-
浅谈前缀索引
一.什么是前缀索引
所谓前缀索引说白了就是对字符串的前n个字符建立索引
二.为什么选择前缀索引
一般来说使用前缀索引,可能都是因为整个字段的数据量太大,没有必要针对整个字段建立索引,前缀索引仅仅是选择一个字段的前n个字符作为索引,这样一方面可以节约索引空间,另一方面则可以提高索引效率,当然很明显,这种方式也会降低索引的选择性。这里又涉及到一个概念,索引选择性
三.什么是索引选择性
它是指不重复的索引值和数据表的记录总数的比值,取值范围在 [0,1] 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让 MySQL 在查找时过滤掉更多的行。
那是不是选择性越高的索引越好呢?也不全是,就拿唯一索引举例,数据具有唯一性,那么索引选择性肯定为1,搜索时能直接通过搜索条件定位到具体一行记录,这个时候虽然性能最好,但是也是最费空间的(相对于前缀),而前缀恰恰就是希望能够在索引的性能和空间之间找到一个平衡,我们希望能够选择足够长的前缀以保证较高的选择性,但是又希望索引不要太过于占用存储空间。四.前缀索引的n应该怎么确定
那么我们该如何选择一个合适的索引选择性呢?索引前缀应该足够长,以便前缀索引的选择性接近于索引的整个列,即前缀的基数应该接近于完整列的基数
五.举个例子
我们来看一个实际的问题,下图的表(test)中假设有6条数据,除主键外,我们没有其他的索引

现在我们有一个需求:根据手机号查询用户id,那前缀索引应该怎么玩呢或者说怎么确定这个n
1.首先我们可以通过如下 SQL 得到全列选择性 (这里结果为1,即没有重复的值)
sql: SELECT COUNT(DISTINCT phone) / COUNT(*) FROM test

2.调试我们的n(索引选择性)
sql: SELECT COUNT(DISTINCT LEFT(phone, N)) / COUNT(*) FROM test;
这里的思路就是不停的追加n的值,获取到最近全列选择性(也就是1),但是N最小的值

其实我们基于表中的数据也可以看出,前三位已经可以达到唯一确定数据的作用了(现实中数据量大切区分度较高,需要调试以确定这个n)

确定好前缀索引的n接下来就可以去创建并使用了
sql: alter table test add index phone_index(phone(3));

