-
JVM 内存结构 和 垃圾回收
JVM 内存结构 和 垃圾回收
1. 引言
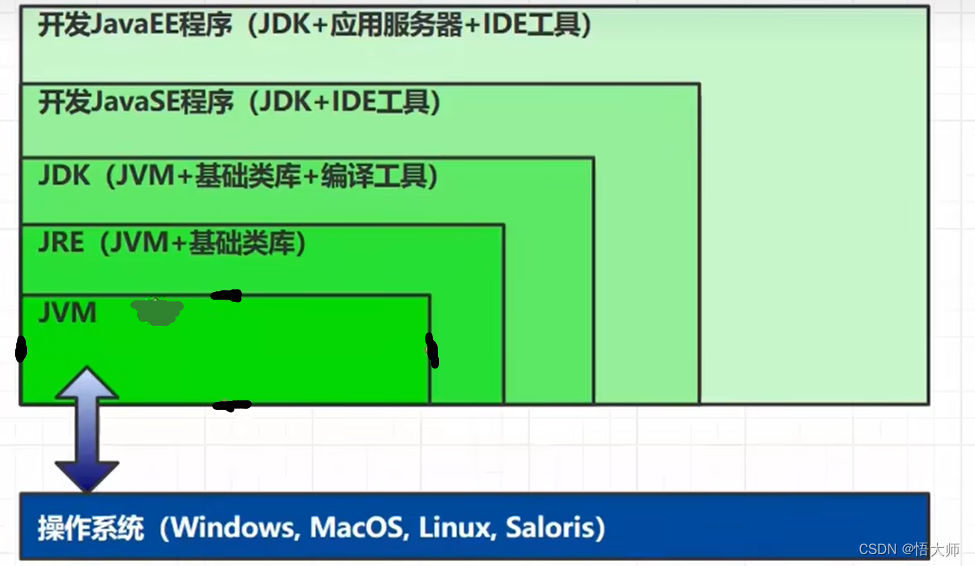
1.1 什么是 JVM ?
Java Virtual Machine - java 程序的运行环境(java 二进制字节码的运行环境)
好处:
- 一次编写,到处运行
- 自动内存管理,垃圾回收功能
- 数组下标越界,越界检查
- 多态
比较:
jvm、jre、jdk
1.2 学习路线

2. 内存结构
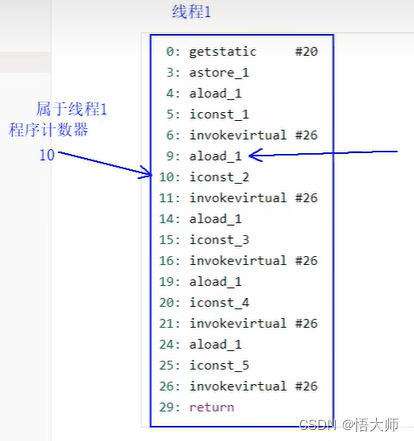
2.1 程序计数器
Program Counter Register 程序计数器(寄存器)
-
作用:是记住下一条 JVM 指令的执行地址。
-
特点:
-
是线程私有的
-
不会存在内存溢出
-
2.2 虚拟机栈
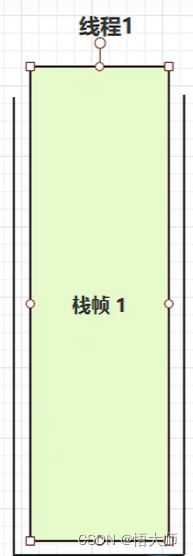
- 栈:线程运行需要的内存空间
- 栈帧:每个方法运行时需要的内存(参数、局部变量、返回地址)

2.2.1 定义
Java Virtual Machine Stacks(Java 虚拟机栈)
- 每个线程运行时所需要的内存,称为虚拟机栈。
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存。
- 每个线程只能由一个活动栈帧,对应着当前正在执行的那个方法。
2.2.1.1 问题辨析
-
垃圾回收是否设计栈内存?
- 不涉及,因为每次方法调用结束后,都会被弹出栈,被自动回收,所以不需要垃圾回收来管理栈内存。
- 垃圾回收只涉及堆内存中的对象,对于栈内存并不涉及。
-
栈内存分配越大越好吗?
- 在具体的虚拟机中的栈的大小都有规定。
- 而且栈内存的大小并不是越大越好,栈内存越大,可能会使线程的空间被压缩变小。

- 方法内的局部变量是否线程安全?
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
- 如果是局部变量引用了对象,并逃离方法的作用方法,需要考虑线程安全
public class Demo1_18 { //多个线程同时执行此方法 static void m1() { int x=0; for(int i=0; i<5000; i++) { x++; } System.out.println(x); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

对于局部变量并不会发生内存安全问题,因为对于每一个线程的栈都是私有的,其中会分别拥有一个自己的局部变量,互不影响。
但是,对于 static 不一样,static 静态变量是共享的,会产生线程安全问题。如下图:

