-
【天池竞赛】心跳数据挖掘
天池学习赛 心跳数据挖掘 168分攻略

Chapter 1. 赛题解析
就如比赛界面所介绍的一般,这里再复述一遍
''' 本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事 —— 心跳信号分类预测。 赛题以心电图心跳信号数据为背景,要求选手根据心电图感应数据预测心跳信号所属类别,其中心跳信号对应正常病例以及受不同心律不齐和心肌梗塞影响的病例,这是一个多分类的问题。通过这道赛题来引导大家了解医疗大数据的应用,帮助竞赛新人进行自我练习、自我提高。 '''- 1
- 2
- 3
- 4
- 5
赛题以心电图心跳信号分类为任务,数据为一段心跳信号序列,其中每个样本的信号序列采样频次一致,长度相等。
训练集有十万条数据,每个测试集都有两万条数据。
数据的字段表如下:
Field Description id 为心跳信号分配的唯一标识 hearbeat_signals 心跳信号序列 label 心跳信号类别(0,1,2,3) 分类的测评分数计算公式为:
∑ ∣ y i − y ^ i ∣ \sum|y_i-\hat y_i| ∑∣yi−y^i∣
也就是L1Loss。
作为入门赛,本题的难度不算特别大,最开始的时候,每一频率采样的序号信息都是叠加放在
hearbeat_signals属性里的,拆分后的表现为一段时间序列。我们来看下数据,首先先导入需要的依赖库:
import pandas as pd import numpy as np import os- 1
- 2
- 3
创建一个工作环境:
env="TianChi_Data" if os.path.exists(env): pass else: os.mkdir(env)- 1
- 2
- 3
- 4
- 5
借助
Pandas模块,读取数据:train=pd.read_csv(r".\train.csv") # 训练数据 test=pd.read_csv(r".\testA.csv") # 测试数据- 1
- 2
之前我们说信号数据是被叠加在字段下的,所以现在要做的就是将信号从字段中分开。下面是一个标准的处理代码:
# 将数据简单处理:数据切割以及打标签 train_list = [] for items in train.values: train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]]) # 转化到DataFrame方便处理 train = pd.DataFrame(np.array(train_list)) train.columns = ['id'] + [str(i) for i in range(len(train_list[0]) - 2)] + ['label'] test_list = [] for items in test.values: test_list.append([items[0]] + [float(i) for i in items[1].split(',')]) test = pd.DataFrame(np.array(test_list)) test.columns = ['id'] + [str(i) for i in range(len(test_list[0]) - 1)] # 模型数据集准备 x_train = train.drop(['id', 'label'], axis=1) y_train = train['label'] x_test = test.drop(['id'], axis=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
好了,我们已经处理完了数据,那么接下来按理来说,要进行过的就是EDA数据探索性分析。
首先来看看数据的分布,我们通过柱状图进行展示:
bars=[y_train[y_train==i].count() for i in y_train.unique()] plt.bar([i for i in y_train.unique()],bars,width=0.2) plt.show()- 1
- 2
- 3

柱状图能够快速的让我们了解数据的分布和数量关系,比如这里,我们发现,
1类数据是最多的,推测这应该是正常心跳。关于心电图序列的具体意义,还是需要看几篇论文去了解,这里我们就简单的当做信号序列吧。此时心跳序列共有
205个频率,每个频率都对应着一个[0,1]之间的浮点值,推测其已经完成了标准化,因此我们在后面的数据预处理过程中可以不需要再进行标准化了。数据在每一个频次上的统计量为:

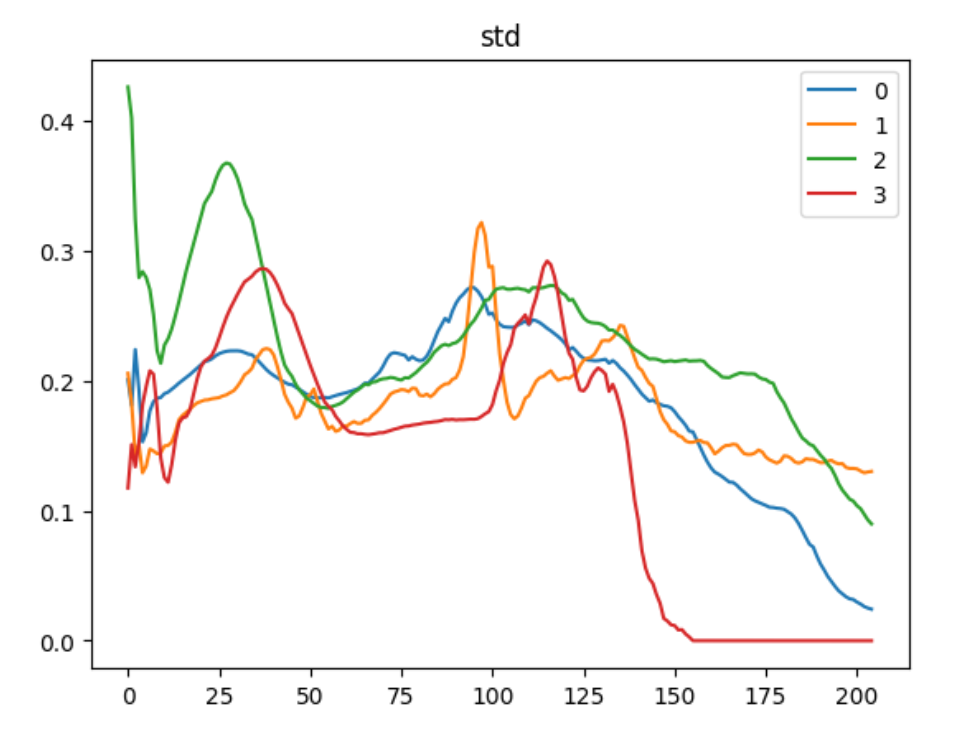

emmm可以发现,三类数据在
0-130左右表现出很强的脉动,之后又断崖式下降,可能是突然的心悸,或者是类似室上性心动过速这种心脏病。零类数据我们一开始推测其为正常数据,在标准差上,波动性较小,相对稳定。一类数据变化最频繁,心跳比较不规律,但二类和零类差别不大,应该是一个区分难点。好了,针对上面的分析,我们可以简单得到一些结论:
- 这是一个一维时间序列数据
- 数据的区间范围在
[0,1] - 数据存在大量拖尾0,可能是由于离开机器导致的
- 数据样本分布不均匀
- 数据样本量较大
针对存在的问题,我们可以进行:
- 上采样、加入噪声的方式对样本不均衡问题进行处理
- 对于大量拖尾零,可以考虑一个截断区间,但区间如何选取是个十分麻烦的事情
- 不需要进行标准化
Chapter 2. Baseline
Baseline可以分为数据预处理、模型准备、训练、测试、预测五个部分。
2.1 数据预处理
这部分我们其实已经提到过了,这里直接给一段完整的:
import pandas as pd import numpy as np import torch.nn as nn import matplotlib.pyplot as plt from imblearn.over_sampling import SMOTE import torch import time from sklearn.model_selection import train_test_split from tqdm import tqdm #----------------------------数据预处理---------------------------------# train=pd.read_csv(r"train.csv") test=pd.read_csv(r"testA.csv") # 将数据简单处理:数据切割以及打标签 train_list = [] for items in train.values: train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]]) train = pd.DataFrame(np.array(train_list)) train.columns = ['id'] + [str(i) for i in range(len(train_list[0]) - 2)] + ['label'] test_list = [] for items in test.values: test_list.append([items[0]] + [float(i) for i in items[1].split(',')]) test = pd.DataFrame(np.array(test_list)) test.columns = ['id'] + [str(i) for i in range(len(test_list[0]) - 1)] # 模型数据集准备 x_train = train.drop(['id', 'label'], axis=1) y_train = train['label'] x_test = test.drop(['id'], axis=1) # 使用 SMOTE 对数据进行上采样以解决类别不平衡问题 smote = SMOTE(random_state=1024, n_jobs=-1) k_x_train, k_y_train = smote.fit_resample(x_train, y_train) # 将训练集转换为适应 CNN 输入的 shape k_x_train = np.array(k_x_train).reshape(k_x_train.shape[0], k_x_train.shape[1], 1) # 分割训练集和测试集 X_train,X_test,Y_train,Y_test=train_test_split(k_x_train,k_y_train,test_size=0.25,random_state=1) # 转换成 tensor train_norm = torch.FloatTensor(X_train) label_train=torch.LongTensor(Y_train).reshape(-1,1) label_train = torch.zeros(label_train.shape[0], 4).scatter_(1, label_train, 1) # 生成one-hot test_norm=torch.FloatTensor(X_test) label_test=torch.LongTensor(Y_test).reshape(-1,1) label_test = torch.zeros(label_test.shape[0], 4).scatter_(1, label_test, 1) # 生成one-hot- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
2.2 模型准备阶段
这个阶段我们需要一个数据集和加载器,用来迭代我们的数据。
class TDataset(Data.Dataset): def __init__(self,x,y): self.x=x self.y=y def __getitem__(self,idx): data=self.x[idx] label=self.y[idx] return data,label def __len__(self): return len(self.x) dataset=TDataset(train_norm,label_train) train_data=torch.utils.data.DataLoader(dataset,batch_size=32,shuffle=True) dataset=TDataset(test_norm,label_test) test_data=torch.utils.data.DataLoader(dataset,batch_size=32,shuffle=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
然后,我们需要一个精度评估,这里我们采用了Label Smooth方法,用来减少分类数据非黑即白可能导致的过拟合问题,提升泛化能力。
class AbsLoss(nn.Module): def __init__(self,ls=0.1,cn=4): self.ls=ls self.cn=cn super(AbsLoss, self).__init__() def forward(self,x,y): y=torch.clamp(y.float(),min=self.ls/(self.cn-1),max=1.0-self.ls) return torch.sum(torch.sum(torch.abs(x-y)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3 模型训练与测试阶段
这个阶段就是单纯的定义优化器、定义损失函数、进行训练。
def Train(model,seed=1,epochs=200): device="cuda" if torch.cuda.is_available() else "cpu" model=model.to(device) Mloss=None path="./TianChi/best_model%d.pth"%seed # 设置损失函数,这里使用的是均方误差损失 criterion=AbsLoss() # 设置优化函数和学习率lr optimizer = torch.optim.Adam(model.parameters(),lr=0.00001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0) criterion=criterion.to(device) model.train() start_time = time.time() total_loss=0 for epoch in range(epochs): for seq, y_train in