执行一个查询sql

3.结合执行计划,我们来分析一下执行过程
- 从 phone_index 索引中找到第一个值为 “134” 的记录(phone 的前3个字符)
- 由于 phone_index 是二级索引,叶子结点保存的是主键值,所以此时拿到主键 id
- 根据主键 id 去回表,在主键索引上找到 id 所在行的完整记录,返回给 server 层。
- server 层判断其 phone 是不是 13499213214(所以执行计划的Extra 为 Using where)
1.如果不是,这行记录丢弃。
2.如果是,将该记录加入结果集 - 索引叶子结点上数据之间是有单向链表维系的,所以接着第一步查找的结果,继续向后读取下一条记录,然后重复 2、3、4 步,直到在 phone_index 上取到的值不为 “134” 时,循环结束。
注意: 如果我们建立了前缀索引的选择性为 1,那么就不需要第 5 步了因为满足条件的值就一条,如果前缀索引选择性小于 1,就需要第五步。
从上流程中,可以合理选择前缀索引长度能够既节省空间,又提高搜索效率。
六:前缀索引的缺点
例1:
凡事都有二面行,那么前缀索引真的完美么,当然不是
我们再看一个场景,根据手机号查询phone,你可能觉得有点傻,其实你可以换成根据手机号查询name,我这里是为了更好去说这个问题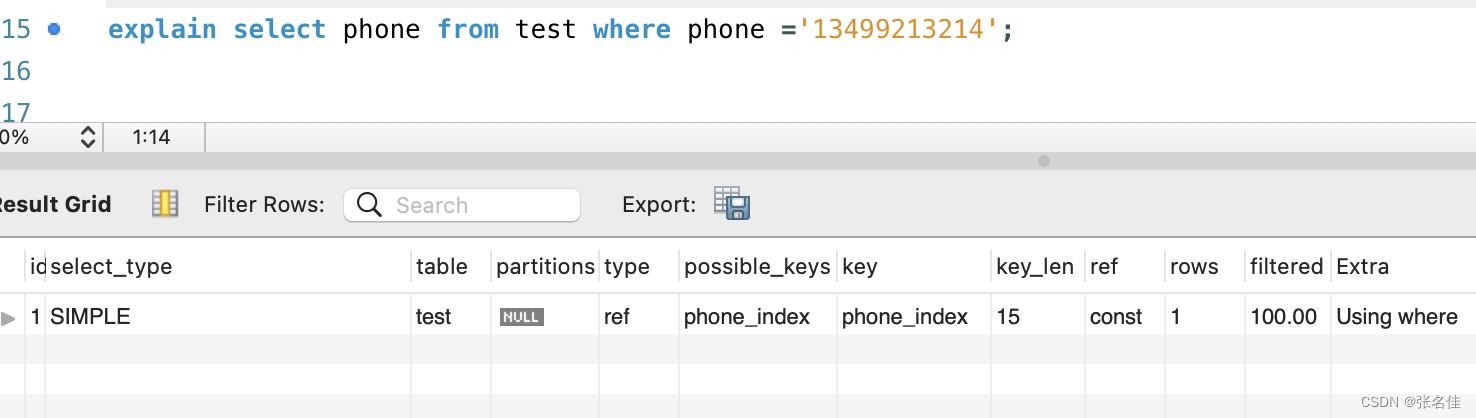
说好的索引覆盖呢?(注意看 Extra 是 Using where)
前缀索引中,B+Tree 里保存的就不是完整的 phone 字段的值(这里成了phone的前3个字符),就需要回表才能拿到需要的数据了,哪怕是这个索引字段本身。所以,用了前缀索引,必须回表,也用不了覆盖索引了。例2:
假设我们的需求是有一个县的居民的身份证信息表,那么我们又该如何给id_card建立前缀索引呢?

1.我们按照之前的分析,我们先确定索引的选择性,但是我们发现身份证号的前8位是居民地址区号,如果还按照之前的方法来做,那么起步的前缀长度就需要8+,甚至10几位才满足区分度,但索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低
2.那么我们可以去替mysql做点事情(这个思路其实很关键,我们在做优化的时候,一定要把mysql当成傻子,多替他去做一些事情,才能更好的达到优化极致),这里我们使用二个方法(当然了还有其他的)
1.“倒叙存储”,查询的时候,在业务代码层,将查询的条件反转,同时将我们数据也反向存储并建立前缀索引,这样可以避免前8位带来的问题
2.“hash处理”,对身份证进行存入另一个字段并加上普通索引,查询的时候由于存在冲突,所以where部分要判断id_card的值是否精确相同。
sql 例如: select id_card,name from test where id_card = “XXX” and id_card_hash_code = "YYYY "七. 总结
- 前缀索引是一种能使索引更小,查询更快的有效办法,但另一方面也有其缺点:例如mysql无法使用其前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做索引覆盖
- 要选择足够长的前缀以保证较高的选择性,同时也要区分业务的不同场景灵活变动
-
相关阅读:
驱动测试开发
要是你想使用异步队列的话,那就试试Reactor Flux吧!
从看ahooks源码说起:源码准备阶段
PHP Xdebug3 + VS Code 新版配置踩坑
安卓优化策略
基于Java毕业设计永川区自行车在线租赁管理系统源码+系统+mysql+lw文档+部署软件
矿物鉴定VR实践教学平台:打造全新的沉浸式学习体验
Qt存手撸界面
MATLAB R2023b安装包下载链接
【PyQt5系列】修改计数器实现控制
- 原文地址:https://blog.csdn.net/zmj199536/article/details/128000550