-
计算机网络笔记【面试】
计算机网络笔记【面试】
前言
以下内容源自xiaolincoding
仅供学习交流使用推荐
计算机网络笔记
二、基础篇
综上所述,TCP/IP 网络通常是由上到下分成 4 层,分别是应用层,传输层,网络层和网络接口层。
三、HTTP篇
3.9 既然有 HTTP 协议,为什么还要有 WebSocket?
四、TCP 篇
4.1 TCP 三次握手与四次挥手面试题
什么是 TCP ?
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。

面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。
UDP 和 TCP 有什么区别呢?分别的应用场景是?
TCP 和 UDP 区别:
1. 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
2. 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
3. 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议,具体可以参见这篇文章:如何基于 UDP 协议实现可靠传输?(opens new window)
4. 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5. 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。
- UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
6. 传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠。
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7. 分片不同
- TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
- UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
- FTP 文件传输;
- HTTP / HTTPS;
由于 UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,因此经常用于:
- 包总量较少的通信,如 DNS 、SNMP 等;
- 视频、音频等多媒体通信;
- 广播通信;
TCP 连接建立
TCP 三次握手过程是怎样的?
TCP 是面向连接的协议,所以使用 TCP 前必须先建立连接,而建立连接是通过三次握手来进行的。三次握手的过程如下图:

- 一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态客户端会随机初始化序号
- (client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN 标志位置为 1 ,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
- 服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
- 客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。
- 服务端收到客户端的应答报文后,也进入 ESTABLISHED 状态。
从上面的过程可以发现第三次握手是可以携带数据的,前两次握手是不可以携带数据的,这也是面试常问的题。
一旦完成三次握手,双方都处于 ESTABLISHED 状态,此时连接就已建立完成,客户端和服务端就可以相互发送数据了。
为什么是三次握手?不是两次、四次?
接下来,以三个方面分析三次握手的原因:
- 三次握手才可以阻止重复历史连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
-三次握手才可以避免资源浪费
小结
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
不使用「两次握手」和「四次握手」的原因:
- 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
TCP 连接断开
TCP 四次挥手过程是怎样的?

- 客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1 的报文,也即 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。
- 服务端收到该报文后,就向客户端发送 ACK 应答报文,接着服务端进入 CLOSE_WAIT 状态。
- 客户端收到服务端的 ACK 应答报文后,之后进入 FIN_WAIT_2 状态。
- 等待服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。
- 客户端收到服务端的 FIN 报文后,回一个 ACK 应答报文,之后进入 TIME_WAIT 状态
- 服务端收到了 ACK 应答报文后,就进入了 CLOSE 状态,至此服务端已经完成连接的关闭。
- 客户端在经过 2MSL 一段时间后,自动进入 CLOSE 状态,至此客户端也完成连接的关闭。
你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。
这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
为什么挥手需要四次?
再来回顾下四次挥手双方发 FIN 包的过程,就能理解为什么需要四次了。
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务端收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送
FIN 报文给客户端来表示同意现在关闭连接。
从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN 一般都会分开发送,因此是需要四次挥手。
当被动关闭方在 TCP 挥手过程中,如果「没有数据要发送」,同时「没有开启 TCP_QUICKACK(默认情况就是没有开启,没有开启 TCP_QUICKACK,等于就是在使用 TCP 延迟确认机制)」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
但是在特定情况下,四次挥手是可以变成三次挥手的,具体情况可以看这篇:TCP 四次挥手,可以变成三次吗?(opens new window)
所以,出现三次挥手现象,是因为 TCP 延迟确认机制导致的。
4.2 TCP 重传、滑动窗口、流量控制、拥塞控制

重传机制
接下来说说常见的重传机制:
- 超时重传
- 快速重传
- SACK
- D-SACK
超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据,也就是我们常说的超时重传。
快速重传
所以,快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传一个,还是重传所有的问题。
可以看到,不管是重传一个报文,还是重传已发送的报文,都存在问题。
为了解决不知道该重传哪些 TCP 报文,于是就有 SACK 方法。
SACK 方法
还有一种实现重传机制的方式叫:SACK( Selective Acknowledgment), 选择性确认。
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
Duplicate SACK
Duplicate SACK 又称 D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
下面举例两个栗子,来说明 D-SACK 的作用。
可见,D-SACK 有这么几个好处:
- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
- 可以知道是不是「发送方」的数据包被网络延迟了;
- 可以知道网络中是不是把「发送方」的数据包给复制了;
滑动窗口
发送方的滑动窗口