tqdm(train_data): seq,y_train=seq.to(device),y_train.to(device) optimizer.zero_grad() y_pred = model(seq) y_train=y_train.to(torch.int64) loss = criterion(y_pred, y_train) loss.backward() optimizer.step() total_loss+=loss if Mloss==None: Mloss=total_loss.tolist() else: if total_loss.tolist()<Mloss: Mloss=total_loss.tolist() torch.save(model.state_dict(),path) print("Saving") print(f'Epoch: {epoch+1:2} Loss: {total_loss}') total_loss=0 print(f'\nDuration: {time.time() - start_time:.0f} seconds') return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
生成一个模型然后进行训练:
m=Net1() Train(m,1)- 1
- 2
加载最优的参数
m.load_state_dict(torch.load("./TianChi/best_model1.pth"))- 1
训练则大同小异,在
with torch.no_grad()和model.eval()情况下计算test与label[test]的L1Loss即可
2.4 预测阶段
我们选择平权投票的方式进行。
Test_pre=torch.FloatTensor(x_test.values) Test_pre=Test_pre.reshape(x_test.shape[0],x_test.shape[1], 1)- 1
- 2
此时,这些模型是被训练好了的,这里不一一展示了。
models=[m1,m,m1_c,m4_c,m5,m6]- 1
进行平权投票
pre=None with torch.no_grad(): cnt=0 for i in models: i.to("cpu") i.eval() v=i(Test_pre) if pre==None: pre=v else: pre+=v pre/=6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
控制结果阈值输出:
# 设定初始后处理阈值 thr = [0.49, 0.49, 0.49, 0.49] # 输出结果阈值处理 def result_thr_process(result): temp = result.T.copy() for j in [1, 2, 3, 0]: #由于0类是大类,放在最后做阈值处理 for i in range(temp.shape[1]): if temp[j,i] > thr[j]: temp[:,i] = 0 temp[j,i] = 1 return temp r=result_thr_process(pre.data.numpy())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
将数据输出保存即可。
D=pd.DataFrame(r.T) D.to_excel(r"Pre1.xlsx")- 1
- 2
Chapter 3. 模型选用
3.1 概述
这类时间序列分类问题,
KNN并不是个很好的选择,因为我们注意到0类和2类样本之间是比较相似的,贝叶斯网络准确率应该不会很高,比较好的选择可以是梯度提升树、随机森林这类模型,比如lightgbm,优点是运算速度快,精度高,但需要足够好的特征,也就是非常考验特征工程。当然,我们这里不用机器学习的方法,为什么呢,因为
lgbm的得分大概在500-1000+,上榜的分数至少也要194,远达不到我们的要求。所以,我们考虑采用深度学习的方式进行模型训练。
首先考虑的就是一维卷积神经网络,
CNN能够挖掘出局部隐藏信息,提升训练精度。其次是LSTM,长短期记忆模型,这个模型常用于文本分析,它可以顾及上下文关系,也可以用于时间序列推测,但是本题并不是时间序列推测,而是分类问题,所以LSTM并不能作为最后的输出层。再有是对模型的一些改进结构,比如ResNet,一维RepVGG等结构,这些改进结构可能能取得不错的进展。在噪声增强方面,我们尝试用
GAN进行训练,预期是构造出一堆fake数据喂给模型,增强模型的泛化能力,但是效果并不理想,也可能是GAN模型选用和训练参数的问题。除却单模分析,我们可以借助机器学习中的集成学习方式,对这些模型进行集成分析,提高对噪声的鲁棒性和模型精度。我们考虑了两个方向,一个是多个模型投票,一个是
stacking方式,即将多个模型的输出作为新模型的输入。stacking在测试集上的表现优异,但是在最终测试集上的表现却不如人意,可能是出现了过拟合现象。我们最终选择多模融合+平权投票的方式进行训练,使用的网络类型和代码如下:
网络 架构 Net1 CNN Net2 CNN Net3 CNN Net4 CNN+LSTM Net5 CNN Net6 ResNet
3.2 模型选择
1️⃣ Net1
class Net1(nn.Module): def __init__(self): super(Net1, self).__init__() self.conv1=nn.Conv1d(in_channels = 1,out_channels = 64,kernel_size = 11,stride = 1,padding = 5) self.bn1=nn.BatchNorm1d(1) self.hidden=nn.Sequential( nn.LeakyReLU(), nn.Conv1d(64, 128,11,5), nn.BatchNorm1d(128), nn.LeakyReLU(), nn.Conv1d(128, 256,6,3), nn.BatchNorm1d(256), nn.LeakyReLU(), nn.Conv1d(256, 256,11,1,padding=5,dilation=2), nn.BatchNorm1d(256), nn.LeakyReLU(), nn.AdaptiveMaxPool1d(output_size=4), nn.Dropout(), nn.Flatten(), nn.Linear(256 * 4, 256), nn.LeakyReLU(), nn.Linear(256, 128), nn.LeakyReLU(), nn.Linear(128, 4), nn.Softmax(dim=1) ) def forward(self,x): x = x.view(x.size(0),1,x.size(1)) x=self.bn1(x) x=self.conv1(x) return self.hidden(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2️⃣Net2
