-
Kafka(二)- Kafka集群部署
一、安装部署
1. 集群规划
例如在3台服务器上安装zookeeper和kafka
hadoop102 hadoop103 hadoop104 zookeeper zookeeper zookeeper kafka kafka kafka 2. 虚拟机前置准备工作
(1)配置IP
需要保证 Linux 系统 ifcfg-ens33 文件中 IP 地址、虚拟网络编辑器地址 和 Windows系统中VMnet8网络IP地址相同

1.首先配置虚拟网络编辑器地址,点击编辑选择虚拟网络编辑器

2.选择VMnet8,修改子网IP网段为10,只要跟其他网段不冲突就行

3.点击Net设置,网段配置一致也是10,网关最后一位默认是2

4.在Windows上打开网络和共享中心,配置VMnet8

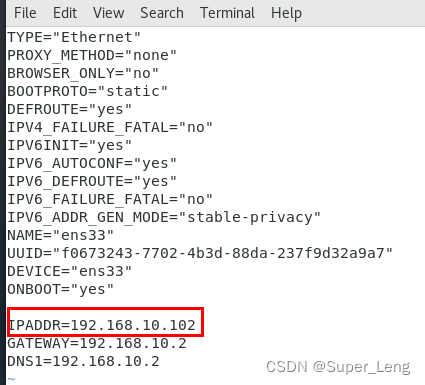
5.在root用户下输入vim /etc/sysconfig/network-scripts/ifcfg-ens33,当前BOOTPROTO="dhcp"表示动态获取IP地址,每次重启虚拟机,IP都会变化。所以需要修改为BOOTPROTO="static"表示IP地址固定不变。

6.还需要多加几行配置,最终配置如下:

(2)修改主机名称和hosts文件
1.配置hostname,输入vim /etc/hostname,修改为hadoop100

2.在Linux上配置主机名称映射,输入vim /etc/hosts,添加以下内容

3.重启虚拟机,输入reboot
4.启动后,验证IP

验证主机名称

5.修改Windows的主机映射文件hosts,在文件在C:\Windows\System32\drivers\etc目录下

(3)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service 注意:在企业开发时,通常单个服务器的防火墙是关闭的。公司整体对外会设置非常安全的防火墙- 1
- 2
- 3
(4)克隆虚拟机
1.利用模板机 hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
注意:克隆时,要先关闭 hadoop100



2.修改IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33- 1
3.修改主机名称
[root@hadoop102 ~]# vim /etc/hostname hadoop102- 1
- 2
4.重启服务器
[root@hadoop102 ~]# reboot- 1
3. 集群部署
官方下载地址:http://kafka.apache.org/downloads.html
kafka代码是由2种语言编写,producer和consumer由Java编写,broker由Scala编写,所以安装包一个版本对应Scala,一个版本对应Java。
(1)解压安装包
下载后的安装包存放在/opt/software/中,再将安装包解压到/opt/module/中。(根据个人习惯选择目录存放)
[root@hadoop102 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/- 1
解压完进入kafka目录,结构如下:

查看bin目录结构,存放了所有脚本,每个模块都有一个脚本,例如:consumer、producer、topics对应的脚本
kafka-console-consumer.sh、kafka-console-producer.sh、kafka-topics.sh

(2)修改配置文件
查看config目录结构:

修改server.properties配置文件:
[hadoop102 config]# vim server.properties- 1
主要修改以下圈出部分的内容:

(3)编写集群分发脚本
① scp(secure copy)安全拷贝
1.scp 定义:scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
2.基本语法:
scp -r $pdir/$fname $user@$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称- 1
- 2
3.案例实操
前提:在 hadoop102、hadoop103、hadoop104 都已经创建好的/opt/module、 /opt/software 两个目录(a)在 hadoop102 上,将 hadoop102 中/opt/module/kafka_2.12-3.0.0 目录拷贝到hadoop103上。 [root@hadoop102 ~]# scp -r /opt/module/kafka_2.12-3.0.0/ root@hadoop103:/opt/module/- 1
- 2
(b)也可以在 hadoop104 上,将 hadoop102 中/opt/module/kafka_2.12-3.0.0 目录拷贝到hadoop104上。 [root@hadoop104 ~]# scp -r root@hadoop102:/opt/module/kafka_2.12-3.0.0 ./- 1
- 2
(c)还可以在 hadoop103 上操作,将 hadoop102 中/opt/modulekafka_2.12-3.0.0 目录拷贝到hadoop104上。 [root@hadoop103 ~]# scp -r root@hadoop102:/opt/module/kafka_2.12-3.0.0 root@hadoop104:/opt/module- 1
- 2
② rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。1.基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 -a 归档拷贝 -v 显示复制过程- 1
- 2
- 3
- 4
2.案例实操
(a)删除 hadoop103 中/opt/module/kafka_2.12-3.0.0 [root@hadoop103 module]# rm -rf kafka_2.12-3.0.0/- 1
- 2
(b)同步 hadoop102 中的/opt/module/kafka_2.12-3.0.0 到 hadoop103 [root@hadoop102 module]# rsync -av /opt/module/kafka_2.12-3.0.0/ root@hadoop103:/opt/module/kafka_2.12-3.0.0/- 1
- 2
③ xsync 集群分发脚本
由于每次同步时都要输入很多命令,还要输入密码,所以可以通过 xsync 集群分发脚本,一步到位。
下面演示xsync集群分发脚本的编写与使用
(1)需求:循环复制文件到所有节点的相同目录下(2)需求分析:
(a)rsync 命令原始拷贝:之前hadoop102 同步到hadoop103、hadoop104需要输入以下命令 [root@hadoop102 module]# rsync -av /opt/module/kafka_2.12-3.0.0/ root@hadoop103:/opt/module/kafka_2.12-3.0.0/ [root@hadoop102 module]# rsync -av /opt/module/kafka_2.12-3.0.0/ root@hadoop104:/opt/module/kafka_2.12-3.0.0/- 1
- 2
- 3
(b)现在期望只输入以下命令就能同步到所有服务器上 [root@hadoop102 module]# xsync kafka_2.12-3.0.0/- 1
- 2
(c)并且期望脚本xsync kafka_2.12-3.0.0/在任何路径都能使用(所以脚本需要放在声明了全局环境变量的路径下) 1.首先查看哪些目录是全局的 [root@hadoop102 module]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin 2.如果不想在提供的目录下存放脚本, 可以添加一个自己的目录到全局环境中(前提是要创建好/home/hadoop/bin目录) 2.1在/etc/profile.d/my_env.sh 文件中增加 export PATH="$PATH:/home/hadoop/bin" 环境变量配置 [root@hadoop102 ~]# vim /etc/profile.d/my_env.sh export PATH="$PATH:/home/hadoop/bin" 2.2配置完后,刷新一下环境变量 [root@hadoop102 ~]# source /etc/profile 3.再次查看时,多了一个全局目录/home/hadoop/bin [root@hadoop102 ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/home/hadoop/bin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)编写脚本
(a)在/home/hadoop/bin 目录下创建 xsync 文件,在该文件中编写如下代码 [root@hadoop102 bin]$ vim xsync #!/bin/bash #1. $#表示参数个数,判断参数个数是否小于1 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do #打印输入的主机名 echo ==================== $host ==================== #3. 遍历所有目录,逐个发送 # 例如执行命令:xsync kafka zookeeper,表示先同步kafka文件,再同步zookeeper文件 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 # 先执行cd -P /opt/module,再执行pwd,可以获取当前的父目录,-P表示软链接(P大写) pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 # basename /opt/module/kafka, 则当前文件名为kafka fname=$(basename $file) # ssh hadoop103可以访问hadoop103主机,并且创建目录mkdir -p /opt/module/kafka,-p表示不管目录存不存在都会创建 ssh $host "mkdir -p $pdir" # rsync -av /opt/module/kafka/ root@hadoop103:/opt/module/kafka/ rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
(b)修改脚本 xsync 具有执行权限 [root@hadoop102 bin]# chmod 777 xsync- 1
- 2

(c)执行脚本 [root@hadoop102 ~]# xsync /opt/module/kafka_2.12-3.0.0/ 执行完后,hadoop102、hadoop103、hadoop104上都会有kafka_2.12-3.0.0文件- 1
- 2
- 3
(4)SSH 无密登录配置
由于每向一个服务器进行同步时,都需要输入密码。为了不用每次输密码,所以可以进行SSH无密登录配置
① 配置 ssh
基本语法
1.ssh 另一台电脑的 IP 地址,例如:hadoop102登录到hadoop103 [root@hadoop102 ~]# ssh hadoop103- 1
- 2

