-
Zookeeper
一、Zookeeper 简介
1、Zookeeper是什么?
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目
Zookeeper的工作机制:

2、Zookeeper特点

- Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按照其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,client能读到最新数据
3、数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个
节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过
其路径唯一标识。

4、应用场景
常用的场景有:
- 服务注册中心
- 分布式锁
- 统一配置管理

5、下载
官网地址:https://zookeeper.apache.org/
二、Zookeeper单机安装
1、安装前的一些前置准备工作
1)安装JDK
见博客:https://blog.csdn.net/hc1285653662/article/details/1280700192)将zookeeper的安装包拷贝到Linux系统中

- 解压并且将名称修改为 zookeeper-3.5.7
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz

2、配置修改
1)将 /mydata/zookeeper/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 拷贝一份,修改为 zoo.cfg

2)打开 zoo.cfg 文件,修改 dataDir 路径
/mysoft/zookeeper/zookeeper-3.5.7/zkData

在上述路径下创建zkData文件夹

3、Zookeeper的简单操作
启动zookeeper:
./zkServer.sh start- 1
查看zookeeper 的启动状态
./zkServer.sh status- 1

启动zk客户端
./zkCli.sh- 1
停止客户端
quit- 1
停止 Zookeeper
./zkServer.sh stop- 1
【补充】 设置zookeeper开机自启动
1)vim /etc/rc.local 并加入以下两行命令export JAVA_HOME=/mysoft/jdk/jdk1.8.0_251 /mysoft/zookeeper/zookeeper-3.5.7/bin/zkServer.sh start- 1
- 2

2)重启虚拟机4、配置参数解读
- tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
- initLimit = 10:LF初始通信时限(Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量))
- syncLimit = 5:LF同步通信时限 (Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死)
- dataDir:Zookeeper中的数据的保存目录
- clientPort = 2181:客户端连接端口,通常不做修改
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
三、zookeeper的集群操作
3.1、集群安装
3.1.1 集群安装
1)集群规划
在 192.168.239.11、192.168.239.12和 192.168.239.13三个虚拟机节点上都部署 Zookeeper2)三个虚拟机上安装zookeeper,并配置好 dataDir文件夹,单机的安装方式可以参考上面!!
3)在三台机器的配置服务器编号
在/mysoft/zookeeper/data 目录下创建一个 myid 的文件
在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)


4)配置zoo.cfg文件
增加如下配置server.1=192.168.239.11:2888:3888 server.2=192.168.239.12:2888:3888 server.3=192.168.239.13:2888:3888- 1
- 2
- 3
配置参数解读
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口5)分别启动三个zookeeper服务
bin/zkServer.sh start查看三个zookeeper服务的状态
bin/zkServer.sh status
发现节点1是主节点,其他两个节点是从节点

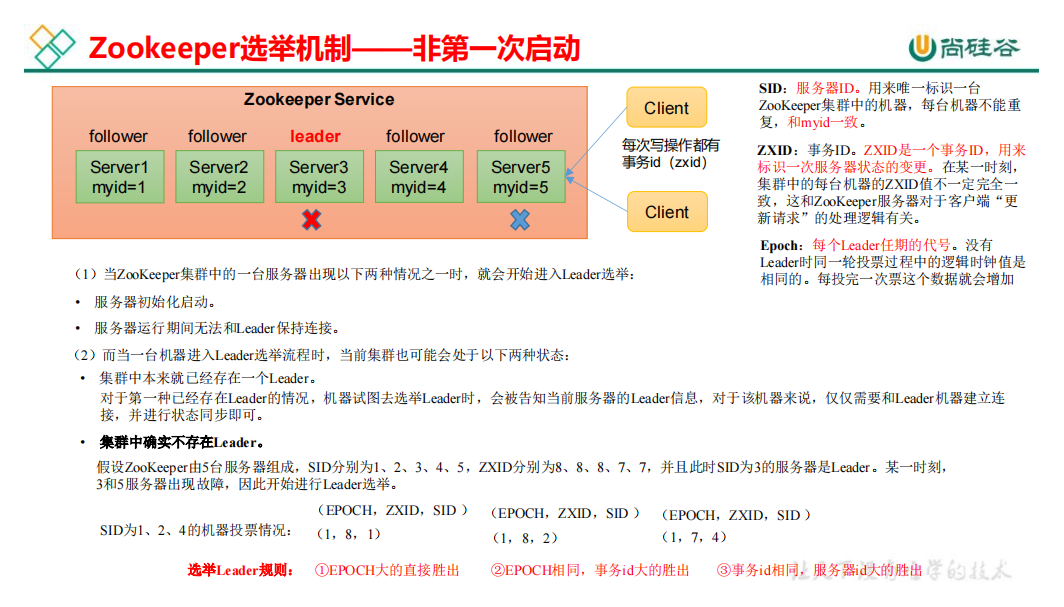
3.1.2 选举机制(面试重点)

