-
Trie字典树详解
📖1. 什么是Trie树
Trie树,又叫字典树,前缀树(Prefix Tree),单词查找树,是一种多叉树的结构.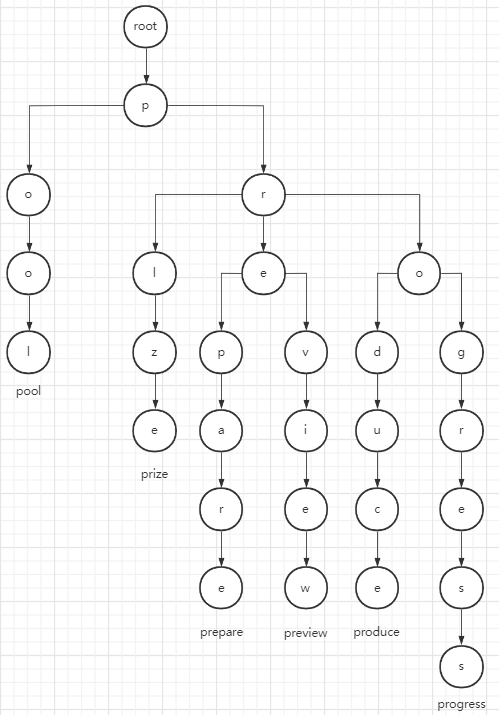
上图就是一颗
Trie树,表示了关键字集合{"pool", "prize", "prepare", "preview", "produce", "progress"}.字典树的基本性质如下:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同.
算法核心:利用字符串的公共前缀来减少查询时间,最大限度的减少无畏字符串的比较.
使用范围:
- 单词检索
- 统计和排序字符串
- 字符串前缀搜索
我们来看一个场景:

当我们在浏览器的搜索框中打出一个字符串的前缀时,它便实时的显示出了以这个输入为前缀的一些字符串,也就是说,它帮我们搜索到了以这个输入为前缀的所有字符串,并且显示出了搜索频率较高的一些,这就是字典树的一个应用场景:单词自动补齐.
📖2. Trie树的一些应用场景
除了自动补齐的例子外,
Trie树还有一些其他的应用场景:-
串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词.
-
单词自动完成
编辑代码时,输入字符,自动提示可能的关键字,变量或函数等信息.
-
最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即它们所在的节点的公共祖先个数,问题就转化为最近公共祖先问题
-
串排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,将他们按字典序从小到大输出. 用字典树进行排序,这棵树的每个节点的所有子节点很明显的按照其字母大小排序,对这棵树进行前序遍历即可.
📖3. Trie树的优缺点
Trie树的核心思想是空间换时间,利用字符串的公共前缀来减少无畏字符串的比较以达到提高查询效率的目的.优点:插入和查询的效率高,都为
O(m),其中m是待插入/查询的字符串的长度.关于查询,可能有人会说,哈希表的时间复杂度为O(1),岂不是更快?
- 哈希表的效率通常取决于哈希函数的好坏,若一个坏的哈希函数可能会导致发生许多冲突,将具有相似前缀的字符串映射到同一个哈希桶中,在进行这个哈希桶中进行查找时,就会导致这些相同前缀的重复比较,效率并不一定比
Trie树高. Trie树中的不同关键字不会产生哈希冲突Trie树可以对关键字按字典序排序
缺点:当所有关键字都不具有相同或类似的前缀,空间消耗过大.
📖4. Trie树的节点怎样定义
对于
Trie树,它是一个多叉树的结构,所有我们可以在节点中定义map来存储孩子节点字符数据和节点指针的对应关系.在查找的过程中,我们怎样标定字符串的结尾呢?

