-
数据结构与算法之查找算法
数据结构与算法——查找算法
本文将不断更新查找有关算法,由于精力有限,因此本博文将分多次更新,感谢您的关注
1. 二分法查找(折半查找)
1.1 算法叙述
-
二分法查找又称折半查找,顾名思义也就是将待查找范围不断折半直到不能再折为止
-
适用范围:数据表是顺序结构,也就是从小到大或从大到小已经排好序
-
算法复杂度:O(logn)
-
思路如下图:

1.2 实例说明
-
以NTC温度转化为例,通过ADC采集到NTC的电压之后,计算出NTC的电阻值,之后采用查表的方案查询此NTC阻值所对应的温度
-
本文已
TSM1A682J3952RZ这颗NTC电阻为例,数据手册地址:NTC数据手册地址 -
代码如下:
temperature内记录了从数据手册内获取到的NTC从 -40 ~ 125℃ 所对应的阻值search_dichotomy为二分法查找算法实现
#include/* ntc -40 ~ 125℃ 阻值 */ const float temperature[] = { 249.76 , 233.36 , 218.16 , 204.07 , 190.98 , 178.8 , 167.47 , 156.9 , 147.06 , 137.88, 129.31 , 121.31 , 113.85 , 106.88 , 100.38 , 94.3 , 88.626 , 83.325 , 78.372 , 73.743, 69.417 , 65.372 , 61.589 , 58.05 , 54.738 , 51.638 , 48.735 , 46.015 , 43.466 , 41.075, 38.833 , 36.729 , 34.753 , 32.897 , 31.153 , 29.513 , 27.97 , 26.518 , 25.151 , 23.863, 22.649 , 21.505 , 20.426 , 19.407 , 18.445 , 17.537 , 16.679 , 15.868 , 15.101 , 14.375, 13.688 , 13.039 , 12.423 , 11.84 , 11.288 , 10.765 , 10.269 , 9.7981 , 9.3517 , 8.9281, 8.5261 , 8.1445 , 7.7821 , 7.4379 , 7.1108 , 6.8 , 6.5046 , 6.2237 , 5.9565 , 5.7024, 5.4606 , 5.2305 , 5.0115 , 4.8029 , 4.6043 , 4.4151 , 4.2348 , 4.063 , 3.8992 , 3.743, 3.594 , 3.4519 , 3.3163 , 3.1869 , 3.0633 , 2.9453 , 2.8326 , 2.7249 , 2.6219 , 2.5235, 2.4294 , 2.3394 , 2.2533 , 2.1709 , 2.0921 , 2.0166 , 1.9442 , 1.8749 , 1.8086 , 1.7449, 1.6839 , 1.6254 , 1.5693 , 1.5154 , 1.4637 , 1.4141 , 1.3664 , 1.3207 , 1.2767 , 1.2344, 1.1938 , 1.1548 , 1.1172 , 1.0811 , 1.0463 , 1.0128 , 0.98063 , 0.94961 , 0.91974 , 0.89097, 0.86325 , 0.83654 , 0.81079 , 0.78596 , 0.76202 , 0.73894 , 0.71667 , 0.69518 , 0.67444 , 0.65443, 0.63512 , 0.61647 , 0.59846 , 0.58107 , 0.56427 , 0.54804 , 0.53237 , 0.51722 , 0.50258 , 0.48843, 0.47475 , 0.46153 , 0.44875 , 0.43639 , 0.42443 , 0.41288 , 0.4017 , 0.39089 , 0.38043 , 0.37031, 0.36052 , 0.35105 , 0.34189 , 0.33303 , 0.32445 , 0.31616 , 0.30813 , 0.30035 , 0.29284 , 0.28556, 0.27852 , 0.2717 , 0.26511 , 0.25873 , 0.25255 , 0.24658 , }; /** * @brief 二分法查找算法 * * @param elem 待查找数据 * @param table 数据表 * @param table_size 数据表大小 * @return int -1:参数错误 >=0:待查找元素所在表中位置 */ int search_dichotomy(float elem, const float *table, int table_size) { int mid = 0, left = 0, right = 0; if (table == NULL || table_size == 0) return -1; left = 0; right = table_size - 1; mid = (left + right) / 2; if (elem > table[0]) { return 0; } else if (elem < table[table_size - 1]) { return right; } while (left < right) { if (elem > table[mid]) { right = mid; mid = (left + right) / 2; } else if (elem < table[mid]) { left = mid; mid = (left + right) / 2; } else if (elem == table[mid]) { break; } if (left == mid) { break; } else if (right == mid) { mid += 1; break; } } printf("mid:%d left:%d right:%d\n", mid, left, right); return mid; } int main(int argc, char **argv) { printf("*************************\n"); printf("二分法排序\n"); printf("*************************\n"); int temp = 0; temp = search_dichotomy(17.5f, temperature, sizeof(temperature)); temp -= 40; printf("temperature is:%d\n", temp); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
2. 插值查找(比例查找)
2.1 算法叙述
插值查找是在二分查找上的一种改进,但是这种改进需要使用在合适的场景,否则改进之后查找速度反而会有所下降
从来没有最好的算法,只有最合适的算法!