class Net2(nn.Module): def __init__(self): super(Net2, self).__init__() self.conv1=nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 7,stride = 1,padding = 5) self.conv2=nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 11,stride = 1,padding = 7) self.conv3=nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 17,stride = 1,padding = 10) self.re=nn.LeakyReLU(0.2) self.bn1=nn.BatchNorm1d(32) self.Conv=nn.Sequential( nn.ReLU(), nn.Conv1d(32, 64,11,1), nn.BatchNorm1d(64), nn.ReLU(), nn.Conv1d(64, 128,3,1), nn.BatchNorm1d(128), nn.ReLU(), nn.AdaptiveMaxPool1d(output_size=4) ) self.fl=nn.Flatten() self.Linear=nn.Sequential( nn.LeakyReLU(), nn.Dropout(0.1), nn.Linear(128*4, 256), nn.LeakyReLU(), nn.Linear(256, 1024), nn.LeakyReLU(), nn.Linear(1024, 4), nn.Softmax(dim=1) ) def forward(self,x): x = x.view(x.size(0),1,x.size(1)) x1=self.conv1(x) x3=self.conv3(x) x2=self.conv2(x) x=self.re(self.bn1(x1+x2+x3)) x=self.Conv(x) x=self.fl(x) return self.Linear(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3️⃣ Net3
class Net3(nn.Module): def __init__(self): super(Net3,self).__init__() self.conv1 = nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 11,stride = 1,padding = 5) self.conv2 = nn.Conv1d(32,64,11,1,5) self.conv3 = nn.Conv1d(64,128,3,1,1) self.conv4 = nn.Conv1d(128,256,3,1,1) self.bn1 = nn.BatchNorm1d(1) self.bn2 = nn.BatchNorm1d(32) self.bn3 = nn.BatchNorm1d(64) self.bn4 = nn.BatchNorm1d(128) self.maxpool = nn.MaxPool1d(4) self.re = nn.LeakyReLU() self.dp = nn.Dropout(0.1) self.linear = nn.Sequential( nn.Linear(256*4*3,1024), nn.LeakyReLU(), nn.Linear(1024,128), nn.LeakyReLU(), nn.Linear(128,4), nn.Softmax(dim=1) ) def forward(self,x): x = x.view(x.size(0),1,x.size(1)) x = self.bn1(x) x = self.bn2(self.re(self.conv1(x))) x = self.re(self.conv2(x)) x = self.maxpool(x) x = self.bn3(x) x = self.bn4(self.relu(self.conv3(x))) x = self.re(self.conv4(x)) x = self.maxpool(x) x = self.dp(x) x = x.view(x.size(0),-1) x = self.linear(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4️⃣ Net4
class Net4(nn.Module): def __init__(self): super(Net4,self).