-14';
3)查询加载结果
hive (gmall)> select * from dwd_dim_coupon_info where dt='2020-06-14' limit 2;三十六.活动维度表(全量)
活动维度表

1)建表语句
- drop table if exists dwd_dim_activity_info;
- create external table dwd_dim_activity_info(
- `id` string COMMENT '编号',
- `activity_name` string COMMENT '活动名称',
- `activity_type` string COMMENT '活动类型',
- `start_time` string COMMENT '开始时间',
- `end_time` string COMMENT '结束时间',
- `create_time` string COMMENT '创建时间'
- ) COMMENT '活动信息表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_activity_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_activity_info partition(dt='2020-06-14')
- select
- id,
- activity_name,
- activity_type,
- start_time,
- end_time,
- create_time
- from ods_activity_info
- where dt='2020-06-14';
3)查询结果
select * from dwd_dim_activity_info where dt='2020-06-14' limit 2
自定义UDTF函数的一个好处,为什么不使用系统的炸裂函数?
理由:自定义UDTF函数的好处是可以快速定义到函数的问题.更加的灵活,可以快速定义到问题.脚本之中进行执行的时候,自定义函数前面也是需要增加库名的,第一遍自己写没有添加会导致执行不下去.
自定义函数声明问题:自定义函数是以库为单位,并不是全局的,不能够跨越库去执行相应的函数.
自定义UDTF函数的步骤:
(1)定义一个类,继承G..UDTF
(2)重写里面的三个方法,初始化(输入参数的个数 和类型校验 定义返回值名称 校验返回值类型)
process(支持多进多出,本次项目是用的是=>1进多出 object[0].toString forward)
close
(3)打包+上传(hdfs集群路径)
(4)在hive客户端进行注册gmall->create function ex_json_array as "全类名" using "hdfs://hadoop"stored as parquet + lzo 是支持切片的
三十七.DWD_业务_维度退化

进行相应的join操作,进而得到相应的维度退化过程.(面试:对于哪些表进行了维度退化)
省份表和地区表-------地区表
商品表 spu 品类表 三级分类 二级分类 一级分类------商品维度表
时间 (年 月 日)-------时间维度表三十八.DWD_业务_ETL清洗
ETL内容:(1)数据清洗,就是进行相应的数据解析; (2)核心字段不能为空.(3)超时信息进行过滤.(4)重复数据进行过滤.(5)核心字段错误,进行过滤.
清洗手段:hql,spark sql,python,MR,Kettle(深圳比较多,北京是比较少的)
来了10000条日志,这里需要进行清洗的数据是多少. 10000条数据算正常,但是一旦超过了10000条,找谁
用户行为数据(点赞) 业务数据(点赞) 当他们都是存在的时候,
1.正常情况下我们是使用业务数据的.(优先选择业务)
2.拼接:业务 | 用户行为
有业务用业务,但是当业务Hi空的时候用用户行为的.三十九.DWD_业务_活动维度

1)建表语句
- drop table if exists dwd_dim_activity_info;
- create external table dwd_dim_activity_info(
- `id` string COMMENT '编号',
- `activity_name` string COMMENT '活动名称',
- `activity_type` string COMMENT '活动类型',
- `start_time` string COMMENT '开始时间',
- `end_time` string COMMENT '结束时间',
- `create_time` string COMMENT '创建时间'
- ) COMMENT '活动信息表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_activity_info/'
- tblproperties ("parquet.compression"="lzo");
2) 数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_activity_info partition(dt='2020-06-14')
- select
- id,
- activity_name,
- activity_type,
- start_time,
- end_time,
- create_time
- from ods_activity_info
- where dt='2020-06-14';
3)查询加载结果
hive (gmall)> select * from dwd_dim_activity_info where dt='2020-06-14' limit 2;
四十.DWD_业务_地区维度

1)创建表
- DROP TABLE IF EXISTS `dwd_dim_base_province`;
- CREATE EXTERNAL TABLE `dwd_dim_base_province` (
- `id` string COMMENT 'id',
- `province_name` string COMMENT '省市名称',
- `area_code` string COMMENT '地区编码',
- `iso_code` string COMMENT 'ISO编码',
- `region_id` string COMMENT '地区id',
- `region_name` string COMMENT '地区名称'
- ) COMMENT '地区维度表'
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_base_province/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_base_province
- select
- bp.id,
- bp.name,
- bp.area_code,
- bp.iso_code,
- bp.region_id,
- br.region_name
- from
- (
- select * from ods_base_province
- ) bp
- join
- (
- select * from ods_base_region
- ) br
- on bp.region_id = br.id;
3)查询加载结果
select * from dwd_dim_base_province limit 2;四十一.DWD_业务_时间维度
1)建表语句
- DROP TABLE IF EXISTS `dwd_dim_date_info`;
- CREATE EXTERNAL TABLE `dwd_dim_date_info`(
- `date_id` string ,
- `week_id` string ,
- `week_day` string ,
- `day` string ,
- `month` string ,
- `quarter` string ,
- `year` string ,
- `is_workday` string ,
- `holiday_id` string
- )
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_date_info/'
- tblproperties ("parquet.compression"="lzo");
2)把date_info.txt文件上传到hadoop102的/opt/module/db_log/路径
3)数据装载
注意:由于dwd_dim_date_info是列式存储+LZO压缩。直接将date_info.txt文件导入到目标表,并不会直接转换为列式存储+LZO压缩。我们需要创建一张普通的临时表dwd_dim_date_info_tmp,将date_info.txt加载到该临时表中。最后通过查询临时表数据,把查询到的数据插入到最终的目标表中。
(1)创建临时表,非列式存储
- DROP TABLE IF EXISTS `dwd_dim_date_info_tmp`;
- CREATE EXTERNAL TABLE `dwd_dim_date_info_tmp`(
- `date_id` string ,
- `week_id` string ,
- `week_day` string ,
- `day` string ,
- `month` string ,
- `quarter` string ,
- `year` string ,
- `is_workday` string ,
- `holiday_id` string
- )
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/dwd/dwd_dim_date_info_tmp/';
(2)将数据导入临时表
load data local inpath '/opt/module/db_log/date_info.txt' into table dwd_dim_date_info_tmp;
(3)将数据导入正式表
insert overwrite table dwd_dim_date_info select * from dwd_dim_date_info_tmp;
4)查询加载结果
hive (gmall)> select * from dwd_dim_date_info;
上面的过程就是将date——info.txt之中的数据先是导入到临时表之中,然后在使用列式存储的方法和lzo压缩将上述的东西直接再存入表中。
四十二.DWD_业务_支付事实表

 1)建表语句
1)建表语句- drop table if exists dwd_fact_payment_info;
- create external table dwd_fact_payment_info (
- `id` string COMMENT 'id',
- `out_trade_no` string COMMENT '对外业务编号',
- `order_id` string COMMENT '订单编号',
- `user_id` string COMMENT '用户编号',
- `alipay_trade_no` string COMMENT '支付宝交易流水编号',
- `payment_amount` decimal(16,2) COMMENT '支付金额',
- `subject` string COMMENT '交易内容',
- `payment_type` string COMMENT '支付类型',
- `payment_time` string COMMENT '支付时间',
- `province_id` string COMMENT '省份ID'
- ) COMMENT '支付事实表表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_payment_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_payment_info partition(dt='2020-06-14')
- select
- pi.id,
- pi.out_trade_no,
- pi.order_id,
- pi.user_id,
- pi.alipay_trade_no,
- pi.total_amount,
- pi.subject,
- pi.payment_type,
- pi.payment_time,
- oi.province_id
- from
- (
- select * from ods_payment_info where dt='2020-06-14'
- )pi
- join
- (
- select id, province_id from ods_order_info where dt='2020-06-14'
- )oi
- on pi.order_id = oi.id;
这里的join里面的select是可以进行随便写的(在实际的企业之中,*是不可以出现的,因为会影响性能),on是对应条件。
3)查询结果
hive (gmall)> select * from dwd_fact_payment_info where dt='2020-06-14' limit 2;
四十三.DWD_业务_退款事实表
把ODS层ods_order_refund_info表数据导入到DWD层退款事实表,在导入过程中可以做适当的清洗。
时间
用户
地区
商品
优惠券
活动
编码
度量值
退款
√
√
√
件数/金额
1)建表语句
- drop table if exists dwd_fact_order_refund_info;
- create external table dwd_fact_order_refund_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户ID',
- `order_id` string COMMENT '订单ID',
- `sku_id` string COMMENT '商品ID',
- `refund_type` string COMMENT '退款类型',
- `refund_num` bigint COMMENT '退款件数',
- `refund_amount` decimal(16,2) COMMENT '退款金额',
- `refund_reason_type` string COMMENT '退款原因类型',
- `create_time` string COMMENT '退款时间'
- ) COMMENT '退款事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_order_refund_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_order_refund_info partition(dt='2020-06-14')
- select
- id,
- user_id,
- order_id,
- sku_id,
- refund_type,
- refund_num,
- refund_amount,
- refund_reason_type,
- create_time
- from ods_order_refund_info
- where dt='2020-06-14';
3)查询结果
select * from dwd_fact_order_refund_info where dt='2020-06-14' limit 2;四十四.DWD_业务_评价事实表
把ODS层ods_comment_info表数据导入到DWD层评价事实表,在导入过程中可以做适当的清洗。
时间
用户
地区
商品
优惠券
活动
编码
度量值
评价
√
√
√
个数
1)建表语句
- drop table if exists dwd_fact_comment_info;
- create external table dwd_fact_comment_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户ID',
- `sku_id` string COMMENT '商品sku',
- `spu_id` string COMMENT '商品spu',
- `order_id` string COMMENT '订单ID',
- `appraise` string COMMENT '评价',
- `create_time` string COMMENT '评价时间'
- ) COMMENT '评价事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_comment_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_comment_info partition(dt='2020-06-14')
- select
- id,
- user_id,
- sku_id,
- spu_id,
- order_id,
- appraise,
- create_time
- from ods_comment_info
- where dt='2020-06-14';
3)查询加载结果
select * from dwd_fact_comment_info where dt='2020-06-14' limit 2;
四十五.DWD_业务_订单详情事实表-217
时间
用户
地区
商品
优惠券
活动
编码
度量值
订单详情
√
√
√
√
件数/金额

阿里的一道面试题:如下所示,

上面需要进行考虑的是一个分摊情况,在相应的字段之中的表示

1)建表语句
- drop table if exists dwd_fact_order_detail;
- create external table dwd_fact_order_detail (
- `id` string COMMENT '订单编号',
- `order_id` string COMMENT '订单号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT 'sku商品id',
- `sku_name` string COMMENT '商品名称',
- `order_price` decimal(16,2) COMMENT '商品价格',
- `sku_num` bigint COMMENT '商品数量',
- `create_time` string COMMENT '创建时间',
- `province_id` string COMMENT '省份ID',
- `source_type` string COMMENT '来源类型',
- `source_id` string COMMENT '来源编号',
- `original_amount_d` decimal(20,2) COMMENT '原始价格分摊',
- `final_amount_d` decimal(20,2) COMMENT '购买价格分摊',
- `feight_fee_d` decimal(20,2) COMMENT '分摊运费',
- `benefit_reduce_amount_d` decimal(20,2) COMMENT '分摊优惠'
- ) COMMENT '订单明细事实表表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_order_detail/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_order_detail partition(dt='2020-06-14')
- select
- id,
- order_id,
- user_id,
- sku_id,
- sku_name,
- order_price,
- sku_num,
- create_time,
- province_id,
- source_type,
- source_id,
- original_amount_d,
- if(rn=1,final_total_amount -(sum_div_final_amount - final_amount_d),final_amount_d),
- if(rn=1,feight_fee - (sum_div_feight_fee - feight_fee_d),feight_fee_d),
- if(rn=1,benefit_reduce_amount - (sum_div_benefit_reduce_amount -benefit_reduce_amount_d), benefit_reduce_amount_d)
- from
- (
- select
- od.id,
- od.order_id,
- od.user_id,
- od.sku_id,
- od.sku_name,
- od.order_price,
- od.sku_num,
- od.create_time,
- oi.province_id,
- od.source_type,
- od.source_id,
- round(od.order_price*od.sku_num,2) original_amount_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_amount_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d,
- row_number() over(partition by od.order_id order by od.id desc) rn,
- oi.final_total_amount,
- oi.feight_fee,
- oi.benefit_reduce_amount,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2)) over(partition by od.order_id) sum_div_final_amount,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2)) over(partition by od.order_id) sum_div_feight_fee,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) sum_div_benefit_reduce_amount
- from
- (
- select * from ods_order_detail where dt='2020-06-14'
- ) od
- join
- (
- select * from ods_order_info where dt='2020-06-14'
- ) oi
- on od.order_id=oi.id
- )t1;
上面代码的核心是对于分摊的操作,如下所示:

阿里面试题上来了,
3)查询加载结果
hive (gmall)> select * from dwd_fact_order_detail where dt='2020-06-14' limit 2;
四十六.DWD层_业务_订单加购表
由于购物车的数量是会发生变化,所以导增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
周期型快照事实表劣势:存储的数据量会比较大。
解决方案:周期型快照事实表存储的数据比较讲究时效性,时间太久了的意义不大,可以删除以前的数据。
时间
用户
地区
商品
优惠券
活动
编码
度量值
加购
√
√
√
件数/金额
1)建表语句
- drop table if exists dwd_fact_cart_info;
- create external table dwd_fact_cart_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT 'skuid',
- `cart_price` string COMMENT '放入购物车时价格',
- `sku_num` string COMMENT '数量',
- `sku_name` string COMMENT 'sku名称 (冗余)',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '修改时间',
- `is_ordered` string COMMENT '是否已经下单。1为已下单;0为未下单',
- `order_time` string COMMENT '下单时间',
- `source_type` string COMMENT '来源类型',
- `srouce_id` string COMMENT '来源编号'
- ) COMMENT '加购事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_cart_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_cart_info partition(dt='2020-06-14')
- select
- id,
- user_id,
- sku_id,
- cart_price,
- sku_num,
- sku_name,
- create_time,
- operate_time,
- is_ordered,
- order_time,
- source_type,
- source_id
- from ods_cart_info
- where dt='2020-06-14';
3)查询结果
select * from dwd_fact_cart_info where dt='2020-06-14' limit 2;四十七.DWD层_业务_收藏事实表
收藏的标记,是否取消,会发生变化,做增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
时间
用户
地区
商品
优惠券
活动
编码
度量值
收藏
√
√
√
个数
1)建表语句
- drop table if exists dwd_fact_favor_info;
- create external table dwd_fact_favor_info(
- `id` string COMMENT '编号',
- `user_id` string COMMENT '用户id',
- `sku_id` string COMMENT 'skuid',
- `spu_id` string COMMENT 'spuid',
- `is_cancel` string COMMENT '是否取消',
- `create_time` string COMMENT '收藏时间',
- `cancel_time` string COMMENT '取消时间'
- ) COMMENT '收藏事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_favor_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_favor_info partition(dt='2020-06-14')
- select
- id,
- user_id,
- sku_id,
- spu_id,
- is_cancel,
- create_time,
- cancel_time
- from ods_favor_info
- where dt='2020-06-14';
3)查询结果查询
select * from dwd_fact_favor_info where dt='2020-06-14' limit 2;四十八.DWD层_业务_优惠券领用事实表
时间
用户
地区
商品
优惠券
活动
编码
度量值
优惠券领用
√
√
√
个数
优惠卷的生命周期:领取优惠卷-》用优惠卷下单-》优惠卷参与支付
累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数
1)建表语句
- drop table if exists dwd_fact_coupon_use;
- create external table dwd_fact_coupon_use(
- `id` string COMMENT '编号',
- `coupon_id` string COMMENT '优惠券ID',
- `user_id` string COMMENT 'userid',
- `order_id` string COMMENT '订单id',
- `coupon_status` string COMMENT '优惠券状态',
- `get_time` string COMMENT '领取时间',
- `using_time` string COMMENT '使用时间(下单)',
- `used_time` string COMMENT '使用时间(支付)'
- ) COMMENT '优惠券领用事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_coupon_use/'
- tblproperties ("parquet.compression"="lzo");
注意:dt是按照优惠卷领用时间get_time做为分区。
2)数据装载

注意下面的代码之中有一句动态分区非严格模式,如果要是没有这一句的话会进行相应的报错.在非严格模式下,分区是开始不用指定的.
- set hive.exec.dynamic.partition.mode=nonstrict;
- set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_coupon_use partition(dt)
- select
- if(new.id is null,old.id,new.id),
- if(new.coupon_id is null,old.coupon_id,new.coupon_id),
- if(new.user_id is null,old.user_id,new.user_id),
- if(new.order_id is null,old.order_id,new.order_id),
- if(new.coupon_status is null,old.coupon_status,new.coupon_status),
- if(new.get_time is null,old.get_time,new.get_time),
- if(new.using_time is null,old.using_time,new.using_time),
- if(new.used_time is null,old.used_time,new.used_time),
- date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
- from
- (
- select
- id,
- coupon_id,
- user_id,
- order_id,
- coupon_status,
- get_time,
- using_time,
- used_time
- from dwd_fact_coupon_use
- where dt in
- (
- select
- date_format(get_time,'yyyy-MM-dd')
- from ods_coupon_use
- where dt='2020-06-14'
- )
- )old
- full outer join
- (
- select
- id,
- coupon_id,
- user_id,
- order_id,
- coupon_status,
- get_time,
- using_time,
- used_time
- from ods_coupon_use
- where dt='2020-06-14'
- )new
- on old.id=new.id;
上面是使用的全连接的过程,就是有不同的地方进行补充.先是选出来未来要被覆盖的数据,全外连接相应的新产生的数据.