判断以下的方法会不会发生局部变量的线程安全问题?
public class Demo1_17 { public static void main(String[] args) { } // m1 不会发生局部变量的线程安全问题,原因跟上面一样 public static void m1() { StringBuilder sb = new StringBuilder(); sb.append(1); sb.append(2); sb.append(3); System.out.println(sb.toString()); } // m2 不是线程安全,如下 /*public static void main(StringI] args) { StringBuilder sb = new StringBuilder(); sb.append(4); sb.append(5); sb.append(6); new Thread(()->{ m2(sb); }).start(); }*/ public static void m2(StringBuilder sb) { sb.append(1); sb.append(2); sb.append(3); System.out.println(sb.toString()); } // m3 不是线程安全,理由同 m2 public static StringBuilder m3() { StringBuilder sb = new StringBuilder(); sb.append(1); sb.append(2); sb.append(3); return sb; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
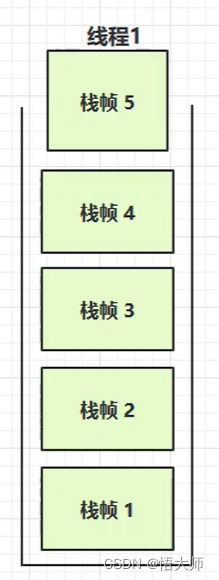
2.2.2 栈内存溢出
-
栈帧过多导致栈内存溢出
- 对于递归调用出口不正确。或者转换为 json 对象时,其中的两个对象之间互相引用,这时需要使用 @jsonignore 来阻止递归引用。
-
栈帧过大导致栈内存溢出
2.2.3 线程运行诊断
2.2.3.1 cpu 占用过多
定位:
- 用
top定位哪个进程对 cpu 的占用过高 ps H -eo pid,tid,%cpu | grep 进程id,用ps命令进一步定位是哪个线程引起的 cpu 占用过高。jstack 进程id- 可以根据线程 id 找到有问题的线程,进一步定位到问题代码的源码行号
2.2.3.2 程序运行很长时间但是没有结果
nohup java cn.itcast.jvm.t1.Demo1_3 &2.3 本地方法栈
-
Java 虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。
-
本地方法栈,也是线程私有的。
-
允许被实现成固定或者是可动态扩展的内存大小。(在内存溢出方面是相同的)
- 如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java 虚拟机将会抛出一个
StackoverflowError异常。 - 如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存 或者 在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个
OutofMemoryError异常。
- 如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java 虚拟机将会抛出一个
-
本地方法是使用 C语言 实现的。
-
它的具体做法是 Native Method Stack 中 登记 native 方法,在 Execution Engine 执行时加载本地方法库。
-
当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虛拟机限制的世界。它和虚拟机拥有同样的权限:
-
本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区。
-
它甚至可以直接使用本地处理器中的寄存器
-
直接从本地内存的堆中分配任意数量的内存。
-
-
并不是所有的 JVM 都支持本地方法。因为 Java虚拟机规范 并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果 JVM 产品不打算支持 native 方法,也可以无需实现本地方法栈。
-
在Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。
2.4 堆
2.4.1 定义
通过 new 关键字,创建对象都会使用堆内存。
特点:
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
2.4.2 堆内存溢出
/** * 演示堆内存溢出java.lang.OutOfMemoryError: Java heap space * -Xmx8m */ public class Demo1 _5{ public static void main(String[] args) { int i=0; try { List<String> list = new ArrayList<>(); String a = "hello"; while (true) { list.add(a); // hello, hellohello, hellohellohellohello ... a= a + a; // hellohellohellohe1lo i++; } } catch (Throwable e) { e.printStackTrace(); System.out.println(i); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.4.3 堆内存诊断
-
jps工具
- 查看当前系统中有哪些 java 进程
-
jmap工具
- 查看堆内存占用情况
jmap -heap -进程id
-
jconsole工具
- 图形界面的,多功能的监测工具,可以连续监测
-
jvisualvm工具
2.5 方法区
2.5.1 定义

2.5.2 组成

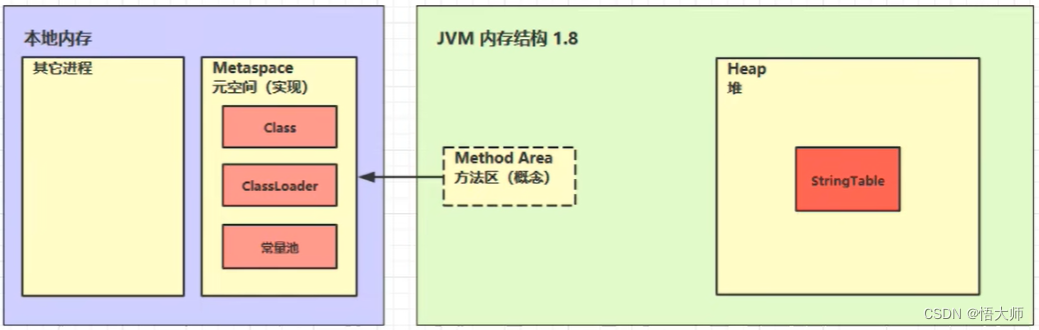
2.5.3 方法区内存溢出
-
1.8 以前会导致永久代内存溢出
-
/** * 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space * -XX:MaxPermSize=8m */- 1
- 2
- 3
- 4
-
-
1.8 以后会导致元空间内存溢出
-
/** * 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace * -XX:MaxMetaspaceSize=8m */ public class Demo1_8 extends ClassLoader { // 可以用来加戴类的二进制字节码 public static void main(String[] args) { int j=0; try { Demo1_8 test = new Demo1_8(); for(int i=0; i<10000; i++, j++){ // ClassWriter作用是生成类的二进制字节码 ClassWriter CW = new ClassWriter(0); // 版本号, pub1ic, 类名, 包名, 父类, 接口 CW.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/0bject", null); // 返回byte[] byte[] code = CW.toByteArray(); // 执行了类的加载 test.defineClass("Class" + i, code, 0, code.length); // Class 对象 } } finally { System.out.println(j); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
-
2.5.4 常量池
// 二进制字节码(类基本信息,常量池,类方法定义,包含了虚拟机指令) public class HelloWorld { public static void main(String[] args) { System.out.println("hello world"); } }- 1
- 2
- 3
- 4
- 5
- 6
使用以下命令可以反编译 *.class 文件,达到判断的效果
javap -c 文件名- 1

类的基本信息:

常量池:

类方法定义:

2.5.5 运行时常量池
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池,常量池是
*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
2.5.6 StringTable
先看几道面试题:
String s1 = "a"; String s2 = "b"; String s3 = "a" + "b"; String s4 = s1 + s2; String s5 = "ab"; String s6 = s4.intern(); //问 System.out.println(s3 == s4); // false System.out.println(s3 == s5); // true System.out.println(s3 == s6); // true String x2 = new String("c") + new String("d"); String x1 = "cd"; x2.intern(); System.out.println(x1 == x2); // false //问,如果调换了[最后两行代码]的位置呢 System.out.println(x1 == x2); // true // 问,如果调换了[最后两行代码]的位置呢,如果是jdk1.6呢 System.out.println(x1 == x2); // false- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder (1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用
intern方法,主动将串池中还没有的字符串对象放入串池- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
- 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回
// StringTable [ "a", "b", "ab" ] hashtable 结构,不能扩容 public class Demo1_22 { //常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象 // Idc #2 会把 a 符号变为 "a" 字符串对象 // Idc #3 会把 b 符号变为 "b" 字符串对象 // Idc #4 会把 ab 符号变为 "ab" 字符串对象 public static void main(String[] args) { String s1 = "a"; //懒惰的 String s2 = "b"; String s3 = "ab"; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
类方法定义:

运行时常量池:

// StringTable [ "a", "b", "ab" ] hashtable 结构,不能扩容 public class Demo1_22 { //常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象 // Idc #2 会把 a 符号变为 "a" 字符串对象 // Idc #3 会把 b 符号变为 "b" 字符串对象 // Idc #4 会把 ab 符号变为 "ab" 字符串对象 public static void main(String[] args) { String s1 = "a"; //懒惰的 String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab") System.out.println( s3==s4 ); //false } } // StringBuilder 的 toString()方法 @Override public String toString() { // Create a copy, don't share the array return new String(value, 0, count) ; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
类方法定义:

// StringTable [ "a", "b”, "ab" ] hashtable 结构,不能扩容 public class Demo1_22 { //常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象 // Idc #2 会把 a 符号变为 "a" 字符串对象 // Idc #3 会把 b 符号变为 "b" 字符串对象 // Idc #4 会把 ab 符号变为 "ab" 字符串对象 public static void main(String[] args) { String s1 = "a"; // 懒惰的 String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab") String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为 ab System.out.println( s3==s5 ); //true } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

