-
【STL】string 类
目录
👉为什么要学习 string 类👈
在 C 语言中,字符串是以
'\0'结尾的一些字符的集合,为了操作方便,C 标准库中提供了一些 str 系列的库函数,但是这些库函数与字符串是分离开的,不太符合面向对象的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。在 OJ 中,有关字符串的题目基本以 string 类的形式出现。如果还用 C 语言先将轮子造出来,再去解题的话,代码量就会显得相当多,而且 string 类使用起来是相当的方便。
👉标准库中的 string 类👈
string 类有相当多的函数接口,我们无法将每个函数接口的功能都能记得清清楚楚。但对于一些非常常用的函数接口,我们要记住它们的函数原型、功能以及如何实现。
在学习的过程中,我们难免会记不清楚函数接口的原型、功能啊。这时候,我们就要学会查文档了。那么,我给大家推荐一个网站(https://legacy.cplusplus.com/) ,里面可以查到函数接口的相关信息。

什么是 string 类
- string 类是表示字符串的类。
- string 类是 basic_string 模板类的一个实例,它使用 char 来实例化 basic_string 模板类,并用 char_traits 和 allocator 作为 basic_string 的默认参数。


为什么会将 string 设置成模板呢?因为这里涉及了编码问题。那什么是编码呢?编码是信息从一种形式或格式转换为另一种形式的过程(映射关系),也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。而大家第一次接触的编码可能就是 ASCII 码(美国信息交换标准代码)。

除了 ASCII 码,还有统一码,也称为万国码。

统一码中用的比较多的就是 UTF-8,因为 UTF-8 是兼容 ASCII 码的。关于统一码的编码规则和相关编码的优缺点,大家可以百度查询,我就不赘述了。除了统一码外,还有 GBK 编码,这是中国国标的编码,其采用的是双字节编码方案。

那现在我给大家看一看 GBK 编码的演示。

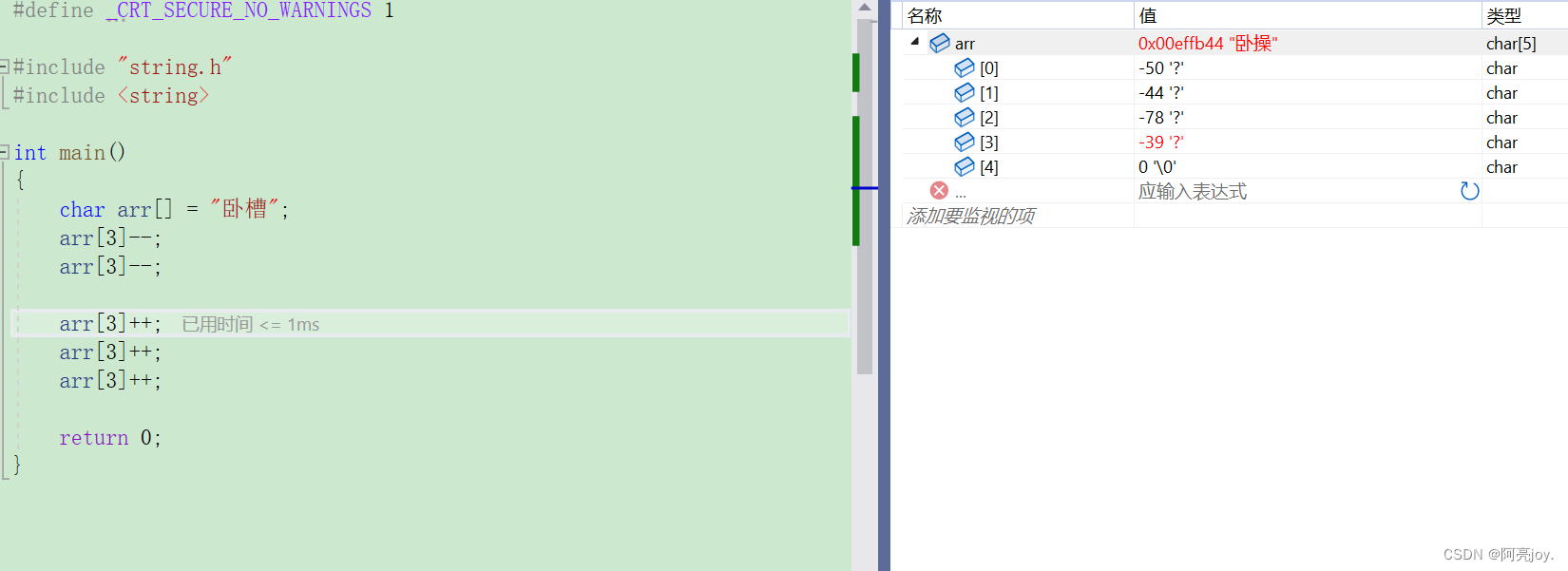
因为汉字博大精深,所以 GBK 编码就将同音字或音相近的字编在一起。注:一个汉字是占两个字的。因为有了 UTF-8、UTF-16、UTF-32 和 GBK 的不同编码形式,那么就有了 basic_string 模板类。大家可以根据自己的需求采用不同的类。而我们今天所学的 string 类是存储的是 char。
// 动态增长的字符数组 template<class T> class basic_string { private: T* _str; size_t _size; size_t _capacity; }; typedef basic_string<char> string;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