__init__() self.conv1 = nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 11,stride = 1,padding = 5) self.conv2 = nn.Conv1d(32,64,11,1,5,dilation=2) self.conv3 = nn.Conv1d(64,128,9,1,5) self.conv4 = nn.Conv1d(128,256,3,1,1) self.bn1 = nn.BatchNorm1d(1) self.bn2 = nn.BatchNorm1d(32) self.bn3 = nn.BatchNorm1d(64) self.bn4 = nn.BatchNorm1d(128) self.fl=nn.Flatten() self.maxpool = nn.AdaptiveMaxPool1d(output_size=4) self.re = nn.LeakyReLU() self.dp = nn.Dropout(0.1) self.linear = nn.Sequential( nn.Linear(256*4*3,1024), nn.LeakyReLU(), nn.Linear(1024,128), nn.LeakyReLU(), nn.Linear(128,4), nn.Softmax(dim=1) ) self.ls=nn.LSTM(256*4,1024) def forward(self,x): x = x.view(x.size(0),1,x.size(1)) x = self.bn1(x) x = self.bn2(self.re(self.conv1(x))) x = self.re(self.conv2(x)) x = self.maxpool(x) x = self.bn3(x) x = self.bn4(self.relu(self.conv3(x))) x = self.re(self.conv4(x)) x = self.maxpool(x) x = self.dp(x) x,h=self.ls(self.fl(x)) x = self.dp(x) x = x.view(x.size(0),-1) x = self.linear(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
5️⃣ CNN5
class Net5(nn.Module): def __init__(self): super(Net5, self).__init__() self.conv_layer1 = nn.Sequential( nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3, padding=1), nn.BatchNorm1d(16), nn.ReLU() ) # 下采样down-sampling self.sampling_layer1 = nn.Sequential( nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3, padding=1), nn.BatchNorm1d(32), nn.ReLU(), nn.MaxPool1d(kernel_size=2, stride=2), ) self.conv_layer2 = nn.Sequential( nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3, padding=1), nn.BatchNorm1d(64), nn.ReLU() ) self.sampling_layer2 = nn.Sequential( nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1), nn.BatchNorm1d(128), nn.ReLU(), nn.MaxPool1d(kernel_size=2, stride=2), ) self.conv_layer3 = nn.Sequential( nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3, padding=1), nn.BatchNorm1d(256), nn.ReLU() ) self.sampling_layer3 = nn.Sequential( nn.Conv1d(in_channels=256, out_channels=512, kernel_size=3, padding=1), nn.BatchNorm1d(512), nn.ReLU(), nn.MaxPool1d(kernel_size=2, stride=2), ) self.lr = nn.Sequential( nn.Linear(in_features=512*25, out_features=256*25), nn.ReLU(), nn.Linear(in_features=256*25, out_features=128*25), nn.ReLU(), nn.Linear(in_features=128*25, out_features=64*25), nn.ReLU(), nn.Linear(in_features=64*25, out_features=4) ) self.sf = nn.Softmax(dim=1) def forward(self, x): x=x.view(x.shape[0],x.shape[-1],x.shape[-2]) x = self.conv_layer1(x) x = self.sampling_layer1(x) x = self.conv_layer2(x) x = self.sampling_layer2(x) x = self.conv_layer3(x) x = self.sampling_layer3(x) x = x.view(x.size(0), -1) x = self.lr(x) return self.sf(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
6️⃣ Net6
class Bottlrneck(torch.nn.Module): def __init__(self,In_channel,Med_channel,Out_channel,downsample=False): super(Bottlrneck, self).