3)查询加载结果
hive (gmall)> select * from dwd_fact_coupon_use where dt='2020-06-14' limit 2;
四十九.DWD_业务_系统函数(concat、concat_ws、collect_set、STR_TO_MAP)
1)concat函数
concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL

2)concat_ws函数
concat_ws函数在连接字符串的时候,只要有一个字符串不是NULL,就不会返回NULL。concat_ws函数需要指定分隔符。

3)STR_TO_MAP函数
(1)语法描述
STR_TO_MAP(VARCHAR text, VARCHAR listDelimiter, VARCHAR keyValueDelimiter)
(2)功能描述
使用listDelimiter将text分隔成K-V对,然后使用keyValueDelimiter分隔每个K-V对,组装成MAP返回。默认listDelimiter为( ,),keyValueDelimiter为(=)。
(3)案例
str_to_map('1001=2020-06-14,1002=2020-06-14', ',' , '=')
输出
{"1001":"2020-06-14","1002":"2020-06-14"}
这个地方的含义就是使用了两刀进行了切割的过程.五十.DWD_业务_订单表分析
时间
用户
地区
商品
优惠券
活动
编码
度量值
订单
√
√
√
√
件数/金额
订单生命周期:创建时间=》支付时间=》取消时间=》完成时间=》退款时间=》退款完成时间。
由于ODS层订单表只有创建时间和操作时间两个状态,不能表达所有时间含义,所以需要关联订单状态表。订单事实表里面增加了活动id,所以需要关联活动订单表。
1)建表语句
- drop table if exists dwd_fact_order_info;
- create external table dwd_fact_order_info (
- `id` string COMMENT '订单编号',
- `order_status` string COMMENT '订单状态',
- `user_id` string COMMENT '用户id',
- `out_trade_no` string COMMENT '支付流水号',
- `create_time` string COMMENT '创建时间(未支付状态)',
- `payment_time` string COMMENT '支付时间(已支付状态)',
- `cancel_time` string COMMENT '取消时间(已取消状态)',
- `finish_time` string COMMENT '完成时间(已完成状态)',
- `refund_time` string COMMENT '退款时间(退款中状态)',
- `refund_finish_time` string COMMENT '退款完成时间(退款完成状态)',
- `province_id` string COMMENT '省份ID',
- `activity_id` string COMMENT '活动ID',
- `original_total_amount` decimal(16,2) COMMENT '原价金额',
- `benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',
- `feight_fee` decimal(16,2) COMMENT '运费',
- `final_total_amount` decimal(16,2) COMMENT '订单金额'
- ) COMMENT '订单事实表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_fact_order_info/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
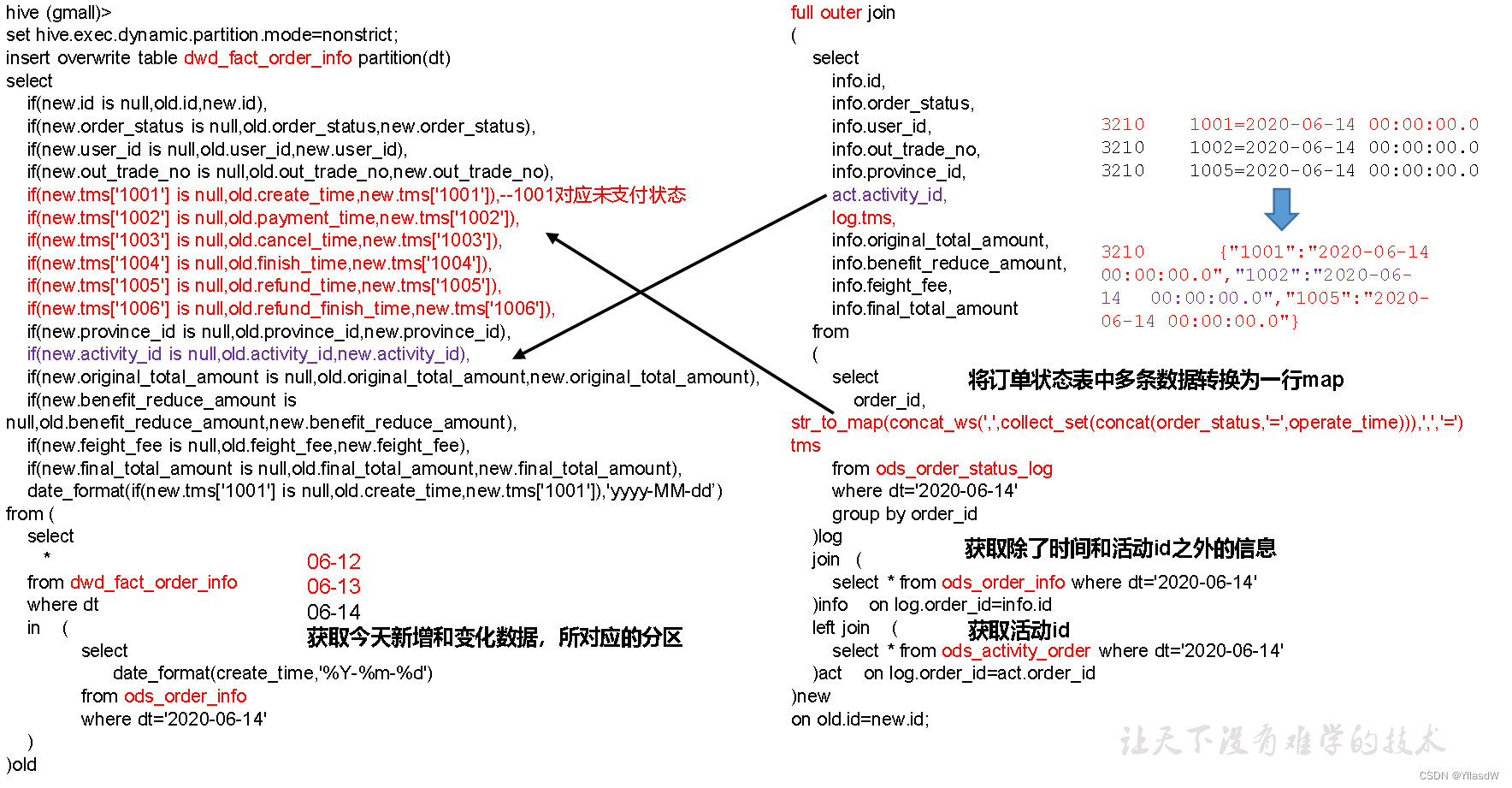
3)常用函数
select order_id, concat(order_status,'=', operate_time) from ods_order_status_log where dt='2020-06-14';

select order_id, collect_set(concat(order_status,'=',operate_time)) from ods_order_status_log where dt='2020-06-14' group by order_id; //这句话的含义就是将上面的订单id是相同的数据进行一个聚合,相同的聚合到一行上面,多行转为一行.按照订单的id.

select order_id, concat_ws(',', collect_set(concat(order_status,'=',operate_time))) from ods_order_status_log where dt='2020-06-14' group by order_id;//将上面的数据使用,进行分割.

可见原来是数组的样子,现在完全是一个字符串的样子.
select order_id, str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))), ',' , '=') from ods_order_status_log where dt='2020-06-14' group by order_id;//我们将其变成一个map的样子,里面的状态值对应着不同的含义.

4) 数据装载代码
- set hive.exec.dynamic.partition.mode=nonstrict;
- set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_fact_order_info partition(dt)
- select
- if(new.id is null,old.id,new.id),
- if(new.order_status is null,old.order_status,new.order_status),
- if(new.user_id is null,old.user_id,new.user_id),
- if(new.out_trade_no is null,old.out_trade_no,new.out_trade_no),
- if(new.tms['1001'] is null,old.create_time,new.tms['1001']),--1001对应未支付状态
- if(new.tms['1002'] is null,old.payment_time,new.tms['1002']),
- if(new.tms['1003'] is null,old.cancel_time,new.tms['1003']),
- if(new.tms['1004'] is null,old.finish_time,new.tms['1004']),
- if(new.tms['1005'] is null,old.refund_time,new.tms['1005']),
- if(new.tms['1006'] is null,old.refund_finish_time,new.tms['1006']),
- if(new.province_id is null,old.province_id,new.province_id),
- if(new.activity_id is null,old.activity_id,new.activity_id),
- if(new.original_total_amount is null,old.original_total_amount,new.original_total_amount),
- if(new.benefit_reduce_amount is null,old.benefit_reduce_amount,new.benefit_reduce_amount),
- if(new.feight_fee is null,old.feight_fee,new.feight_fee),
- if(new.final_total_amount is null,old.final_total_amount,new.final_total_amount),
- date_format(if(new.tms['1001'] is null,old.create_time,new.tms['1001']),'yyyy-MM-dd')
- from
- (
- select
- id,
- order_status,
- user_id,
- out_trade_no,
- create_time,
- payment_time,
- cancel_time,
- finish_time,
- refund_time,
- refund_finish_time,
- province_id,
- activity_id,
- original_total_amount,
- benefit_reduce_amount,
- feight_fee,
- final_total_amount
- from dwd_fact_order_info
- where dt
- in
- (
- select
- date_format(create_time,'yyyy-MM-dd')
- from ods_order_info
- where dt='2020-06-14'
- )
- )old
- full outer join
- (
- select
- info.id,
- info.order_status,
- info.user_id,
- info.out_trade_no,
- info.province_id,
- act.activity_id,
- log.tms,
- info.original_total_amount,
- info.benefit_reduce_amount,
- info.feight_fee,
- info.final_total_amount
- from
- (
- select
- order_id,
- str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=') tms
- from ods_order_status_log
- where dt='2020-06-14'
- group by order_id
- )log
- join
- (
- select * from ods_order_info where dt='2020-06-14'
- )info
- on log.order_id=info.id
- left join
- (
- select * from ods_activity_order where dt='2020-06-14'
- )act
- on log.order_id=act.order_id
- )new
- on old.id=new.id;
5)查询加载结果
hive (gmall)> select * from dwd_fact_order_info where dt='2020-06-14' limit 2;
五十一.DWD_业务_用户拉链表(非常重要的)
面试会问:
1.项目之中有没有用过拉链表?
2.用户的某一特征是变化的,但是不是经常变化的,请问你应该如何处理?(比如说是手机号为例子)用户表中的数据每日既有可能新增,也有可能修改,但修改频率并不高,属于缓慢变化维度,此处采用拉链表存储用户维度数据。
1)什么是拉链表拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就是会进行重新放入一个新的记录,并把当前日期作为生效开始日期.如果当前的信息任然是有效的,在生效结束日期前填入一个极大值(9999-99-99)

2) 为什么要使用拉链表?
拉链表适用于数据缓慢变化的数据,可以大大节约使用的空间.
3) 如何使用拉链表?

4) 拉链表的形成过程

5)拉链表制作过程图

用户当日全部数据和MySQL中每天变化的数据拼接到一起,形成一个新的临时的拉链数据表.用临时的拉链数据表去覆盖掉旧的拉链数据表.
6)拉链表制作过程
步骤0:初始化拉链表(首次独立执行)
(1)建立拉链表
- drop table if exists dwd_dim_user_info_his;
- create external table dwd_dim_user_info_his(
- `id` string COMMENT '用户id',
- `name` string COMMENT '姓名',
- `birthday` string COMMENT '生日',
- `gender` string COMMENT '性别',
- `email` string COMMENT '邮箱',
- `user_level` string COMMENT '用户等级',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '操作时间',
- `start_date` string COMMENT '有效开始日期',
- `end_date` string COMMENT '有效结束日期'
- ) COMMENT '用户拉链表'
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_user_info_his/'
- tblproperties ("parquet.compression"="lzo");
(2)初始化拉链表------在原来的用户表上加上两列
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_user_info_his
- select
- id,
- name,
- birthday,
- gender,
- email,
- user_level,
- create_time,
- operate_time,
- '2020-06-14',
- '9999-99-99'
- from ods_user_info oi
- where oi.dt='2020-06-14';
步骤1:制作当日变动数据(包括新增,修改)每日执行

(1)如何获得每日变动表
a.最好表内有创建时间和变动时间(Lucky!)
b.如果没有,可以利用第三方工具监控比如canal(后面会说到),监控MySQL的实时变化进行记录(麻烦)。
c.逐行对比前后两天的数据,检查md5(concat(全部有可能变化的字段))是否相同(low)
d.要求业务数据库提供变动流水(人品,颜值)
(2)因为ods_user_info本身导入过来就是新增变动明细的表,所以不用处理
a)数据库中新增2020-06-15一天的数据
b)通过Sqoop把2020-06-15日所有数据导入
mysql_to_hdfs.sh all 2020-06-15
c)ods层数据导入
hdfs_to_ods_db.sh all 2020-06-15
步骤2:先合并变动信息,再追加新增信息,插入到临时表中
1)建立临时表
- drop table if exists dwd_dim_user_info_his_tmp;
- create external table dwd_dim_user_info_his_tmp(
- `id` string COMMENT '用户id',
- `name` string COMMENT '姓名',
- `birthday` string COMMENT '生日',
- `gender` string COMMENT '性别',
- `email` string COMMENT '邮箱',
- `user_level` string COMMENT '用户等级',
- `create_time` string COMMENT '创建时间',
- `operate_time` string COMMENT '操作时间',
- `start_date` string COMMENT '有效开始日期',
- `end_date` string COMMENT '有效结束日期'
- ) COMMENT '订单拉链临时表'
- stored as parquet
- location '/warehouse/gmall/dwd/dwd_dim_user_info_his_tmp/'
- tblproperties ("parquet.compression"="lzo");
2)导入脚本

- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table dwd_dim_user_info_his_tmp
- select * from
- (
- select --获取的是新增和变化的数据
- id,
- name,
- birthday,
- gender,
- email,
- user_level,
- create_time,
- operate_time,
- '2020-06-15' start_date,--加上两列
- '9999-99-99' end_date
- from ods_user_info where dt='2020-06-15'
- union all --union代表的是进行去重,union进行拼接
- select
- uh.id,
- uh.name,
- uh.birthday,
- uh.gender,
- uh.email,
- uh.user_level,
- uh.create_time,
- uh.operate_time,
- uh.start_date,
- if(ui.id is not null and uh.end_date='9999-99-99', date_add(ui.dt,-1), uh.end_date) end_date
- from dwd_dim_user_info_his uh left join
- (
- select
- *
- from ods_user_info
- where dt='2020-06-15'
- ) ui on uh.id=ui.id
- )his
- order by his.id, start_date;
新的知识点-------------------------横向拼接用join,纵向拼接用union all
步骤3:把临时表覆盖给拉链表
1)导入数据
insert overwrite table dwd_dim_user_info_his select * from dwd_dim_user_info_his_tmp;
2)查询导入数据
select id, start_date, end_date from dwd_dim_user_info_his limit 2;
五十二.DWD_业务导入脚本
写脚本的五个步骤:
①#!/bin/bash
②定义变量
③获取时间
④sql语句 sql=" "遇到表, ${APP}/$do_date 遇到时间, 自定义函数需要加上${APP}
⑤执行sql(执行索引)1.编写脚本
1)在/home/atguigu/bin目录下创建脚本ods_to_dwd_db.sh
vim ods_to_dwd_db.sh在脚本中填写如下内容:
地区表只导入一次,时间表手动上传一次,用户拉链表:临时表 初始化拉链表(只能第一次手动导入,不能够在脚本里面第一次导入)- #!/bin/bash
- APP=gmall
- hive=/opt/module/hive/bin/hive
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$2" ] ;then
- do_date=$2
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql1="
- set mapreduce.job.queuename=hive;
- set hive.exec.dynamic.partition.mode=nonstrict;
- SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- insert overwrite table ${APP}.dwd_dim_sku_info partition(dt='$do_date')
- select
- sku.id,
- sku.spu_id,
- sku.price,
- sku.sku_name,
- sku.sku_desc,
- sku.weight,
- sku.tm_id,
- ob.tm_name,
- sku.category3_id,
- c2.id category2_id,
- c1.id category1_id,
- c3.name category3_name,
- c2.name category2_name,
- c1.name category1_name,
- spu.spu_name,
- sku.create_time
- from
- (
- select * from ${APP}.ods_sku_info where dt='$do_date'
- )sku
- join
- (
- select * from ${APP}.ods_base_trademark where dt='$do_date'
- )ob on sku.tm_id=ob.tm_id
- join
- (
- select * from ${APP}.ods_spu_info where dt='$do_date'
- )spu on spu.id = sku.spu_id
- join
- (
- select * from ${APP}.ods_base_category3 where dt='$do_date'
- )c3 on sku.category3_id=c3.id
- join
- (
- select * from ${APP}.ods_base_category2 where dt='$do_date'
- )c2 on c3.category2_id=c2.id
- join
- (
- select * from ${APP}.ods_base_category1 where dt='$do_date'
- )c1 on c2.category1_id=c1.id;
- insert overwrite table ${APP}.dwd_dim_coupon_info partition(dt='$do_date')
- select
- id,
- coupon_name,
- coupon_type,
- condition_amount,
- condition_num,
- activity_id,
- benefit_amount,
- benefit_discount,
- create_time,
- range_type,
- spu_id,
- tm_id,
- category3_id,
- limit_num,
- operate_time,
- expire_time
- from ${APP}.ods_coupon_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_dim_activity_info partition(dt='$do_date')
- select
- id,
- activity_name,
- activity_type,
- start_time,
- end_time,
- create_time
- from ${APP}.ods_activity_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_fact_order_detail partition(dt='$do_date')
- select
- id,
- order_id,
- user_id,
- sku_id,
- sku_num,
- order_price,
- sku_num,
- create_time,
- province_id,
- source_type,
- source_id,
- original_amount_d,
- if(rn=1,final_total_amount-(sum_div_final_amount-final_amount_d),final_amount_d),
- if(rn=1,feight_fee-(sum_div_feight_fee-feight_fee_d),feight_fee_d),
- if(rn=1,benefit_reduce_amount-(sum_div_benefit_reduce_amount-benefit_reduce_amount_d),benefit_reduce_amount_d)
- from
- (
- select
- od.id,
- od.order_id,
- od.user_id,
- od.sku_id,
- od.sku_name,
- od.order_price,
- od.sku_num,
- od.create_time,
- oi.province_id,
- od.source_type,
- od.source_id,
- round(od.order_price*od.sku_num,2) original_amount_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_amount_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
- round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d,
- row_number() over(partition by od.order_id order by od.id desc) rn,
- oi.final_total_amount,
- oi.feight_fee,
- oi.benefit_reduce_amount,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2)) over(partition by od.order_id) sum_div_final_amount,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2)) over(partition by od.order_id) sum_div_feight_fee,
- sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) sum_div_benefit_reduce_amount
- from
- (
- select * from ${APP}.ods_order_detail where dt='$do_date'
- ) od
- join
- (
- select * from ${APP}.ods_order_info where dt='$do_date'
- ) oi
- on od.order_id=oi.id
- )t1;
- insert overwrite table ${APP}.dwd_fact_payment_info partition(dt='$do_date')
- select
- pi.id,
- pi.out_trade_no,
- pi.order_id,
- pi.user_id,
- pi.alipay_trade_no,
- pi.total_amount,
- pi.subject,
- pi.payment_type,
- pi.payment_time,
- oi.province_id
- from
- (
- select * from ${APP}.ods_payment_info where dt='$do_date'
- )pi
- join
- (
- select id, province_id from ${APP}.ods_order_info where dt='$do_date'
- )oi
- on pi.order_id = oi.id;
- insert overwrite table ${APP}.dwd_fact_order_refund_info partition(dt='$do_date')
- select
- id,
- user_id,
- order_id,
- sku_id,
- refund_type,
- refund_num,
- refund_amount,
- refund_reason_type,
- create_time
- from ${APP}.ods_order_refund_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_fact_comment_info partition(dt='$do_date')
- select
- id,
- user_id,
- sku_id,
- spu_id,
- order_id,
- appraise,
- create_time
- from ${APP}.ods_comment_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_fact_cart_info partition(dt='$do_date')
- select
- id,
- user_id,
- sku_id,
- cart_price,
- sku_num,
- sku_name,
- create_time,
- operate_time,
- is_ordered,
- order_time,
- source_type,
- source_id
- from ${APP}.ods_cart_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_fact_favor_info partition(dt='$do_date')
- select
- id,
- user_id,
- sku_id,
- spu_id,
- is_cancel,
- create_time,
- cancel_time
- from ${APP}.ods_favor_info
- where dt='$do_date';
- insert overwrite table ${APP}.dwd_fact_coupon_use partition(dt)
- select
- if(new.id is null,old.id,new.id),
- if(new.coupon_id is null,old.coupon_id,new.coupon_id),
- if(new.user_id is null,old.user_id,new.user_id),
- if(new.order_id is null,old.order_id,new.order_id),
- if(new.coupon_status is null,old.coupon_status,new.coupon_status),
- if(new.get_time is null,old.get_time,new.get_time),
- if(new.using_time is null,old.using_time,new.using_time),
- if(new.used_time is null,old.used_time,new.used_time),
- date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
- from
- (
- select
- id,
- coupon_id,
- user_id,
- order_id,
- coupon_status,
- get_time,
- using_time,
- used_time
- from ${APP}.dwd_fact_coupon_use
- where dt in
- (
- select
- date_format(get_time,'yyyy-MM-dd')
- from ${APP}.ods_coupon_use
- where dt='$do_date'
- )
- )old
- full outer join
- (
- select
- id,
- coupon_id,
- user_id,
- order_id,
- coupon_status,
- get_time,
- using_time,
- used_time
- from ${APP}.ods_coupon_use
- where dt='$do_date'
- )new
- on old.id=new.id;
- insert overwrite table ${APP}.dwd_fact_order_info partition(dt)
- select
- if(new.id is null,old.id,new.id),
- if(new.order_status is null,old.order_status,new.order_status),
- if(new.user_id is null,old.user_id,new.user_id),
- if(new.out_trade_no is null,old.out_trade_no,new.out_trade_no),
- if(new.tms['1001'] is null,old.create_time,new.tms['1001']),--1001对应未支付状态
- if(new.tms['1002'] is null,old.payment_time,new.tms['1002']),
- if(new.tms['1003'] is null,old.cancel_time,new.tms['1003']),
- if(new.tms['1004'] is null,old.finish_time,new.tms['1004']),
- if(new.tms['1005'] is null,old.refund_time,new.tms['1005']),
- if(new.tms['1006'] is null,old.refund_finish_time,new.tms['1006']),
- if(new.province_id is null,old.province_id,new.province_id),
- if(new.activity_id is null,old.activity_id,new.activity_id),
- if(new.original_total_amount is null,old.original_total_amount,new.original_total_amount),
- if(new.benefit_reduce_amount is null,old.benefit_reduce_amount,new.benefit_reduce_amount),
- if(new.feight_fee is null,old.feight_fee,new.feight_fee),
- if(new.final_total_amount is null,old.final_total_amount,new.final_total_amount),
- date_format(if(new.tms['1001'] is null,old.create_time,new.tms['1001']),'yyyy-MM-dd')
- from
- (
- select
- id,
- order_status,
- user_id,
- out_trade_no,
- create_time,
- payment_time,
- cancel_time,
- finish_time,
- refund_time,
- refund_finish_time,
- province_id,
- activity_id,
- original_total_amount,
- benefit_reduce_amount,
- feight_fee,
- final_total_amount
- from ${APP}.dwd_fact_order_info
- where dt
- in
- (
- select
- date_format(create_time,'yyyy-MM-dd')
- from ${APP}.ods_order_info
- where dt='$do_date'
- )
- )old
- full outer join
- (
- select
- info.id,
- info.order_status,
- info.user_id,
- info.out_trade_no,
- info.province_id,
- act.activity_id,
- log.tms,
- info.original_total_amount,
- info.benefit_reduce_amount,
- info.feight_fee,
- info.final_total_amount
- from
- (
- select
- order_id,
- str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=') tms
- from ${APP}.ods_order_status_log
- where dt='$do_date'
- group by order_id
- )log
- join
- (
- select * from ${APP}.ods_order_info where dt='$do_date'
- )info
- on log.order_id=info.id
- left join
- (
- select * from ${APP}.ods_activity_order where dt='$do_date'
- )act
- on log.order_id=act.order_id
- )new
- on old.id=new.id;
- "
- sql2="
- insert overwrite table ${APP}.dwd_dim_base_province
- select
- bp.id,
- bp.name,
- bp.area_code,
- bp.iso_code,
- bp.region_id,
- br.region_name
- from ${APP}.ods_base_province bp
- join ${APP}.ods_base_region br
- on bp.region_id=br.id;
- "
- sql3="
- insert overwrite table ${APP}.dwd_dim_user_info_his_tmp
- select * from
- (
- select
- id,
- name,
- birthday,
- gender,
- email,
- user_level,
- create_time,
- operate_time,
- '$do_date' start_date,
- '9999-99-99' end_date
- from ${APP}.ods_user_info where dt='$do_date'
- union all
- select
- uh.id,
- uh.name,
- uh.birthday,
- uh.gender,
- uh.email,
- uh.user_level,
- uh.create_time,
- uh.operate_time,
- uh.start_date,
- if(ui.id is not null and uh.end_date='9999-99-99', date_add(ui.dt,-1), uh.end_date) end_date
- from ${APP}.dwd_dim_user_info_his uh left join
- (
- select
- *
- from ${APP}.ods_user_info
- where dt='$do_date'
- ) ui on uh.id=ui.id
- )his
- order by his.id, start_date;
- insert overwrite table ${APP}.dwd_dim_user_info_his
- select * from ${APP}.dwd_dim_user_info_his_tmp;
- "
- case $1 in
- "first"){
- $hive -e "$sql1$sql2"
- };;
- "all"){
- $hive -e "$sql1$sql3"
- };;
- esac
初次导入时,脚本的第一个参数应为first,线上环境不传第二个参数,自动获取前一天日期。
[atguigu@hadoop102 bin]$ ods_to_dwd_db.sh first 2020-06-14
每日定时导入,脚本的第一个参数应为all,线上环境不传第二个参数,自动获取前一天日期。
[atguigu@hadoop102 bin]$ ods_to_dwd_db.sh all 2020-06-15
五十三.DWS层_DWT层

站在维度的角度去看待事实.

五十四.DWS_DWT层术语
1)用户
用户以设备为判断标准,在移动统计中,每个独立设备认为是一个独立用户。Android系统根据IMEI号,IOS系统根据OpenUDID来标识一个独立用户,每部手机一个用户。
2)新增用户
首次联网使用应用的用户。如果一个用户首次打开某APP,那这个用户定义为新增用户;卸载再安装的设备,不会被算作一次新增。新增用户包括日新增用户、周新增用户、月新增用户。
3)活跃用户
打开应用的用户即为活跃用户,不考虑用户的使用情况。每天一台设备打开多次会被计为一个活跃用户。
4)周(月)活跃用户(用户活跃要去重)
某个自然周(月)内启动过应用的用户,该周(月)内的多次启动只记一个活跃用户。
5)月活跃率
月活跃用户与截止到该月累计的用户总和之间的比例。
6)沉默用户
用户仅在安装当天(次日)启动一次,后续时间无再启动行为。该指标可以反映新增用户质量和用户与APP的匹配程度。
7)版本分布
不同版本的周内各天新增用户数,活跃用户数和启动次数。利于判断APP各个版本之间的优劣和用户行为习惯。
8)本周回流用户
上周未启动过应用,本周启动了应用的用户。
9)连续n周活跃用户
连续n周,每周至少启动一次。
10)忠诚用户
连续活跃5周以上的用户
11)连续活跃用户
连续2周及以上活跃的用户
12)近期流失用户
连续n(2<= n <= 4)周没有启动应用的用户。(第n+1周没有启动过)
13)留存用户
某段时间内的新增用户,经过一段时间后,仍然使用应用的被认作是留存用户;这部分用户占当时新增用户的比例即是留存率。
例如,5月份新增用户200,这200人在6月份启动过应用的有100人,7月份启动过应用的有80人,8月份启动过应用的有50人;则5月份新增用户一个月后的留存率是50%,二个月后的留存率是40%,三个月后的留存率是25%。
14)用户新鲜度
每天启动应用的新老用户比例,即新增用户数占活跃用户数的比例。
15)单次使用时长
每次启动使用的时间长度。
16)日使用时长
累计一天内的使用时间长度。
17)启动次数计算标准
IOS平台应用退到后台就算一次独立的启动;Android平台我们规定,两次启动之间的间隔小于30秒,被计算一次启动。用户在使用过程中,若因收发短信或接电话等退出应用30秒又再次返回应用中,那这两次行为应该是延续而非独立的,所以可以被算作一次使用行为,即一次启动。业内大多使用30秒这个标准,但用户还是可以自定义此时间间隔。
五十五.DWS_DWT层系统函数
一. nvl函数
1)基本语法
NVL(表达式1,表达式2)
如果表达式1为空值,NVL返回值为表达式2的值,否则返回表达式1的值。
该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是表达式1和表达式2的数据类型必须为同一个类型。
2)案例实操
- hive (gmall)> select nvl(1,0);
- 1
- hive (gmall)> select nvl(null,"hello");
- hello
二. 日期处理函数
1)date_format函数(根据格式整理日期)
hive (gmall)> select date_format('2020-06-14','yyyy-MM');
2020-06
2)date_add函数(加减日期) 其功能和date_sub函数的功能是相同的
hive (gmall)> select date_add('2020-06-14',-1);
2020-06-13
hive (gmall)> select date_add('2020-06-14',1);
2020-06-15
3)next_day函数
(1)取当前天的下一个周的周一
hive (gmall)> select next_day('2020-06-14','MO');
2020-06-15
说明:星期一到星期日的英文(Monday,Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday)
(2)取当前周的周一
hive (gmall)> select date_add(next_day('2020-06-14','MO'),-7);
2020-06-8
4)last_day函数(求当月最后一天日期)
hive (gmall)> select last_day('2020-06-14');
2020-06-30
五十六.DWS_DWT层复杂数据类型
1)map结构数据定义
map<string,string>------这里是相应的k v类型进行存储
2)array结构数据定义
array
3)struct结构数据定义
struct
4)struct和array嵌套定义(比较常见的)
array
五十七.DWS层设备行为宽表分析
 1)建表语句
1)建表语句- drop table if exists dws_uv_detail_daycount;
- create external table dws_uv_detail_daycount
- (
- `mid_id` string COMMENT '设备id',
- `brand` string COMMENT '手机品牌',
- `model` string COMMENT '手机型号',
- `login_count` bigint COMMENT '活跃次数',
- `page_stats` array<struct<page_id:string,page_count:bigint>> COMMENT '页面访问统计'
- ) COMMENT '每日设备行为表'
- partitioned by(dt string)
- stored as parquet
- location '/warehouse/gmall/dws/dws_uv_detail_daycount'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- with
- tmp_start as
- (
- select
- mid_id,
- brand,
- model,
- count(*) login_count
- from dwd_start_log
- where dt='2020-06-14'
- group by mid_id,brand,model
- ),
- tmp_page as
- (
- select
- mid_id,
- brand,
- model, collect_set(named_struct('page_id',page_id,'page_count',page_count)) page_stats
- from
- (
- select
- mid_id,
- brand,
- model,
- page_id,
- count(*) page_count
- from dwd_page_log
- where dt='2020-06-14'
- group by mid_id,brand,model,page_id
- )tmp
- group by mid_id,brand,model
- )
- insert overwrite table dws_uv_detail_daycount partition(dt='2020-06-14')
- select
- nvl(tmp_start.mid_id,tmp_page.mid_id),
- nvl(tmp_start.brand,tmp_page.brand),
- nvl(tmp_start.model,tmp_page.model),
- tmp_start.login_count,
- tmp_page.page_stats
- from tmp_start
- full outer join tmp_page
- on tmp_start.mid_id=tmp_page.mid_id
- and tmp_start.brand=tmp_page.brand
- and tmp_start.model=tmp_page.model;
首先在用户活动表dw_start_log之中进行提取,提取出来相应的活跃次数,group by之中只能够存在三类信息,一类是字段信息,一类是常量,最后一种是聚合函数。
由page_stats之中的信息可以知道,我们这个地方是提取array之中的东西,一个一个进行提取,进而得到更多的信息,进行一个聚合操作。这里的字段是在dwd_page_log之中进行提取, page_id, count(*) page_count在这个地方的操作是将其进行相应的聚合处理,collect_set在这里的使用1上面的东西进行相应的一个聚合的过程,使得在使用的过程之中是非常好用的。collect_set(named_struct('page_id',page_id,'page_count',page_count))之中的name_struct使用是将里面的东西按照行的方式进行一个存储,可以指定里面的名称,如果要是struct的话就是一个按照col存储的过程,不能够使用名称进行指定。上面使用的with start_tmp as是创建一个临时表的过程,只有在使用第一个的时候是使用with *** as,其余的时候是使用*** as,可以直接省略as。
这里使用full outer join是将两端的信息都进行一个保全的过程。
3)查询加载结果
select * from dws_uv_detail_daycount where dt='2020-06-14' limit 2;
五十八.DWT层设备行为宽表完成

如何写出sql?
sql by里面只能有三个类型:字段 常量 聚合函数处理累积类型指标:
先找出旧表数据(当前表) 找出新表数据(在当前层的下一层),再使用join操作,有新的取出新的,没有新的取出旧的。1)建表语句
- drop table if exists dwt_uv_topic;
- create external table dwt_uv_topic
- (
- `mid_id` string comment '设备id',
- `brand` string comment '手机品牌',
- `model` string comment '手机型号',
- `login_date_first` string comment '首次活跃时间',
- `login_date_last` string comment '末次活跃时间',
- `login_day_count` bigint comment '当日活跃次数',
- `login_count` bigint comment '累积活跃天数'
- ) COMMENT '设备主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_uv_topic'
- tblproperties ("parquet.compression"="lzo");
旧表概念就是在当前一天的所有数据,累积型表都是full outer join,进行连接下一层的数据。
首次活跃,使用旧的数据进行判断,末次使用新的数据进行判断。

2)数据装载
- insert overwrite table dwt_uv_topic
- select
- nvl(new.mid_id,old.mid_id),
- nvl(new.model,old.model),
- nvl(new.brand,old.brand),
- if(old.mid_id is null,'2020-06-14',old.login_date_first),
- if(new.mid_id is not null,'2020-06-14',old.login_date_last),
- if(new.mid_id is not null, new.login_count,0),
- nvl(old.login_count,0)+if(new.login_count>0,1,0)
- from
- (
- select
- *
- from dwt_uv_topic
- )old
- full outer join
- (
- select
- *
- from dws_uv_detail_daycount
- where dt='2020-06-14'
- )new
- on old.mid_id=new.mid_id;
上面的old就是当前的表,新的表是下一层的dws层,里面含有相应的时间
3)查询加载结果
hive (gmall)> select * from dwt_uv_topic limit 5;
五十九.DWS层_会员行为宽表分析
1)建表语句
- drop table if exists dws_user_action_daycount;
- create external table dws_user_action_daycount
- (
- user_id string comment '用户 id',
- login_count bigint comment '登录次数',
- cart_count bigint comment '加入购物车次数',
- order_count bigint comment '下单次数',
- order_amount decimal(16,2) comment '下单金额',
- payment_count bigint comment '支付次数',
- payment_amount decimal(16,2) comment '支付金额',
- order_detail_stats array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计'
- ) COMMENT '每日会员行为'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dws/dws_user_action_daycount/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- select
- user_id,
- count(*) login_count
- from dwd_start_log
- where dt='2020-06-14'
- and user_id is not null
- group by user_id;
使用上面代码先是进行测试了一下,结果如下是可以正常运行的。

- with
- tmp_login as
- (
- select
- user_id,
- count(*) login_count
- from dwd_start_log
- where dt='2020-06-14'
- and user_id is not null
- group by user_id
- ),
- tmp_cart as
- (
- select
- user_id,
- count(*) cart_count
- from dwd_action_log
- where dt='2020-06-14'
- and user_id is not null
- and action_id='cart_add'
- group by user_id
- ),tmp_order as
- (
- select
- user_id,
- count(*) order_count,
- sum(final_total_amount) order_amount
- from dwd_fact_order_info
- where dt='2020-06-14'
- group by user_id
- ) ,
- tmp_payment as
- (
- select
- user_id,
- count(*) payment_count,
- sum(payment_amount) payment_amount
- from dwd_fact_payment_info
- where dt='2020-06-14'
- group by user_id
- ),
- tmp_order_detail as
- (
- select
- user_id,
- collect_set(named_struct('sku_id',sku_id,'sku_num',sku_num,'order_count',order_count,'order_amount',order_amount)) order_stats
- from
- (
- select
- user_id,
- sku_id,
- sum(sku_num) sku_num,
- count(*) order_count,
- cast(sum(final_amount_d) as decimal(20,2)) order_amount
- from dwd_fact_order_detail
- where dt='2020-06-14'
- group by user_id,sku_id
- )tmp
- group by user_id
- )
- insert overwrite table dws_user_action_daycount partition(dt='2020-06-14')
- select
- tmp_login.user_id,
- login_count,
- nvl(cart_count,0),
- nvl(order_count,0),
- nvl(order_amount,0.0),
- nvl(payment_count,0),
- nvl(payment_amount,0.0),
- order_stats
- from tmp_login
- left join tmp_cart on tmp_login.user_id=tmp_cart.user_id
- left join tmp_order on tmp_login.user_id=tmp_order.user_id
- left join tmp_payment on tmp_login.user_id=tmp_payment.user_id
- left join tmp_order_detail on tmp_login.user_id=tmp_order_detail.user_id;
3)查询加载结果
hive (gmall)> select * from dws_user_action_daycount where dt='2020-06-14' limit 2;
六十.DWT层_会员行为宽表完成