总结
- string 是表示字符串的类。
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作 string 的常规操作。
- string 在底层实际是 basic_string 模板类的别名,typedef basic_string
- 不能操作多字节或者变长字符的序列
- 在使用 string 类时,必须包含 #include 头文件以及 using namespace std。
👉string 类的构造函数👈
string 类对象的常见构造

(constructor)函数名称 功能说明 string() (重点) 构造空的 string 类对象,即空字符串 string(const char* s)(重点) 用字符串来构造 string 类对象 string(size_t n, char c) string 类对象中包含 n 个字符 c string(const string&s) (重点) 拷贝构造函数 string()
该构造函数是无参的构造函数,其构造出来的对象的
size为 0,capacity的大小取决于编译器是如何实现 string 类的。
string(const char*)
该构造函数是用常量字符串去构造一个对象出来,也是很常用的一个构造函数。

注:+= 是 string 类的运算符重载,可以在 string 类对象的末尾默认插入字符或者字符串,后面的内容会讲解其模拟实现。<< 也是 string 类的运算符重载。
除了上面的string s2("广东省深圳市")这样的写法,还可以想string s3 = "hello world"这样写。因为string(const char*)的函数原码没有用explicit修饰,可以支持隐式类型转换。先生成一个临时对象,再用临时对象去拷贝构造我们想要的对象s3,但是这个过程会被编译器优化成string s3("hello world")。string(size_t n, char c)
这个构造函数是用 n 个 字符来创建一个对象。

string(const string&s)
这个是 string 类的拷贝构造函数,也是相当的重要,一定要掌握。

注:因为 s6 之前是没有创建的,所以string s6 = s2调用的是拷贝构造函数。如果 s6 之前已经创建好了,那么s6 = s2调用的就是赋值运算符重载。string (const char* s, size_t n)
这个构造函数是用字符串 s 的前 n 个字符来创建一个 string 类对象。注:n 最好不要超过字符串 s 的长度,否则创建出来的对象将未知。不过这个函数也不经常使用,要使用的话,就可以查一下文档。