__init__() self.stride = 1 if downsample == True: self.stride = 2 self.layer = torch.nn.Sequential( torch.nn.Conv1d(In_channel, Med_channel, 1, self.stride), torch.nn.BatchNorm1d(Med_channel), torch.nn.LeakyReLU(), torch.nn.Conv1d(Med_channel, Med_channel, 3, padding=1), torch.nn.BatchNorm1d(Med_channel), torch.nn.LeakyReLU(), torch.nn.Conv1d(Med_channel, Out_channel, 1), torch.nn.BatchNorm1d(Out_channel), torch.nn.LeakyReLU(), ) if In_channel != Out_channel: self.res_layer = torch.nn.Conv1d(In_channel, Out_channel,1,self.stride) else: self.res_layer = None def forward(self,x): if self.res_layer is not None: residual = self.res_layer(x) else: residual = x return self.layer(x)+residual class ResNet(torch.nn.Module): def __init__(self,in_channels=1,classes=4): super(ResNet, self).__init__() self.features = torch.nn.Sequential( torch.nn.Conv1d(in_channels,64,kernel_size=11,stride=1,padding=5), torch.nn.MaxPool1d(3,2,1), Bottlrneck(64,64,256,False), Bottlrneck(256,64,256,False), Bottlrneck(256,64,256,False), torch.nn.AdaptiveAvgPool1d(output_size=4), torch.nn.Dropout(0.1) ) self.classifer = torch.nn.Sequential( torch.nn.Linear(256*4,1024), nn.BatchNorm1d(1024), nn.LeakyReLU(), torch.nn.Linear(1024,256), nn.BatchNorm1d(256), nn.LeakyReLU(), torch.nn.Linear(256,4), torch.nn.Softmax(dim=-1) ) def forward(self,x): x=x.view(x.shape[0],1,-1) x = self.features(x) x = x.view(x.shape[0],-1) x = self.classifer(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
3.3 模型叠加
另外提一下,如何进行
stacking,首先要有一个新模型,这个模型一般不会太复杂class Linear1(nn.Module): def __init__(self,inChannel): super(Linear1,self).__init__() self.Linear=nn.Sequential( nn.Linear(inChannel,64), nn.BatchNorm1d(64), nn.LeakyReLU(), nn.Linear(64,128), nn.BatchNorm1d(128), nn.LeakyReLU(), nn.Linear(128,4), nn.Softmax(dim=1) ) def forward(self,x): return self.Linear(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们对多个模型的容器
models里面的每个模型都进行训练,并将输出数据叠加:star=[i*50000 for i in range(6)] # 因为数据量太多了我内存不够,所以拆开来 with torch.no_grad(): TD=None for i in range(len(star)-1): Train_val=test_norm[star[i]:star[i+1]] T=models[0](Train_val) for i in models[1:]: T=torch.cat([T,i(Train_val)],dim=1) # 这是贴到一起的方法 if TD==None: TD=T else: TD=torch.cat([TD,T])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这种叠加是在列上叠加,也就是每个模型都能叠出来
4个特征,例如我们有10个模型,那么输出大小为:
[ n u m , 4 ∗ 10 ] [num,4*10] [num,4∗10]
还有种是直接加上去的,这里没有进行尝试,可以试一下。然后利用这个数据,对我们最后一个模型进行训练即可。注意这里的
test_norm是处理好了的测试集。
3.4 GAN生成假数据
首先我们要有一个生成器,和一个判别器,这两个模型性能要差不多,最后可以达到纳什均衡。
from torch.autograd import Variable class Generator(nn.Module): def __init__(self,inC): # 生成器要做的就是把随机噪声转化为图像像素 super(Generator, self).__init__() def block(in_feat,out_feat,normalize=True): # in: 初始化随机噪声 # out: 指定神经元输出 # 做个最简单的全连接 layers=[nn.Linear(in_feat,out_feat)] if normalize: # batch初始化 layers.append(nn.BatchNorm1d(out_feat,0.8)) # leakrelu激活函数 layers.append(nn.LeakyReLU(0.2,inplace=True)) return layers self.model=nn.Sequential( *block(inC,128,normalize=False), *block(128, 256), *block(256, 512), *block(512, 1024), nn.Linear(1024, 205), nn.Tanh() ) def forward(self,z): x=self.model(z) return x # 判别器 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.model=nn.Sequential( # 