2.hadoop103 退回到 hadoop102 [atguigu@hadoop103 ~]$ exit- 1
- 2

② 无密钥配置
1.免密登录原理
首先在A服务器生成密钥对,只将公钥拷贝给B服务器,B服务器会将公钥放在授权key的文件中
2.生成公钥和私钥
进入.ssh目录,该目录下有个known_hosts文件,再查看known_hosts文件 [root@hadoop102 ~]# cd .ssh/ [root@hadoop102 .ssh]# ll total 4 -rw-r--r--. 1 root root 558 Nov 28 00:11 known_hosts [root@hadoop102 .ssh]# cat known_hosts hadoop103,192.168.10.103 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBIW8j1y/nhu5Q4K+3VGjTnChzq9cbIjzozabQQcjUCU9PdVFBIdD8PleMmDBEK6NCHzF7EW1m6n6iA1S4ihC3GM= hadoop104,192.168.10.104 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBIW8j1y/nhu5Q4K+3VGjTnChzq9cbIjzozabQQcjUCU9PdVFBIdD8PleMmDBEK6NCHzF7EW1m6n6iA1S4ihC3GM= hadoop102,192.168.10.102 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBIW8j1y/nhu5Q4K+3VGjTnChzq9cbIjzozabQQcjUCU9PdVFBIdD8PleMmDBEK6NCHzF7EW1m6n6iA1S4ihC3GM= 说明hadoop102访问过hadoop102、hadoop103、hadoop104- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
配置hadoop102无密登录hadoop103、hadoop104
#输入ssh-keygen -t rsa后,一直点击回车键,直到出现以下结果 [root@hadoop102 .ssh]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:NIVyD44Gsv0U5nVOiN5KA79KFCl4sQvlVO7hlQdhFZA root@hadoop102 The key's randomart image is: +---[RSA 2048]----+ | .+o..=*o+. | |.++o=.Eo*.o | |..o=oOoO+* | | ..+ooXoo.o | | ..o= +S | | . + | | . . | | . | | | +----[SHA256]-----+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
# 再次查看.ssh目录,此时生成了公钥和私钥id_rsa、id_rsa.pub [root@hadoop102 .ssh]# ll total 12 -rw-------. 1 root root 1675 Nov 28 00:54 id_rsa -rw-r--r--. 1 root root 396 Nov 28 00:54 id_rsa.pub -rw-r--r--. 1 root root 558 Nov 28 00:11 known_hosts- 1
- 2
- 3
- 4
- 5
- 6
# 查看公钥 [root@hadoop102 .ssh]# cat id_rsa.pub ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDC6TzfM8ZEZQ8X0u9zFyWQ65cMuBk8YB3yqEjyEjVYtAHijSg0EpTh3NVrEmWaPaSv+6tCziPYjsdWdIQ1k+h8CgyRnV1vc4UTH+YETcl78ScoLWfDxiEBVmKS4aPMYt21yvExGQ/3wZYGFpGVoiUdpHU/QVbpXPjQZ5KjIkOZxzuqsDx5pUbuLT/TLxB5d0ZGYl5mMmVpFIyPlr+btozGNe23h1KAI/rniIrAqU/jYaeoWcrpFLgmiuoG4DPpPqev+GjBe3CS6ow+2i0UwX9czul+cZMWF58EJrhXX/zD6lC+nr6qX5mUTzuhoQpquYy9YetjhpD4iHOAjwT6sbiX root@hadoop102 # 将hadoop102的公钥复制给hadoop102、hadoop103、hadoop104 [root@hadoop102 .ssh]# ssh-copy-id hadoop102 [root@hadoop102 .ssh]# ssh-copy-id hadoop103 [root@hadoop102 .ssh]# ssh-copy-id hadoop104 # hadoop102再次访问hadoop103时,将不再输入hadoop103的密码 [root@hadoop102 .ssh]# ssh hadoop103 Last login: Mon Nov 28 00:24:06 2022 from hadoop102 [root@hadoop103 ~]# # 查看hadoop103中的.ssh目录,多了一个authorized_keys文件,该文件尾部有一行root@hadoop102表示允许hadoop102免密登录 [root@hadoop103 .ssh]# ll total 8 -rw-------. 1 root root 396 Nov 28 00:59 authorized_keys -rw-r--r--. 1 root root 372 Nov 28 00:51 known_hosts [root@hadoop103 .ssh]# cat authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDC6TzfM8ZEZQ8X0u9zFyWQ65cMuBk8YB3yqEjyEjVYtAHijSg0EpTh3NVrEmWaPaSv+6tCziPYjsdWdIQ1k+h8CgyRnV1vc4UTH+YETcl78ScoLWfDxiEBVmKS4aPMYt21yvExGQ/3wZYGFpGVoiUdpHU/QVbpXPjQZ5KjIkOZxzuqsDx5pUbuLT/TLxB5d0ZGYl5mMmVpFIyPlr+btozGNe23h1KAI/rniIrAqU/jYaeoWcrpFLgmiuoG4DPpPqev+GjBe3CS6ow+2i0UwX9czul+cZMWF58EJrhXX/zD6lC+nr6qX5mUTzuhoQpquYy9YetjhpD4iHOAjwT6sbiX root@hadoop102- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
# 再次进行同步分发给其他服务器,不用再输入密码了 [root@hadoop102 bin]# xsync /opt/module/kafka_2.12-3.0.0/- 1
- 2
