-
Transformer Fusion for Indoor RGB-D Semantic Segmentation非官方自己实现的代码

声明:文章没有官方的代码,这里自己浅显的分析一下。
首先看一下encoder,就是swin transformer,假设RGB的维度为(1,3,480,480),Depth维度为(1,1,480,480)。维度分别变为**(1,64,120,120)—>(1,64,120,120)—>(1,128,60,60)—>(1,256,30,30)—>(1,512,15,15)。**
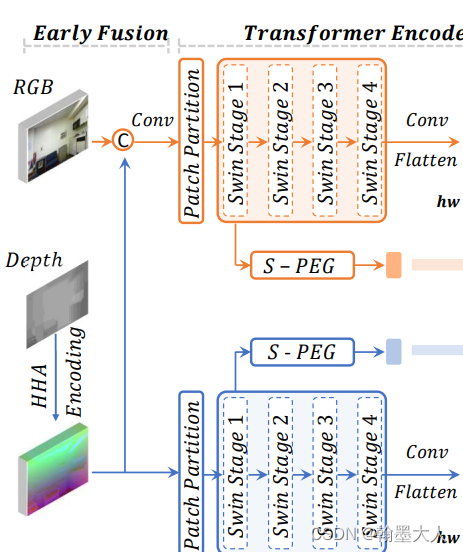
接着经过卷积,然后展平。在原文中,通道进行了减少,假设我们这里通过一个1x1卷积,将通道由512缩减到256.然后进行展平,(1,256,15,15)展平为(1,256,225)。

接着输入到三步融合模块中。
首先大小和维度经过融合后是不发生变换的。即输出也为(1,256,225)。

然后就是图中的位置编码:
既然他能和K和Q进行相加,那么维度肯定是匹配的。
公式:我们可以看到位置编码是在生成Q,K,V之后才加上的。而非先加上再生成Q,K,V因为V就没有加位置编码。且这个地方采用的多头,对每一个头的Q和V进行相加。


把公式5括号里面的参数带入到multihead(Q,K,V)中。

关于这个地方位置编码的相加存在一些疑问:
首先他的计算方式和VIT的一样,没有什么不同,但是关键在于只对Q和K进行相加,对V没有加。
我们看VIT的维度变化,VIT使用了多头注意力计算。本来每个头的Q,K,V都计算一次,即每次只有一个头,有多少个头计算多少次,然后总的结果按照维度进行拼接。
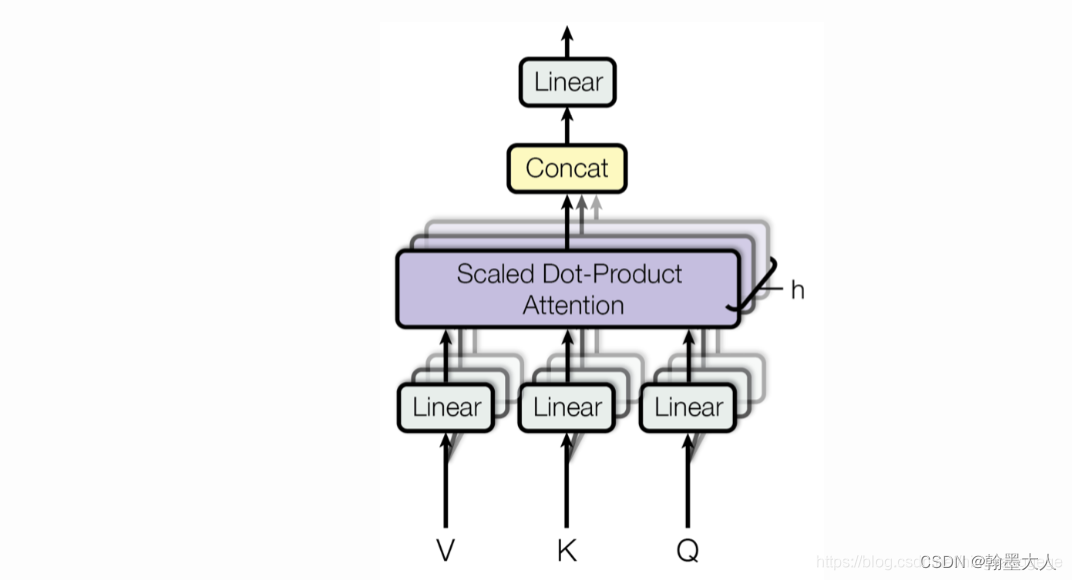
在代码中(12个头),实现的是Q,K,V有12个头,Q,K,V总共只计算一次。

在本文中,位置编码为第一个stage的输出,即(1,14400,64)。经过reshape为图片(1,64,120,120)。我们知道self.attention的输入为(1,225,256)。那么如果要相加,需要把维度升高到256,即原文中的投影到高维空间(语义信息就更丰富)。然后经过两个3x3卷积进行局部特征提取,最后进行下采样,reshape到序列。
我们猜测一下(1,64,120,120)—>(1,256,120,120)—>(1,256,120,120)—>(1,256,120,120)—>(1,256,15,15)—>(1,225,256)

然后回到融合部分,输入master序列为(1,225,256),经过类似VIT线性投影操作,生成Q,K,V,和VIT一样是多头,那么假设有8个头,那么Q,K,V的维度分别为(1,8,225,32)。然后就是位置编码(1,225,256)经过reshape,即分为八个头,每个头维度为(1,225,32)。这样就可以和Q,V进行相加。至于为什么V不加位置编码,我也不晓得。难道是为了和后面保持一致?补充序列也一样。后面的交叉注意力:和前面的基本一样,区别是:上下两个分支的Q和Q带的位置编码分别来自对方。因为他们两个分支的头一样,维度一样,只有模态不一样,所以进行相乘还是不难的,还有就是位置编码和前一个自注意力使用的是一样的,即一个来自stage1的位置编码全程使用。

最后是深度引导,上一个模块的辅助分支的输出(1,225,256),仍然经过线性投影为多头。他进行qkv生成时候的linear就不需要x3了,,因为他只有一个输出。同理主分支也只需生成两个分支,embed_dim扩大两倍。最后在reshape为图片大小,即(1,256,15,15)。
decoder:八倍上采样。

自己写的代码,很粗糙,其中将swin transformer转换为了resnet34,这样结构简单了点,而且每一层的输出都是图片,避免了位置编码还要将序列转换为图片。都是一些很简单的函数,如有错误,欢迎指正。import warnings import numpy as np import torch import torch.nn as nn import torch.nn.functional as F from torchsummary import summary # from src.models.refine import Refine from src.models.resnet import ResNet34 from src.models.context_modules import get_context_module from src.models.resnet import BasicBlock, NonBottleneck1D # from src.models.model_utils import ConvBNAct, Swish, Hswish # conding=gb2312 def convt_bn_relu(ch_in, ch_out, kernel=3, stride=2, padding=1, output_padding=1, bn=True, relu=True): assert (kernel % 2) == 1, \ 'only odd kernel is supported but kernel = {}'.format(kernel) layers = [] layers.append(nn.ConvTranspose2d(ch_in, ch_out, kernel, stride, padding, output_padding, bias=not bn)) if bn: layers.append(nn.BatchNorm2d(ch_out)) if relu: layers.append(nn.ReLU(inplace=True)) layers = nn.Sequential(*layers) return layers def conv_bn_relu(ch_in, ch_out, kernel, stride=1, padding=0, bn=True,relu=True): assert (kernel % 2) == 1, \ 'only odd kernel is supported but kernel = {}'.format(kernel) layers = [] layers.append(nn.Conv2d(ch_in, ch_out, kernel, stride, padding, bias=not bn)) if bn: layers.append(nn.BatchNorm2d(ch_out)) if relu: