-
数据挖掘——关联规则理论部分
week11-2022年11月11日|2023年2月16日更新
目录
0.数据挖掘基本算法
Apriori算法
Frequent-patterm tree和FP-growth算法
多维关联规则挖掘
相关规则
基于约束的关联规则挖掘
总结
1.关联规则 Association Rules
关联规则表示了项之间的关系
1.1示例
谷物,牛奶 => 水果
1.2含义
“买谷类食品和牛奶的人也会买水果”
1.3应用
商店可以把谷类食品和牛奶作特价品以使人们买更多的水果
2.市场购物篮分析
2.1分析事务数据库表
Person Basket A 薯片, 沙司, 曲奇, 饼干, 可乐, 啤酒 B 生菜, 菠菜, 桔子, 芹菜, 苹果, 葡萄 C 薯片,沙司, 披萨, 蛋糕 D 生菜,菠菜, 牛奶, 黄油 我们是否可假定?薯片=>沙司 生菜=>菠菜
3.关联规则挖掘
在事务数据库,关系数据库和其他信息库中的项或对象的集合之间,发现频繁模式,关联,相关或因果关系的结构。
4.基本概念
4.1包含
通常数据包含:
TID(事务ID) Basket(项的子集) 4.2频繁模式
数据库中出现频繁的模式(项集,序列,等等);
4.3项集
I = [ i 1 , i 2 , i 3 , . . . , i m ] " role="presentation" style="position: relative;">4.4事务
T ⊆ i " role="presentation" style="position: relative;">4.5关联规则
A => B " role="presentation" style="position: relative;">A ⊂ I , B ⊂ I , A ∩ B = ∅ " role="presentation" style="position: relative;">4.6事务数据集
事务数据集用D表示:
Transaction-id Items bought 10 A,B,C 20 A,C 30 A,D 40 B,E,F 4.7事务标识TID
每一个事务关联着一个标识,称作TID。
5.度量有趣的关联规则
5.1支持度s
D中同时包含A和B的事务数与总的事务数的比值;
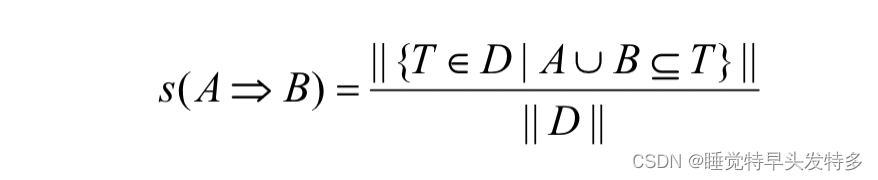
规则
A => B " role="presentation" style="position: relative;">在数据集中D中的支持度为s,其中s表示D中包含A ∪ B " role="presentation" style="position: relative;">(即同时包含A和B)的事务的百分率,即可用条件概率P ( A ∪ B ) " role="presentation" style="position: relative;">表示。support(
A => B " role="presentation" style="position: relative;">)= P ( A ∪ B ) " role="presentation" style="position: relative;">5.2可信度c
D中同时包含A和B的事务数与只包含A的事务数的比值;

规则
A => B " role="presentation" style="position: relative;">在数据集D中的可信度为c,其中c表示D中包含A的事务中也包含B的百分率,即可用条件概率P ( B | A ) " role="presentation" style="position: relative;">表示。confidence(
A => B " role="presentation" style="position: relative;">)= P ( B | A ) " role="presentation" style="position: relative;">5.3条件概率
条件概率
P ( B | A ) " role="presentation" style="position: relative;">表示A发生的条件下B也发生的概率。5.4关联规则标准
关联规则根据以下两个标准(包含或排除):
最小支持度s:表示规则中的所有项在事务中出现的频度。
最小可信度c:表示规则中左边的项(集)的出现暗示着右边的项(集)出现的频度。
6.市场购物篮分析——课堂思考

(1)总共有A,B,C,D四个项集,例如{生菜,菠菜,桔子,芹菜,苹果,葡萄}是一个6项集,{薯片,沙司,披萨,蛋糕}是一个4项集;
(2)生菜,菠菜,桔子,芹菜,苹果,葡萄 ?
(3)支持度s 2(A+C)/4(A+B+C+D)=2/4=1/2;
(4)可信度c 2/2=1。
7.频繁项集
7.1项
项集里面包含的每一个物品;
7.2项集
任意项的集合;
7.3k-项集
包含k个项的项集;
7.4频繁(或大)项集
满足最小支持度的项集。
8.强关联规则
给定一个项集,容易生成关联规则。
项集:{薯片,沙司,啤酒}
啤酒,薯片=>沙司
啤酒,沙司=>薯片
薯片,沙司=>啤酒
8.1强规则
强规则是有趣的;
强规则通常定义为那些满足最小支持度和最小可信度的规则。
给出一个项集,如何生成关联规则?
'买了什么物品之后,还会继续买什么?' ——> 强关联规则
9.关联规则挖掘
两个基本步骤
找出所有的频繁项集(条件:满足最小支持度)
找出所有的强关联规则
——由频繁项集生成关联规则
——保留满足最小可信度的规则
下节预告
L 1 
存在一个数据库:扫描数据库依次得到
C 1 L 1 C 2 L 2 C 3 L 3 只有前两项一致,我们才可以“相连”。
频繁1-项集

构建FP-树

创建根节点...
-
相关阅读:
开发deepstram的自定义插件,使用gst-dseaxmple插件进行扩充,实现deepstream图像输出前的预处理,实现图像自定义绘制图(精四)
【跟着大佬学JavaScript】之数组去重(结果对比)
深入理解ngx_http_upstream_vnswrr_module负载均衡模块
Intel 高性能库之IPP信号处理简介及下载(版本5.1、6.1,含32位和64位及注册)
Spring Security(七) ——跨域配置
2023/9/9总结
企业内业务系统与Activiti流程引擎的结合(十二)
web蓝桥杯真题:绝美宋词
不用 Spring 居然连最基本的接口都不会写了!
Java 中 List 删除元素
- 原文地址:https://blog.csdn.net/m0_57656758/article/details/127807447