1)建表语句
- drop table if exists dwt_user_topic;
- create external table dwt_user_topic
- (
- user_id string comment '用户id',
- login_date_first string comment '首次登录时间',
- login_date_last string comment '末次登录时间',
- login_count bigint comment '累积登录天数',
- login_last_30d_count bigint comment '最近30日登录天数',
- order_date_first string comment '首次下单时间',
- order_date_last string comment '末次下单时间',
- order_count bigint comment '累积下单次数',
- order_amount decimal(16,2) comment '累积下单金额',
- order_last_30d_count bigint comment '最近30日下单次数',
- order_last_30d_amount bigint comment '最近30日下单金额',
- payment_date_first string comment '首次支付时间',
- payment_date_last string comment '末次支付时间',
- payment_count decimal(16,2) comment '累积支付次数',
- payment_amount decimal(16,2) comment '累积支付金额',
- payment_last_30d_count decimal(16,2) comment '最近30日支付次数',
- payment_last_30d_amount decimal(16,2) comment '最近30日支付金额'
- )COMMENT '会员主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_user_topic/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- insert overwrite table dwt_user_topic
- select
- nvl(new.user_id,old.user_id),
- if(old.login_date_first is null and new.login_count>0,'2020-06-14',old.login_date_first),
- if(new.login_count>0,'2020-06-14',old.login_date_last),
- nvl(old.login_count,0)+if(new.login_count>0,1,0),
- nvl(new.login_last_30d_count,0),
- if(old.order_date_first is null and new.order_count>0,'2020-06-14',old.order_date_first),
- if(new.order_count>0,'2020-06-14',old.order_date_last),
- nvl(old.order_count,0)+nvl(new.order_count,0),
- nvl(old.order_amount,0)+nvl(new.order_amount,0),
- nvl(new.order_last_30d_count,0),
- nvl(new.order_last_30d_amount,0),
- if(old.payment_date_first is null and new.payment_count>0,'2020-06-14',old.payment_date_first),
- if(new.payment_count>0,'2020-06-14',old.payment_date_last),
- nvl(old.payment_count,0)+nvl(new.payment_count,0),
- nvl(old.payment_amount,0)+nvl(new.payment_amount,0),
- nvl(new.payment_last_30d_count,0),
- nvl(new.payment_last_30d_amount,0)
- from
- dwt_user_topic old
- full outer join
- (
- select
- user_id,
- sum(if(dt='2020-06-14',login_count,0)) login_count,
- sum(if(dt='2020-06-14',order_count,0)) order_count,
- sum(if(dt='2020-06-14',order_amount,0)) order_amount,
- sum(if(dt='2020-06-14',payment_count,0)) payment_count,
- sum(if(dt='2020-06-14',payment_amount,0)) payment_amount,
- sum(if(login_count>0,1,0)) login_last_30d_count,
- sum(order_count) order_last_30d_count,
- sum(order_amount) order_last_30d_amount,
- sum(payment_count) payment_last_30d_count,
- sum(payment_amount) payment_last_30d_amount
- from dws_user_action_daycount
- where dt>=date_add( '2020-06-14',-30)
- group by user_id
- )new
- on old.user_id=new.user_id;
3)查询加载结果
hive (gmall)> select * from dwt_user_topic limit 5;六十一.数据仓库小总结
1)ODS
①保持数据原貌不做任何修改;
②创建分区表;
③采用LZO压缩;2)DWD
①清洗工具:HQL spark sql python mr kettle
②清洗规则:空值 重复数据 过期数据 解析
③清洗掉多少数据算正常 万分之一
④采用LZO压缩
⑤采用列式存储
⑥创建分区表
⑦维度退化(维度建模 星形模型)
⑧建模
选择业务=》声明粒度=》确定维度=》确定事实
全部选择 保持最小粒度 时间 用户 地点 活动 优惠券 商品(进行相应的维度退化) 确定事实表(次数 个数 件数 金额)3)DWS=》粒度是天
表:时间 用户 商品 地点 活动 优惠券
字段:站在维度的角度去看待事实,去看待相应的度量值4)DWT=》粒度是从事件开始到结束
表:时间 用户 商品 地点 活动 优惠券
字段:站在维度的角度去看待事实,关注开始 结束 度量值的累积值 一段时间的累计值5)ADS统计指标
六十二.数据仓库_宽表回顾
如果要是不存在DWS和DWT是可以的,因为存在DWD层,DWD层的信息是足够明细的。DWS和DWT层是为了为了提高表的复用性。后面所谓的需求是为了做统计,就是将相应的数据做一个聚合的过程,有的东西是需要需要进行好多步骤,然后分析得到最终的结果。
DWS和DWT就是将进行重复计算的数据放到一个表之中,这就是相应的宽表的意义。
主题宽表就是什么主题就是什么东西,宽表之中就是所有的和事实表相关的东西。这个表为什么要这样进行设计,因为这样设计是和后面的需求有关系的,就是为了方便统计各个指标。一个维度字段和一个度量值。这里的宽表并不是万能的,只能应对一些常见的需求,并不能应对万能的需求。
每天进行更新的时候,并不是将DWS所有的都进行聚合,DWT存在的意义就是将增加的数据与新的DWS进行一个累加的过程。
六十三.DWS_商品主题每日统计
1)建表语句
- drop table if exists dws_sku_action_daycount;
- create external table dws_sku_action_daycount
- (
- sku_id string comment 'sku_id',
- order_count bigint comment '被下单次数',
- order_num bigint comment '被下单件数',
- order_amount decimal(16,2) comment '被下单金额',
- payment_count bigint comment '被支付次数',
- payment_num bigint comment '被支付件数',
- payment_amount decimal(16,2) comment '被支付金额',
- refund_count bigint comment '被退款次数',
- refund_num bigint comment '被退款件数',
- refund_amount decimal(16,2) comment '被退款金额',
- cart_count bigint comment '被加入购物车次数',
- favor_count bigint comment '被收藏次数',
- appraise_good_count bigint comment '好评数',
- appraise_mid_count bigint comment '中评数',
- appraise_bad_count bigint comment '差评数',
- appraise_default_count bigint comment '默认评价数'
- ) COMMENT '每日商品行为'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dws/dws_sku_action_daycount/'
- tblproperties ("parquet.compression"="lzo");
前三个实在相应的订单详情的字段之中找到。
2)数据装载
注意:如果是23点59下单,支付日期跨天。需要从订单详情里面取出支付时间是今天,且订单时间是昨天或者今天的订单。
- with
- tmp_order as
- (
- ---包含支付的订单也包含未支付的订单
- select
- sku_id,
- count(*) order_count, ---直接使用count(*)就可以拿到下单次数
- sum(sku_num) order_num, ---商品支付的件数
- sum(final_amount_d) order_amount ---商品支付的最终金额(统一按照最终金额算)
- from dwd_fact_order_detail
- where dt='2020-06-14' --- 过滤,按照当天的数据算
- group by sku_id
- ),
- tmp_payment as
- (
- ---支付的订单
- select
- sku_id,
- count(*) payment_count,
- sum(sku_num) payment_num,
- sum(final_amount_d) payment_amount
- from dwd_fact_order_detail
- where dt='2020-06-14'
- and order_id in
- (
- select
- id
- from dwd_fact_order_info
- where (dt='2020-06-14'
- or dt=date_add('2020-06-14',-1)) ---进行了订单
- and date_format(payment_time,'yyyy-MM-dd')='2020-06-14' ---进行了支付
- )
- group by sku_id
- ),
- tmp_refund as
- (
- select
- sku_id,
- count(*) refund_count,
- sum(refund_num) refund_num,
- sum(refund_amount) refund_amount
- from dwd_fact_order_refund_info
- where dt='2020-06-14'
- group by sku_id
- ),
- tmp_cart as
- (
- select
- item sku_id,
- count(*) cart_count
- from dwd_action_log
- where dt='2020-06-14'
- and user_id is not null
- and action_id='cart_add'
- group by item
- ),tmp_favor as
- (
- select
- item sku_id,
- count(*) favor_count
- from dwd_action_log
- where dt='2020-06-14'
- and user_id is not null
- and action_id='favor_add'
- group by item
- ),
- tmp_appraise as
- (
- select
- sku_id,
- sum(if(appraise='1201',1,0)) appraise_good_count,
- sum(if(appraise='1202',1,0)) appraise_mid_count,
- sum(if(appraise='1203',1,0)) appraise_bad_count,
- sum(if(appraise='1204',1,0)) appraise_default_count
- from dwd_fact_comment_info
- where dt='2020-06-14'
- group by sku_id
- )
- insert overwrite table dws_sku_action_daycount partition(dt='2020-06-14')
- select
- sku_id,
- sum(order_count),
- sum(order_num),
- sum(order_amount),
- sum(payment_count),
- sum(payment_num),
- sum(payment_amount),
- sum(refund_count),
- sum(refund_num),
- sum(refund_amount),
- sum(cart_count),
- sum(favor_count),
- sum(appraise_good_count),
- sum(appraise_mid_count),
- sum(appraise_bad_count),
- sum(appraise_default_count)
- from
- (
- select
- sku_id,
- order_count,
- order_num,
- order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_order
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- payment_count,
- payment_num,
- payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_payment
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- refund_count,
- refund_num,
- refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_refund
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_cart
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_favor
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- appraise_good_count,
- appraise_mid_count,
- appraise_bad_count,
- appraise_default_count
- from tmp_appraise
- )tmp
- group by sku_id;
上面的with as是为了声明子查询,使用left join是左边有的,加上右边有的,并且上面的操作是使用补零的操作进行联合。
3)查询加载结果
hive (gmall)>
select * from dws_sku_action_daycount where dt='2020-06-14' limit 2;
六十四.DWT_商品主题宽表_数据装载
1)建表语句
- drop table if exists dwt_sku_topic;
- create external table dwt_sku_topic
- (
- sku_id string comment 'sku_id',
- spu_id string comment 'spu_id',
- order_last_30d_count bigint comment '最近30日被下单次数',
- order_last_30d_num bigint comment '最近30日被下单件数',
- order_last_30d_amount decimal(16,2) comment '最近30日被下单金额',
- order_count bigint comment '累积被下单次数',
- order_num bigint comment '累积被下单件数',
- order_amount decimal(16,2) comment '累积被下单金额',
- payment_last_30d_count bigint comment '最近30日被支付次数',
- payment_last_30d_num bigint comment '最近30日被支付件数',
- payment_last_30d_amount decimal(16,2) comment '最近30日被支付金额',
- payment_count bigint comment '累积被支付次数',
- payment_num bigint comment '累积被支付件数',
- payment_amount decimal(16,2) comment '累积被支付金额',
- refund_last_30d_count bigint comment '最近三十日退款次数',
- refund_last_30d_num bigint comment '最近三十日退款件数',
- refund_last_30d_amount decimal(16,2) comment '最近三十日退款金额',
- refund_count bigint comment '累积退款次数',
- refund_num bigint comment '累积退款件数',
- refund_amount decimal(16,2) comment '累积退款金额',
- cart_last_30d_count bigint comment '最近30日被加入购物车次数',
- cart_count bigint comment '累积被加入购物车次数',
- favor_last_30d_count bigint comment '最近30日被收藏次数',
- favor_count bigint comment '累积被收藏次数',
- appraise_last_30d_good_count bigint comment '最近30日好评数',
- appraise_last_30d_mid_count bigint comment '最近30日中评数',
- appraise_last_30d_bad_count bigint comment '最近30日差评数',
- appraise_last_30d_default_count bigint comment '最近30日默认评价数',
- appraise_good_count bigint comment '累积好评数',
- appraise_mid_count bigint comment '累积中评数',
- appraise_bad_count bigint comment '累积差评数',
- appraise_default_count bigint comment '累积默认评价数'
- )COMMENT '商品主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_sku_topic/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- insert overwrite table dwt_sku_topic
- select
- nvl(new.sku_id,old.sku_id),
- sku_info.spu_id,
- nvl(new.order_count30,0),
- nvl(new.order_num30,0),
- nvl(new.order_amount30,0),
- nvl(old.order_count,0) + nvl(new.order_count,0),
- nvl(old.order_num,0) + nvl(new.order_num,0),
- nvl(old.order_amount,0) + nvl(new.order_amount,0),
- nvl(new.payment_count30,0),
- nvl(new.payment_num30,0),
- nvl(new.payment_amount30,0),
- nvl(old.payment_count,0) + nvl(new.payment_count,0),
- nvl(old.payment_num,0) + nvl(new.payment_count,0),
- nvl(old.payment_amount,0) + nvl(new.payment_count,0),
- nvl(new.refund_count30,0),
- nvl(new.refund_num30,0),
- nvl(new.refund_amount30,0),
- nvl(old.refund_count,0) + nvl(new.refund_count,0),
- nvl(old.refund_num,0) + nvl(new.refund_num,0),
- nvl(old.refund_amount,0) + nvl(new.refund_amount,0),
- nvl(new.cart_count30,0),
- nvl(old.cart_count,0) + nvl(new.cart_count,0),
- nvl(new.favor_count30,0),
- nvl(old.favor_count,0) + nvl(new.favor_count,0),
- nvl(new.appraise_good_count30,0),
- nvl(new.appraise_mid_count30,0),
- nvl(new.appraise_bad_count30,0),
- nvl(new.appraise_default_count30,0) ,
- nvl(old.appraise_good_count,0) + nvl(new.appraise_good_count,0),
- nvl(old.appraise_mid_count,0) + nvl(new.appraise_mid_count,0),
- nvl(old.appraise_bad_count,0) + nvl(new.appraise_bad_count,0),
- nvl(old.appraise_default_count,0) + nvl(new.appraise_default_count,0)
- from
- dwt_sku_topic old
- full outer join
- (
- select
- sku_id,
- sum(if(dt='2020-06-14', order_count,0 )) order_count,
- sum(if(dt='2020-06-14',order_num ,0 )) order_num,
- sum(if(dt='2020-06-14',order_amount,0 )) order_amount ,
- sum(if(dt='2020-06-14',payment_count,0 )) payment_count,
- sum(if(dt='2020-06-14',payment_num,0 )) payment_num,
- sum(if(dt='2020-06-14',payment_amount,0 )) payment_amount,
- sum(if(dt='2020-06-14',refund_count,0 )) refund_count,
- sum(if(dt='2020-06-14',refund_num,0 )) refund_num,
- sum(if(dt='2020-06-14',refund_amount,0 )) refund_amount,
- sum(if(dt='2020-06-14',cart_count,0 )) cart_count,
- sum(if(dt='2020-06-14',favor_count,0 )) favor_count,
- sum(if(dt='2020-06-14',appraise_good_count,0 )) appraise_good_count,
- sum(if(dt='2020-06-14',appraise_mid_count,0 ) ) appraise_mid_count ,
- sum(if(dt='2020-06-14',appraise_bad_count,0 )) appraise_bad_count,
- sum(if(dt='2020-06-14',appraise_default_count,0 )) appraise_default_count,
- sum(order_count) order_count30 ,
- sum(order_num) order_num30,
- sum(order_amount) order_amount30,
- sum(payment_count) payment_count30,
- sum(payment_num) payment_num30,
- sum(payment_amount) payment_amount30,
- sum(refund_count) refund_count30,
- sum(refund_num) refund_num30,
- sum(refund_amount) refund_amount30,
- sum(cart_count) cart_count30,
- sum(favor_count) favor_count30,
- sum(appraise_good_count) appraise_good_count30,
- sum(appraise_mid_count) appraise_mid_count30,
- sum(appraise_bad_count) appraise_bad_count30,
- sum(appraise_default_count) appraise_default_count30
- from dws_sku_action_daycount
- where dt >= date_add ('2020-06-14', -30)
- group by sku_id
- )new
- on new.sku_id = old.sku_id
- left join
- (select * from dwd_dim_sku_info where dt='2020-06-14') sku_info
- on nvl(new.sku_id,old.sku_id)= sku_info.id;
上面的构建的思路也是使用普通的叠加的操作,拿到的数据和之前的数据进行相加。
有一个小细节,上面的spu_id和去拿到?需要和商品维度表进行一个join六十五.DWS_活动每日统计宽表

1)建表语句
- drop table if exists dwt_activity_topic;
- create external table dwt_activity_topic(
- `id` string COMMENT '编号',
- `activity_name` string COMMENT '活动名称',
- `activity_type` string COMMENT '活动类型',
- `start_time` string COMMENT '开始时间',
- `end_time` string COMMENT '结束时间',
- `create_time` string COMMENT '创建时间',
- `display_day_count` bigint COMMENT '当日曝光次数',
- `order_day_count` bigint COMMENT '当日下单次数',
- `order_day_amount` decimal(20,2) COMMENT '当日下单金额',
- `payment_day_count` bigint COMMENT '当日支付次数',
- `payment_day_amount` decimal(20,2) COMMENT '当日支付金额',
- `display_count` bigint COMMENT '累积曝光次数',
- `order_count` bigint COMMENT '累积下单次数',
- `order_amount` decimal(20,2) COMMENT '累积下单金额',
- `payment_count` bigint COMMENT '累积支付次数',
- `payment_amount` decimal(20,2) COMMENT '累积支付金额'
- ) COMMENT '活动主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_activity_topic/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- with
- tmp_op as
- (
- select
- activity_id,
- sum(if(date_format(create_time,'yyyy-MM-dd')='2020-06-14',1,0)) order_count,
- sum(if(date_format(create_time,'yyyy-MM-dd')='2020-06-14',final_total_amount,0)) order_amount,---统计14号的订单金额总额
- sum(if(date_format(payment_time,'yyyy-MM-dd')='2020-06-14',1,0)) payment_count,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='2020-06-14',final_total_amount,0)) payment_amount
- from dwd_fact_order_info
- where (dt='2020-06-14' or dt=date_add('2020-06-14',-1))
- and activity_id is not null --- 过滤没有参加活动的订单
- group by activity_id
- ),
- tmp_display as
- (
- select
- item activity_id,
- count(*) display_count
- from dwd_display_log
- where dt='2020-06-14'
- and item_type='activity_id'
- group by item
- ),
- tmp_activity as
- (
- select
- *
- from dwd_dim_activity_info
- where dt='2020-06-14'
- )
- insert overwrite table dws_activity_info_daycount partition(dt='2020-06-14')
- select
- nvl(tmp_op.activity_id,tmp_display.activity_id),
- tmp_activity.activity_name,
- tmp_activity.activity_type,
- tmp_activity.start_time,
- tmp_activity.end_time,
- tmp_activity.create_time,
- tmp_display.display_count,
- tmp_op.order_count,
- tmp_op.order_amount,
- tmp_op.payment_count,
- tmp_op.payment_amount
- from tmp_op
- full outer join tmp_display on tmp_op.activity_id=tmp_display.activity_id
- left join tmp_activity on nvl(tmp_op.activity_id,tmp_display.activity_id)=tmp_activity.id;
3)查询加载结果
hive (gmall)>
select * from dws_activity_info_daycount where dt='2020-06-14' limit 2
六十六.DWT_活动主题宽表