layers.append(nn.ReLU(inplace=True)) layers = nn.Sequential(*layers) return layers def drop_path(x, drop_prob: float = 0., training: bool = False): if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output class DropPath(nn.Module): def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) class Mlp(nn.Module): """ MLP as used in Vision Transformer, MLP-Mixer and related networks """ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x class Spge(nn.Module): def __init__(self, in_channels, ): super(Spge, self).__init__() self.spge_rgb = nn.Sequential( nn.Conv2d(in_channels, in_channels * 4, kernel_size=1, stride=1, padding=0), conv_bn_relu(in_channels * 4, in_channels * 4, kernel=3, padding=1, bn=True, relu=True), conv_bn_relu(in_channels * 4, in_channels * 4, kernel=3, padding=1, bn=True, relu=True) ) self.spge_depth = nn.Sequential( nn.Conv2d(in_channels, in_channels * 4, kernel_size=1, stride=1, padding=0), conv_bn_relu(in_channels * 4, in_channels * 4, kernel=3, padding=1, bn=True, relu=True), conv_bn_relu(in_channels * 4, in_channels * 4, kernel=3, padding=1, bn=True, relu=True) ) def forward(self,rgb,depth): #(1,64,120,120) _,_,h,w = rgb.size() rgb_f = self.spge_rgb(rgb)#(1,256,120,120) depth_f = self.spge_depth(depth)#(1,256,120,120) rgb_f_1 = F.interpolate(rgb_f,size=(h//8,w//8),mode='nearest').flatten(2).permute(0,2,1)#(1,256,15,15) depth_f_1 = F.interpolate(depth_f,size=(h//8,w//8),mode='nearest').flatten(2).permute(0,2,1)#(1,256,15,15) return rgb_f_1 ,depth_f_1 class Attention(nn.Module): def __init__(self, dim, # 输入token的dim num_heads=8, qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0.): super(Attention, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.pos = nn.Linear(dim, dim, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_ratio) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio) def forward(self, x ,pe): # [batch_size, num_patches + 1, total_embed_dim] B, N, C = x.shape #(1,225,256) b, n, c = pe.shape#(1,225,256) posenc = self.pos(pe).reshape(b, n, self.num_heads, c // self.num_heads).permute(0,2,1,3)#(1,8,225,32) # qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] # reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] # permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head] qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)#(3,1,8,225,32) # [batch_size, num_heads, num_patches + 1, embed_dim_per_head] # q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) q = qkv[0] + posenc #(1,8,225,32) k = qkv[1] + posenc #(1,8,225,32) v = qkv[2] #(1,8,225,32) # transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1] # @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1] attn = (q @ k.transpose(-2, -1)) * self.scale#(1,8,225,225) attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) # @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head] # transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head] # reshape: -> [batch_size, num_patches + 1, total_embed_dim] x = (attn @ v).transpose(1, 2).reshape(B, N, C) #(1,225,256) x = self.proj(x) x = self.proj_drop(x) return x class Attention_c(nn.Module): def __init__(self, dim, # 输入token的dim num_heads=8, qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0.): super(Attention_c, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.pos = nn.Linear(dim, dim, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_ratio) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio) def forward(self, x ,y, x_pos, y_pos): #(depth_s,rgb_s,depth_pe,rgb_pe) B, N, C = x.shape #(1,225,256) b, n, c = x_pos.shape#(1,225,256) x_pos = self.pos(x_pos).reshape(b, n,self.num_heads, c // self.num_heads).permute(0,2,1,3)#(1,8,225,32) y_pos = self.pos(y_pos).reshape(b, n,self.num_heads, c // self.num_heads).permute(0,2,1,3)#(1,8,225,32) qkv_x = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)#(3,1,8,225,32) qkv_y = self.qkv(y).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)#(3,1,8,225,32) q = qkv_y[0] + y_pos #(1,8,225,32) k = qkv_x[1] + x_pos #(1,8,225,32) v = qkv_x[2]#(1,8,225,32) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x class Attention_g(nn.Module): def __init__(self, dim, # 输入token的dim num_heads=8, qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0.): super(Attention_g, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv_x = nn.Linear(dim, dim * 3, bias=qkv_bias) self.qkv_y = nn.Linear(dim, dim,bias=qkv_bias) self.pos = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_ratio) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio) def forward(self, x ,y, x_pos, y_pos): B, N, C = x.shape #(1,225,256) b, n, c = x_pos.shape x_pos = self.pos(x_pos).reshape(b, n, 3, self.num_heads, c // self.num_heads).permute(2, 0, 3, 1, 4) y_pos = self.pos(y_pos).reshape(b, n, 3, self.num_heads, c // self.num_heads).permute(2, 0, 3, 1, 4) qkv_x = self.qkv_x(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) qkv_y = self.qkv_y(y).reshape(B, N, self.num_heads, C // self.num_heads).permute(0,2,1,3) q = qkv_y+ y_pos k = qkv_x[1] + x_pos v = qkv_x[2] attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x class Block_s(nn.Module): def __init__(self, dim=256, num_heads=8, qkv_bias=False, qk_scale=None, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., norm_layer=nn.LayerNorm): super(Block_s, self).__init__() self.norm1 = norm_layer(dim) self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) def forward(self, x,rgb_pos): x = x + self.drop_path(self.attn(self.norm1(x),rgb_pos)) #(1,225,256) return x class Block_c(nn.Module): def __init__(self, dim, num_heads, qkv_bias=False, qk_scale=None, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., norm_layer=nn.LayerNorm): super(Block_c, self).