-
Mysql - 读写分离与读负载均衡之Maxscale
原文地址
Mysql - 读写分离与读负载均衡之Maxscale - 小豹子加油 - 博客园
maxscale会自动识别出集群的master与slave角色。所以我们可以将maxscale与mha结合起来,既能实现主库的故障转移,又能实现读写分离和从库的负载均衡。
一、概述
常见的高可用方案如MMM和MHA等都将重点放在主库上,一旦主库出现故障,通过这些方案能将主库故障进行转移。
本文将给大家介绍一款由mariadb公司出品的中间件Maxscale,该中间件能实现读写分离和读负载均衡,安装和配置都十分简单。
官方文档https://mariadb.com/kb/en/maxscale-22-getting-started/
二、节点介绍
本次实验采用4台虚拟机,操作系统版本Centos6.10,mysql版本5.7.25
maxscale 10.40.16.60 路由 路由节点
node1 10.40.16.61 主库 提供写服务
node2 10.40.16.62 从库 提供读服务
node3 10.40.16.63 从库 提供读服务
节点拓扑图

三、安装
1. 配置一主二从
其中node1是主库,node2和node3是从库。具体的复制搭建这里就省略,要是这都不会,那么该文章对你就没意思了。顺便安利一个自己写的mysql一键安装脚本https://www.cnblogs.com/ddzj01/p/10678296.html
注明:集群中使用的复制账号为repl,密码是'123456'
2. 下载maxscale包
下载地址:MaxScale/2.2.0/centos/6Server/x86_64/ - MariaDB
 我在做实验的时候,最开始使用的是maxscale的最新版本(如:2.2.21-GA),安装完后发现参数文件/etc/maxscale.cnf里面都只支持mariadb(protocol=MariaDBBackend),而不支持oracle官方的mysql。所以就选用一个了比较老的maxscale版本。等实验做完了,我再试着用最新版本的maxscale软件+老的参数文件也是能够运行的。所以如果使用的oracle官方的mysql,要想使用最新版本的maxscale,则需要使用老版本的参数文件去替换新版本中的参数文件。
我在做实验的时候,最开始使用的是maxscale的最新版本(如:2.2.21-GA),安装完后发现参数文件/etc/maxscale.cnf里面都只支持mariadb(protocol=MariaDBBackend),而不支持oracle官方的mysql。所以就选用一个了比较老的maxscale版本。等实验做完了,我再试着用最新版本的maxscale软件+老的参数文件也是能够运行的。所以如果使用的oracle官方的mysql,要想使用最新版本的maxscale,则需要使用老版本的参数文件去替换新版本中的参数文件。3. 安装maxscale
在maxscale节点
yum install -y libaio libaio-devel
rpm -ivh maxscale-2.2.0-1.centos.6.x86_64.rpm
四、配置
1. 在node1(主库)创建相关账号
监控账号,maxscale使用该账号监控集群状态。如果发现某个从服务器复制线程停掉了,那么就不向其转发请求了。
(root@localhost)[(none)]> grant replication slave, replication client on *.* to scalemon@'%' identified by '123456';
路由账号,maxscale使用该账号将不同的请求分发到不同的节点上。当客户端连接到maxscale这个节点上时,maxscale节点会使用该账号去查后端数据库,检查客户端登陆的用户是否有权限或密码是否正确等等。
(root@localhost)[(none)]> grant select on mysql.* to maxscale@'%' identified by '123456';
2. 在maxscale节点配置参数文件/etc/maxscale.cnf
3. 在maxscale节点安装mysql客户端
注意这一步不是必须的,我只是为了方便后面的实验,选择在该节点安装一个mysql客户端,然后通过该客户端去连maxscale
tar -zxvf mysql-5.7.25-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local/
ln -s mysql-5.7.25-linux-glibc2.12-x86_64 mysql
echo 'export PATH=$PATH:/usr/local/mysql/bin' >> /root/.bash_profile
cd ~
source .bash_profile
五、maxscale相关操作
1. 启动maxscale服务
maxscale -f /etc/maxscale.cnf
2. 登录maxscale管理器
默认的用户名和密码是admin/mariadb
[root@monitor ~]# maxadmin --user=admin --password=mariadb
查看集群状态

