-
Transformer Fusion for Indoor RGB-D Semantic Segmentation
如何聚合多尺度特征这是一个问题,现有的方法大多通过卷积来实现,而很少在特征融合的地方使用长距离依赖,因此对于大物体的分割就会有挑战。本文提出基于transformer的融合策略,来更好的建模上下文。
TransD-Fusion包含①:一个自完善,②:交叉矫正和③:深度引导融合,还有一个④语义位置编码来将注意力限制到相邻的像素。
当前模型融合有三个挑战,分别为多模态融合,每个模态含噪声,特征对齐。
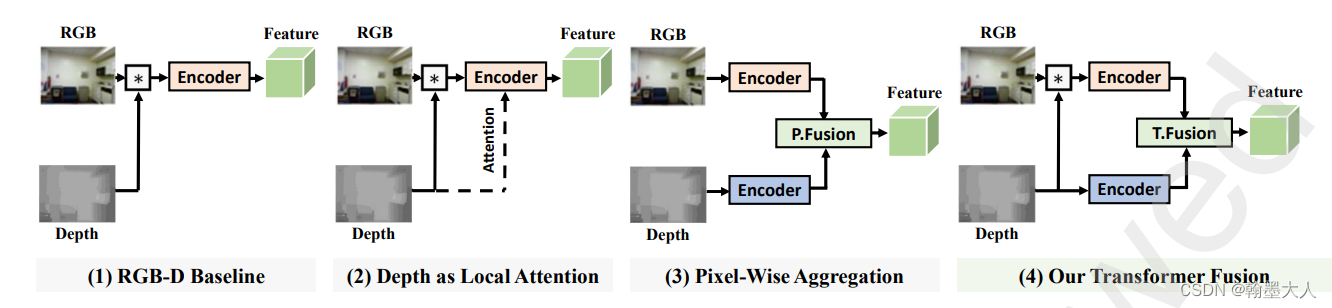
现在大多的融合方法还是逐像素融合,限制了情景化的线索(上下文信息),导致结果遇到了瓶颈。
transformer通过Q和K之间的关系建模全局的注意力,我们可以将内在的q和k之间的关系,延伸到跨模态的关系。(说明:平时的transformer通过对patch embedding进行三个线性投射形成的,操作的对象是token,即一个token序列形成了三个qkv,而跨模态的qkv则是qk或者v其中一个来自于其他的模态进行注意力计算)。