1)建表语句
- drop table if exists dwt_activity_topic;
- create external table dwt_activity_topic(
- `id` string COMMENT '编号',
- `activity_name` string COMMENT '活动名称',
- `activity_type` string COMMENT '活动类型',
- `start_time` string COMMENT '开始时间',
- `end_time` string COMMENT '结束时间',
- `create_time` string COMMENT '创建时间',
- `display_day_count` bigint COMMENT '当日曝光次数',
- `order_day_count` bigint COMMENT '当日下单次数',
- `order_day_amount` decimal(20,2) COMMENT '当日下单金额',
- `payment_day_count` bigint COMMENT '当日支付次数',
- `payment_day_amount` decimal(20,2) COMMENT '当日支付金额',
- `display_count` bigint COMMENT '累积曝光次数',
- `order_count` bigint COMMENT '累积下单次数',
- `order_amount` decimal(20,2) COMMENT '累积下单金额',
- `payment_count` bigint COMMENT '累积支付次数',
- `payment_amount` decimal(20,2) COMMENT '累积支付金额'
- ) COMMENT '活动主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_activity_topic/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- insert overwrite table dwt_activity_topic
- select
- nvl(new.id,old.id),
- nvl(new.activity_name,old.activity_name),
- nvl(new.activity_type,old.activity_type),
- nvl(new.start_time,old.start_time),
- nvl(new.end_time,old.end_time),
- nvl(new.create_time,old.create_time),
- nvl(new.display_count,0),
- nvl(new.order_count,0),
- nvl(new.order_amount,0.0),
- nvl(new.payment_count,0),
- nvl(new.payment_amount,0.0),
- nvl(new.display_count,0)+nvl(old.display_count,0),
- nvl(new.order_count,0)+nvl(old.order_count,0),
- nvl(new.order_amount,0.0)+nvl(old.order_amount,0.0),
- nvl(new.payment_count,0)+nvl(old.payment_count,0),
- nvl(new.payment_amount,0.0)+nvl(old.payment_amount,0.0)
- from
- (
- select
- *
- from dwt_activity_topic
- )old
- full outer join
- (
- select
- *
- from dws_activity_info_daycount
- where dt='2020-06-14'
- )new
- on old.id=new.id;
3)查询加载结果
hive (gmall)> select * from dwt_activity_topic limit 5;
六十七.DWS-DWT_地区主题表
1)建表语句
- drop table if exists dws_area_stats_daycount;
- create external table dws_area_stats_daycount(
- `id` bigint COMMENT '编号',
- `province_name` string COMMENT '省份名称',
- `area_code` string COMMENT '地区编码',
- `iso_code` string COMMENT 'iso编码',
- `region_id` string COMMENT '地区ID',
- `region_name` string COMMENT '地区名称',
- `login_count` string COMMENT '活跃设备数',
- `order_count` bigint COMMENT '下单次数',
- `order_amount` decimal(20,2) COMMENT '下单金额',
- `payment_count` bigint COMMENT '支付次数',
- `payment_amount` decimal(20,2) COMMENT '支付金额'
- ) COMMENT '每日地区统计表'
- PARTITIONED BY (`dt` string)
- stored as parquet
- location '/warehouse/gmall/dws/dws_area_stats_daycount/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- with
- tmp_login as
- (
- select
- area_code,
- count(*) login_count
- from dwd_start_log
- where dt='2020-06-14'
- group by area_code
- ),
- tmp_op as
- (
- select
- province_id,
- sum(if(date_format(create_time,'yyyy-MM-dd')='2020-06-14',1,0)) order_count,
- sum(if(date_format(create_time,'yyyy-MM-dd')='2020-06-14',final_total_amount,0)) order_amount,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='2020-06-14',1,0)) payment_count,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='2020-06-14',final_total_amount,0)) payment_amount
- from dwd_fact_order_info
- where (dt='2020-06-14' or dt=date_add('2020-06-14',-1))
- group by province_id
- )
- insert overwrite table dws_area_stats_daycount partition(dt='2020-06-14')
- select
- pro.id,
- pro.province_name,
- pro.area_code,
- pro.iso_code,
- pro.region_id,
- pro.region_name,
- nvl(tmp_login.login_count,0),
- nvl(tmp_op.order_count,0),
- nvl(tmp_op.order_amount,0.0),
- nvl(tmp_op.payment_count,0),
- nvl(tmp_op.payment_amount,0.0)
- from dwd_dim_base_province pro
- left join tmp_login on pro.area_code=tmp_login.area_code
- left join tmp_op on pro.id=tmp_op.province_id;
1)建表语句
- drop table if exists dwt_area_topic;
- create external table dwt_area_topic(
- `id` bigint COMMENT '编号',
- `province_name` string COMMENT '省份名称',
- `area_code` string COMMENT '地区编码',
- `iso_code` string COMMENT 'iso编码',
- `region_id` string COMMENT '地区ID',
- `region_name` string COMMENT '地区名称',
- `login_day_count` string COMMENT '当天活跃设备数',
- `login_last_30d_count` string COMMENT '最近30天活跃设备数',
- `order_day_count` bigint COMMENT '当天下单次数',
- `order_day_amount` decimal(16,2) COMMENT '当天下单金额',
- `order_last_30d_count` bigint COMMENT '最近30天下单次数',
- `order_last_30d_amount` decimal(16,2) COMMENT '最近30天下单金额',
- `payment_day_count` bigint COMMENT '当天支付次数',
- `payment_day_amount` decimal(16,2) COMMENT '当天支付金额',
- `payment_last_30d_count` bigint COMMENT '最近30天支付次数',
- `payment_last_30d_amount` decimal(16,2) COMMENT '最近30天支付金额'
- ) COMMENT '地区主题宽表'
- stored as parquet
- location '/warehouse/gmall/dwt/dwt_area_topic/'
- tblproperties ("parquet.compression"="lzo");
2)数据装载
- insert overwrite table dwt_area_topic
- select
- nvl(old.id,new.id),
- nvl(old.province_name,new.province_name),
- nvl(old.area_code,new.area_code),
- nvl(old.iso_code,new.iso_code),
- nvl(old.region_id,new.region_id),
- nvl(old.region_name,new.region_name),
- nvl(new.login_day_count,0),
- nvl(new.login_last_30d_count,0),
- nvl(new.order_day_count,0),
- nvl(new.order_day_amount,0.0),
- nvl(new.order_last_30d_count,0),
- nvl(new.order_last_30d_amount,0.0),
- nvl(new.payment_day_count,0),
- nvl(new.payment_day_amount,0.0),
- nvl(new.payment_last_30d_count,0),
- nvl(new.payment_last_30d_amount,0.0)
- from
- (
- select
- *
- from dwt_area_topic
- )old
- full outer join
- (
- select
- id,
- province_name,
- area_code,
- iso_code,
- region_id,
- region_name,
- sum(if(dt='2020-06-14',login_count,0)) login_day_count,
- sum(if(dt='2020-06-14',order_count,0)) order_day_count,
- sum(if(dt='2020-06-14',order_amount,0.0)) order_day_amount,
- sum(if(dt='2020-06-14',payment_count,0)) payment_day_count,
- sum(if(dt='2020-06-14',payment_amount,0.0)) payment_day_amount,
- sum(login_count) login_last_30d_count,
- sum(order_count) order_last_30d_count,
- sum(order_amount) order_last_30d_amount,
- sum(payment_count) payment_last_30d_count,
- sum(payment_amount) payment_last_30d_amount
- from dws_area_stats_daycount
- where dt>=date_add('2020-06-14',-30)
- group by id,province_name,area_code,iso_code,region_id,region_name
- )new
- on old.id=new.id;
3)查询加载结果
hive (gmall)> select * from dwt_area_topic limit 5;
六十八.DWS_DWT数据导入脚本
A.DWS数据导入脚本
1)在/home/atguigu/bin目录下创建脚本dwd_to_dws.sh
[atguigu@hadoop102 bin]$ vim dwd_to_dws.sh
- #!/bin/bash
- APP=gmall
- hive=/opt/module/hive/bin/hive
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$1" ] ;then
- do_date=$1
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql="
- set mapreduce.job.queuename=hive;
- with
- tmp_start as
- (
- select
- mid_id,
- brand,
- model,
- count(*) login_count
- from ${APP}.dwd_start_log
- where dt='$do_date'
- group by mid_id,brand,model
- ),
- tmp_page as
- (
- select
- mid_id,
- brand,
- model,
- collect_set(named_struct('page_id',page_id,'page_count',page_count)) page_stats
- from
- (
- select
- mid_id,
- brand,
- model,
- page_id,
- count(*) page_count
- from ${APP}.dwd_page_log
- where dt='$do_date'
- group by mid_id,brand,model,page_id
- )tmp
- group by mid_id,brand,model
- )
- insert overwrite table ${APP}.dws_uv_detail_daycount partition(dt='$do_date')
- select
- nvl(tmp_start.mid_id,tmp_page.mid_id),
- nvl(tmp_start.brand,tmp_page.brand),
- nvl(tmp_start.model,tmp_page.model),
- tmp_start.login_count,
- tmp_page.page_stats
- from tmp_start
- full outer join tmp_page
- on tmp_start.mid_id=tmp_page.mid_id
- and tmp_start.brand=tmp_page.brand
- and tmp_start.model=tmp_page.model;
- with
- tmp_login as
- (
- select
- user_id,
- count(*) login_count
- from ${APP}.dwd_start_log
- where dt='$do_date'
- and user_id is not null
- group by user_id
- ),
- tmp_cart as
- (
- select
- user_id,
- count(*) cart_count
- from ${APP}.dwd_action_log
- where dt='$do_date'
- and user_id is not null
- and action_id='cart_add'
- group by user_id
- ),tmp_order as
- (
- select
- user_id,
- count(*) order_count,
- sum(final_total_amount) order_amount
- from ${APP}.dwd_fact_order_info
- where dt='$do_date'
- group by user_id
- ) ,
- tmp_payment as
- (
- select
- user_id,
- count(*) payment_count,
- sum(payment_amount) payment_amount
- from ${APP}.dwd_fact_payment_info
- where dt='$do_date'
- group by user_id
- ),
- tmp_order_detail as
- (
- select
- user_id,
- collect_set(named_struct('sku_id',sku_id,'sku_num',sku_num,'order_count',order_count,'order_amount',order_amount)) order_stats
- from
- (
- select
- user_id,
- sku_id,
- sum(sku_num) sku_num,
- count(*) order_count,
- cast(sum(final_amount_d) as decimal(20,2)) order_amount
- from ${APP}.dwd_fact_order_detail
- where dt='$do_date'
- group by user_id,sku_id
- )tmp
- group by user_id
- )
- insert overwrite table ${APP}.dws_user_action_daycount partition(dt='$do_date')
- select
- tmp_login.user_id,
- login_count,
- nvl(cart_count,0),
- nvl(order_count,0),
- nvl(order_amount,0.0),
- nvl(payment_count,0),
- nvl(payment_amount,0.0),
- order_stats
- from tmp_login
- left outer join tmp_cart on tmp_login.user_id=tmp_cart.user_id
- left outer join tmp_order on tmp_login.user_id=tmp_order.user_id
- left outer join tmp_payment on tmp_login.user_id=tmp_payment.user_id
- left outer join tmp_order_detail on tmp_login.user_id=tmp_order_detail.user_id;
- with
- tmp_order as
- (
- select
- sku_id,
- count(*) order_count,
- sum(sku_num) order_num,
- sum(final_amount_d) order_amount
- from ${APP}.dwd_fact_order_detail
- where dt='$do_date'
- group by sku_id
- ),
- tmp_payment as
- (
- select
- sku_id,
- count(*) payment_count,
- sum(sku_num) payment_num,
- sum(final_amount_d) payment_amount
- from ${APP}.dwd_fact_order_detail
- where dt='$do_date'
- and order_id in
- (
- select
- id
- from ${APP}.dwd_fact_order_info
- where (dt='$do_date'
- or dt=date_add('$do_date',-1))
- and date_format(payment_time,'yyyy-MM-dd')='$do_date'
- )
- group by sku_id
- ),
- tmp_refund as
- (
- select
- sku_id,
- count(*) refund_count,
- sum(refund_num) refund_num,
- sum(refund_amount) refund_amount
- from ${APP}.dwd_fact_order_refund_info
- where dt='$do_date'
- group by sku_id
- ),
- tmp_cart as
- (
- select
- item sku_id,
- count(*) cart_count
- from ${APP}.dwd_action_log
- where dt='$do_date'
- and user_id is not null
- and action_id='cart_add'
- group by item
- ),tmp_favor as
- (
- select
- item sku_id,
- count(*) favor_count
- from ${APP}.dwd_action_log
- where dt='$do_date'
- and user_id is not null
- and action_id='favor_add'
- group by item
- ),
- tmp_appraise as
- (
- select
- sku_id,
- sum(if(appraise='1201',1,0)) appraise_good_count,
- sum(if(appraise='1202',1,0)) appraise_mid_count,
- sum(if(appraise='1203',1,0)) appraise_bad_count,
- sum(if(appraise='1204',1,0)) appraise_default_count
- from ${APP}.dwd_fact_comment_info
- where dt='$do_date'
- group by sku_id
- )
- insert overwrite table ${APP}.dws_sku_action_daycount partition(dt='$do_date')
- select
- sku_id,
- sum(order_count),
- sum(order_num),
- sum(order_amount),
- sum(payment_count),
- sum(payment_num),
- sum(payment_amount),
- sum(refund_count),
- sum(refund_num),
- sum(refund_amount),
- sum(cart_count),
- sum(favor_count),
- sum(appraise_good_count),
- sum(appraise_mid_count),
- sum(appraise_bad_count),
- sum(appraise_default_count)
- from
- (
- select
- sku_id,
- order_count,
- order_num,
- order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_order
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- payment_count,
- payment_num,
- payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_payment
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- refund_count,
- refund_num,
- refund_amount,
- 0 cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_refund
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- cart_count,
- 0 favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_cart
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- favor_count,
- 0 appraise_good_count,
- 0 appraise_mid_count,
- 0 appraise_bad_count,
- 0 appraise_default_count
- from tmp_favor
- union all
- select
- sku_id,
- 0 order_count,
- 0 order_num,
- 0 order_amount,
- 0 payment_count,
- 0 payment_num,
- 0 payment_amount,
- 0 refund_count,
- 0 refund_num,
- 0 refund_amount,
- 0 cart_count,
- 0 favor_count,
- appraise_good_count,
- appraise_mid_count,
- appraise_bad_count,
- appraise_default_count
- from tmp_appraise
- )tmp
- group by sku_id;
- with
- tmp_login as
- (
- select
- area_code,
- count(*) login_count
- from ${APP}.dwd_start_log
- where dt='$do_date'
- group by area_code
- ),
- tmp_op as
- (
- select
- province_id,
- sum(if(date_format(create_time,'yyyy-MM-dd')='$do_date',1,0)) order_count,
- sum(if(date_format(create_time,'yyyy-MM-dd')='$do_date',final_total_amount,0)) order_amount,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='$do_date',1,0)) payment_count,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='$do_date',final_total_amount,0)) payment_amount
- from ${APP}.dwd_fact_order_info
- where (dt='$do_date' or dt=date_add('$do_date',-1))
- group by province_id
- )
- insert overwrite table ${APP}.dws_area_stats_daycount partition(dt='$do_date')
- select
- pro.id,
- pro.province_name,
- pro.area_code,
- pro.iso_code,
- pro.region_id,
- pro.region_name,
- nvl(tmp_login.login_count,0),
- nvl(tmp_op.order_count,0),
- nvl(tmp_op.order_amount,0.0),
- nvl(tmp_op.payment_count,0),
- nvl(tmp_op.payment_amount,0.0)
- from ${APP}.dwd_dim_base_province pro
- left join tmp_login on pro.area_code=tmp_login.area_code
- left join tmp_op on pro.id=tmp_op.province_id;
- with
- tmp_op as
- (
- select
- activity_id,
- sum(if(date_format(create_time,'yyyy-MM-dd')='$do_date',1,0)) order_count,
- sum(if(date_format(create_time,'yyyy-MM-dd')='$do_date',final_total_amount,0)) order_amount,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='$do_date',1,0)) payment_count,