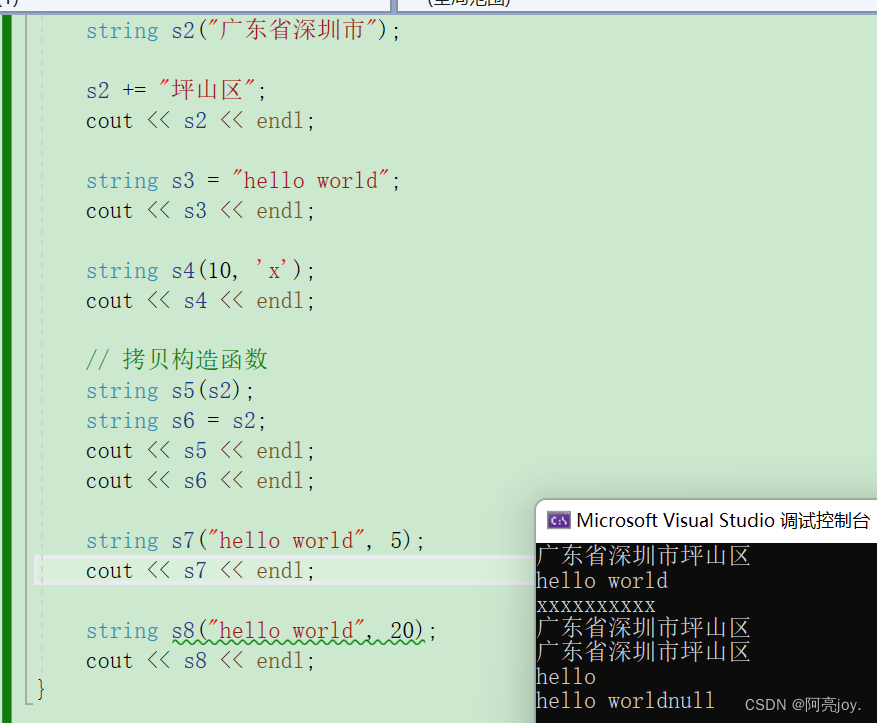
注:string 类的 << 运算符重载并不是以'\0'作为打印的结束标志,而是打印到 string 类对象最后的一个字符。只是'\0'在 VS2022 无法显示出来。所以,就出现了以上的打印结果。string (const string& str, size_t pos, size_t len = npos)
该函数是用对象 str 从 pos 位置起的的 len 个字符来创建对象。注:npos 是 string 的静态const size_t成员变量,其值为 -1,是非常大的一个正数。如果 len 很大,就会用 pos 位置到末尾位置之间的字符来创建对象。


👉string 类的访问和遍历方式👈
下标访问

注:size 是 string类的成员函数,size 是有效字符的个数,不包含'\0','\0'是标识字符。[ ] 是运算符重载。[ ] 运算符重载原型
char& operator[](size_t pos) { assert(pos < _size); return _str[i]; }- 1
- 2
- 3
- 4
- 5
因为有断言,所以如果越界访问的话就要报错,所以用 [ ] 运算符重载时一定不能越界访问,就是越界读也不行。

at

at 函数也可以访问 string 类对象的数据,其参数为 pos。at 函数也会进行越界检查,如果发生了越界,就会抛出异常。
front 和 back
front 和 back 这个函数接口,就是返回头部和尾部的字符。



需要注意的是:空的 string类对象不能调用这两个函数接口。范围 for

范围 for 的底层原理就是迭代器,那迭代器就是类似于指针的东西,也有可能不是指针。不过,迭代器用起来非常像指针。下标遍历和范围 for 遍历各有各的优势,自己可以针对不同的场景使用。

注:swap 是交换的模板函数,reverse 是逆置算法的函数接口,其两个参数为迭代器。

迭代器
迭代器
iterator的使用方式像指针,底层实现有可能是指针,也有可能不是指针。注:iterator是一种类型。


可以看到迭代器用起来就像是指针一样。注:s1.begin() 是返回 s1 第一个元素位置的迭代器,s1.end() 是返回最后一个元素的下一个位置的迭代器。
注:迭代器和范围 for 是各种容器通用的访问形式,而下标 [ ] 只适用于 string 和 vector。
比如:vector 的迭代器变量。
vector<int> v; vector<int>::iterator vit = v.begin(); while (vit != v.end()) { cout << *vit << ' '; vit++; } cout << endl;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这些迭代器使用起来都是非常像的,只是换了个容器而已。除了正向迭代器,还有反向迭代器
reverse_iterator。现在,我们也来学习一下。

rbegin 获取最后一个数据位置的 reverse_iterator,rend获取第一个数据前一个位置的 reverse_iterator。注:如果类型名过长的话,可以使用 auto 关键字自动推导类型。如果我们想要用迭代器来遍历用 const 关键字修饰的类对象,那么就要使用正向迭代器
const_iterator或者方向迭代器const_reverse_iterator。那么,我就给大家演示一下反向迭代器的使用。
注:权限只能缩小和平移,不能够放大,否则无法通过编译。如果在迭代器的最前面加上 const 关键字,那么迭代器就无妨自增或者自减。
四种迭代器总结