插值查找,又称之为比例查找,在二分查找的基础上进行修改,二分查找中
mid的值永远是left~right的一半,而插值查找也就是根据需要查找的数据在left ~ right中间的比例去设置mid的值插值查找适用于线性度比较高的目标数据中查找,线性度越高,效果越好;线性度越低,效果越差
2.2 实例说明
我们在
二分查找的基础上进行修改,代码如下:#include/* ntc -40 ~ 125℃ 阻值 */ const float temperature[] = { /* 249.76 , 233.36 , 218.16 , 204.07 , 190.98 , 178.8 , 167.47 , 156.9 , 147.06 , 137.88, 129.31 , 121.31 , 113.85 , 106.88 , 100.38 , 94.3 , 88.626 , 83.325 , 78.372 , 73.743, 69.417 , 65.372 , 61.589 , 58.05 , 54.738 , 51.638 , 48.735 , 46.015 , 43.466 , 41.075, 38.833 , 36.729 , 34.753 , 32.897 , 31.153 , 29.513 , 27.97 , 26.518 , 25.151 , 23.863, 22.649 , 21.505 , 20.426 , 19.407 , 18.445 , 17.537 , 16.679 , 15.868 , 15.101 , 14.375, 13.688 , 13.039 , 12.423 , 11.84 , 11.288 , 10.765 , 10.269 , 9.7981 , 9.3517 , 8.9281, 8.5261 , 8.1445 , 7.7821 , 7.4379 , 7.1108 , 6.8 , 6.5046 , 6.2237 , 5.9565 , 5.7024, 5.4606 , 5.2305 , 5.0115 , 4.8029 , 4.6043 , 4.4151 , 4.2348 , 4.063 , 3.8992 , 3.743, 3.594 , 3.4519 , 3.3163 , 3.1869 , 3.0633 , 2.9453 , 2.8326 , 2.7249 , 2.6219 , 2.5235, 2.4294 , 2.3394 , 2.2533 , 2.1709 , 2.0921 , 2.0166 , 1.9442 , 1.8749 , 1.8086 , 1.7449, 1.6839 , 1.6254 , 1.5693 , 1.5154 , 1.4637 , 1.4141 , 1.3664 , 1.3207 , 1.2767 , 1.2344, 1.1938 , 1.1548 , 1.1172 , 1.0811 , 1.0463 , 1.0128 , 0.98063 , 0.94961 , 0.91974 , 0.89097, 0.86325 , 0.83654 , 0.81079 , 0.78596 , 0.76202 , 0.73894 , 0.71667 , 0.69518 , 0.67444 , 0.65443, 0.63512 , 0.61647 , 0.59846 , 0.58107 , 0.56427 , 0.54804 , 0.53237 , 0.51722 , 0.50258 , 0.48843, 0.47475 , 0.46153 , 0.44875 , 0.43639 , 0.42443 , 0.41288 , 0.4017 , 0.39089 , 0.38043 , 0.37031, 0.36052 , 0.35105 , 0.34189 , 0.33303 , 0.32445 , 0.31616 , 0.30813 , 0.30035 , 0.29284 , 0.28556, 0.27852 , 0.2717 , 0.26511 , 0.25873 , 0.25255 , 0.24658 ,*/ 20,19,18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1,0, }; /** * @brief 二分法查找算法 * * @param elem 待查找数据 * @param table 数据表 * @param table_size 数据表大小 * @return int -1:参数错误 >=0:待查找元素所在表中位置 */ int search_dichotomy(float elem, const float *table, int table_size) { int mid = 0, left = 0, right = 0; int count = 0; if (table == NULL || table_size == 0) return -1; left = 0; right = table_size - 1; // mid = (left + right) / 2; //二分法查找 mid = left + ((elem - table[left]) / (table[right] - table[left])) * (right - left); //插值查找 if (elem > table[0]) { return 0; } else if (elem < table[table_size - 1]) { return right; } while (left < right) { if (elem > table[mid]) { right = mid; } else if (elem < table[mid]) { left = mid; } else if (elem == table[mid]) { break; } mid = left + ((elem - table[left]) / (table[right] - table[left])) * (right - left);//插值查找 // mid = (left + right) / 2; //二分法查找 if (left == mid) { break; } else if (right == mid) { mid += 1; break; } count ++; } printf("mid:%d left:%d right:%d\n", mid, left, right); printf("count = %d\n", count); return mid; } int main(int argc, char **argv) { printf("=========================\n"); printf(" 插值查找 \n"); printf("*************************\n"); int temp = 0; temp = search_dichotomy(17.5f, temperature, sizeof(temperature)/sizeof(temperature[0])); temp -= 40; printf("temperature is:%d\n", temp); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
上述为插值插值的实现,和二分法查找相比,唯一修改了
mid的计算过程此外我们对
针对插值查找仅适用于线性度比较高的目标数据,这一结论进行验证:-
当目标数据线性度非常好,斜率k为1的集合
- 采用插值查找,查找次数:
0次 
- 采用二分查找,查找次数:3次
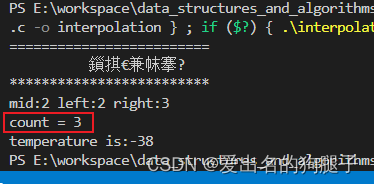
- 采用插值查找,查找次数:
-
当目标数据线性度较差,我们还用第一节中的NTC电阻值的数据,其数据线性度如下:

- 采用插值查找,查找次数:24次!