所以节点的定义:
struct TrieNode { //节点中存储的字符数据 char ch_; //单词的末尾字符存储单词的数量 int freqs_; //存储孩子节点字符数据和节点指针的对应关系 std::map- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
📖5. 代码实现
#include#include #include #include #include using namespace std; class TrieTree { public: TrieTree() { root_ = new TrieNode('\0', 0); } public: //添加单词 void add(const string& word) { TrieNode* cur = root_; for (int i = 0; i < word.size(); ++i) { auto childIt = cur->nodeMap_.find(word[i]); if (childIt == cur->nodeMap_.end()) { //相应的字符的节点没有,创建它 TrieNode* child = new TrieNode(word[i], 0); cur->nodeMap_.emplace(word[i], child); cur = child; } else { //相应的字符节点已经存在,移动cur指向对应的节点 cur = childIt->second; } } //cur指向了word单词的最后一个节点 cur->freqs_++; } //查询单词 int query(const string& word) { TrieNode* cur = root_; for (int i = 0; i < word.size(); ++i) { auto childIt = cur->nodeMap_.find(word[i]); if (childIt == cur->nodeMap_.end()) { return 0; } //移动cur指向下一个单词的字符节点上 cur = childIt->second; } //最终指向了这个单词的最后一个字符 return cur->freqs_; } //删除单词 void remove(const string& word) { TrieNode* cur = root_; TrieNode* del = root_; //从哪个节点开始删除 char delch = word[0]; for (int i = 0; i < word.size(); ++i) { auto childIt = cur->nodeMap_.find(word[i]); if (childIt == cur->nodeMap_.end()) return; //pool po情况二和情况三 if (cur->freqs_ > 0 || cur->nodeMap_.size() > 1) { del = cur; delch = word[i]; } //cur移动到子节点 cur = childIt->second; } //cur指向了末尾节点 if (cur->nodeMap_.empty()) { //开始删除 TrieNode* child = del->nodeMap_[delch]; del->nodeMap_.erase(delch); //释放相应的节点内存 queue<TrieNode*> que; que.push(child); while (!que.empty()) { TrieNode* front = que.front(); que.pop(); //把当前节点的孩子全部入队列 for (auto& pair : front->nodeMap_) { que.push(pair.second); } //释放当前节点资源 delete front; } } else { //情况1 //当前单词末尾字符后面还有字符节点,不做任何节点删除操作 cur->freqs_ = 0; } } //前序遍历字典树 void preOrder() { string word; vector<string> wordList; preOrder(root_, word, wordList); for (auto word : wordList) { cout << word << endl; } cout << endl; } //串的前缀搜索 vector<string> queryPrefix(const string& prefix) { TrieNode* cur = root_; for (int i = 0; i < prefix.size(); ++i) { auto childIt = cur->nodeMap_.find(prefix[i]); if (childIt == cur->nodeMap_.end()) { return {}; } cur = childIt->second; } //cur指向了前缀的最后一个字符节点了 vector<string> wordList; preOrder(cur, prefix.substr(0, prefix.size() - 1), wordList); return wordList; } private: struct TrieNode { TrieNode(char ch, int freqs) : ch_(ch) , freqs_(freqs) {} //节点中存储的字符数据 char ch_; //单词的末尾字符存储单词的数量 int freqs_; //存储孩子节点字符数据和节点指针的对应关系 std::map<char, TrieNode*> nodeMap_; }; private: void preOrder(TrieNode* cur, string word, vector<string>& wordList) { //前序遍历 根 左 右 if (cur != root_) { word.push_back(cur->ch_); if (cur->freqs_ > 0) { wordList.push_back(word); } } //递归处理子节点 for (auto pair : cur->nodeMap_) { preOrder(pair.second, word, wordList); } } private: TrieNode* root_; //指向树的根结点 }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
//功能测试: #include "TrieTree.h" int main() { TrieTree trie; trie.add("hello"); trie.add("hello"); trie.add("helloo"); trie.add("hel"); trie.add("hel"); trie.add("hel"); trie.add("china"); trie.add("ch"); trie.add("ch"); trie.add("heword"); trie.add("hellw"); cout << "数量统计: " << endl; cout << trie.query("hello") << endl; cout << trie.query("helloo") << endl; cout << trie.query("hel") << endl; cout << trie.query("china") << endl; cout << trie.query("ch") << endl; cout << "=====================" << endl; cout << "前序遍历: " << endl; trie.preOrder(); cout << "=====================" << endl; vector<string> words = trie.queryPrefix("he"); cout << "前缀串搜索: " << endl; for (auto word : words) { cout << word << endl; } cout << endl; trie.remove("hellw"); cout << "=====================" << endl; cout << "删除测试: " << endl; trie.preOrder(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
📖6. 字典树的优化
上面我们提到过,字典树有一个缺点:占用内存空间过大.
所以,我们可以将字典树进行优化:
字符节点后面没有其他单词,可以把字符节点压缩到一个节点中进行存储.

-
相关阅读:
2022-08-30 第六小组 瞒春 学习笔记
【Vue】style和class 列表渲染 使用v-for进行循环 监控失效 双向数据绑定 过滤案例 事件修饰符
OpenCV的C#版本EmguCV-1、安装和环境配置
推文项目进展如何
chatGPT快捷键(最新版本)
dRep-基因组质控、去冗余及物种界定
Node.js个人博客
Java Websocket 02: 原生模式通过 Websocket 传输文件
Google DataFlow入门与(Pub/Sub-DataFlow-BigQuery解决方案)
3.webpack4初体验(webpack可以处理的文件)
- 原文地址:https://blog.csdn.net/smf12138/article/details/127984898
