-
spark3.3.1 for CDH6.3.2 打包
spark3.3.1 CDH 打包
因为 CDH 在 6.3.2 之后开始收费,而自带的spark版本太低,还阉割了 spark-sql 功能。所以我们直接外挂spark3.3.1,使用 CDH 6.3.2 相关的 hadoop lib。
下载相关组件
wget https://archive.apache.org/dist/maven/maven-3/3.8.6/source/apache-maven-3.8.6-src.tar.gz wget https://archive.apache.org/dist/spark/spark-3.3.1/spark-3.3.1.tgz mv spark-3.3.1.tgz apache-maven-3.6.3-src.tar.gz /opt/ cd /opt/ tar -zxvf spark-3.3.1.tgz tar -zxvf apache-maven-3.6.3-src.tar.gz- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
更改环境变量
# 登陆 10.0.1.20 # 环境变量的一些相关配置 可忽略 # 实例: ava.sh maven.sh scala.sh ==> java.sh <== export JAVA_HOME=/opt/jdk1.8.0_351 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=${JAVA_PATH}:${PATH} ==> maven.sh <== export MAVEN_HOME=/opt/apache-maven-3.6.3 export PATH=$PATH:$MAVEN_HOME/bin ==> scala.sh <== export SCALA_HOME=/opt/scala-2.12.17 export PATH=$PATH:$SCALA_HOME/bin # 验证 请保证每个环境参数都存在。 echo $JAVA_HOME echo $JRE_HOME echo $CLASSPATH echo $JAVA_PATH echo $MAVEN_HOME echo $SCALA_HOME echo $PATH # 上述的JAVA JRE MAVEN都存在 java -version scala -version mvn -v- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
更改相关配置文件
添加maven中央仓库 和 cloudera 仓库
vim ${SPARK_HOME}/pom.xml- 1
在 repositories中添加
<repository> <id>alimavenid> <name>aliyun mavenname> <url>http://maven.aliyun.com/nexus/content/groups/public/url> <releases> <enabled>trueenabled> releases> <snapshots> <enabled>falseenabled> snapshots> repository> <repository> <id>clouderaid> <url>https://repository.cloudera.com/artifactory/cloudera-repos/url> repository>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里也需要将hadoop verison进行更改
<hadoop.version>3.0.0-cdh6.3.2hadoop.version> <maven.version>3.6.3maven.version>- 1
- 2
更改mvn地址
vim ./dev/make-distribution.sh #MVN="$SPARK_HOME/build/mvn" MVN="/opt/apache-maven-3.6.3/bin/mvn"- 1
- 2
- 3
maven 打包参数
vim ./dev/make-distribution.sh # 将原始 export MAVEN_OPTS="${MAVEN_OPTS:--Xmx2g -XX:ReservedCodeCacheSize=1g}" # 更改为 export MAVEN_OPTS="${MAVEN_OPTS:--Xmx6g -XX:ReservedCodeCacheSize=2g}"- 1
- 2
- 3
- 4
更改 scala版本
scala -version # 2.12 ./dev/change-scala-version.sh 2.12- 1
- 2
- 3

maven编译命令
用的是spark的 ./dev/make-distribution.sh 脚本进行编译,这个脚本其实也是用maven编译的,
- –tgz 指定以tgz结尾
- –name后面跟的是我们Hadoop的版本,在后面生成的tar包我们会发现名字后面的版本号也是这个(这个可以看make-distribution.sh源码了解)
- -Pyarn 是基于yarn
- -Dhadoop.version=3.0.0-cdh6.3.2 指定Hadoop的版本。
./dev/make-distribution.sh \ --name 3.0.0-cdh6.3.2 --tgz -Pyarn -Phadoop-3.0 \ -Phive -Phive-thriftserver -Dhadoop.version=3.0.0-cdh6.3.2 -X- 1
- 2
- 3

maven打包完毕
版本包打完结果:


会有一个名为 spark-3.3.1-bin-3.0.0-cdh6.3.2.tgz 的版本包出现。
安装 spark3-cdh
在 /opt/cloudera/parcels/CDH/ 中安装spark-3.3.1
cp spark-3.3.1-bin-3.0.0-cdh6.3.2.tgz /opt/cloudera/parcels/CDH/lib cd /opt/cloudera/parcels/CDH/lib tar -zxvf spark-3.3.1-bin-3.0.0-cdh6.3.2.tgz mv spark-3.3.1-bin-3.0.0-cdh6.3.2 spark3- 1
- 2
- 3
- 4
配置 spark-env
cp /etc/spark/conf/spark-env.sh /opt/cloudera/parcels/CDH/lib/spark3/conf vim ./conf/spark-env.sh # 更改一下 SPARK_HOME(其实也不用更改,但需要确认目录是否正确) cp /etc/hive/conf/hive-site.xml /opt/cloudera/parcels/CDH/lib/spark3/conf/ # 确保CDH已经正常启动,并且resourcesManager已经启动- 1
- 2
- 3
- 4
- 5
- 6

编辑一个 spark-sql
vim ${SPARK3_HOME}/bin/spark-sql #vim /opt/cloudera/parcels/CDH/bin/spark-sql #!/bin/bash # Reference: http://stackoverflow.com/questions/59895/can-a-bash-script-tell-what-directory-its-stored-in export HADOOP_CONF_DIR=/etc/hadoop/conf export YARN_CONF_DIR=/etc/hadoop/conf SOURCE="${BASH_SOURCE[0]}" BIN_DIR="$( dirname "$SOURCE" )" while [ -h "$SOURCE" ] do SOURCE="$(readlink "$SOURCE")" [[ $SOURCE != /* ]] && SOURCE="$BIN_DIR/$SOURCE" BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )" done BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )" LIB_DIR=$BIN_DIR/../lib export HADOOP_HOME=$LIB_DIR/hadoop # Autodetect JAVA_HOME if not defined . $LIB_DIR/bigtop-utils/bigtop-detect-javahome exec $LIB_DIR/spark3/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
完成后使用 alternatives 进行环境变量管控
alternatives --install /usr/bin/spark-sql spark-sql /opt/cloudera/parcels/CDH/bin/spark-sql 1 alternatives --config spark-sql # 如果有多个版本,切换为刚刚配置的- 1
- 2
- 3

验证 spark-sql
进入spark-sql
show databases; use ods; show tables;- 1
- 2
- 3
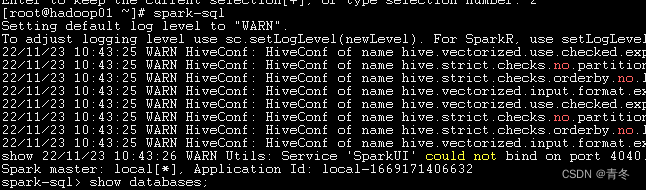
该节点spark-sql搭建完毕。
其余节点只需要scp spark包,并进行对应操作即可。
PS 打包出来的文件
https://download.csdn.net/download/qq_36610426/87125679
不需要积分下载,请好评!
-
相关阅读:
docker通过挂载conf文件启动redis
牛血清白蛋白标记微囊藻毒素(MCLR)(BSA-MCLR)
基于Java的城市桥梁道路管理系统(Vue.js+SpringBoot)
d3dx9_39.dll丢失怎么修复?d3dx9_39.dll丢失的四种修复办法分享
Java并发-交替打印的四种方法。
【MATLAB教程案例21】图像的初步认识,通过MATLAB对图像进行简单操作——读、写、缩放、二值图、直方图、灰度图、色度空间转化等
SpringBoot综合案例——Dubbo-Zookeeper-MyBatis-MySQL-Redis
Parker派克高速电机MGV【高速、低惯性】测试台应用
前端实现Jest单元测试
《MySQL实战45讲》——学习笔记01 “MySQL基本架构和redo log两阶段提交“
- 原文地址:https://blog.csdn.net/qq_36610426/article/details/127997188