除了迭代器有 const 和非 const 的,[] 运算符重载也用 const 和非 const 的版本。这两个版本的函数形成函数重载。那什么样的函数什么时候要实现 const 版本的,什么时候要实现非 const 版本的。见下图:
👉string 类对象的容量操作👈
函数名称 功能说明 size(重点) 返回字符串有效字符长度 length 返回字符串有效字符长度 capacity 返回空间总大小 empty(重点) 检测字符串是否为空串,是返回 true,否则返回 false clear(重点) 清空有效字符 reserve(重点) 为字符串预留空间 resize(重点) 将有效字符的个数该成 n 个,多出的空间用字符 c 填充 size / length
size 和 length 都是返回字符串的有效字符长度,功能一样的。只有 string 类有 length 的函数,而其它容器只有 size 的函数接口。

capacity
capacity 是返回 string 类对象的容量大小的函数接口。

max_size
max_size 函数接口返回的是 string 类对象能存储有效字符的最多个数,该大小取决于编译器的实现。注:这个函数接口没什么用。

clear
clear 是清空类对象的数据,但一般不会清空类对象的空间。

resize 和 reserve
resize 是修改 string 类的有效字符的个数 size 的,而reserve 是修改 string 类对象的容量。这两个函数接口时非常重要的,因为这往往涉及了扩容和缩容的问题。那我们现在通过下面的代码了解一下 string 类的扩容机制。
VS2022 下 string 类的扩容机制
void TestPushBack() { string s; size_t sz = s.capacity(); cout << "making s grow:\n"; for (int i = 0; i < 100; ++i) { s.push_back('c'); if (sz != s.capacity()) { sz = s.capacity(); cout << "capacity changed: " << sz << '\n'; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

Linux 下 string 类的扩容机制
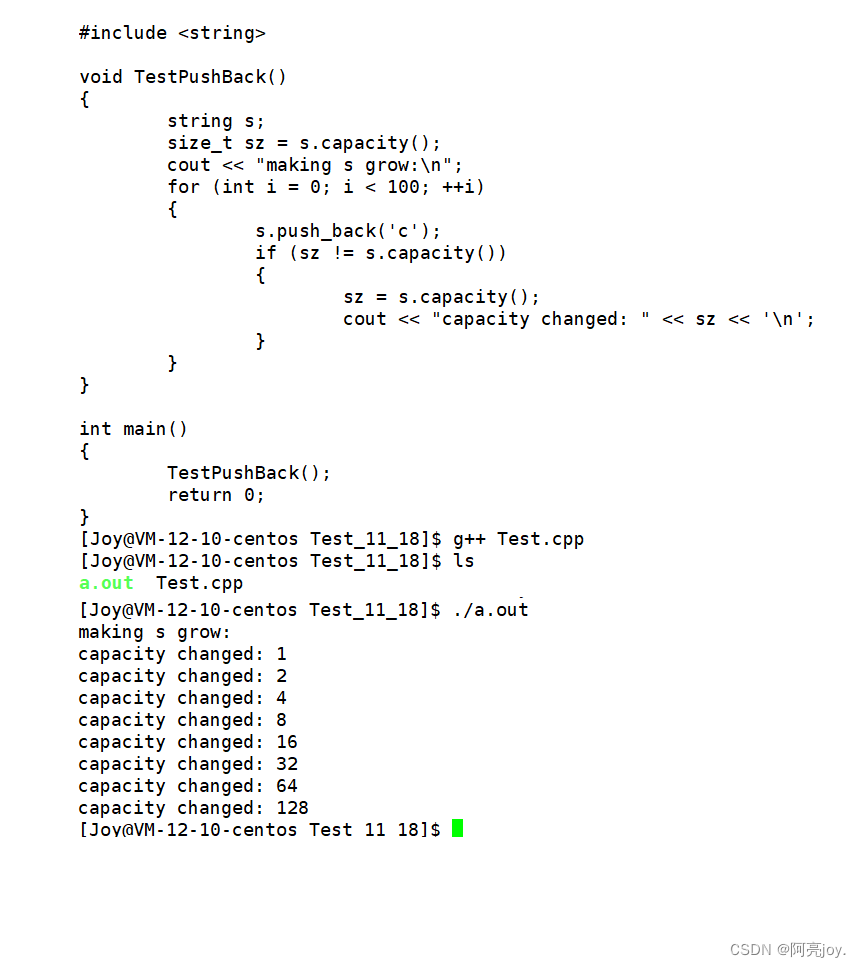
通过上面的图片,我们就可以发现 VS2022 string 类的扩容倍数大约是 1.5 倍,而 Linux 下 string 类的扩容倍数是 2 倍。所以,string 类的扩容倍数取决于编译器的实现,对于 STL 中的其它容器的扩容机制也一样。其实扩容是有效率上的消耗的。如果我们知道需要多少的空间来存储数据,那么我们就可以借助 reserve 来提前讲空间开好,这样就可以避免频繁的扩容。