- 采用二分查找,查找次数:
7次 
由此可见,根据目标数据/群体合理的使用算法尤为重要!
3. 斐波那契查找(黄金分割法查找)
3.1 算法叙述
黄金分割法查找,和二分查找思想相差不多,也是通过不断的缩小数据所在的范围来查找所需要的数据。
黄金分割法,由于其
mid每次的取值均在黄金分割点上,因此称之为黄金分割法查找。而由于斐波拉契数列,连续的三个数十分接近黄金分割点,如 斐波拉契数列:
1 1 2 3 5 8 13 21 34 55 89 144 233任选连续的三组数,如
13 21 34,(34 - 21)/ (34 - 13) = 0.619此数值十分接近黄金分割点,因此斐波拉契分割法也称之为黄金分割法(pass: 当然前面那几组1 1 2误差会大点)那么如何实现斐波拉契查找呢?
-
第一步:首先定义斐波拉契数组
F[],并定义变量k -
第二步:找到
F[k]刚好大于待查找数组table的长度 -
之后按照下图所示进行循环比较

-
第四步:直至
k < 0或left < right或table[left] = elem或table[right] = elem任意一条件满足,结束循环
3.2 实例说明
我们依旧以第1节中的NTC电阻为例,采用斐波拉契查找对NTC电阻阻值对应的温度进行查找,代码如下:
#include#include #include /* ntc -40 ~ 125℃ 阻值 */ const float temperature[] = { 249.76 , 233.36 , 218.16 , 204.07 , 190.98 , 178.8 , 167.47 , 156.9 , 147.06 , 137.88, 129.31 , 121.31 , 113.85 , 106.88 , 100.38 , 94.3 , 88.626 , 83.325 , 78.372 , 73.743, 69.417 , 65.372 , 61.589 , 58.05 , 54.738 , 51.638 , 48.735 , 46.015 , 43.466 , 41.075, 38.833 , 36.729 , 34.753 , 32.897 , 31.153 , 29.513 , 27.97 , 26.518 , 25.151 , 23.863, 22.649 , 21.505 , 20.426 , 19.407 , 18.445 , 17.537 , 16.679 , 15.868 , 15.101 , 14.375, 13.688 , 13.039 , 12.423 , 11.84 , 11.288 , 10.765 , 10.269 , 9.7981 , 9.3517 , 8.9281, 8.5261 , 8.1445 , 7.7821 , 7.4379 , 7.1108 , 6.8 , 6.5046 , 6.2237 , 5.9565 , 5.7024, 5.4606 , 5.2305 , 5.0115 , 4.8029 , 4.6043 , 4.4151 , 4.2348 , 4.063 , 3.8992 , 3.743, 3.594 , 3.4519 , 3.3163 , 3.1869 , 3.0633 , 2.9453 , 2.8326 , 2.7249 , 2.6219 , 2.5235, 2.4294 , 2.3394 , 2.2533 , 2.1709 , 2.0921 , 2.0166 , 1.9442 , 1.8749 , 1.8086 , 1.7449, 1.6839 , 1.6254 , 1.5693 , 1.5154 , 1.4637 , 1.4141 , 1.3664 , 1.3207 , 1.2767 , 1.2344, 1.1938 , 1.1548 , 1.1172 , 1.0811 , 1.0463 , 1.0128 , 0.98063 , 0.94961 , 0.91974 , 0.89097, 0.86325 , 0.83654 , 0.81079 , 0.78596 , 0.76202 , 0.73894 , 0.71667 , 0.69518 , 0.67444 , 0.65443, 0.63512 , 0.61647 , 0.59846 , 0.58107 , 0.56427 , 0.54804 , 0.53237 , 0.51722 , 0.50258 , 0.48843, 0.47475 , 0.46153 , 0.44875 , 0.43639 , 0.42443 , 0.41288 , 0.4017 , 0.39089 , 0.38043 , 0.37031, 0.36052 , 0.35105 , 0.34189 , 0.33303 , 0.32445 , 0.31616 , 0.30813 , 0.30035 , 0.29284 , 0.28556, 0.27852 , 0.2717 , 0.26511 , 0.25873 , 0.25255 , 0.24658 , }; int create_fibonacci(unsigned int **fib_table, int buf_size) { int tmp[3] = {1, 1, 2}; int count = 3; unsigned int *table = NULL; if (buf_size < 2) { printf("buf too short!