可以看到我并没有在maxscale.cnf中指明哪一个是master哪一个是slave,maxscale会自动识别出集群的master与slave角色。所以我们可以将maxscale与mha结合起来,既能实现主库的故障转移,又能实现读写分离和从库的负载均衡。
查看集群中的用户

六、测试
1. 测试读写分离
在node1(主库)上创建一个测试账号
(root@localhost)[(none)]> grant all on *.* to scott@'%' identified by 'tiger';
在maxscale节点连接数据库
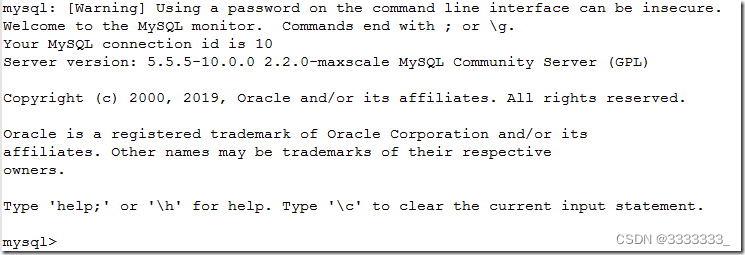
[root@monitor ~]# mysql -uscott -ptiger -h10.40.16.60 -P4006
注意这里的-h连接的maxscale节点,-P是maxscale的端口,如果maxscale与mysql client不在同一台机器,还需要关闭maxscale上的防火墙
验证读写分离
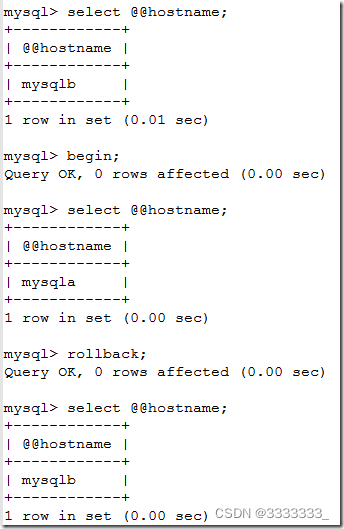
可以看到,读的请求就转发给了node2,而写的请求转发给了node1,读写分离验证成功。
2. 测试读负载均衡
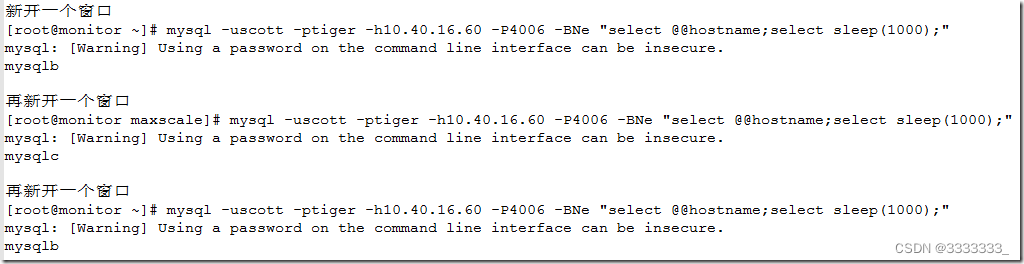
在mysql服务器上分别查看当前的连接状态
node1

node2

node3

可以看到在maxscale上面进行的三个连接在这三台mysql服务器上都进行了连接,所不同的是,node2有两个会话在执行该语句,而node3有一个会话在执行该语句。也就是说默认会将读的操作均匀分配到每个从节点中。
3. 单个slave出现故障
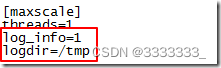
修改maxscale.cnf参数,将路由日志的级别设置为info,这步跟实验无关,只是为了方便看日志
重启maxscale服务
ps -ef | grep maxscale | grep -v grep | awk '{print $2}' | xargs kill -9
maxscale -f /etc/maxscale.cnf
停掉node2的复制
(root@localhost)[(none)]> stop slave;
观察/tmp/maxscale.log