(5)修改集群其他服务器的配置
分别在 hadoop103 和 hadoop104 上修改配置文件/opt/module/kafka_2.12-3.0.0/config/server.properties中的 broker.id=1、broker.id=2
注:broker.id 不得重复,整个集群中唯一。[root@hadoop103 config]# vim server.properties 修改:broker.id=1 [root@hadoop104 config]# vim server.properties 修改:broker.id=2- 1
- 2
- 3
- 4
(6)配置环境变量
1.在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置 [root@hadoop102 ~]# vim /etc/profile.d/my_env.sh #KAFKA_HOME export KAFKA_HOME=/opt/module/kafka_2.12-3.0.0 export PATH=$PATH:$KAFKA_HOME/bin- 1
- 2
- 3
- 4
- 5
2.刷新一下环境变量 [root@hadoop102 ~]# source /etc/profile- 1
- 2
3.分发环境变量文件到其他服务器,并source /etc/profile [root@hadoop102 ~]# xsync /etc/profile.d/my_env.sh [root@hadoop103 ~]$ source /etc/profile [root@hadoop104 ~]$ source /etc/profile- 1
- 2
- 3
- 4
- 5
(7)kafka启动集群
先启动 Zookeeper 集群,然后启动 Kafka。先配置Zookeeper集群
(1)先启动 Zookeeper 集群,然后启动 Kafka。 [root@hadoop102 kafka]$ zk.sh start (2)依次在 hadoop102、hadoop103、hadoop104 节点上启动 Kafka [root@hadoop102 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties [root@hadoop103 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties [root@hadoop104 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties- 1
- 2
- 3
- 4
- 5
- 6
(8)kafka关闭集群
[root@hadoop102 kafka_2.12-3.0.0]$ bin/kafka-server-stop.sh [root@hadoop103 kafka_2.12-3.0.0]$ bin/kafka-server-stop.sh [root@hadoop104 kafka_2.12-3.0.0]$ bin/kafka-server-stop.sh- 1
- 2
- 3
(9)kafka集群启停脚本
(1)在/home/hadoop/bin 目录下创建文件 kf.sh 脚本文件 [root@hadoop102 bin]$ vim kf.sh 脚本如下: #! /bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------启动 $i Kafka-------" ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/server.properties" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------停止 $i Kafka-------" ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-stop.sh " done };; esac (2)添加执行权限 [root@hadoop102 bin]$ chmod +x kf.sh (3)启动集群命令 [root@hadoop102 ~]$ kf.sh start (4)停止集群命令 [root@hadoop102 ~]$ kf.sh stop 注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后,再停止Zookeeper集群。 因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
相关阅读:
【ICLR 2021】半监督目标检测:Unbiased Teacher For Semi-Supervised Object Detection
leetcode中级2,Sorting and Searching:347. 前 K 个高频元素
【目标检测】——PE-YOLO精读
校园广播站人员和节目管理系统
iptables-参数-A和-I
ANR问题分析手记
nginx部署vue前端项目,访问报错500 Internal Server Error
前端优化渲染:长列表渲染
146. LRU 缓存
计算机毕业设计Java高校勤工助学管理系统(源码+系统+mysql数据库+lw文档)
- 原文地址:https://blog.csdn.net/qq_36602071/article/details/128058604