// intern() 函数 // StringTable [ "a", "b" , "ab"(到12行放入)] public class Demo1_23 { public static void main(String[] args) { String s = new String("a") + new String("b"); // new String("ab") // 堆 new String("a") new String("b") new String("ab") String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回 System.out.println( s2=="ab" ); //true } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
// intern() 函数 // StringTable [ "ab" , "a", "b" ] public class Demo1_23 { public static void main(String[] args) { String x = "ab"; String s = new String("a") + new String("b"); // 堆 new String("a") new String("b") new String("ab") String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回 System.out.println( s2==x ); //true System.out.println( s==x ); //false } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
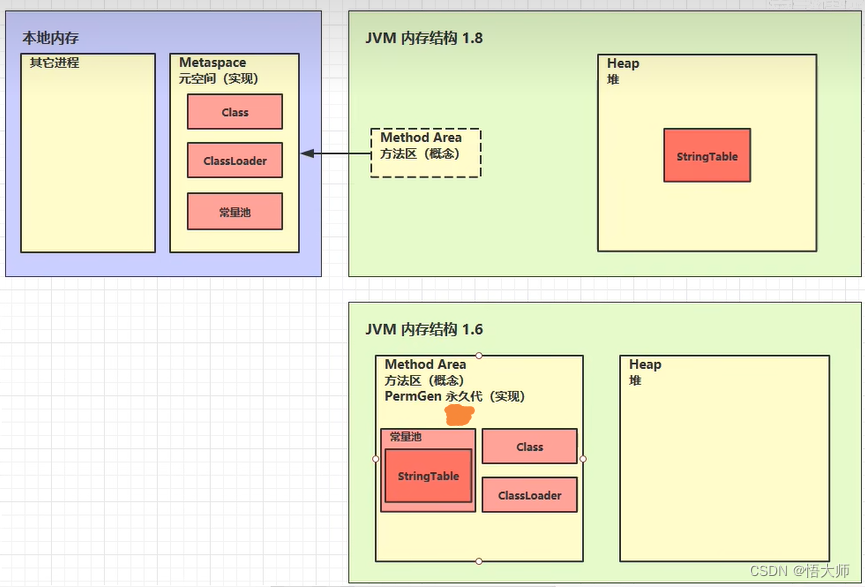
2.5.6.1 StringTable 的位置
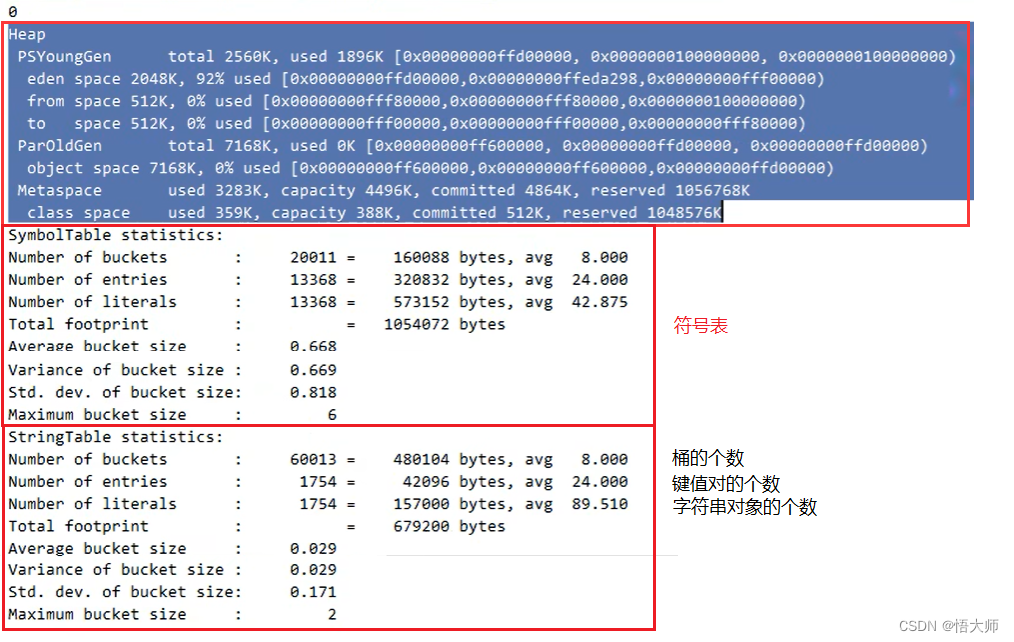
2.5.6.2 StringTable 的垃圾回收
/** * 演示 StringTable 垃圾回收 * -Xmx1Om -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:go */ public class Demo1_7 { public static void main(String[] args) throws InterruptedException { int i=0; try { } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
/** * 演示 StringTable 垃圾回收 * -Xmx1Om -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:go */ public class Demo1_7 { public static void main(String[] args) throws InterruptedException { int i=0; try { for (int j = 0; j < 10000; j++) { // j=10000 String.valueOf(j).intern(); i++; } } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
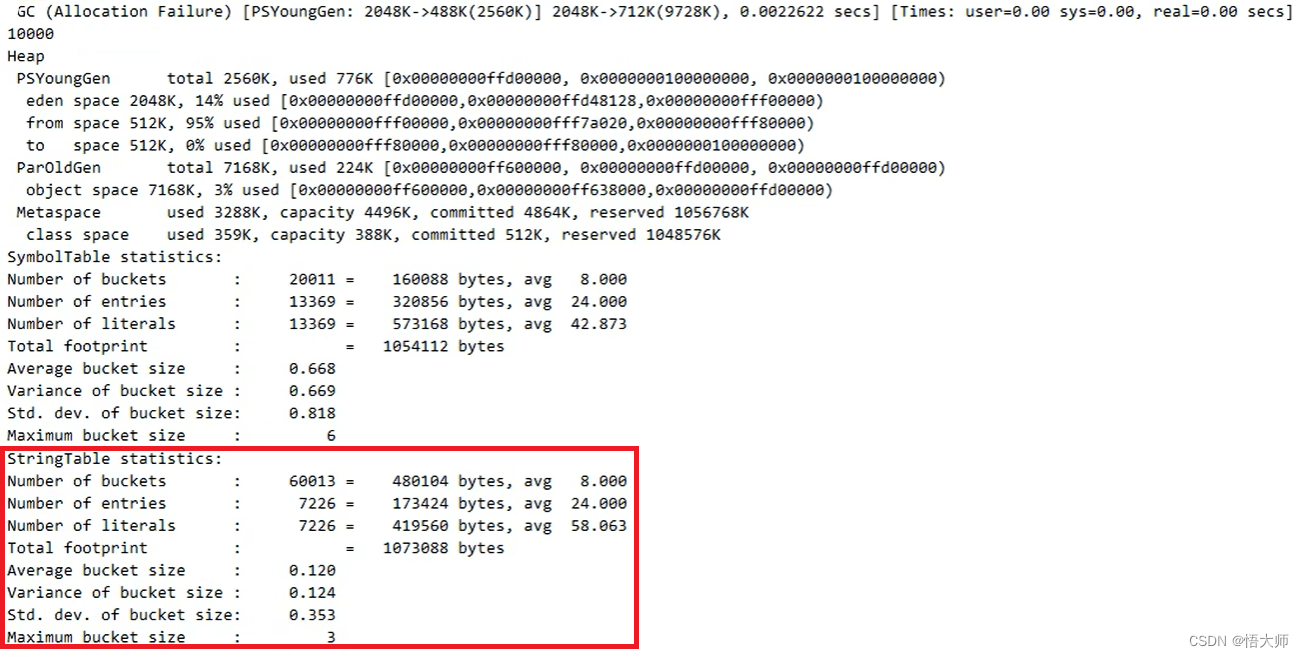
2.5.6.3 StringTable 性能调优
- 调整
-XX:StringTableSize=桶个数的值,使得有合适的哈希分布,减少哈希冲突。 - 考虑将字符串对象是否入池
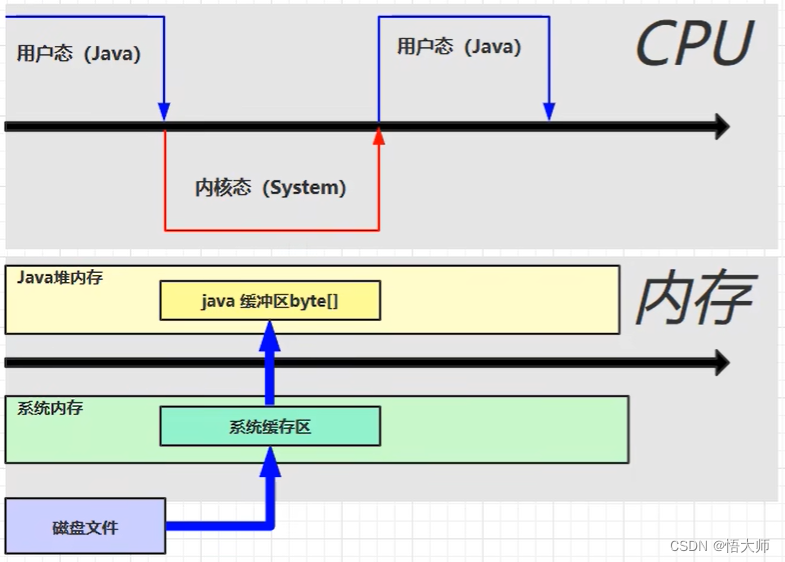
2.5.7 直接内存
2.5.7.1 定义
Direct Memory
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理

package cn.itcast.jvm.t1.direct; import java.io.IOException; import java.nio.ByteBuffer; /** * 禁用显式回收对直接内存的影响 */ public class Demo1_26 { static int _1Gb = 1024 * 1024 * 1024; /* * -XX:+DisableExplicitGC 显式的 */ public static void main(String[] args) throws IOException { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb); System.out.println("分配完毕..."); System.in.read(); System.out.println("开始释放..."); byteBuffer = null; System.gc(); // 显式的垃圾回收,Full GC System.in.read(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1 处:

