-
在python 深度学习Keras中计算神经网络集成模型
神经网络的训练过程是一个挑战性的优化过程,通常无法收敛。最近我们被客户要求撰写关于深度学习的研究报告,包括一些图形和统计输出。
这可能意味着训练结束时的模型可能不是稳定的或表现最佳的权重集,无法用作最终模型。
解决此问题的一种方法是使用在训练运行结束时多个模型的权重平均值。
平均模型权重
学习深度神经网络模型的权重需要解决高维非凸优化问题。
解决此优化问题的一个挑战是,有许多“ 好的 ”解决方案,学习算法可能会反弹而无法稳定。
解决此问题的一种方法是在训练过程即将结束时合并所收集的权重。通常,这可以称为时间平均,并称为Polyak平均或Polyak-Ruppert平均,以该方法的原始开发者命名。
Polyak平均通过优化算法访问的参数空间将轨迹中的几个点平均在一起。
多类别分类问题
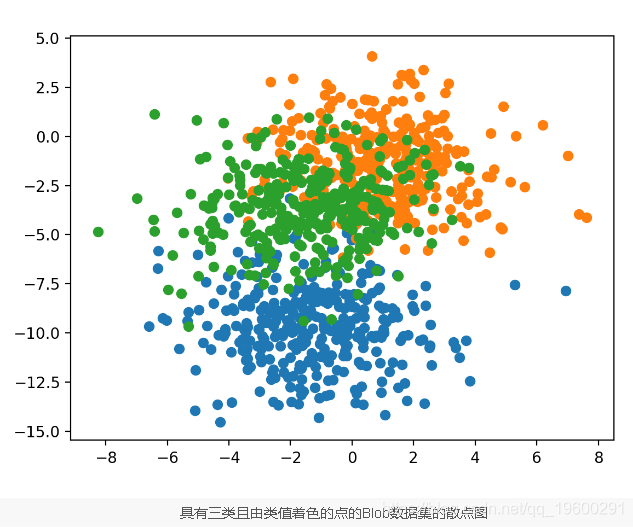
我们使用一个小的多类分类问题作为基础来证明模型权重集合。
该问题有两个输入变量(代表点的x和y坐标),每组中点的标准偏差为2.0。
- # 生成2D分类数据集
- X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
结果是我们可以建模的数据集的输入和输出元素。
为了了解问题的复杂性,我们可以在二维散点图上绘制每个点,并通过类值对每个点进行着色。
- # 数据集的散点图
- # 生成2D分类数据集
- # 每个类值的散点图
- for class_value in range(3):
- # 选择带有类别标签的点的索引
- row_ix = where(y == class_value)
- # 不同颜色点的散点图
- pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
- # 显示图
运行示例将创建整个数据集的散点图。我们可以看到2.0的标准偏差意味着类不是线性可分离的(由线分隔),从而导致许多歧义点。
多层感知器模型
在定义模型之前,我们需要设计一个集合的问题。
在我们的问题中,训练数据集相对较小。具体来说,训练数据集中的示例与保持数据集的比例为10:1。这模仿了一种情况,在这种情况下,我们可能会有大量未标记的示例和少量带有标记的示例用于训练模型。
该问题是多类分类问题,我们 在输出层上使用softmax激活
-
相关阅读:
Websocket在Asp.net webApi(.net framework)上的应用
Ubuntu 配置
CentOS7安装squid代理服务器
wallys/IPQ8074A 4x4 2.4G 8x8 5G 802.11ax
数据可视化之对外经济发展,近五年我国对外货物进出口总额持续上涨
app小程序手机端Python爬虫实战18-通过mitmproxy解析短视频App返回数据
docker下快速部署openldap与PHPLdapAdmin
【补题日记】[2022牛客暑期多校2]I-let fat tension
.NET周报 【4月第4期 2023-04-23】
【华为机试真题 JAVA】DNA序列-100
- 原文地址:https://blog.csdn.net/tecdat/article/details/128155691