3.2 命令行语法
参考博客 https://blog.csdn.net/hc1285653662/article/details/131936308
3.3 客户端操作
public class TestZookeeper { // 2181 : 访问 zookeeper集群的端口号 private String connectString = "172.20.10.14:2181,172.20.10.4:2181,172.20.10.5:2181"; private int sessionTimeout = 2000; private ZooKeeper zkClient; @Before public void init() throws IOException { zkClient = new ZooKeeper(connectString, 2000, new Watcher() { @Override public void process(WatchedEvent watchedEvent) { } }); } //创建节点 @Test public void create() throws Exception { // 参数1:要创建的节点的路径; // 参数2:节点数据 ; // 参数3:节点权限 ; // 参数4:节点的类型 String nodeCreated = zkClient.create("/atguigu", "jinlian".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println(nodeCreated); } //创建子节点并监控数据的变化 @Test public void getDataAndWatch() throws Exception { List<String> children = zkClient.getChildren("/", false); for (String s:children){ System.out.println(s); } } // 判断znode是否存在 @Test public void exist() throws Exception { Stat stat = zkClient.exists("/sanguo", false); System.out.println(stat == null ? "not exist" : "exist"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
3.4 客户端向服务端写数据流程
在ZooKeeper集群中,客户端向Leader写数据的流程如下:
-
客户端连接到ZooKeeper集群: 客户端首先需要建立与ZooKeeper集群的连接。客户端通常会指定一个或多个ZooKeeper服务器的地址,然后尝试连接到这些服务器中的一个。一旦连接建立,客户端就可以开始与ZooKeeper交互。
-
客户端发送写请求给Leader: 客户端向当前的Leader节点发送写请求。Leader节点负责协调写操作。客户端可以向Leader节点发送创建、更新或删除ZooKeeper节点的请求。
-
Leader验证并处理请求: Leader节点接收客户端的写请求后,首先会验证请求的有效性。这包括检查请求是否符合ZooKeeper的数据模型和权限设置。如果请求有效,Leader节点会处理请求,并将其转化为一个事务。
-
Leader将事务广播给Follower节点: 一旦Leader节点生成了事务,它将该事务广播给所有的Follower节点,包括Observer节点。这确保了数据的复制和一致性。Follower节点在收到事务后会异步地应用该事务,以保持数据一致。
-
Leader等待大多数Follower节点确认: Leader节点等待大多数Follower节点确认已经应用了该事务。在大多数Follower节点确认后,Leader认为该事务已经被提交。
-
Leader响应客户端: 一旦Leader节点确认事务已提交,它会向客户端发送成功响应。客户端可以收到响应后,知道写操作已成功执行。
-
客户端处理响应: 客户端在收到成功响应后,可以继续其后续操作,如读取数据或执行其他操作。
-
Leader向Follower节点广播事务快照: 随着时间的推移,Leader节点会向Follower节点定期广播事务快照,以便Follower节点能够追赶上数据更新的进度。这确保了Follower节点和Leader节点之间的数据一致性。
总之,客户端向ZooKeeper Leader节点写数据的流程涉及客户端连接到Leader节点,向Leader发送写请求,Leader节点验证、处理请求,然后广播事务给Follower节点,最后向客户端发送成功响应。这个过程确保了数据的一致性和可靠性。
四、服务器动态上下线监听案例
略
五、Zookeeper实现分布式锁
https://blog.csdn.net/hc1285653662/article/details/131869318
-
相关阅读:
【PB续命04】借用Oracle的加密解密续命
R语言进行数据分组聚合统计变换(Aggregating transforms)、计算dataframe数据的分组最小值(min)
游戏遇到的问题
【AICFD案例教程】轴流风扇仿真分析
2022年最新宁夏建筑八大员(材料员)模拟考试试题及答案
京东云开发者|mysql基于binlake同步ES积压解决方案
LQ0047 最大比例【GCD】
事务提交之后再执行某些操作 → 你有哪些实现方式?
Linux文件系统
[附源码]Java计算机毕业设计SSM钓鱼爱好者交流平台
- 原文地址:https://blog.csdn.net/hc1285653662/article/details/128050583