接收方的滑动窗口
流量控制
拥塞控制
于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。
为了在「发送方」调节所要发送数据的量,定义了一个叫做「拥塞窗口」的
拥塞控制主要是四个算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢启动
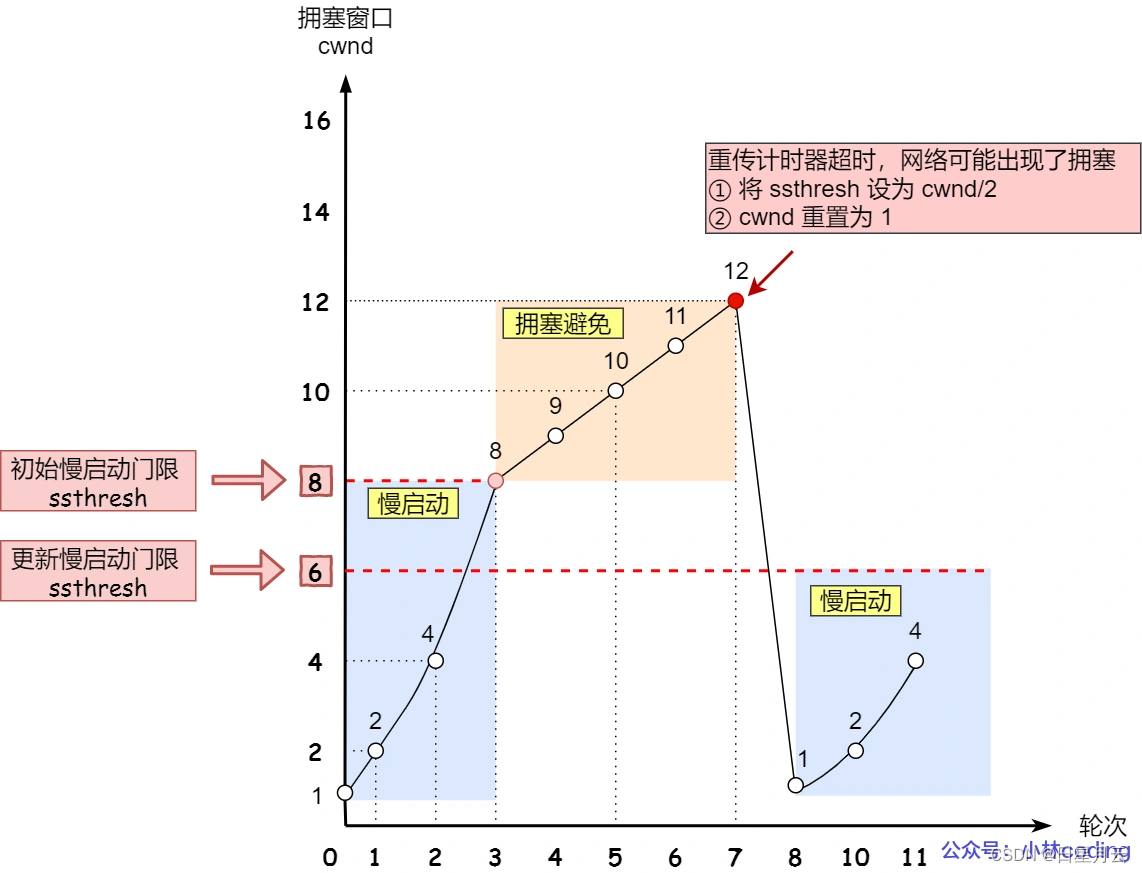
TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量,如果一上来就发大量的数据,这不是给网络添堵吗?
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这里假定拥塞窗口 cwnd 和发送窗口 swnd 相等,下面举个栗子:

那慢启动涨到什么时候是个头呢?
有一个叫慢启动门限 ssthresh (slow start threshold)状态变量。
- 当 cwnd < ssthresh 时,使用慢启动算法。
- 当 cwnd >= ssthresh 时,就会使用「拥塞避免算法」。
拥塞避免算法
那么进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。

所以,我们可以发现,拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。
就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。
当触发了重传机制,也就进入了「拥塞发生算法」。
拥塞发生
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种:
- 超时重传
- 快速重传
这两种使用的拥塞发送算法是不同的,接下来分别来说说。
发生超时重传的拥塞发生算法
当发生了「超时重传」,则就会使用拥塞发生算法。
这个时候,ssthresh 和 cwnd 的值会发生变化:
ssthresh设为cwnd/2,cwnd重置为1(是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)
发生快速重传的拥塞发生算法
还有更好的方式,前面我们讲过「快速重传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
cwnd = cwnd/2,也就是设置为原来的一半;
-ssthresh = cwnd;- 进入快速恢复算法
快速恢复
然后,进入快速恢复算法如下:
- 拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了);
- 重传丢失的数据包;
- 如果再收到重复的 ACK,那么 cwnd 增加 1;
- 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
快速恢复算法的变化过程如下图:

最后
2022-11-25 11:09:30
这篇博客能写好的原因是:站在巨人的肩膀上
这篇博客要写好的目的是:做别人的肩膀
开源:为爱发电
学习:为我而行
-
相关阅读:
100天精通Golang(基础入门篇)——第20天:Golang 接口 深度解析☞从基础到高级
SQL学习十七、事务处理
反沙箱方法
深入理解并发三大特性
微信小程序会议OA系统其他页面
Python的21天学习总结
Java 与 Go:可变数组
【Vant2】Tab标签页组件自动跳转的坑
遥测、遥信、遥控、定值?IEC61850?-----极简记录
上周热点回顾(12.18-12.24)
- 原文地址:https://blog.csdn.net/qq_51625007/article/details/128032911