判别器要做的就是识别图像状态 nn.Linear(205,512), nn.LeakyReLU(0.2,inplace=True), nn.Linear(512,256), nn.LeakyReLU(0.2,inplace=True), nn.Linear(256,1), # 需要映射到01 nn.Sigmoid() ) def forward(self,img): validity=self.model(img) return validity # 损失函数 # 用的是BCEloss # 即计算样本正确识别信息熵 loss=torch.nn.BCELoss() device="cuda" if torch.cuda.is_available() else "cpu" # 创建生成器 gen=Generator(64) dis=Discriminator() # 是否调用GPU cuda=True if torch.cuda.is_available() else False Tensor=torch.cuda.FloatTensor if cuda else torch.FloatTensor if cuda: gen.cuda() dis.cuda() loss.cuda() # 定义优化器 opt_G=torch.optim.Adam(gen.parameters(),lr=0.0005,betas=(0.9, 0.99)) opt_D=torch.optim.Adam(dis.parameters(),lr=0.0005,betas=(0.9, 0.99))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
重点是训练过程,如何获得某一类标签的
fake数据呢?首先我们要获得该类的真实数据。举个栗子:
label=torch.LongTensor(Y_train).reshape(-1,1) cls=0 idx=(label==cls).reshape(-1) d=train_norm[idx] lab_idx=label[idx] label_c = torch.zeros(lab_idx.shape[0], 4).scatter_(1, lab_idx, 1) dataset=TDataset(d,label_c) train_data_c=torch.utils.data.DataLoader(dataset,batch_size=32,shuffle=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后就是我们的博弈过程啦:
for epoch in range(200): g_loss_train=0 d_loss_train=0 for i,(input,target) in tqdm(enumerate(train_data_c)): input=input.to(device) input=input.squeeze() num_img=input.size(0) real_label = torch.ones(num_img) fake_label = torch.zeros(num_img) real_label = real_label.reshape(real_label.size(0), -1).to(device) fake_label = fake_label.reshape(fake_label.size(0), -1).to(device) # 训练判别器 real_out=dis(input) try: d_loss_real=loss(real_out,real_label) except: continue real_score=real_out z=torch.randn((num_img,64)).to(device) fake_img=gen(z) fake_out=dis(fake_img) try: d_loss_fake=loss(fake_out,fake_label) except: continue d_loss=d_loss_fake+d_loss_real opt_D.zero_grad() d_loss.backward() opt_D.step() # 训练生成器 z=torch.randn((num_img,64)).to(device) fake_img=gen(z) output=dis(fake_img) try: g_loss=loss(output,real_label) except: continue opt_G.zero_grad() g_loss.backward() opt_G.step() g_loss_train+=g_loss.item() d_loss_train+=d_loss.item() print("[G_loss: %d] [D_loss: %d]"%(g_loss_train,d_loss_train))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
训练好的生成器就能生成对应类别的数据了,将其设为真实数据混入原始数据,提高模型的鲁棒性和泛化能力。
noise=Variable(Tensor(np.random.normal(0,1,(10000,64)))) x=gen(noise)- 1
- 2
Chapter 4. 总结
-
Dropout需要放在线性层之前
-
要先做激活层,再做BN
-
划分数据集可能会导致序号打乱,此时不能直接转成Tensor,可以采用
A.to_numpy()重新获取序号 -
转成one-hot编码有很多方式,其中一种可以是:
label_train = torch.zeros(label_train.shape[0], 4).scatter_(1, label_train, 1)- 1
- 2
-
相关阅读:
detect_topic
区,段,碎片区与表空间结构
工业设计:产品配色与产品形态的关系
docker部署前端项目(二)遇到的问题
JDK1.8 JVM内存模型
大数据运维工程师面试
JS中数据类型
算法9-动态规划
m基于OFDM数字电视地面广播系统中频域同步技术研究
Elasticsearch之mapping
- 原文地址:https://blog.csdn.net/qq_45957458/article/details/128029815