__init__() self.norm1 = norm_layer(dim) self.attn_c = Attention_c(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) def forward(self, x,y,rgb_pos,depth_pos): x = x + self.drop_path(self.attn_c(self.norm1(x),self.norm2(y),rgb_pos,depth_pos))#(1,225,256) return x class Block_g(nn.Module): def __init__(self, dim, num_heads, qkv_bias=False, qk_scale=None, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., norm_layer=nn.LayerNorm): super(Block_g, self).__init__() self.norm1 = norm_layer(dim) self.attn_c = Attention_c(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) def forward(self, x,y,rgb_pos,depth_pos): x = x + self.drop_path(self.attn_g(self.norm1(x),self.norm2(y),rgb_pos,depth_pos)) return x class Transformer_fusion(nn.Module): def __init__(self, num_heads=8, qkv_bias = False, embed_dim =256, qk_scale = None, drop_ratio = 0.1, attn_drop_ratio =0., drop_path_ratio =0., norm_layer = nn.LayerNorm, ): super(Transformer_fusion,self).__init__() self.rgb_out = Block_s(dim=embed_dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=drop_path_ratio, norm_layer=norm_layer) self.depth_out = Block_s(dim=embed_dim, num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=drop_path_ratio, norm_layer=norm_layer) self.rgb_c = Block_c(dim=embed_dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=drop_path_ratio, norm_layer=norm_layer) self.depth_c = Block_c(dim=embed_dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=drop_path_ratio, norm_layer=norm_layer) self.rgb_g = Block_g(dim=embed_dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=drop_path_ratio, norm_layer=norm_layer) self.norm_rgb = norm_layer(embed_dim) self.norm_depth = norm_layer(embed_dim) def forward(self,rgb,depth,rgb_pe,depth_pe): b,n,c = rgb.shape #(1,225,256) rgb_s = self.rgb_out (rgb,rgb_pe)#(1,225,256) depth_s = self.depth_out(depth,depth_pe)#(1,225,256) rgb_c = self.rgb_c (rgb_s,depth_s,rgb_pe,depth_pe)#(1,225,256) depth_c = self.depth_c (depth_s,rgb_s,depth_pe,rgb_pe)#(1,225,256) rgb_g = self.rgb_g(rgb_c,depth_c,rgb_pe,depth_pe)#(1,225,256) out = rgb_g.reshape(b,c,int(np.sqrt(n)),int(np.sqrt(n)))#(1,256,15,15) return out class DeepLabV3Plus(nn.Module): def __init__(self, in_channels=[64, 128, 256, 512], num_classes=40, norm_layer=nn.BatchNorm2d): super(DeepLabV3Plus, self).__init__() self.num_classes = num_classes self.aspp = ASPP(in_channels=in_channels[2], atrous_rates=[6, 12, 18], norm_layer=norm_layer) self.low_level = nn.Sequential( nn.Conv2d(in_channels[0], 256, kernel_size=3, stride=1, padding=1), norm_layer(256), nn.ReLU(inplace=True) ) self.block = nn.Sequential( nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1), norm_layer(256), nn.ReLU(inplace=True), convt_bn_relu(256,128,kernel=3,stride=4,padding=1,output_padding=3), nn.Dropout(0.1), nn.Conv2d(128, num_classes, 1)) def forward(self, c1,c4): #(1,64,120,120)/(1,512,15,15) c1 = self.low_level(c1)#(1,256,120,120) c4 = self.aspp(c4)#(1,256,15,15) c4 = F.interpolate(c4, c1.size()[2:], mode='bilinear', align_corners=True)#(1,256,120,120) output = self.block(torch.cat([c4, c1], dim=1)) #(1,40,480,480) return output class ASPPConv(nn.Module): def __init__(self, in_channels, out_channels, atrous_rate, norm_layer): super(ASPPConv, self).