- sum(if(date_format(payment_time,'yyyy-MM-dd')='$do_date',final_total_amount,0)) payment_amount
- from ${APP}.dwd_fact_order_info
- where (dt='$do_date' or dt=date_add('$do_date',-1))
- and activity_id is not null
- group by activity_id
- ),
- tmp_display as
- (
- select
- item activity_id,
- count(*) display_count
- from ${APP}.dwd_display_log
- where dt='$do_date'
- and item_type='activity_id'
- group by item
- ),
- tmp_activity as
- (
- select
- *
- from ${APP}.dwd_dim_activity_info
- where dt='$do_date'
- )
- insert overwrite table ${APP}.dws_activity_info_daycount partition(dt='$do_date')
- select
- nvl(tmp_op.activity_id,tmp_display.activity_id),
- tmp_activity.activity_name,
- tmp_activity.activity_type,
- tmp_activity.start_time,
- tmp_activity.end_time,
- tmp_activity.create_time,
- tmp_display.display_count,
- tmp_op.order_count,
- tmp_op.order_amount,
- tmp_op.payment_count,
- tmp_op.payment_amount
- from tmp_op
- full outer join tmp_display on tmp_op.activity_id=tmp_display.activity_id
- left join tmp_activity on nvl(tmp_op.activity_id,tmp_display.activity_id)=tmp_activity.id;
- "
- $hive -e "$sql"
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 dwd_to_dws.sh3)执行脚本导入数据
[atguigu@hadoop102 bin]$ dwd_to_dws.sh 2020-06-154)查看导入数据
hive (gmall)>
select * from dws_uv_detail_daycount where dt='2020-06-15' limit 2;
select * from dws_user_action_daycount where dt='2020-06-15' limit 2;
select * from dws_sku_action_daycount where dt='2020-06-15' limit 2;
select * from dws_activity_info_daycount where dt='2020-06-15' limit 2;
select * from dws_area_stats_daycount where dt='2020-06-15' limit 2;B.DWT数据导入脚本
1)在/home/atguigu/bin目录下创建脚本dws_to_dwt.sh
[atguigu@hadoop102 bin]$ vim dws_to_dwt.sh
- #!/bin/bash
- APP=gmall
- hive=/opt/module/hive/bin/hive
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$1" ] ;then
- do_date=$1
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql="
- set mapreduce.job.queuename=hive;
- insert overwrite table ${APP}.dwt_uv_topic
- select
- nvl(new.mid_id,old.mid_id),
- nvl(new.model,old.model),
- nvl(new.brand,old.brand),
- if(old.mid_id is null,'$do_date',old.login_date_first),
- if(new.mid_id is not null,'$do_date',old.login_date_last),
- if(new.mid_id is not null, new.login_count,0),
- nvl(old.login_count,0)+if(new.login_count>0,1,0)
- from
- (
- select
- *
- from ${APP}.dwt_uv_topic
- )old
- full outer join
- (
- select
- *
- from ${APP}.dws_uv_detail_daycount
- where dt='$do_date'
- )new
- on old.mid_id=new.mid_id;
- insert overwrite table ${APP}.dwt_user_topic
- select
- nvl(new.user_id,old.user_id),
- if(old.login_date_first is null and new.login_count>0,'$do_date',old.login_date_first),
- if(new.login_count>0,'$do_date',old.login_date_last),
- nvl(old.login_count,0)+if(new.login_count>0,1,0),
- nvl(new.login_last_30d_count,0),
- if(old.order_date_first is null and new.order_count>0,'$do_date',old.order_date_first),
- if(new.order_count>0,'$do_date',old.order_date_last),
- nvl(old.order_count,0)+nvl(new.order_count,0),
- nvl(old.order_amount,0)+nvl(new.order_amount,0),
- nvl(new.order_last_30d_count,0),
- nvl(new.order_last_30d_amount,0),
- if(old.payment_date_first is null and new.payment_count>0,'$do_date',old.payment_date_first),
- if(new.payment_count>0,'$do_date',old.payment_date_last),
- nvl(old.payment_count,0)+nvl(new.payment_count,0),
- nvl(old.payment_amount,0)+nvl(new.payment_amount,0),
- nvl(new.payment_last_30d_count,0),
- nvl(new.payment_last_30d_amount,0)
- from
- ${APP}.dwt_user_topic old
- full outer join
- (
- select
- user_id,
- sum(if(dt='$do_date',login_count,0)) login_count,
- sum(if(dt='$do_date',order_count,0)) order_count,
- sum(if(dt='$do_date',order_amount,0)) order_amount,
- sum(if(dt='$do_date',payment_count,0)) payment_count,
- sum(if(dt='$do_date',payment_amount,0)) payment_amount,
- sum(if(login_count>0,1,0)) login_last_30d_count,
- sum(order_count) order_last_30d_count,
- sum(order_amount) order_last_30d_amount,
- sum(payment_count) payment_last_30d_count,
- sum(payment_amount) payment_last_30d_amount
- from ${APP}.dws_user_action_daycount
- where dt>=date_add( '$do_date',-30)
- group by user_id
- )new
- on old.user_id=new.user_id;
- insert overwrite table ${APP}.dwt_sku_topic
- select
- nvl(new.sku_id,old.sku_id),
- sku_info.spu_id,
- nvl(new.order_count30,0),
- nvl(new.order_num30,0),
- nvl(new.order_amount30,0),
- nvl(old.order_count,0) + nvl(new.order_count,0),
- nvl(old.order_num,0) + nvl(new.order_num,0),
- nvl(old.order_amount,0) + nvl(new.order_amount,0),
- nvl(new.payment_count30,0),
- nvl(new.payment_num30,0),
- nvl(new.payment_amount30,0),
- nvl(old.payment_count,0) + nvl(new.payment_count,0),
- nvl(old.payment_num,0) + nvl(new.payment_count,0),
- nvl(old.payment_amount,0) + nvl(new.payment_count,0),
- nvl(new.refund_count30,0),
- nvl(new.refund_num30,0),
- nvl(new.refund_amount30,0),
- nvl(old.refund_count,0) + nvl(new.refund_count,0),
- nvl(old.refund_num,0) + nvl(new.refund_num,0),
- nvl(old.refund_amount,0) + nvl(new.refund_amount,0),
- nvl(new.cart_count30,0),
- nvl(old.cart_count,0) + nvl(new.cart_count,0),
- nvl(new.favor_count30,0),
- nvl(old.favor_count,0) + nvl(new.favor_count,0),
- nvl(new.appraise_good_count30,0),
- nvl(new.appraise_mid_count30,0),
- nvl(new.appraise_bad_count30,0),
- nvl(new.appraise_default_count30,0) ,
- nvl(old.appraise_good_count,0) + nvl(new.appraise_good_count,0),
- nvl(old.appraise_mid_count,0) + nvl(new.appraise_mid_count,0),
- nvl(old.appraise_bad_count,0) + nvl(new.appraise_bad_count,0),
- nvl(old.appraise_default_count,0) + nvl(new.appraise_default_count,0)
- from
- (
- select
- sku_id,
- spu_id,
- order_last_30d_count,
- order_last_30d_num,
- order_last_30d_amount,
- order_count,
- order_num,
- order_amount ,
- payment_last_30d_count,
- payment_last_30d_num,
- payment_last_30d_amount,
- payment_count,
- payment_num,
- payment_amount,
- refund_last_30d_count,
- refund_last_30d_num,
- refund_last_30d_amount,
- refund_count,
- refund_num,
- refund_amount,
- cart_last_30d_count,
- cart_count,
- favor_last_30d_count,
- favor_count,
- appraise_last_30d_good_count,
- appraise_last_30d_mid_count,
- appraise_last_30d_bad_count,
- appraise_last_30d_default_count,
- appraise_good_count,
- appraise_mid_count,
- appraise_bad_count,
- appraise_default_count
- from ${APP}.dwt_sku_topic
- )old
- full outer join
- (
- select
- sku_id,
- sum(if(dt='$do_date', order_count,0 )) order_count,
- sum(if(dt='$do_date',order_num ,0 )) order_num,
- sum(if(dt='$do_date',order_amount,0 )) order_amount ,
- sum(if(dt='$do_date',payment_count,0 )) payment_count,
- sum(if(dt='$do_date',payment_num,0 )) payment_num,
- sum(if(dt='$do_date',payment_amount,0 )) payment_amount,
- sum(if(dt='$do_date',refund_count,0 )) refund_count,
- sum(if(dt='$do_date',refund_num,0 )) refund_num,
- sum(if(dt='$do_date',refund_amount,0 )) refund_amount,
- sum(if(dt='$do_date',cart_count,0 )) cart_count,
- sum(if(dt='$do_date',favor_count,0 )) favor_count,
- sum(if(dt='$do_date',appraise_good_count,0 )) appraise_good_count,
- sum(if(dt='$do_date',appraise_mid_count,0 ) ) appraise_mid_count ,
- sum(if(dt='$do_date',appraise_bad_count,0 )) appraise_bad_count,
- sum(if(dt='$do_date',appraise_default_count,0 )) appraise_default_count,
- sum(order_count) order_count30 ,
- sum(order_num) order_num30,
- sum(order_amount) order_amount30,
- sum(payment_count) payment_count30,
- sum(payment_num) payment_num30,
- sum(payment_amount) payment_amount30,
- sum(refund_count) refund_count30,
- sum(refund_num) refund_num30,
- sum(refund_amount) refund_amount30,
- sum(cart_count) cart_count30,
- sum(favor_count) favor_count30,
- sum(appraise_good_count) appraise_good_count30,
- sum(appraise_mid_count) appraise_mid_count30,
- sum(appraise_bad_count) appraise_bad_count30,
- sum(appraise_default_count) appraise_default_count30
- from ${APP}.dws_sku_action_daycount
- where dt >= date_add ('$do_date', -30)
- group by sku_id
- )new
- on new.sku_id = old.sku_id
- left join
- (select * from ${APP}.dwd_dim_sku_info where dt='$do_date') sku_info
- on nvl(new.sku_id,old.sku_id)= sku_info.id;
- insert overwrite table ${APP}.dwt_activity_topic
- select
- nvl(new.id,old.id),
- nvl(new.activity_name,old.activity_name),
- nvl(new.activity_type,old.activity_type),
- nvl(new.start_time,old.start_time),
- nvl(new.end_time,old.end_time),
- nvl(new.create_time,old.create_time),
- nvl(new.display_count,0),
- nvl(new.order_count,0),
- nvl(new.order_amount,0.0),
- nvl(new.payment_count,0),
- nvl(new.payment_amount,0.0),
- nvl(new.display_count,0)+nvl(old.display_count,0),
- nvl(new.order_count,0)+nvl(old.order_count,0),
- nvl(new.order_amount,0.0)+nvl(old.order_amount,0.0),
- nvl(new.payment_count,0)+nvl(old.payment_count,0),
- nvl(new.payment_amount,0.0)+nvl(old.payment_amount,0.0)
- from
- (
- select
- *
- from ${APP}.dwt_activity_topic
- )old
- full outer join
- (
- select
- *
- from ${APP}.dws_activity_info_daycount
- where dt='$do_date'
- )new
- on old.id=new.id;
- insert overwrite table ${APP}.dwt_area_topic
- select
- nvl(old.id,new.id),
- nvl(old.province_name,new.province_name),
- nvl(old.area_code,new.area_code),
- nvl(old.iso_code,new.iso_code),
- nvl(old.region_id,new.region_id),
- nvl(old.region_name,new.region_name),
- nvl(new.login_day_count,0),
- nvl(new.login_last_30d_count,0),
- nvl(new.order_day_count,0),
- nvl(new.order_day_amount,0.0),
- nvl(new.order_last_30d_count,0),
- nvl(new.order_last_30d_amount,0.0),
- nvl(new.payment_day_count,0),
- nvl(new.payment_day_amount,0.0),
- nvl(new.payment_last_30d_count,0),
- nvl(new.payment_last_30d_amount,0.0)
- from
- (
- select
- *
- from ${APP}.dwt_area_topic
- )old
- full outer join
- (
- select
- id,
- province_name,
- area_code,
- iso_code,
- region_id,
- region_name,
- sum(if(dt='$do_date',login_count,0)) login_day_count,
- sum(if(dt='$do_date',order_count,0)) order_day_count,
- sum(if(dt='$do_date',order_amount,0.0)) order_day_amount,
- sum(if(dt='$do_date',payment_count,0)) payment_day_count,
- sum(if(dt='$do_date',payment_amount,0.0)) payment_day_amount,
- sum(login_count) login_last_30d_count,
- sum(order_count) order_last_30d_count,
- sum(order_amount) order_last_30d_amount,
- sum(payment_count) payment_last_30d_count,
- sum(payment_amount) payment_last_30d_amount
- from ${APP}.dws_area_stats_daycount
- where dt>=date_add('$do_date',-30)
- group by id,province_name,area_code,iso_code,region_id,region_name
- )new
- on old.id=new.id;
- "
- $hive -e "$sql"
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 dws_to_dwt.sh
3)执行脚本导入数据
[atguigu@hadoop102 bin]$ dws_to_dwt.sh 2020-06-15
4)查看导入数据
hive (gmall)>
select * from dwt_uv_topic limit 5;
select * from dwt_user_topic limit 5;
select * from dwt_sku_topic limit 5;
select * from dwt_activity_topic limit 5;
select * from dwt_area_topic limit 5;六十九.ADS_设备主体_活跃设备---这里的方案是很多的
需求定义:
日活:当日活跃的设备数
周活:当周活跃的设备数
月活:当月活跃的设备数1)建表语句
- drop table if exists ads_uv_count;
- create external table ads_uv_count(
- `dt` string COMMENT '统计日期',
- `day_count` bigint COMMENT '当日用户数量',
- `wk_count` bigint COMMENT '当周用户数量',
- `mn_count` bigint COMMENT '当月用户数量',
- `is_weekend` string COMMENT 'Y,N是否是周末,用于得到本周最终结果',
- `is_monthend` string COMMENT 'Y,N是否是月末,用于得到本月最终结果'
- ) COMMENT '活跃设备数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_uv_count/';
2)导入数据
- insert into table ads_uv_count
- select
- '2020-06-14' dt,
- daycount.ct,
- wkcount.ct,
- mncount.ct,
- if(date_add(next_day('2020-06-14','MO'),-1)='2020-06-14','Y','N') ,
- if(last_day('2020-06-14')='2020-06-14','Y','N')
- from
- (
- select
- '2020-06-14' dt,
- count(*) ct
- from dwt_uv_topic
- where login_date_last='2020-06-14'
- )daycount join
- (
- select
- '2020-06-14' dt,
- count (*) ct
- from dwt_uv_topic
- where login_date_last>=date_add(next_day('2020-06-14','MO'),-7)
- and login_date_last<= date_add(next_day('2020-06-14','MO'),-1)
- ) wkcount on daycount.dt=wkcount.dt
- join
- (
- select
- '2020-06-14' dt,
- count (*) ct
- from dwt_uv_topic
- where date_format(login_date_last,'yyyy-MM')=date_format('2020-06-14','yyyy-MM')
- )mncount on daycount.dt=mncount.dt;
下面的代码是老师上课讲的
- insert into table ads_uv_count
- select
- '2020-06-15'
- sum(if(login_date_last='2020-06-15',1,0)),
- sum(if(login_date_last>=date_add(next_day('2020-06-14','MO'),-7) and login_date_last <=date_add(next_day('2020-06-14','MO'),-1) )),
- sum(if(date_format(login_date_last,'yyyy-MM')=date_format('2020-06-15','yyyy-MM'),1,0)),
- if('2020-06-15'=date_add(next_day('2020-06-14','MO'),-7),'Y','N'),
- if('2020-06-15'=last_day('2020-06-14','Y','N'),
- from dwt_uv_topic;
在ads层导入的数据是只有一天的,数据量是比较少的,只有一条数据,就没有必要进行压缩和列式存储了,我们在往mysql之中进行导入的时候,只能够进行全表导入。这个地方是不能够使用overwrite,因为没有进行相应的分区,如果要是使用了overwrite就会导致每天只有一张最新的表。因此,这里改成了insert into。
七十.ADS_每日新增设备进行导入
1)建表语句
- drop table if exists ads_new_mid_count;
- create external table ads_new_mid_count
- (
- `create_date` string comment '创建时间' ,
- `new_mid_count` BIGINT comment '新增设备数量'
- ) COMMENT '每日新增设备数量'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_new_mid_count/';
2)导入数据
- insert into table ads_new_mid_count
- select
- '2020-06-14',
- count(*)
- from dwt_uv_topic
- where login_date_first='2020-06-14';
七十一.ADS_沉默用户
需求定义:
沉默用户:只在安装当天启动过,且启动时间是在7天前1)建表语句
- drop table if exists ads_silent_count;
- create external table ads_silent_count(
- `dt` string COMMENT '统计日期',
- `silent_count` bigint COMMENT '沉默设备数'
- ) COMMENT '沉默用户数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_silent_count';
2)导入2020-06-25数据
- insert into table ads_silent_count
- select
- '2020-06-25',
- count(*)
- from dwt_uv_topic
- where login_date_first=login_date_last
- and login_date_last<=date_add('2020-06-25',-7);
七十二.多表join出现的问题_使用COALESCE函数解决
- full outer join b on a.id=b.id
- full outer join c on a.id=c.id
- full outer join d on a.id=d.id
- full outer join e on a.id=e.id