因此这是一个很自然的方法去聚合RGB-D特征。通过利用上下文信息(transformer获得的),我们就可以处理表面比较形似的物体而深度值是不同的。
①通过transformer注意力实现的,②为了通过互补信息来完善每个模态。③为了有效的分割物体。④产生category-aware的位置编码。
模型框架:
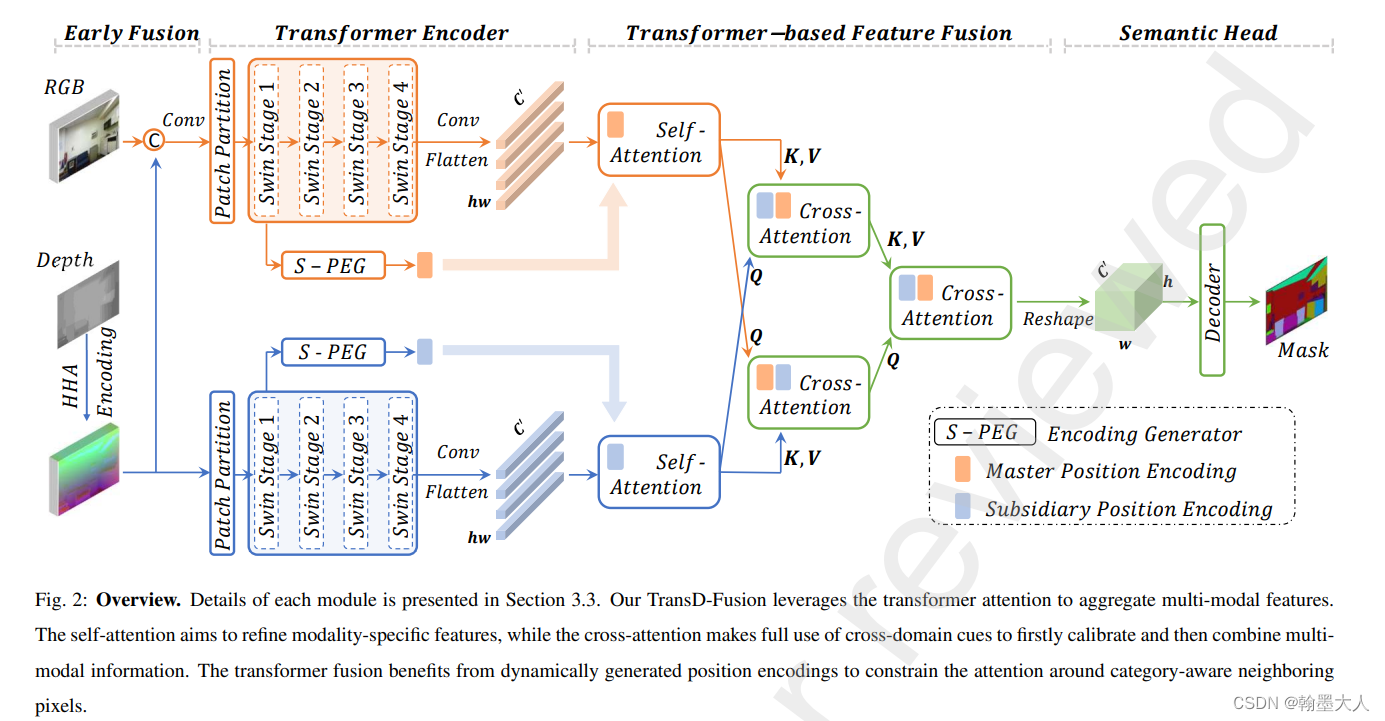
包含主分支和附属分支这种双流encoder,首先Depth转换为HHA,然后和RGB进行concat,接着分别送入swin transformer中。

将产生的结果图经过卷积来减少维度,然后新的特征图进一步进行展平。输入到transformer fusion中。
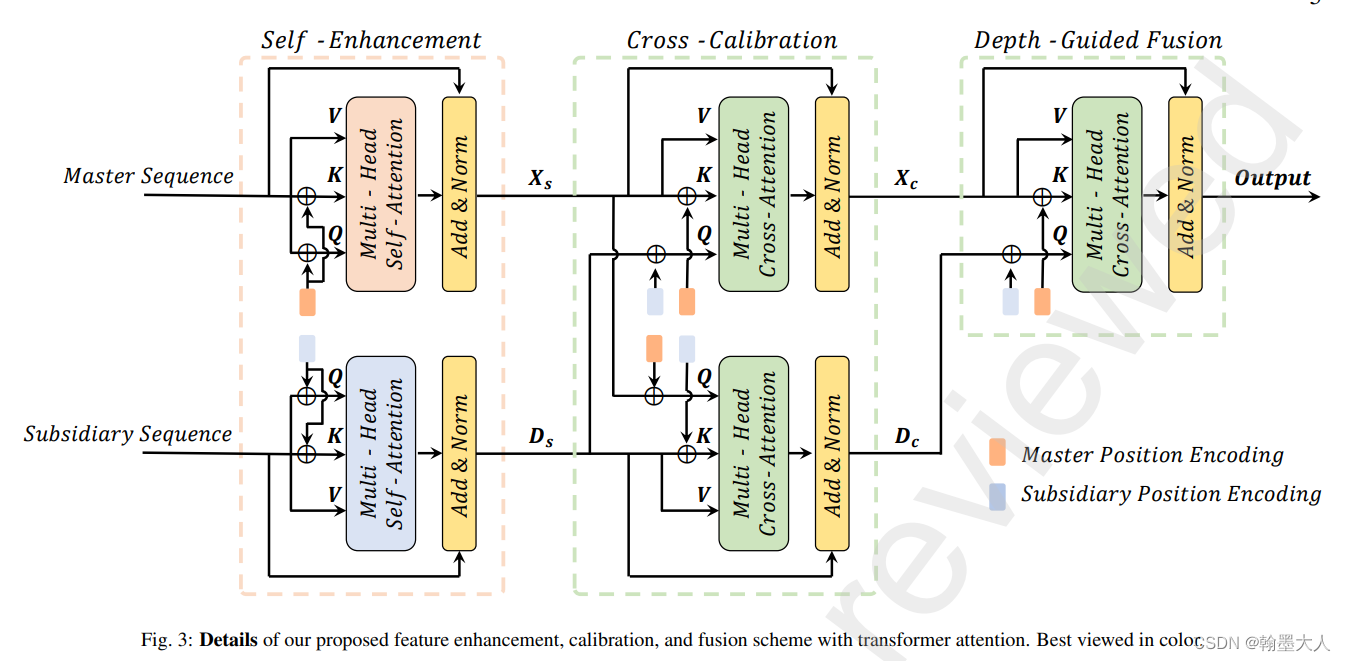
三步:自注意力,通过交叉注意力进行双向矫正,深度引导的query进行分割。
首先看第一步:
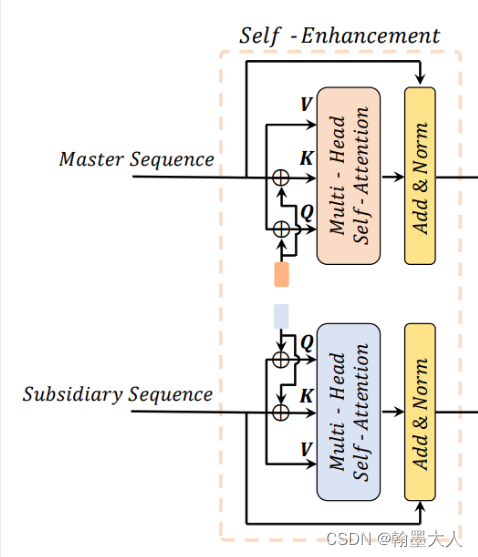
多头自注意力,和普通的transfor一样的。

各个分支进行多头自注意力,然后与本身相加。Px是位置编码。
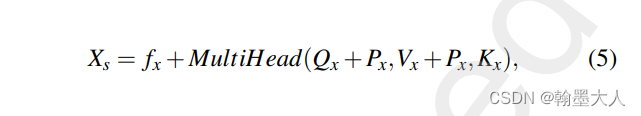
第二步:交叉完善
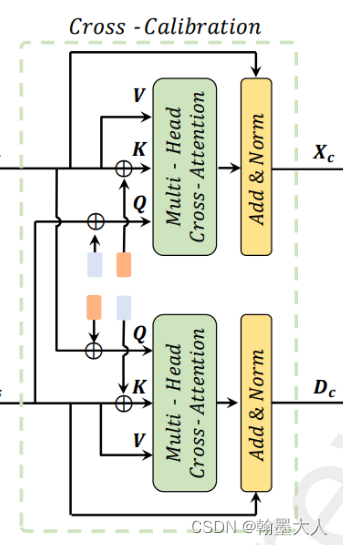
为了消除单模态的模糊,区别于之间的双注意力,作者提出的基于transformer的交叉完善。
RGB分支的Q来自深度分支,因此他自带深度的位置编码,k和v来自自身,带RGB的位置编码。

第三步:深度引导的融合
深度产生的结果作为query来进行跨模态的注意力。
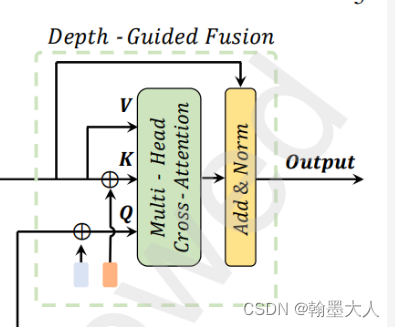
用公式表示为:

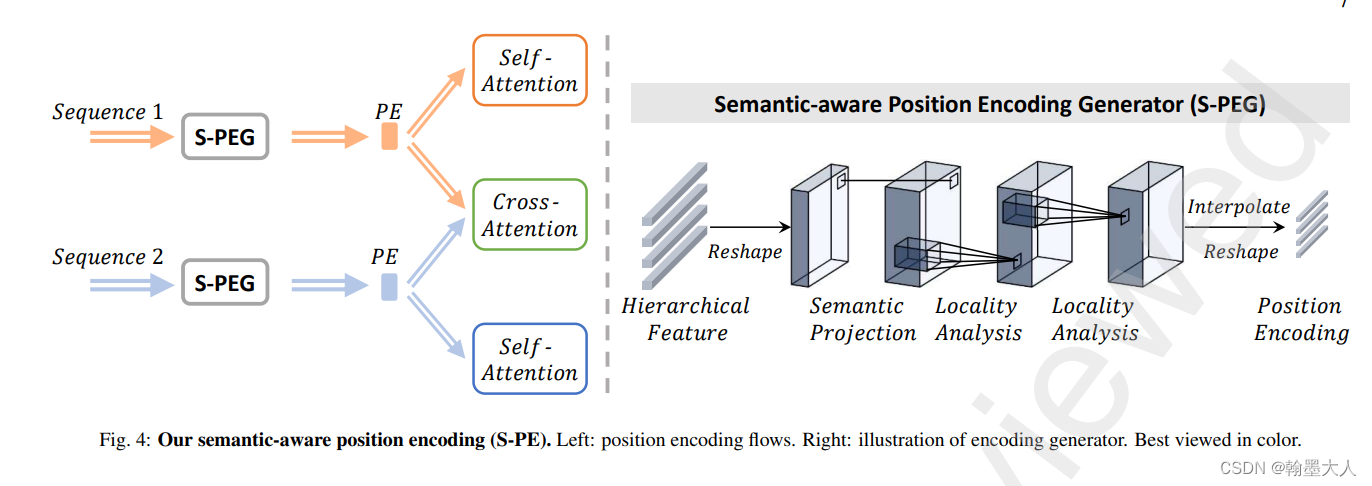
语义位置编码:
从低层次即分辨率的特征图来充分应用空间分辨率。
具体操作:将两个序列reshpe为图片,然后通过卷积投射到高维,然后再通过两个3x3卷积增加序列的局部信息。和CPVT有些类似和CVT也有些类似,即将卷积引入到位置编码中。
