-
[毕业设计]大数据电影数据分析可视化
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯大数据电影数据分析可视化
课题背景和意义
由于最近《哪吒之魔童降世》的火爆,最新票房已经超过49亿,使我对国内票房的整体走势有了很大兴趣,究竟49亿的票房数据,在国内是处于一个什么水平?除了票房数据,又有哪些特征因素可以用来形容一部优秀的影片呢?通过可视化分析的方式,直观地展示国内影片票房的概况。
实现技术思路
网页分析

索引页
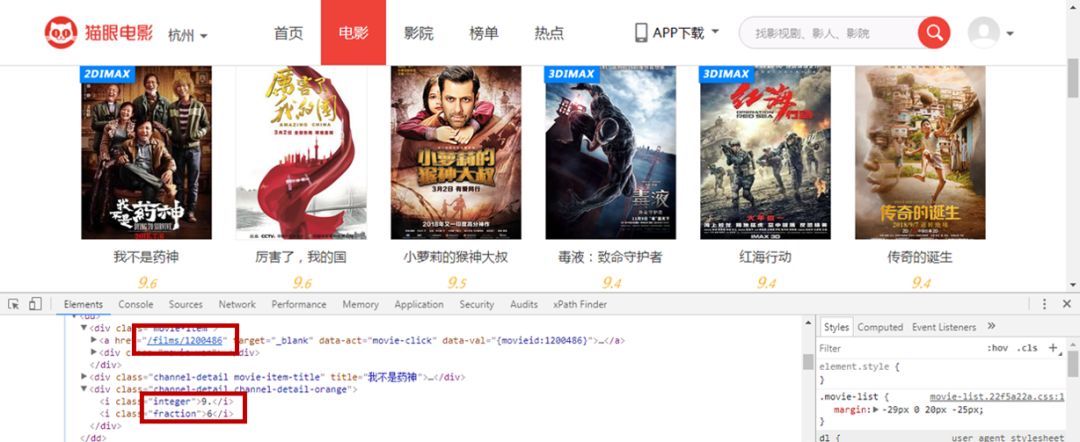
通过点击猫眼电影已经归类好的标签,得到网址信息。
打开开发人员工具,获取索引页里电影的链接以及评分信息。
索引页一共有30多页,但是有电影评分的只有10页。
本次只对有电影评分的数据进行获取。
详情页

对详情页的信息进行获取。
主要是名称,类型,国家,时长,上映时间,评分,评分人数,累计票房。
反爬破解

通过开发人员工具发现,猫眼针对评分,评分人数,累计票房的数据,施加了文字反爬。

通过查看网页源码,发现只要刷新页面,三处文字编码就会改变,无法直接匹配信息。
所以需要下载文字文件,对其进行双匹配。
- from fontTools.ttLib import TTFont
- #font = TTFont('base.woff')
- #font.saveXML('base.xml')
- font = TTFont('maoyan.woff')
- font.saveXML('maoyan.xml')
将woff格式转换为xml格式,以便在Pycharm中查看详细信息。
利用下面这个网站,打开woff文件。
url: http://fontstore.baidu.com/static/editor/index.html
可以得到下面数字部分信息(上下两块)。
在Pycharm中查看xml格式文件(左右两块),你就会发现有对应信息。

- def get_numbers(u):
- """
- 对猫眼的文字反爬进行破解
- """
- cmp = re.compile(",\n url\('(//.*.woff)'\) format\('woff'\)")
- rst = cmp.findall(u)
- ttf = requests.get("http:" + rst[0], stream=True)
- with open("maoyan.woff", "wb") as pdf:
- for chunk in ttf.iter_content(chunk_size=1024):
- if chunk:
- pdf.write(chunk)
- base_font = TTFont('base.woff')
- maoyanFont = TTFont('maoyan.woff')
- maoyan_unicode_list = maoyanFont['cmap'].tables[0].ttFont.getGlyphOrder()
- maoyan_num_list = []
- base_num_list = ['.', '3', '0', '8', '9', '4', '1', '5', '2', '7', '6']
- base_unicode_list = ['x', 'uniF561', 'uniE6E1', 'uniF125', 'uniF83F', 'uniE9E2', 'uniEEA6', 'uniEEC2', 'uniED38', 'uniE538', 'uniF8E7']
- for i in range(1, 12):
- maoyan_glyph = maoyanFont['glyf'][maoyan_unicode_list[i]]
- for j in range(11):
- base_glyph = base_font['glyf'][base_unicode_list[j]]
- if maoyan_glyph == base_glyph:
- maoyan_num_list.append(base_num_list[j])
- break
- maoyan_unicode_list[1] = 'uni0078'
- utf8List = [eval(r"'\u" + uni[3:] + "'").encode("utf-8") for uni in maoyan_unicode_list[1:]]
- utf8last = []
- for i in range(len(utf8List)):
- utf8List[i] = str(utf8List[i], encoding='utf-8')
- utf8last.append(utf8List[i])
- return (maoyan_num_list ,utf8last)
通过上图你就可以将数字6对上号了,其他数字一样的。
实现效果图样例



我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
-
相关阅读:
被欧美公司垄断近 20 年,中国工业软件的机会在哪里?
深入理解Java注解的实现原理以及前世今生
铁路轨道设备概述1:铁路轨道基础设备
Servlet(Cookie和Session)
【Android Framework系列】第15章 Fragment+ViewPager与Viewpager2相关原理
力扣代码学习日记八
Qt基础之四十六:Qt界面中嵌入第三方程序的一点心得
c语言基础学习笔记(二):条件判断语句if-else嵌套和switch-case语句
Design A Twitter
Python+requests编写的自动化测试项目
- 原文地址:https://blog.csdn.net/qq_37340229/article/details/128040369