__init__() self.block = nn.Sequential( nn.Conv2d(in_channels, out_channels, 3, padding=atrous_rate, dilation=atrous_rate, bias=False), norm_layer(out_channels), nn.ReLU(True) ) def forward(self, x): return self.block(x) class AsppPooling(nn.Module): def __init__(self, in_channels, out_channels, norm_layer): super(AsppPooling, self).__init__() self.gap = nn.Sequential( nn.AdaptiveAvgPool2d(1), nn.Conv2d(in_channels, out_channels, 1, bias=False), norm_layer(out_channels), nn.ReLU(True) ) def forward(self, x): size = x.size()[2:] pool = self.gap(x) out = F.interpolate(pool, size, mode='bilinear', align_corners=True) return out class ASPP(nn.Module): def __init__(self, in_channels, atrous_rates, norm_layer): super(ASPP, self).__init__() out_channels = 256 self.b0 = nn.Sequential( nn.Conv2d(in_channels, out_channels, 1, bias=False), norm_layer(out_channels), nn.ReLU(True) ) rate1, rate2, rate3 = tuple(atrous_rates) self.b1 = ASPPConv(in_channels, out_channels, rate1, norm_layer) self.b2 = ASPPConv(in_channels, out_channels, rate2, norm_layer) self.b3 = ASPPConv(in_channels, out_channels, rate3, norm_layer) self.b4 = AsppPooling(in_channels, out_channels, norm_layer=norm_layer) self.project = nn.Sequential( nn.Conv2d(5 * out_channels, out_channels, 1, bias=False), norm_layer(out_channels), nn.ReLU(True), nn.Dropout(0.5) ) def forward(self, x): feat1 = self.b0(x) feat2 = self.b1(x) feat3 = self.b2(x) feat4 = self.b3(x) feat5 = self.b4(x) x = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1) x = self.project(x) #(1,256,15,15) return x class Transfusion(nn.Module): def __init__(self, height=480, width=480, num_classes=40, encoder_rgb='resnet34', encoder_depth='resnet34', encoder_block='BasicBlock', pretrained_on_imagenet=True, pretrained_dir='', activation='relu', ): super(Transfusion, self).__init__() in_channels = 64 # set activation function if activation.lower() == 'relu': self.activation = nn.ReLU(inplace=True) else: raise NotImplementedError( 'Only relu, swish and hswish as activation function are ' 'supported so far. Got {}'.format(activation)) if encoder_rgb == 'resnet50' or encoder_depth == 'resnet50': warnings.warn('Parameter encoder_block is ignored for ResNet50. ' 'ResNet50 always uses Bottleneck') # rgb encoder if encoder_rgb == 'resnet34': self.encoder_rgb = ResNet34( block=encoder_block, pretrained_on_imagenet=pretrained_on_imagenet, pretrained_dir=pretrained_dir, activation=self.activation) else: raise NotImplementedError( 'Only ResNets are supported for ' 'encoder_rgb. Got {}'.format(encoder_rgb)) # depth encoder if encoder_depth == 'resnet34': self.encoder_depth = ResNet34( block=encoder_block, pretrained_on_imagenet=pretrained_on_imagenet, pretrained_dir=pretrained_dir, activation=self.activation, input_channels=1) else: raise NotImplementedError( 'Only ResNets are supported for ' 'encoder_depth. Got {}'.format(encoder_rgb)) self.conv1_rgb = conv_bn_relu(4, 64, kernel=3, stride=2, padding=1,bn=True) self.rgbconv = conv_bn_relu(in_channels*8,in_channels*4,kernel=3,stride=1,padding=1,bn=True) self.depthconv = conv_bn_relu(in_channels*8,in_channels*4,kernel=3,stride=1,padding=1,bn=True) self.spge = Spge(in_channels) self.transfusion = Transformer_fusion(num_heads=8, qkv_bias = False, embed_dim =256, qk_scale = None, drop_ratio = 0.1, attn_drop_ratio =0., drop_path_ratio =0., norm_layer = nn.LayerNorm,) self.decoder = DeepLabV3Plus( in_channels=[64, 128, 256, 512], num_classes=40, norm_layer=nn.BatchNorm2d ) def forward(self, rgb, depth):#rgb, depth rgb_0 = torch.cat([rgb,depth],dim=1) #(1,4,480,480) rgb1 = self.conv1_rgb(rgb_0)#(1,64,240,240) depth1 = self.encoder_depth.forward_first_conv(depth) # (1,64,240,240) fuse1_1 = F.max_pool2d(rgb1, kernel_size=3, stride=2, padding=1)#(1,64,120,120) fuse2_2 = F.max_pool2d(depth1, kernel_size=3, stride=2, padding=1)#(1,64,120,120) # block 2 rgb2 = self.encoder_rgb.forward_layer1(fuse1_1) # (1,64,120,120) depth2 = self.encoder_depth.forward_layer1(fuse2_2) # (1,64,120,120) # block 2 rgb3 = self.encoder_rgb.forward_layer2(rgb2) # (1,128,60,60) depth3 = self.encoder_depth.forward_layer2(depth2) # (1,128,60,60) # block 3 rgb4 = self.encoder_rgb.forward_layer3(rgb3) # (1,256,30,30) depth4 = self.encoder_depth.forward_layer3(depth3) # (1,256,30,30) # block 4 rgb5 = self.encoder_rgb.forward_layer4(rgb4) # (1,512,15,15) depth5 = self.encoder_depth.forward_layer4(depth4) # (1,512,15,15) rgb6 = self.rgbconv(rgb5).flatten(2).permute(0,2,1) #(1,256,15,15)--->(1,225,256) depth6 = self.depthconv(depth5).flatten(2).permute(0,2,1)#(1,256,15,15)--->(1,225,256) # position encoding rgb_pe ,depth_pe = self.spge(rgb2,depth2) # transformer fusion out = self.transfusion(rgb6,depth6,rgb_pe , depth_pe)#(1,256,15,15) # decoder final_out = self.decoder(rgb2,out) #(1,40,480,480) return final_out def main(): height = 480, width = 480, # --------------------------------实例化ESAnet------------------------- model = ESANet() # (传入参数) model.eval() rgb_image = torch.randn(1, 3, 480, 480) depth_image = torch.randn(1, 1, 480, 480) summary(model, input_size=[(3, 480, 480), (1, 480, 480)], device='cpu') with torch.no_grad(): output = model(rgb_image, depth_image) print(output.shape) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585

-
相关阅读:
数据结构——时间复杂度和空间复杂度
spring @value 注入static 注入静态变量方法
java面向对象
Python Flask框架学习教程
实战 | 记一次曲折的钓鱼溯源反制
Nginx Proxy Manager 单机多Docker Compose 反向代理配置
工程建设智慧施工云平台源码 智慧工地平台源码
腾讯算法实习面试总结
数据卷(Data Volumes)&dockerfile
【开源三方库】Fuse.js:强大、轻巧、零依赖的模糊搜索库
- 原文地址:https://blog.csdn.net/qq_43733107/article/details/128018878