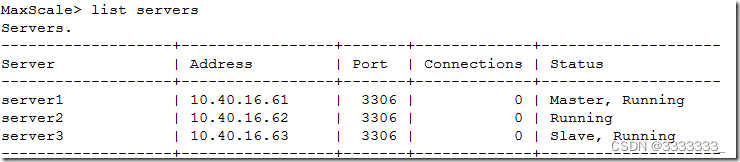
查看集群状态
通过客户端连接集群
mysql -uscott -ptiger -h10.40.16.60 -P4006 -BNe "select @@hostname;"

可以看到node2已经不提供读服务了
4. 所有slave都出现故障
停掉node3的复制
(root@localhost)[(none)]> stop slave;
观察/tmp/maxscale.log

查看集群状态

通过客户端连接集群
mysql -uscott -ptiger -h10.40.16.60 -P4006 -BNe "select @@hostname;"

可以看到读写分离已经不再有效,因为没有slave了,只能去主库读。
我看到有的文章写,如果所有从服务器都失效,即使主库正常也会连接失败,需要在配置文件中添加detect_stale_master=true,但是我这里并没有这种情况,可能是早期的maxscale特性导致的,这里仅作为一个记录。
5. 恢复slave
node2&node3
(root@localhost)[(none)]> start slave;
查看集群状态
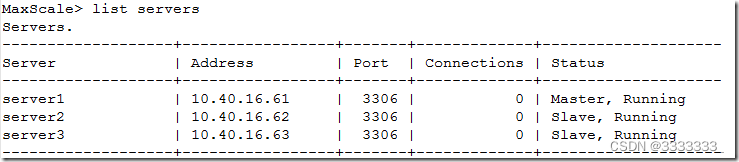
可以看到slave恢复后,又会自动加入到maxscale中来。
6. 测试从库延迟
在node1(主库)创建数据库和给scalemon用户赋权
(root@localhost)[hello]> grant all on *.* to scalemon@'%' identified by '123456';
(root@localhost)[hello]> create database maxscale_schema;
在maxscale节点修改参数文件/etc/maxscale
添加以下参数

重启maxscale服务
ps -ef | grep maxscale | grep -v grep | awk '{print $2}' | xargs kill -9
maxscale -f /etc/maxscale.cnf
把node2的数据库锁住
(root@localhost)[(none)]> flush table with read lock;
在node1中做点修改
(root@localhost)[hello]> insert into t1 values(2);
过一段时间再连数据库发现只能连接到node3了
mysql -uscott -ptiger -h10.40.16.60 -P4006 -BNe "select @@hostname;"

从库延迟测试成功,但是遗憾的是我通过maxadmin和后台日志都没看出任何异常来,可能是有命令我还没熟吧。
七、总结
maxscale就给大家介绍到这里了,我在网上搜maxscale相关的博客时,发现并不多,而且即使有几篇,也非常老,说明这个中间件使用的并不是很广,如果大家对于这个持异议,欢迎大家留言。如果要在生产中使用这种中间件,还需要多多测试稳定性和加了中间件后查询效率的损耗。
优点:
1. 配置简单
2. 能实现读写分离
3. 能实现读负载均衡
缺点:
1. 由于增加了中间层,所以对查询效率有损耗
2. 中间层节点也容易出现单点故障
本文实验部分取材于https://blog.csdn.net/yehanyy/article/details/78983763
-
相关阅读:
DigiCert证书——银行官网的首选
NC20242 [SCOI2005]最大子矩阵
php mysql 后台 操作
MFC application : let‘s learn from the start
Spring源码系列学习
【数据库】02_范式
数据结构与算法--图
【数学】丑数II 和 超级丑数
【MAPBOX基础功能】22、mapbox根据指定中心点绘制指定公里数的矩形
SPark学习笔记:09SparkSQL 数据源之文件和JDBC
- 原文地址:https://blog.csdn.net/wade1010/article/details/128152572