我们用 reserve 函数先将 s 的容量开到了 100,避免频繁的扩容,提高效率。注意,reserve 函数不会对 size 进行修改。如果想要修改 size,就要通过 resize 函数接口了。


注:当 resize 的第二个参数缺省且 n 大于 capacity 时,会插入'\0'。当 n 小于 capacity 时,一般不会缩容。总结
resize(size_t n) 与 resize(size_t n, char c) 都是将字符串中有效字符个数改变到 n 个,不同的是当字符个数增多时:resize(n) 用 0 来填充多出的元素空间,resize(size_t n, char c) 用字符 c 来填充多出的元素空间。注意:resize 在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。reserve(size_t res_arg=0):为 string 预留空间,不改变有效元素个数,当 reserve 的参数小于 string 的底层空间总大小时,reserver 不会改变容量大小。
shrink_to_fit()

shrink_to_fit 函数接口的功能是使 capacity 和 size 保持一致。

注:上面的程序 capacity 好像没有和 size保持一致,这是跟 VS的对齐规则有关系👉 string 类对象的修改操作👈
函数名称 功能说明 push_back 在字符串后尾插字符c append 在字符串后追加一个字符串 operator+= (重点) 在字符串后追加字符串 str c_str(重点) 返回 C 格式字符串 find + npos(重点) 从字符串 pos 位置开始往后找字符 c,返回该字符在字符串中的位置 rfind 从字符串 pos 位置开始往前找字符 c,返回该字符在字符串中的位置 substr 在 str 中从 pos 位置开始,截取 n 个字符,然后将其返回 push_back

append

append 重载了很多函数,不过我们只需要掌握一些常用的函数接口就行了。其他要用的话,可以再查看文档。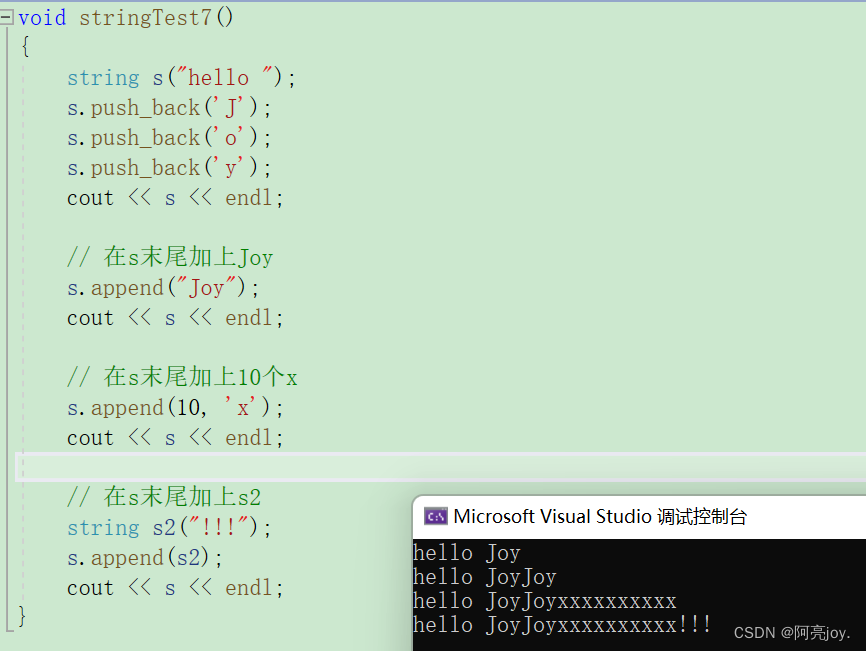
operator +=
append 函数接口不是最常用的,operator += 运算符重载才是最经常用的函数接口,可读性高,使用方便。