2处,通过 unsafe 回收掉了 1Gb 内存,而不是 jvm 回收。

package cn.itcast.jvm.t1.direct; import sun.misc.Unsafe; import java.io.IOException; import java.lang.reflect.Field; /** * 直接内存分配的底层原理:Unsafe */ public class Demo1_27 { static int _1Gb = 1024 * 1024 * 1024; public static void main(String[] args) throws IOException { Unsafe unsafe = getUnsafe(); // 分配内存 long base = unsafe.allocateMemory(_1Gb); unsafe.setMemory(base, _1Gb, (byte) 0); System.in.read(); // 释放内存 unsafe.freeMemory(base); System.in.read(); } public static Unsafe getUnsafe() { try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); Unsafe unsafe = (Unsafe) f.get(null); return unsafe; } catch (NoSuchFieldException | IllegalAccessException e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.5.7.2 分配和回收原理
- 使用了Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法
- ByteBuffer的实现类内部,使用了Cleaner (虚引用)来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler 线程通过 Cleaner 的 clean方法调用 freeMemory 来释放直接内存
3. 垃圾回收
3.1 如何判断对象可以回收
3.1.1 引用计数法
缺点:当循环引用的时候。

3.1.2 可达性分析算法
- Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象
- 扫描堆中的对象,看是否能够沿着 GC Root 对象为起点的引用链找到该对象,找不到,表示可以回收。
- 哪些对象可以作为GC Root ?
3.1.2.1 MAT 工具
3.1.2.2 案例
package cn.itcast.jvm.t2; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * 演示GC Roots */ public class Demo2_2 { public static void main(String[] args) throws InterruptedException, IOException { List<Object> list1 = new ArrayList<>(); list1.add("a"); list1.add("b"); System.out.println(1); // 1 System.in.read(); list1 = null; System.out.println(2); // 2 System.in.read(); System.out.println("end..."); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
1处:


2处:

将以上两个 bin 文件导入到 MAT 工具
1.bin 文件



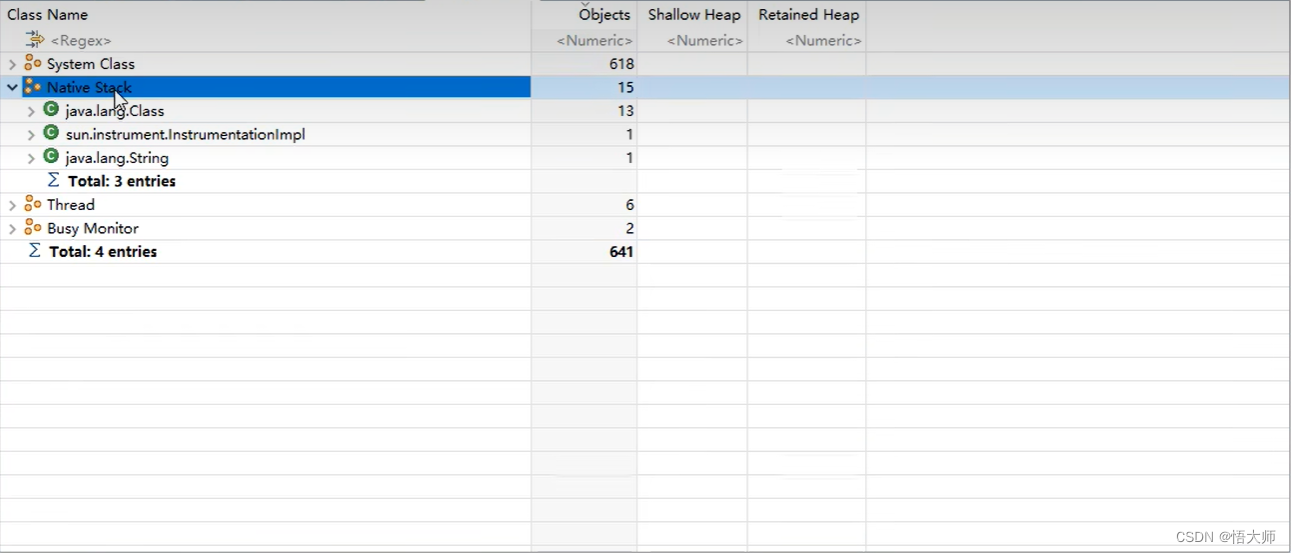

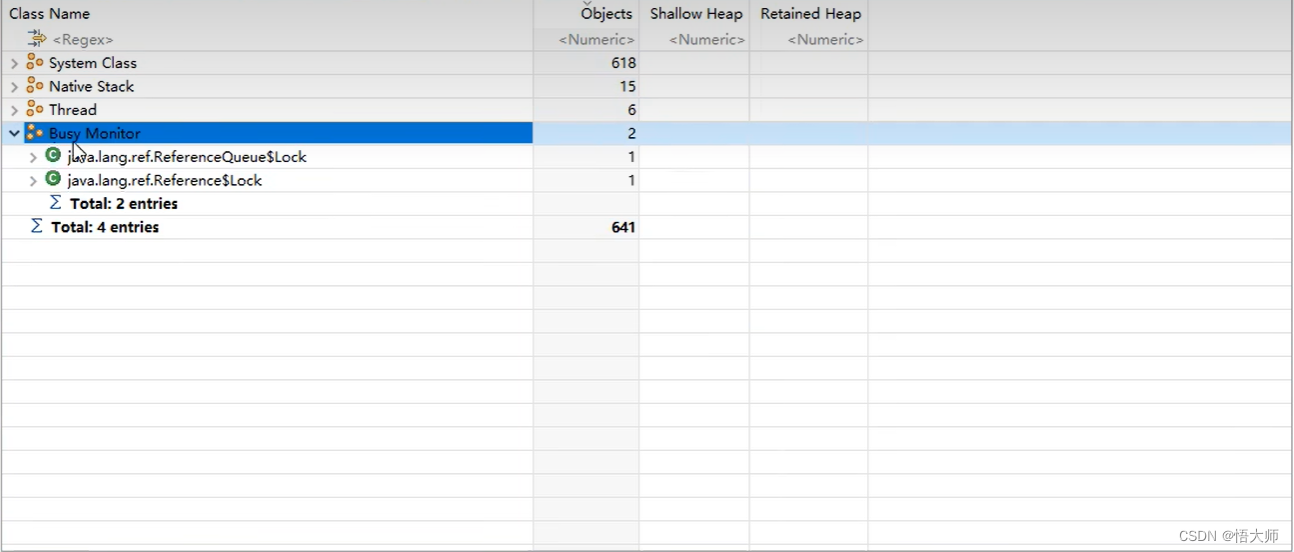
2.bin 文件

3.1.2.3 四种引用
- 强引用
- 只有所有 GC Roots 对象都不通过【强引用】引用该对象,该对象才能被垃圾回收
- 软引用
- 仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次出发垃圾回收,回收软引用对象
- 可以配合引用队列来释放软引用自身
- 弱引用
- 仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象
- 可以配合引用队列来释放弱引用自身
- 虚引用
- 必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队,由 Reference Handler 线程调用虚引用相关方法释放直接内存
- 终结器引用
- 无需手动编码,但其内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize 方法,第二次 GC 时才能回收被引用对象
3.1.2.3.1 例子解释四种引用
以下的情况是,A1 对象、A2 对象、A3 对象等所有对象都被 B 对象强引用,并且 A1 还被 C对象 强引用。
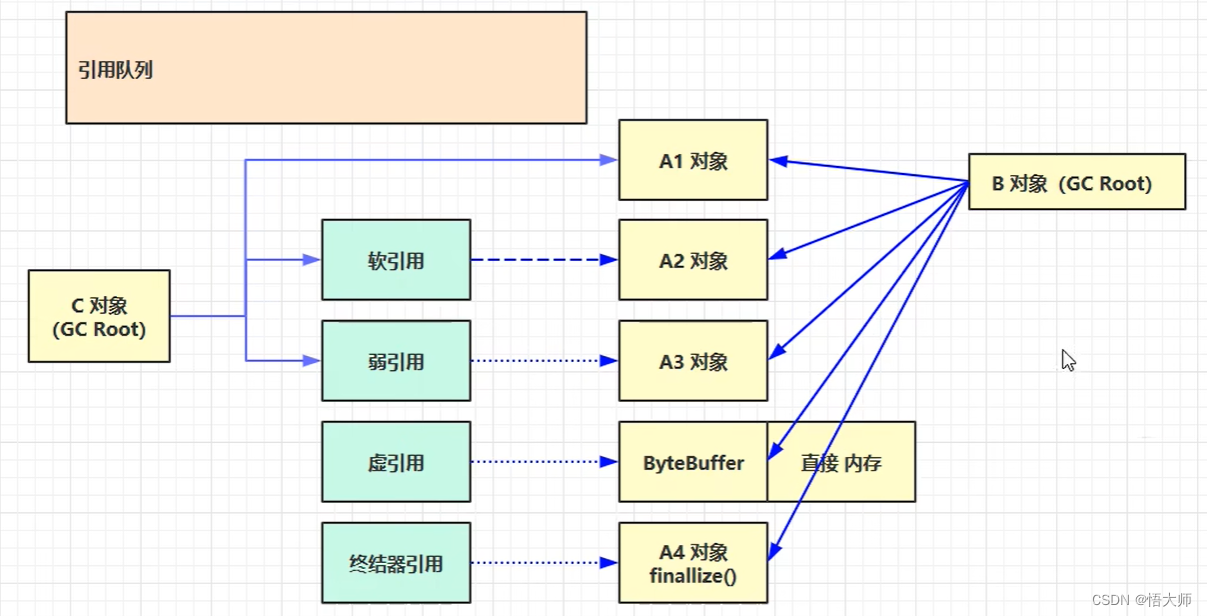
当以下情况,就可以将 A1 对象 回收。

当以下情况,只要满足 发生了一次垃圾回收,并且现在的内存不够 的情况,A2 对象(软引用对象)就可以被回收。
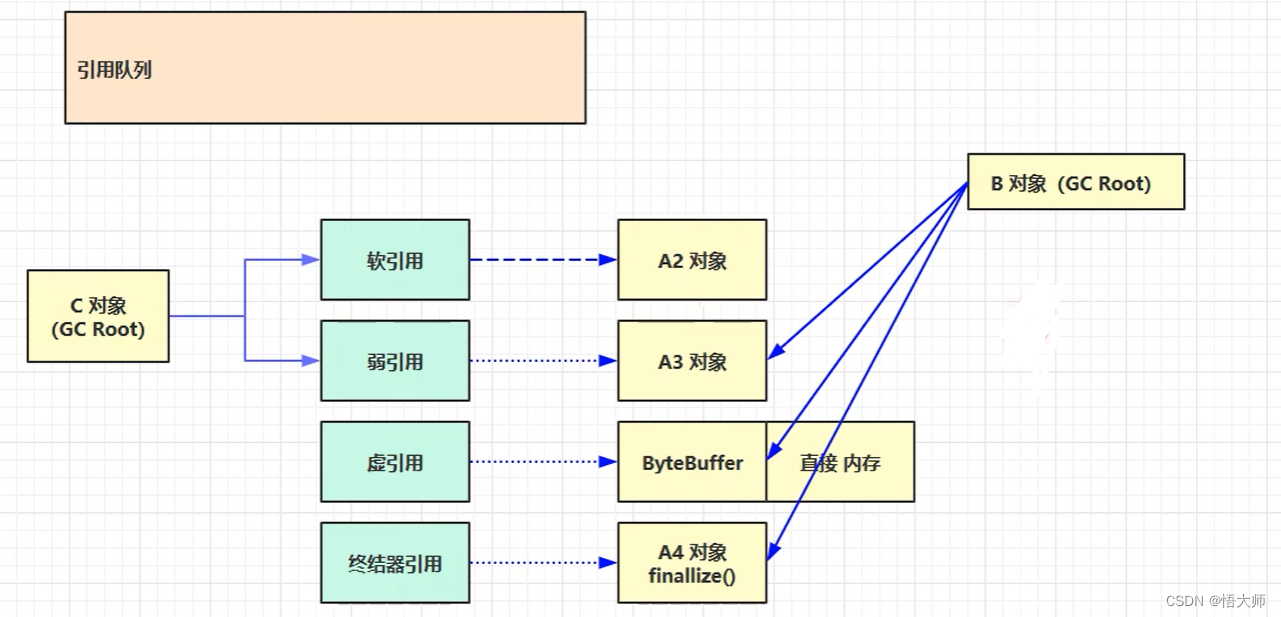
当以下情况,只要满足 发生了一次垃圾回收 的情况,A3 对象(弱引用对象)就可以被回收。