\n"); return -1; } while (tmp[2] < buf_size) { tmp[0] = tmp[1]; tmp[1] = tmp[2]; tmp[2] = tmp[0] + tmp[1]; count ++; } table = (unsigned int *)malloc(count * sizeof(unsigned int)); memset(table, 0, count * sizeof(unsigned int)); table[0] = 1; table[1] = 1; for (int i = 2; i < count; i++) { table[i] = table[i - 1] + table[i -2]; } *fib_table = table; return count; } int search_fibonacci_with_fib(const int *fib_table, float elem,const float *table, int table_size) { int k = 0; int left = 0, right = 0, mid = 0; int count = 0; while (fib_table[k] < table_size) { k ++; } right = table_size - 1; left = 0; //可增加针对elem在right右侧情况单独处理 while (left < right) { mid = left + fib_table[k - 1]; if (table[mid] > elem) { /* 目标元素在黄金分割线右侧 注意:此处由于table是降序 所以是'>' !!! */ left = mid; k = k - 1; } else if (table[mid] < elem) { /* 目标元素在黄金分割线左侧 注意:此处由于table是降序 所以是'<' !!! */ right = mid; k = k - 2; } else { break; } if (k < 0) { mid = left; /* 温度取低温测值 */ break; } count ++; } printf("count: %d\n", count); return mid; } int main(int argc, char **argv) { printf("\nfibonacci search:\n"); unsigned int *fib_table = NULL; int count = 0; int temp = 0; /* 根据所需数据动态创建斐波拉契数列 */ count = create_fibonacci(&fib_table, sizeof(temperature)/sizeof(temperature[0])); for (int i = 0; i < count; i ++) printf("%d ", fib_table[i]); printf("\n"); /* 斐波拉契查找 */ temp = search_fibonacci_with_fib(fib_table, 17.5f, temperature, sizeof(temperature)/sizeof(temperature[0])); temp -= 40; printf("temperature is:%d\n", temp); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
运行结果如下:
fibonacci search: 1 1 2 3 5 8 13 21 34 55 89 144 233 count: 8 temperature is:5- 1
- 2
- 3
- 4
在上述代码中,采用
create_fibonacci根据待查找数组大小动态创建斐波拉契数组,需要注意的是,我们这采用的是NTC电阻,由于NTC电阻的特性,待查找数组是降序,因此斐波拉契查找运算中的大小比较符号需要特别注意!!采用第一节中的实例,同样的目标数组,这是我们进行对比实验之后的运行结果:
dichotomy search: mid:45 left:45 right:46 count = 24 temperature is:5 fibonacci search: 1 1 2 3 5 8 13 21 34 55 89 144 233 count: 8 temperature is:5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
通过此结果中两者循环查找的次数进行比较我们可以发现:采用斐波拉契查找只循环了8次便找到了目标数据,而二分查找需要循环24次,斐波拉契查找远胜于二分查找!!!
同样,如果待查找数据数据更大,斐波拉契的效率会要更高!
4. 线性索引查找
4.1 算法叙述
//TODO
4.2 实例说明
//TODO
由于精力有限,因此本博文将分多次更新,感谢您的关注!
创作不易,转载请注明出处!
关注、点赞+收藏,可快速查看后续分享哦!
-
-
相关阅读:
Docker 运行percona tokudb 引擎
Win10无法访问移动硬盘怎么解决
现货白银需要注意八大事项
vscode 搜索界面的files to include files to exclude 是什么功能?
三万字带你了解那些年面过的Java八股文
SpringBoot中优雅地实现统一响应对象
Java的AQS是个什么东西?它的原理你知道吗?
常用软件安装包
MyBatis-Plus(二、常用注解)
(标签-ar|关键词-运算符)
- 原文地址:https://blog.csdn.net/qq_43332314/article/details/128067109