上面的表在进行相应的join的时候,是存在一定的问题的使用nvl只能够判断二者之间,因此这里提出使用COALESCE函数进行解决。因此,这里的多表进行全外联的写法是如下所示:
- full outer join b on a.id=b.id
- full outer join c on nvl(a.id,b.id)=c.id
- full outer join d on coalesce(a.id,b.id,c.id)=d.id
- full outer join e on coalesce(a.id,b.id,c.id,d.id)=e.id
(回宿舍去吃饭)
七十三.ADS_设备主题_留存

留存用户:某段时间内新增用户(活跃用户),经过一段时间后,又继续使用应用的被认作是留存用户
留存率:留存用户占当时新增用户(活跃用户的比例)就是留存率.在算取相应的留存率的时候:
--- 2020-06-15 的 1 日 留存率
--- 2020-06-15 的 新增
--- 2020-06-16 的 活跃 ---- 2020-06-17得到--- 2020-06-15 的 2 日 留存率
--- 2020-06-15 的 新增
--- 2020-06-17 的 活跃 ---- 2020-06-18得到--- 2020-06-15 的 3 日 留存率
--- 2020-06-15 的 新增
--- 2020-06-18 的 活跃 ---- 2020-06-19得到--- 2020-06-19 的 计算任务是什么?
--- 2020-06-15 的 3 日 留存率
--- 2020-06-16 的 2 日 留存率
--- 2020-06-17 的 1 日 留存率1)建表语句
- drop table if exists ads_user_retention_day_rate;
- create external table ads_user_retention_day_rate
- (
- `stat_date` string comment '统计日期',
- `create_date` string comment '设备新增日期',
- `retention_day` int comment '截止当前日期留存天数',
- `retention_count` bigint comment '留存数量',
- `new_mid_count` bigint comment '设备新增数量',
- `retention_ratio` decimal(16,2) comment '留存率'
- ) COMMENT '留存率'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_user_retention_day_rate/';
2)导入数据
- insert into table ads_user_retention_day_rate
- select
- '2020-06-15',
- date_add('2020-06-15',-1),
- 1,--留存天数
- sum(if(login_date_first=date_add('2020-06-15',-1) and login_date_last='2020-06-15',1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-1),1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-1) and login_date_last='2020-06-15',1,0))/sum(if(login_date_first=date_add('2020-06-15',-1),1,0))*100
- from dwt_uv_topic
- union all
- select
- '2020-06-15',
- date_add('2020-06-15',-2),
- 2,
- sum(if(login_date_first=date_add('2020-06-15',-2) and login_date_last='2020-06-15',1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-2),1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-2) and login_date_last='2020-06-15',1,0))/sum(if(login_date_first=date_add('2020-06-15',-2),1,0))*100
- from dwt_uv_topic
- union all
- select
- '2020-06-15',
- date_add('2020-06-15',-3),
- 3,
- sum(if(login_date_first=date_add('2020-06-15',-3) and login_date_last='2020-06-15',1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-3),1,0)),
- sum(if(login_date_first=date_add('2020-06-15',-3) and login_date_last='2020-06-15',1,0))/sum(if(login_date_first=date_add('2020-06-15',-3),1,0))*100
- from dwt_uv_topic;
3)查询导入数据
hive (gmall)>select * from ads_user_retention_day_rate;
七十四.ADS_设备主题_本周回流
本周回流用户:上周未活跃,本周活跃的设备,且不是本周新增设备
1)建表语句- drop table if exists ads_back_count;
- create external table ads_back_count(
- `dt` string COMMENT '统计日期',
- `wk_dt` string COMMENT '统计日期所在周',
- `wastage_count` bigint COMMENT '回流设备数'
- ) COMMENT '本周回流用户数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_back_count';
2)导入数据
首先拿到本周活跃的数据,
第二件事是将本周新增的数据进行过滤---使用一个and操作,就是将第一天进行登陆的人进行直接的删除掉,
第三件事取出上周活跃,使用join的操作,就是二者之间有重合的部分(本周活跃,上周没有活跃的部分),本周left join上周null- select
- mid_id
- from dwt_uv_detail_daycount
- where dt>=date_add(next_day('2020-06-25','MO'),-7*2)
- and dt<= date_add(next_day('2020-06-25','MO'),-7-1)
假如有一个设备上周活跃了,本周也活跃了,那么login_date_last是本周了,因此下面的这段代码实现上周活跃是不可以的,只能够使用相应的dws进行实验.
- insert into table ads_back_count
- select
- '2020-06-25',
- concat(date_add(next_day('2020-06-25','MO'),-7),'_', date_add(next_day('2020-06-25','MO'),-1)),
- count(*)
- from
- (
- select
- mid_id
- from dwt_uv_topic
- where login_date_last>=date_add(next_day('2020-06-25','MO'),-7)
- and login_date_last<= date_add(next_day('2020-06-25','MO'),-1)
- and login_date_first<date_add(next_day('2020-06-25','MO'),-7)
- )current_wk
- left join
- (
- select
- mid_id
- from dws_uv_detail_daycount
- where dt>=date_add(next_day('2020-06-25','MO'),-7*2)
- and dt<= date_add(next_day('2020-06-25','MO'),-7-1)
- group by mid_id -----进行相应的去重
- )last_wk
- on current_wk.mid_id=last_wk.mid_id
- where last_wk.mid_id is null;
知道如上的代码可以得到相应的上周为null的代码.
3)查询结果
hive (gmall)> select * from ads_back_count;
七十五.ADS_设备主题_流失用户数
流失用户:最近7天未活跃的设备-------最后一次活跃在七天前
1)建表语句
- drop table if exists ads_wastage_count;
- create external table ads_wastage_count(
- `dt` string COMMENT '统计日期',
- `wastage_count` bigint COMMENT '流失设备数'
- ) COMMENT '流失用户数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_wastage_count';
2)导入2020-06-25数据
- insert into table ads_wastage_count
- select
- '2020-06-25',
- count(*)
- from
- (
- select
- mid_id
- from dwt_uv_topic
- where login_date_last<=date_add('2020-06-25',-7)
- group by mid_id
- )t1;
3)查询结果
hive (gmall)> select * from ads_wastage_count;
七十六.Hiveserver2_heap_size
出现java.lang.OutOfMemoryError的问题.
需要进到hive/conf目录下面,在这个目录的下方有一个hive-env.sh.template
$ mv hive-env.sh.template hive-env.sh --- 使得这个脚本生效
去重使用union,不去重就用union all,多个表使用union进行连接,就当成是一个select就可以的.
(回宿舍恰觉)
真的无语了,宿舍有阳性了,封在宿舍已经四天了,什么也没有干,玩了四天,好愧疚.
七十七.ADS_设备主题_最近三周连续活跃
1.建表语句
- drop table if exists ads_continuity_wk_count;
- create external table ads_continuity_wk_count(
- `dt` string COMMENT '统计日期,一般用结束周周日日期,如果每天计算一次,可用当天日期',
- `wk_dt` string COMMENT '持续时间',
- `continuity_count` bigint COMMENT '活跃次数'
- ) COMMENT '最近连续三周活跃用户数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_continuity_wk_count';
2.导入数据
注意下面的连接方法是使用的union all的方式进行连接.最后的判断是使用having进行条件截取,where是过滤的一行一样的数据,having进行过滤的是分完组之后的组.
- insert into table ads_continuity_wk_count
- select
- '2020-06-25',
- concat(date_add(next_day('2020-06-25','MO'),-7*3),'_',date_add(next_day('2020-06-25','MO'),-1)),
- count(*)
- from
- (
- select
- mid_id
- from
- (
- select
- mid_id
- from dws_uv_detail_daycount
- where dt>=date_add(next_day('2020-06-25','monday'),-7)
- and dt<=date_add(next_day('2020-06-25','monday'),-1)
- group by mid_id
- union all
- select
- mid_id
- from dws_uv_detail_daycount
- where dt>=date_add(next_day('2020-06-25','monday'),-7*2)
- and dt<=date_add(next_day('2020-06-25','monday'),-7-1)
- group by mid_id
- union all
- select
- mid_id
- from dws_uv_detail_daycount
- where dt>=date_add(next_day('2020-06-25','monday'),-7*3)
- and dt<=date_add(next_day('2020-06-25','monday'),-7*2-1)
- group by mid_id
- )t1
- group by mid_id
- having count(*)=3
- )t2;
七十八.ADS_设备主题_最近七天连续三天的活跃次数
1.建表语句
- drop table if exists ads_continuity_uv_count;
- create external table ads_continuity_uv_count(
- `dt` string COMMENT '统计日期',
- `wk_dt` string COMMENT '最近7天日期',
- `continuity_count` bigint
- ) COMMENT '最近七天内连续三天活跃用户数'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_continuity_uv_count';
2.导入数据
下面应当注意的是写的思路.

特别注意上面的rank()函数的使用
- insert into table ads_continuity_uv_count
- select
- '2020-06-16',
- concat(date_add('2020-06-16',-6),'_','2020-06-16'),
- count(*)
- from
- (
- select mid_id
- from
- (
- select mid_id
- from
- (
- select
- mid_id,
- date_sub(dt,rank) date_dif
- from
- (
- select
- mid_id,
- dt,
- rank() over(partition by mid_id order by dt) rank--进行一个开窗处理
- from dws_uv_detail_daycount
- where dt>=date_add('2020-06-16',-6) and dt<='2020-06-16'
- )t1
- )t2
- group by mid_id,date_dif
- having count(*)>=3
- )t3
- group by mid_id
- )t4;
第二种思路:使用下面两行进行相减的过程.