对于 软/弱引用 它们自身也会占用一定的内存,所以会有一个引用队列的操作,如果 软/弱引用 指向的对象被回收了,它们自己就会被放进引用队列,如果需要将这些空间垃圾回收,就需要从引用队列中找到响应的空间回收。


对于后面的两个 虚引用 和 终结器引用 都需要配合引用队列使用。当 虚/终结器引用 创建的时候,回关联一个引用队列中的对象

在创建 虚引用对象 的时候,
ByteBuffer会分配一个直接内存,并且把直接内存地址传递给虚引用 Cleaner对象,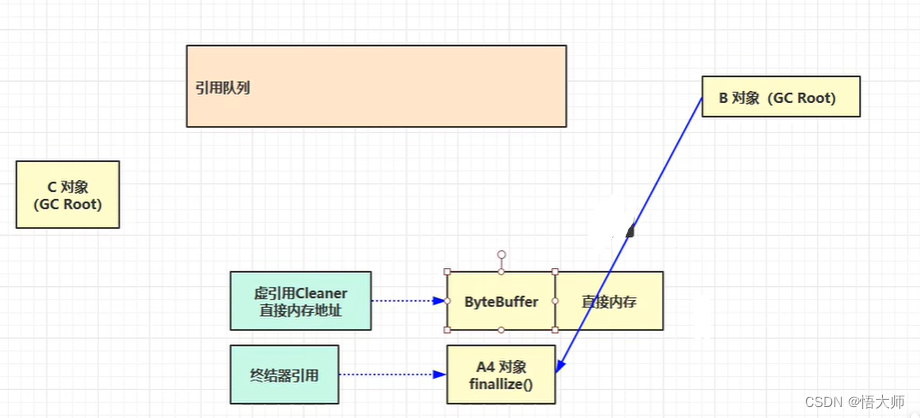
当没有强引用引用
ByteBuffer的时候,其可能会被垃圾回收掉。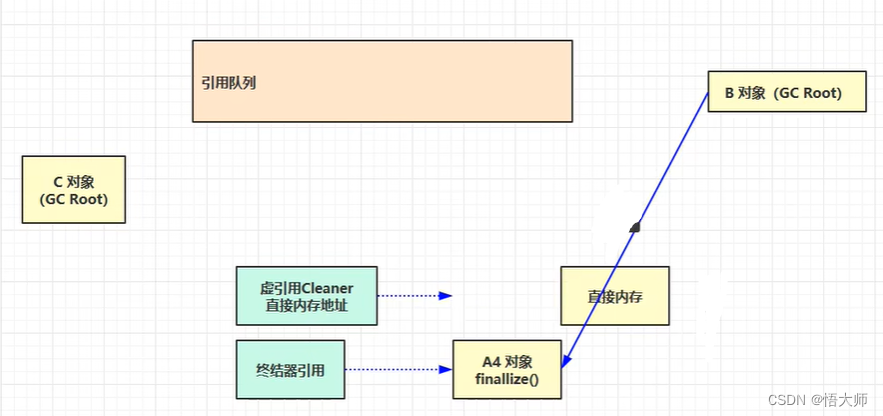
但是,只把
ByteBuffer回收不够,还需要把直接内存给回收。这时候可以把虚引用 Cleaner放到引用队列中。
并且会有一个
referencehandler定时的查找有没有cleaner,如果有就调用Cleaner中的Clean方法,比如Usafe.freeMemory()将其释放掉。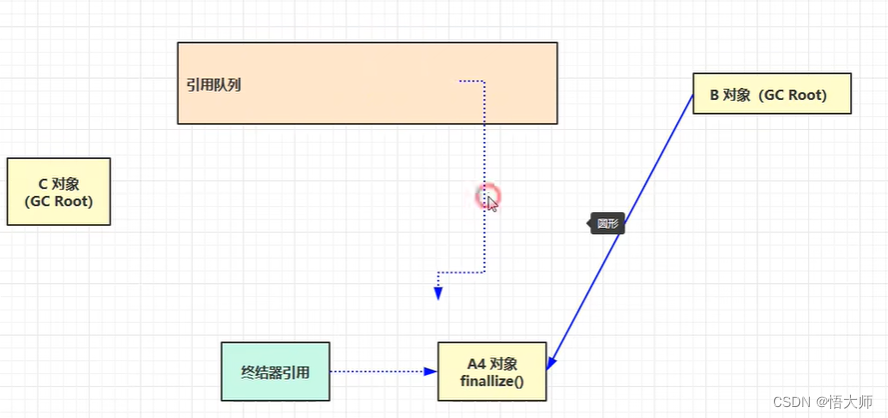
当没有强引用引用这个对象时,虚拟机会帮我们创建终结器引用。

当 A4 对象被垃圾回收时,把对应的 终结器引用 加入队列。

在用一个 优先级很低的
finalizehandler线程,去查看引用队列查看是否有终结器引用,如果有,则根据其找到 A4 对象,并把占用的内存都清空。
3.1.2.3.2 代码解释 软/弱引用
待补充
3.2 回收算法
3.2.1 标记清除(
Mark Sweep)对于内存中的空间,若存在没有
GC Root指向的内存区域,就可以选择标记。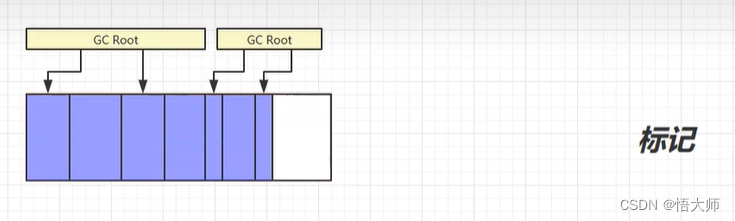
标记以后,就可以进行清除操作,清除操作后的图如下。