insert

注:insert 的接口不经常用,其时间复杂度为 O(N),其接口也比较简单,在这里就不赘述了。erase


注:string& erase (size_t pos = 0, size_t len = npos)该函数是从 pos 位置删除 len 个字符,如果 pos 大于 size,将会抛出异常;如果pos+len>=size,将会删除 pos 删除 pos 位置之后的所有字符以及 pos 位置上的字符。iterator erase (iterator p) 的参数是迭代器,返回值是迭代器。该迭代器指向现在占据第一个被擦除字符位置的字符,如果不存在这样的字符,则返回 string::end。iterator erase (iterator first, iterator last) 该函数删除 [first, last) 之间的字符,返回值同上。assign

assign 这个函数相当于赋值。replace


这个接口了解即可,因为其效率不是很高。find


find 函数是一个查找的函数接口,是比较重要的函数接口,需要熟练掌握。
replace 函数接口的时间复杂度是比较高的,所以上面的代码可以修改成下面的代码。
要求取出文件名的后缀
substr 的函数原型
Linux 下的文件可能会有很多后缀,那如果我们想取出最后一个后缀,怎么解决呢?这时候,就要借助 rfind 函数了。

find_first_of

该函数可以查找给定字符串中的任意一个字符。在这里,就给大家看一个例子,帮助大家理解这个函数。// string::find_first_of #include// std::cout #include // std::string #include // std::size_t int main () { std::string str ("Please, replace the vowels in this sentence by asterisks."); std::size_t found = str.find_first_of("aeiou"); while (found != std::string::npos) { str[found] = '*'; found = str.find_first_of("aeiou",found + 1); } std::cout << str << '\n'; return 0; } // Pl**s*, r*pl*c* th* v*w*ls *n th*s s*nt*nc* by *st*r*sks. - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
c_str
c_str 函数接口返回的是 string 类对象的数组首元素的地址。
打印文件里的内容
#includeusing namespace std; #include #include void stringTest14() { string file("Test.cpp"); FILE* fout = fopen(file.c_str(), "r"); assert(fout); char ch = fgetc(fout); while (ch != EOF) { cout << ch; ch = fgetc(fout); } } int main() { stringTest14(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

👉两道简单题👈
字符串最后一个单词的长度

#includeusing namespace std; #include int main() { string s; getline(cin, s); size_t pos = s.rfind(' '); cout << s.size() - pos - 1 << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

注:cin 遇到空格或者换行就不会在输入缓冲区里提取数据。getline

注:getline 函数也可以从输入缓冲区提取数据,其提取结束标识可以自己指定。如果不指定,默认为换行符。验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是回文串 ,返回 true ;否则,返回 false 。
思路:先写一个函数判断是不是数字或者字母,如果利用快排的思想,定义两个下标 begin 和 end,略过其他字符,找出字母或者数字,比较是否相等。如果不相等,直接返回 false;如果相等,则 begin++,end–。如果循环结束,还是相等,则该字符串是题目所描述的回文串,返回true。
class Solution { public: bool isLetterOrNumber(char ch) { return (ch >= '0' && ch <= '9') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'); } bool isPalindrome(string s) { // 先将大写字母转换成小写字母,再进行判断 for(auto& ch : s) { if(ch >= 'A' && ch <= 'Z') ch += 32; } int begin = 0, end = s.size() - 1; while(begin < end) { while(begin < end && !isLetterOrNumber(s[begin])) ++begin; while(begin < end && !isLetterOrNumber(s[end])) --end; if(s[begin] != s[end]) { return false; } else { ++begin; --end; } } return true; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

-
相关阅读:
我们再来谈一谈HashMap呗(负载因子,遍历角度)
Hadoop原理,HDFS架构,MapReduce原理
闲鱼垃圾评论检测2019CIKM《Spam Review Detection with Graph Convolutional Networks》
电脑重装系统后Win10如何添加系统组件
【GitLab私有仓库】在Linux上用Gitlab搭建自己的私有库并配置cpolar内网穿透
GDP-L-岩藻糖二钠盐,GDP-fucose ,6-Deoxy-β-L-galactopyranosylguanosine 5′-diphosphate
DSPE-PEG-iRGD,磷脂-聚乙二醇-靶向穿膜肽iRGD,用于主动靶向研究
【译】.NET 7 中的性能改进(四)
NIO 基础总结
LeetCode_多指针_二分搜索_中等_792.匹配子序列的单词数
- 原文地址:https://blog.csdn.net/m0_63639164/article/details/127911191