只要能够找到一个差值为2的数据,就是说明是正常的.
七十九.ADS_会员主题信息表
1.建表语句
- drop table if exists ads_user_topic;
- create external table ads_user_topic(
- `dt` string COMMENT '统计日期',
- `day_users` string COMMENT '活跃会员数',
- `day_new_users` string COMMENT '新增会员数',
- `day_new_payment_users` string COMMENT '新增消费会员数',
- `payment_users` string COMMENT '总付费会员数',
- `users` string COMMENT '总会员数',
- `day_users2users` decimal(16,2) COMMENT '会员活跃率',
- `payment_users2users` decimal(16,2) COMMENT '会员付费率',
- `day_new_users2users` decimal(16,2) COMMENT '会员新鲜度'
- ) COMMENT '会员信息表'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_user_topic';
会员新鲜度是指当日的新增会员除以活跃会员数目.
2.导入数据
- insert into table ads_user_topic
- select
- '2020-06-14',
- sum(if(login_date_last='2020-06-14',1,0)),
- sum(if(login_date_first='2020-06-14',1,0)),
- sum(if(payment_date_first='2020-06-14',1,0)),
- sum(if(payment_count>0,1,0)),
- count(*),
- sum(if(login_date_last='2020-06-14',1,0))/count(*),
- sum(if(payment_count>0,1,0))/count(*),
- sum(if(login_date_first='2020-06-14',1,0))/sum(if(login_date_last='2020-06-14',1,0))
- from dwt_user_topic;
八十.ADS_漏斗分析
统计“浏览首页->浏览商品详情页->加入购物车->下单->支付”的转化率
思路:统计各个行为的人数,然后计算比值。
1.建表语句
- drop table if exists ads_user_action_convert_day;
- create external table ads_user_action_convert_day(
- `dt` string COMMENT '统计日期',
- `home_count` bigint COMMENT '浏览首页人数',
- `good_detail_count` bigint COMMENT '浏览商品详情页人数',
- `home2good_detail_convert_ratio` decimal(16,2) COMMENT '首页到商品详情转化率',
- `cart_count` bigint COMMENT '加入购物车的人数',
- `good_detail2cart_convert_ratio` decimal(16,2) COMMENT '商品详情页到加入购物车转化率',
- `order_count` bigint COMMENT '下单人数',
- `cart2order_convert_ratio` decimal(16,2) COMMENT '加入购物车到下单转化率',
- `payment_amount` bigint COMMENT '支付人数',
- `order2payment_convert_ratio` decimal(16,2) COMMENT '下单到支付的转化率'
- ) COMMENT '漏斗分析'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_user_action_convert_day/';
浏览首页和浏览商品详情页是使用相应的设备id进行统计.这里的加入购物车有的是需要登陆的,有的是不需要登陆的.
2.导入数据
平时使用union更加好一些,要是使用join它的效率是比较低的.
- with
- tmp_uv as
- (
- select
- '2020-06-14' dt,
- sum(if(array_contains(pages,'home'),1,0)) home_count,---使用了一个数组,并且进行判断相应的信息是否在这个里面
- sum(if(array_contains(pages,'good_detail'),1,0)) good_detail_count
- from
- (
- select
- mid_id,
- collect_set(page_id) pages---聚合函数,进行一个分组
- from dwd_page_log
- where dt='2020-06-14'
- and page_id in ('home','good_detail')---首页和商品详情页面
- group by mid_id
- )tmp
- ),
- tmp_cop as
- (
- select
- '2020-06-14' dt,
- sum(if(cart_count>0,1,0)) cart_count,
- sum(if(order_count>0,1,0)) order_count,
- sum(if(payment_count>0,1,0)) payment_count
- from dws_user_action_daycount
- where dt='2020-06-14'
- )
- insert into table ads_user_action_convert_day
- select
- tmp_uv.dt,
- tmp_uv.home_count,
- tmp_uv.good_detail_count,
- tmp_uv.good_detail_count/tmp_uv.home_count*100,
- tmp_cop.cart_count,
- tmp_cop.cart_count/tmp_uv.good_detail_count*100,
- tmp_cop.order_count,
- tmp_cop.order_count/tmp_cop.cart_count*100,
- tmp_cop.payment_count,
- tmp_cop.payment_count/tmp_cop.order_count*100
- from tmp_uv
- join tmp_cop
- on tmp_uv.dt=tmp_cop.dt;
八十一.ADS_商品主题_商品个数
1.建表语句
- drop table if exists ads_product_info;
- create external table ads_product_info(
- `dt` string COMMENT '统计日期',
- `sku_num` string COMMENT 'sku个数',
- `spu_num` string COMMENT 'spu个数'
- ) COMMENT '商品个数信息'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_product_info';
2.代入数据------实际操作之中是要进行避免使用distinct的
- insert into table ads_product_info
- select
- '2020-06-14' dt,
- sku_num,
- spu_num
- from
- (
- select
- '2020-06-14' dt,
- count(*) sku_num
- from
- dwt_sku_topic
- ) tmp_sku_num
- join
- (
- select
- '2020-06-14' dt,
- count(*) spu_num
- from
- (
- select
- spu_id
- from
- dwt_sku_topic
- group by
- spu_id
- ) tmp_spu_id
- ) tmp_spu_num
- on tmp_sku_num.dt=tmp_spu_num.dt;
八十二.ADS_商品主题_全局TopN
A.销量排名
1.建表语句
- drop table if exists ads_product_sale_topN;
- create external table ads_product_sale_topN(
- `dt` string COMMENT '统计日期',
- `sku_id` string COMMENT '商品ID',
- `payment_amount` bigint COMMENT '销量'
- ) COMMENT '商品销量排名'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_product_sale_topN';
2.导入数据
- insert into table ads_product_sale_topN
- select
- '2020-06-14' dt,
- sku_id,
- payment_amount
- from
- dws_sku_action_daycount
- where
- dt='2020-06-14'
- order by payment_amount desc
- limit 10;
B.收藏排名
1.建表语句
- drop table if exists ads_product_favor_topN;
- create external table ads_product_favor_topN(
- `dt` string COMMENT '统计日期',
- `sku_id` string COMMENT '商品ID',
- `favor_count` bigint COMMENT '收藏量'
- ) COMMENT '商品收藏排名'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_product_favor_topN';
2.导入数据
- insert into table ads_product_favor_topN
- select
- '2020-06-14' dt,
- sku_id,
- favor_count
- from
- dws_sku_action_daycount
- where
- dt='2020-06-14'
- order by favor_count desc
- limit 10;
C.购物排名
1.建表语句
- drop table if exists ads_product_cart_topN;
- create external table ads_product_cart_topN(
- `dt` string COMMENT '统计日期',
- `sku_id` string COMMENT '商品ID',
- `cart_count` bigint COMMENT '加入购物车次数'
- ) COMMENT '商品加入购物车排名'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_product_cart_topN';
2.导入数据
- insert into table ads_product_cart_topN
- select
- '2020-06-14' dt,
- sku_id,
- cart_count
- from
- dws_sku_action_daycount
- where
- dt='2020-06-14'
- order by cart_count desc
- limit 10;
八十三.ADS_商品主题_退款率
1.建表语句
- drop table if exists ads_product_refund_topN;
- create external table ads_product_refund_topN(
- `dt` string COMMENT '统计日期',
- `sku_id` string COMMENT '商品ID',
- `refund_ratio` decimal(16,2) COMMENT '退款率'
- ) COMMENT '商品退款率排名'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_product_refund_topN';
2.导入数据
- insert into table ads_product_refund_topN
- select
- '2020-06-14',
- sku_id,
- refund_last_30d_count/payment_last_30d_count*100 refund_ratio
- from dwt_sku_topic
- order by refund_ratio desc
- limit 10;
八十四.ADS_商品主题_商品差评率
1.建表语句
- drop table if exists ads_appraise_bad_topN;
- create external table ads_appraise_bad_topN(
- `dt` string COMMENT '统计日期',
- `sku_id` string COMMENT '商品ID',
- `appraise_bad_ratio` decimal(16,2) COMMENT '差评率'
- ) COMMENT '商品差评率'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_appraise_bad_topN';
2.导入数据
- insert into table ads_appraise_bad_topN
- select
- '2020-06-14' dt,
- sku_id,
- appraise_bad_count/(appraise_good_count+appraise_mid_count+appraise_bad_count+appraise_default_count) appraise_bad_ratio
- from
- dws_sku_action_daycount
- where
- dt='2020-06-14'
- order by appraise_bad_ratio desc
- limit 10;
八十五.ADS_营销主题_下单支付统计
需求分析:统计每日下单数,下单金额及下单用户数。
1.建表语句
- drop table if exists ads_order_daycount;
- create external table ads_order_daycount(
- dt string comment '统计日期',
- order_count bigint comment '单日下单笔数',
- order_amount bigint comment '单日下单金额',
- order_users bigint comment '单日下单用户数'
- ) comment '下单数目统计'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_order_daycount';
2.导入数据
- insert into table ads_order_daycount
- select
- '2020-06-14',
- sum(order_count),
- sum(order_amount),
- sum(if(order_count>0,1,0))
- from dws_user_action_daycount
- where dt='2020-06-14';
GMV这个概念的含义是包含付款的金额,也包含没有付款的金额.
八十六.ADS_营销主题_支付信息统计
每日支付金额、支付人数、支付商品数、支付笔数以及下单到支付的平均时长(取自DWD)
1.建表
- drop table if exists ads_payment_daycount;
- create external table ads_payment_daycount(
- dt string comment '统计日期',
- order_count bigint comment '单日支付笔数',
- order_amount bigint comment '单日支付金额',--今天卖出多少商品,今天一共多少种商品卖出
- payment_user_count bigint comment '单日支付人数',
- payment_sku_count bigint comment '单日支付商品数',
- payment_avg_time decimal(16,2) comment '下单到支付的平均时长,取分钟数'
- ) comment '支付信息统计'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_payment_daycount';
2.导入数据
- insert into table ads_payment_daycount
- select
- tmp_payment.dt,
- tmp_payment.payment_count,
- tmp_payment.payment_amount,
- tmp_payment.payment_user_count,
- tmp_skucount.payment_sku_count,
- tmp_time.payment_avg_time
- from
- (
- select
- '2020-06-14' dt,
- sum(payment_count) payment_count,
- sum(payment_amount) payment_amount,
- sum(if(payment_count>0,1,0)) payment_user_count
- from dws_user_action_daycount
- where dt='2020-06-14'
- )tmp_payment
- join
- (
- select
- '2020-06-14' dt,
- sum(if(payment_count>0,1,0)) payment_sku_count
- from dws_sku_action_daycount
- where dt='2020-06-14'
- )tmp_skucount on tmp_payment.dt=tmp_skucount.dt
- join
- (
- select
- '2020-06-14' dt,
- sum(unix_timestamp(payment_time)-unix_timestamp(create_time))/count(*)/60
- --支付时间减去下单时间
- payment_avg_time
- from dwd_fact_order_info
- where dt='2020-06-14'
- and payment_time is not null
- )tmp_time on tmp_payment.dt=tmp_time.dt;
八十七.ADS_商品主题_品牌复购率
这里将买过一次的看作是购买的,买过两次的以及以上的视为是复购的,买过三次以上的看作为多次复购率.
1.建表语句
- drop table ads_sale_tm_category1_stat_mn;
- create external table ads_sale_tm_category1_stat_mn
- (
- tm_id string comment '品牌id',
- category1_id string comment '1级品类id ',
- category1_name string comment '1级品类名称 ',
- buycount bigint comment '购买人数',
- buy_twice_last bigint comment '两次以上购买人数',
- buy_twice_last_ratio decimal(16,2) comment '单次复购率',
- buy_3times_last bigint comment '三次以上购买人数',
- buy_3times_last_ratio decimal(16,2) comment '多次复购率',
- stat_mn string comment '统计月份',
- stat_date string comment '统计日期'
- ) COMMENT '品牌复购率统计'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_sale_tm_category1_stat_mn/';
2.导入数据
- with
- tmp_order as
- (
- select
- user_id,
- order_stats_struct.sku_id sku_id,
- order_stats_struct.order_count order_count
- from dws_user_action_daycount lateral view explode(order_detail_stats) tmp as order_stats_struct
- where date_format(dt,'yyyy-MM')=date_format('2020-06-14','yyyy-MM')
- ),
- tmp_sku as
- (
- select
- id,
- tm_id,
- category1_id,
- category1_name
- from dwd_dim_sku_info
- where dt='2020-06-14'
- )
- insert into table ads_sale_tm_category1_stat_mn
- select
- tm_id,
- category1_id,
- category1_name,
- sum(if(order_count>=1,1,0)) buycount,
- sum(if(order_count>=2,1,0)) buyTwiceLast,
- sum(if(order_count>=2,1,0))/sum( if(order_count>=1,1,0)) buyTwiceLastRatio,
- sum(if(order_count>=3,1,0)) buy3timeLast ,
- sum(if(order_count>=3,1,0))/sum( if(order_count>=1,1,0)) buy3timeLastRatio ,
- date_format('2020-06-14' ,'yyyy-MM') stat_mn,
- '2020-06-14' stat_date
- from
- (
- select
- tmp_order.user_id,
- tmp_sku.category1_id,
- tmp_sku.category1_name,
- tmp_sku.tm_id,
- sum(order_count) order_count
- from tmp_order
- join tmp_sku
- on tmp_order.sku_id=tmp_sku.id
- group by tmp_order.user_id,tmp_sku.category1_id,tmp_sku.category1_name,tmp_sku.tm_id
- )tmp
- group by tm_id, category1_id, category1_name;
八十八.ADS_地区建表语句
1.建表
- drop table if exists ads_area_topic;
- create external table ads_area_topic(
- `dt` string COMMENT '统计日期',
- `id` bigint COMMENT '编号',
- `province_name` string COMMENT '省份名称',
- `area_code` string COMMENT '地区编码',
- `iso_code` string COMMENT 'iso编码',
- `region_id` string COMMENT '地区ID',
- `region_name` string COMMENT '地区名称',
- `login_day_count` bigint COMMENT '当天活跃设备数',
- `order_day_count` bigint COMMENT '当天下单次数',
- `order_day_amount` decimal(16,2) COMMENT '当天下单金额',
- `payment_day_count` bigint COMMENT '当天支付次数',
- `payment_day_amount` decimal(16,2) COMMENT '当天支付金额'
- ) COMMENT '地区主题信息'
- row format delimited fields terminated by '\t'
- location '/warehouse/gmall/ads/ads_area_topic/';
2.数据装载
- insert into table ads_area_topic
- select
- '2020-06-14',
- id,
- province_name,
- area_code,
- iso_code,
- region_id,
- region_name,
- login_day_count,
- order_day_count,
- order_day_amount,
- payment_day_count,
- payment_day_amount
- from dwt_area_topic;
八十九.ADS_脚本的建立
1)在/home/atguigu/bin目录下创建脚本dwt_to_ads.sh
[atguigu@hadoop102 bin]$ vim dwt_to_ads.sh
在脚本中填写如下内容
- #!/bin/bash
- hive=/opt/module/hive/bin/hive
- APP=gmall
- # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
- if [ -n "$1" ] ;then
- do_date=$1
- else
- do_date=`date -d "-1 day" +%F`
- fi
- sql="
- set mapreduce.job.queuename=hive;
- insert into table ${APP}.ads_uv_count
- select
- '$do_date' dt,
- daycount.ct,
- wkcount.ct,
- mncount.ct,
- if(date_add(next_day('$do_date','MO'),-1)='$do_date','Y','N') ,
- if(last_day('$do_date')='$do_date','Y','N')
- from
- (
- select
- '$do_date' dt,
- count(*) ct
- from ${APP}.dwt_uv_topic
- where login_date_last='$do_date'
- )daycount join
- (
- select
- '$do_date' dt,
- count (*) ct
- from ${APP}.dwt_uv_topic
- where login_date_last>=date_add(next_day('$do_date','MO'),-7)
- and login_date_last<= date_add(next_day('$do_date','MO'),-1)
- ) wkcount on daycount.dt=wkcount.dt
- join
- (
- select
- '$do_date' dt,
- count (*) ct
- from ${APP}.dwt_uv_topic
- where date_format(login_date_last,'yyyy-MM')=date_format('$do_date','yyyy-MM')
- )mncount on daycount.dt=mncount.dt;
- insert into table ${APP}.ads_new_mid_count
- select
- login_date_first,
- count(*)
- from ${APP}.dwt_uv_topic
- where login_date_first='$do_date'
- group by login_date_first;
- insert into table ${APP}.ads_silent_count
- select
- '$do_date',
- count(*)
- from ${APP}.dwt_uv_topic
- where login_date_first=login_date_last
- and login_date_last<=date_add('$do_date',-7);
- insert into table ${APP}.ads_back_count
- select
- '$do_date',
- concat(date_add(next_day('$do_date','MO'),-7),'_', date_add(next_day('$do_date','MO'),-1)),
- count(*)
- from
- (
- select
- mid_id
- from ${APP}.dwt_uv_topic
- where login_date_last>=date_add(next_day('$do_date','MO'),-7)
- and login_date_last<= date_add(next_day('$do_date','MO'),-1)
- and login_date_first
- )current_wk
- left join
- (
- select
- mid_id
- from ${APP}.dws_uv_detail_daycount
- where dt>=date_add(next_day('$do_date','MO'),-7*2)
- and dt<= date_add(next_day('$do_date','MO'),-7-1)
- group by mid_id
- )last_wk
- on current_wk.mid_id=last_wk.mid_id
- where last_wk.mid_id is null;
- insert into table ${APP}.ads_wastage_count
- select
- '$do_date',
- count(*)
- from
- (
- select
- mid_id
- from ${APP}.dwt_uv_topic
- where login_date_last<=date_add('$do_date',-7)
- group by mid_id
- )t1;
- insert into table ${APP}.ads_user_retention_day_rate
- select
- '$do_date',--统计日期
- date_add('$do_date',-1),--新增日期
- 1,--留存天数
- sum(if(login_date_first=date_add('$do_date',-1) and login_date_last='$do_date',1,0)),--$do_date的1日留存数
- sum(if(login_date_first=date_add('$do_date',-1),1,0)),--$do_date新增
- sum(if(login_date_first=date_add('$do_date',-1) and login_date_last='$do_date',1,0))/sum(if(login_date_first=date_add('$do_date',-1),1,0))*100
- from ${APP}.dwt_uv_topic
- union all
- select
- '$do_date',--统计日期
- date_add('$do_date',-2),--新增日期
- 2,--留存天数
- sum(if(login_date_first=date_add('$do_date',-2) and login_date_last='$do_date',1,0)),--$do_date的2日留存数
- sum(if(login_date_first=date_add('$do_date',-2),1,0)),--$do_date新增
- sum(if(login_date_first=date_add('$do_date',-2) and login_date_last='$do_date',1,0))/sum(if(login_date_first=date_add('$do_date',-2),1,0))*100
- from ${APP}.dwt_uv_topic
- union all
- select
- '$do_date',--统计日期
- date_add('$do_date',-3),--新增日期
- 3,--留存天数
- sum(if(login_date_first=date_add('$do_date',-3) and login_date_last='$do_date',1,0)),--$do_date的3日留存数
- sum(if(login_date_first=date_add('$do_date',-3),1,0)),--$do_date新增
- sum(if(login_date_first=date_add('$do_date',-3) and login_date_last='$do_date',1,0))/sum(if(login_date_first=date_add('$do_date',-3),1,0))*100
- from ${APP}.dwt_uv_topic;
- insert into table ${APP}.ads_continuity_wk_count
- select
- '$do_date',
- concat(date_add(next_day('$do_date','MO'),-7*3),'_',date_add(next_day('$do_date','MO'),-1)),
- count(*)
- from
- (
- select
- mid_id
- from
- (
- select
- mid_id
- from ${APP}.dws_uv_detail_daycount
- where dt>=date_add(next_day('$do_date','monday'),-7)
- and dt<=date_add(next_day('$do_date','monday'),-1)
- group by mid_id
- union all
- select
- mid_id
- from ${APP}.dws_uv_detail_daycount
- where dt>=date_add(next_day('$do_date','monday'),-7*2)
- and dt<=date_add(next_day('$do_date','monday'),-7-1)
- group by mid_id
- union all
- select
- mid_id
- from ${APP}.dws_uv_detail_daycount
- where dt>=date_add(next_day('$do_date','monday'),-7*3)
- and dt<=date_add(next_day('$do_date','monday'),-7*2-1)
- group by mid_id
- )t1
- group by mid_id
- having count(*)=3
- )t2;
- insert into table ${APP}.ads_continuity_uv_count
- select
- '$do_date',
- concat(date_add('$do_date',-6),'_','$do_date'),
- count(*)
- from
- (
- select mid_id
- from
- (
- select mid_id
- from
- (
- select
- mid_id,
- date_sub(dt,rank) date_dif
- from
- (
- select
- mid_id,
- dt,
- rank() over(partition by mid_id order by dt) rank
- from ${APP}.dws_uv_detail_daycount
- where dt>=date_add('$do_date',-6) and dt<='$do_date'
- )t1
- )t2
- group by mid_id,date_dif
- having count(*)>=3
- )t3
- group by mid_id
- )t4;
- insert into table ${APP}.ads_user_topic
- select
- '$do_date',
- sum(if(login_date_last='$do_date',1,0)),
- sum(if(login_date_first='$do_date',1,0)),
- sum(if(payment_date_first='$do_date',1,0)),
- sum(if(payment_count>0,1,0)),
- count(*),
- sum(if(login_date_last='$do_date',1,0))/count(*),
- sum(if(payment_count>0,1,0))/count(*),
- sum(if(login_date_first='$do_date',1,0))/sum(if(login_date_last='$do_date',1,0))
- from ${APP}.dwt_user_topic;
- with
- tmp_uv as
- (
- select
- '$do_date' dt,
- sum(if(array_contains(pages,'home'),1,0)) home_count,
- sum(if(array_contains(pages,'good_detail'),1,0)) good_detail_count
- from
- (
- select
- mid_id,
- collect_set(page_id) pages
- from ${APP}.dwd_page_log
- where dt='$do_date'
- and page_id in ('home','good_detail')
- group by mid_id
- )tmp
- ),
- tmp_cop as
- (
- select
- '$do_date' dt,
- sum(if(cart_count>0,1,0)) cart_count,
- sum(if(order_count>0,1,0)) order_count,
- sum(if(payment_count>0,1,0)) payment_count
- from ${APP}.dws_user_action_daycount
- where dt='$do_date'
- )
- insert into table ${APP}.ads_user_action_convert_day
- select
- tmp_uv.dt,
- tmp_uv.home_count,
- tmp_uv.good_detail_count,
- tmp_uv.good_detail_count/tmp_uv.home_count*100,
- tmp_cop.cart_count,
- tmp_cop.cart_count/tmp_uv.good_detail_count*100,
- tmp_cop.order_count,
- tmp_cop.order_count/tmp_cop.cart_count*100,
- tmp_cop.payment_count,
- tmp_cop.payment_count/tmp_cop.order_count*100
- from tmp_uv
- join tmp_cop
- on tmp_uv.dt=tmp_cop.dt;
- insert into table ${APP}.ads_product_info
- select
- '$do_date' dt,
- sku_num,
- spu_num
- from
- (
- select
- '$do_date' dt,
- count(*) sku_num
- from
- ${APP}.dwt_sku_topic
- ) tmp_sku_num
- join
- (
- select
- '$do_date' dt,
- count(*) spu_num
- from
- (
- select
- spu_id
- from
- ${APP}.dwt_sku_topic
- group by
- spu_id
- ) tmp_spu_id
- ) tmp_spu_num
- on
- tmp_sku_num.dt=tmp_spu_num.dt;
- insert into table ${APP}.ads_product_sale_topN
- select
- '$do_date' dt,
- sku_id,
- payment_amount
- from
- ${APP}.dws_sku_action_daycount
- where
- dt='$do_date'
- order by payment_amount desc
- limit 10;
- insert into table ${APP}.ads_product_favor_topN
- select
- '$do_date' dt,
- sku_id,
- favor_count
- from
- ${APP}.dws_sku_action_daycount
- where
- dt='$do_date'
- order by favor_count desc
- limit 10;
- insert into table ${APP}.ads_product_cart_topN
- select
- '$do_date' dt,
- sku_id,
- cart_count
- from
- ${APP}.dws_sku_action_daycount
- where
- dt='$do_date'
- order by cart_count desc
- limit 10;
- insert into table ${APP}.ads_product_refund_topN
- select
- '$do_date',
- sku_id,
- refund_last_30d_count/payment_last_30d_count*100 refund_ratio
- from ${APP}.dwt_sku_topic
- order by refund_ratio desc
- limit 10;
- insert into table ${APP}.ads_appraise_bad_topN
- select
- '$do_date' dt,
- sku_id,
- appraise_bad_count/(appraise_good_count+appraise_mid_count+appraise_bad_count+appraise_default_count) appraise_bad_ratio
- from
- ${APP}.dws_sku_action_daycount
- where
- dt='$do_date'
- order by appraise_bad_ratio desc
- limit 10;
- insert into table ${APP}.ads_order_daycount
- select
- '$do_date',
- sum(order_count),
- sum(order_amount),
- sum(if(order_count>0,1,0))
- from ${APP}.dws_user_action_daycount
- where dt='$do_date';
- insert into table ${APP}.ads_payment_daycount
- select
- tmp_payment.dt,
- tmp_payment.payment_count,
- tmp_payment.payment_amount,
- tmp_payment.payment_user_count,
- tmp_skucount.payment_sku_count,
- tmp_time.payment_avg_time
- from
- (
- select
- '$do_date' dt,
- sum(payment_count) payment_count,
- sum(payment_amount) payment_amount,
- sum(if(payment_count>0,1,0)) payment_user_count
- from ${APP}.dws_user_action_daycount
- where dt='$do_date'
- )tmp_payment
- join
- (
- select
- '$do_date' dt,
- sum(if(payment_count>0,1,0)) payment_sku_count
- from ${APP}.dws_sku_action_daycount
- where dt='$do_date'
- )tmp_skucount on tmp_payment.dt=tmp_skucount.dt
- join
- (
- select
- '$do_date' dt,
- sum(unix_timestamp(payment_time)-unix_timestamp(create_time))/count(*)/60 payment_avg_time
- from ${APP}.dwd_fact_order_info
- where dt='$do_date'
- and payment_time is not null
- )tmp_time on tmp_payment.dt=tmp_time.dt;
- with
- tmp_order as
- (
- select
- user_id,
- order_stats_struct.sku_id sku_id,
- order_stats_struct.order_count order_count
- from ${APP}.dws_user_action_daycount lateral view explode(order_detail_stats) tmp as order_stats_struct
- where date_format(dt,'yyyy-MM')=date_format('$do_date','yyyy-MM')
- ),
- tmp_sku as
- (
- select
- id,
- tm_id,
- category1_id,
- category1_name
- from ${APP}.dwd_dim_sku_info
- where dt='$do_date'
- )
- insert into table ${APP}.ads_sale_tm_category1_stat_mn
- select
- tm_id,
- category1_id,
- category1_name,
- sum(if(order_count>=1,1,0)) buycount,
- sum(if(order_count>=2,1,0)) buyTwiceLast,
- sum(if(order_count>=2,1,0))/sum( if(order_count>=1,1,0)) buyTwiceLastRatio,
- sum(if(order_count>=3,1,0)) buy3timeLast ,
- sum(if(order_count>=3,1,0))/sum( if(order_count>=1,1,0)) buy3timeLastRatio ,
- date_format('$do_date' ,'yyyy-MM') stat_mn,
- '$do_date' stat_date
- from
- (
- select
- tmp_order.user_id,
- tmp_sku.category1_id,
- tmp_sku.category1_name,
- tmp_sku.tm_id,
- sum(order_count) order_count
- from tmp_order
- join tmp_sku
- on tmp_order.sku_id=tmp_sku.id
- group by tmp_order.user_id,tmp_sku.category1_id,tmp_sku.category1_name,tmp_sku.tm_id
- )tmp
- group by tm_id, category1_id, category1_name;
- insert into table ${APP}.ads_area_topic
- select
- '$do_date',
- id,
- province_name,
- area_code,
- iso_code,
- region_id,
- region_name,
- login_day_count,
- order_day_count,
- order_day_amount,
- payment_day_count,
- payment_day_amount
- from ${APP}.dwt_area_topic;
- "
- $hive -e "$sql"
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 dwt_to_ads.sh
3)执行脚本导入数据
[atguigu@hadoop102 bin]$ dwt_to_ads.sh 2020-06-15
4)查看导入数据
- select * from ads_uv_count where dt='2020-06-15';
- select * from ads_new_mid_count;
- select * from ads_silent_count where dt='2020-06-15';
- select * from ads_back_count where dt='2020-06-15';
- select * from ads_wastage_count where dt='2020-06-15';
- select * from ads_user_retention_day_rate;
- select * from ads_continuity_wk_count where dt='2020-06-15';
- select * from ads_continuity_uv_count where dt='2020-06-15';
- select * from ads_user_topic where dt='2020-06-15';
- select * from ads_user_action_convert_day where dt='2020-06-15';
- select * from ads_product_info where dt='2020-06-15';
- select * from ads_product_sale_topN where dt='2020-06-15';
- select * from ads_product_favor_topN where dt='2020-06-15';
- select * from ads_product_cart_topN where dt='2020-06-15';
- select * from ads_product_refund_topN where dt='2020-06-15';
- select * from ads_appraise_bad_topN where dt='2020-06-15';
- select * from ads_order_daycount where dt='2020-06-15';
- select * from ads_payment_daycount where dt='2020-06-15';
- select * from ads_sale_tm_category1_stat_mn;
- select * from ads_area_topic where dt='2020-06-15';
往ads层进行导入数据的时候,使用的是insert into,会导致每天出现一个新的文件,就是所谓的小文件,导致大量的小文件的生成.
解决方式是:最直接的方式select * from 原来的 union 新的 overwrite 一下.因而这个任务就是可以重复执行.
这个部分我配置的环境如下网盘所示(38.76G):
链接:https://pan.baidu.com/s/19YzjgAMAqgIIrIUah4oFaQ?pwd=1111
提取码:1111 -
相关阅读:
直播预告:防御升级-SMC2精准对抗账号劫持和漏洞威胁
[RoarCTF 2019]Easy Calc
Linux目录结构
Spring Data JPA使用@DynamicUpdate注解进行Update部分更新
适合学生党的蓝牙耳机有哪些?学生党蓝牙耳机推荐
面试官最喜欢问的Redis知识
14:00面试,14:06就出来了,问的问题有点变态。。。
95后大厂程序员删库被判刑,只因项目被接手对领导心生不满
(杂)网易云歌单导入到apple music
《学习强国》投稿发稿全攻略:三种方式助你实现投稿梦想!
- 原文地址:https://blog.csdn.net/m0_47489229/article/details/127465566