实验:SOTA
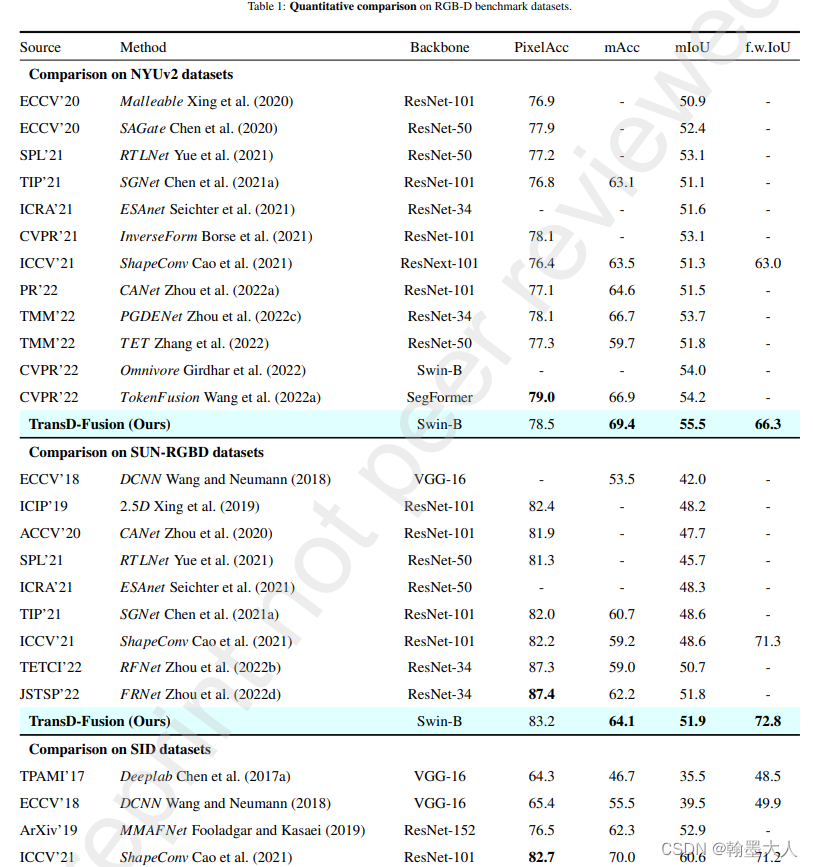
可视化:

消融实验:自行分析 -
相关阅读:
【ppt技巧】批量修改ppt中的字体
贵金属金银铂铑钯回收-HP4080
【区分vue2和vue3下的element UI Card 卡片组件,分别详细介绍属性,事件,方法如何使用,并举例】
量化交易是不是用机器预测股票涨跌?这靠谱吗?
Centos中清除因程序异常终止,导致的残留的Cache/buff_drop_caches命令---linux工作笔记063
互调的影响
爬虫常用笔记总结
【时序数据库InfluxDB】Windows环境下配置InfluxDB+数据可视化,以及使用 C#进行简单操作的代码实例
【从零到一】电子元器件网站建设/开发方案、流程及搭建要点全解
Python多线程教程
- 原文地址:https://blog.csdn.net/qq_43733107/article/details/128008818