注意这边的 清除操作 并不是将
内存空间中所有的内容清零 ,只需要将 内存 起始地址 和 结束地址 记录下来,存储到一个空闲基础列表里就可以了。对于这种
标记/清除的操作的优点是:操作方便,速度较快,缺点是:会产生内存碎片。
3.2.2 标记整理(
Mark Compact)这个方法在 标记 的这一步,和
3.2.1 标记清除中的一样 。
区别在第二步整理部分,在原来的基础上,将内存空间进行整理
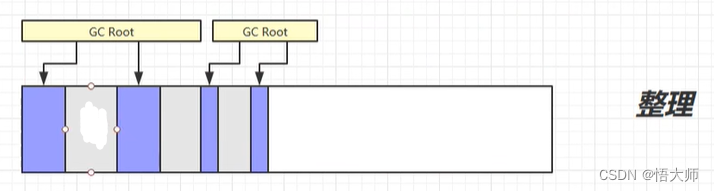


优点是没有内存碎片,缺点是运行速度较慢。
3.2.3 复制(Copy)

复制算法比较特殊,把内存区划分成大小相同的两块区域。

并且把没有
GC Root引用的标记为垃圾,并且删除。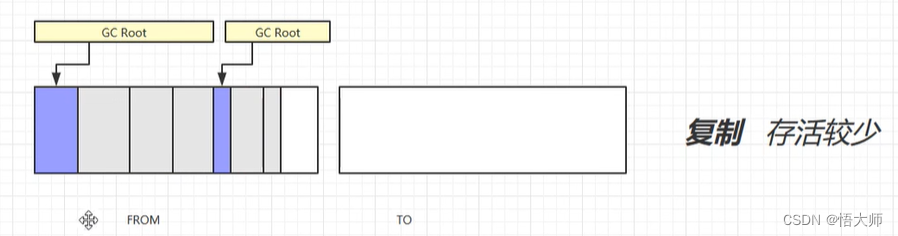
然后将 FROM 区中的内容复制到 TO 区中。

优点:不会产生碎片
缺点:会占用双倍的内存空间
3.2.4 分代垃圾回收算法
在分代垃圾回收算法中,把那些需要长时间使用的对象存储在老年代当中,那些用完就可以丢弃的对象存储在新生代当中。
对象首先分配在伊甸园区域。

当新生代伊甸园空间不足时,就会触发垃圾回收,一般我们把新生代的垃圾回收叫做
Minor GC。Minor GC会引发stop the world,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行。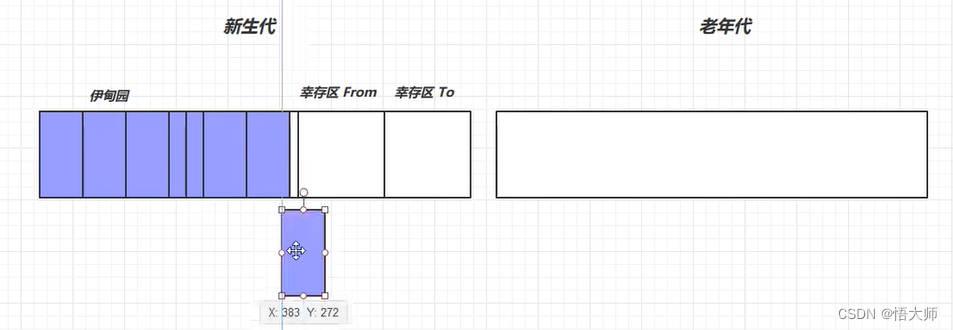
将 伊甸园 中的存活的对象复制到 幸存区to 中。
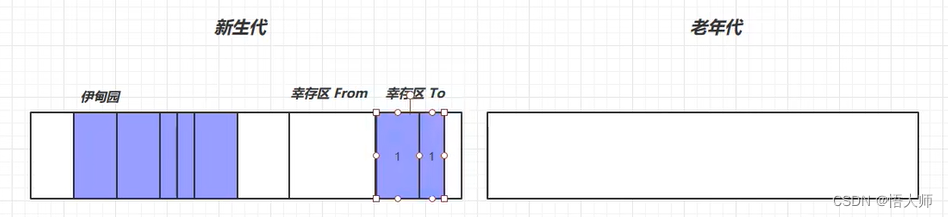
这时,会把幸存的对象的年龄 + 1 +1 +1 ,删除新生代伊甸园中的内容,并且交换 幸存区
from和 幸存区to。
这时,又可以把对象放入到新生代伊甸园中了。
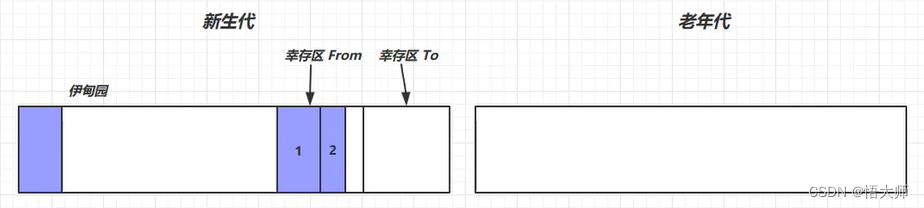
当对象寿命超过阈值时,会晋升至老年代,最大寿命是
15(4bit)

当老年代空间不足,会先尝试触发
minor gc,如果之后空间仍不足,那么触发full gc,STW的时间更长。
3.2.4.1 相关 VM 参数
含义 参数 堆初始大小 -Xms堆最大大小 -Xmx或-XX:MaxHeapSize=size新生代大小 -Xmn或(-XX:NewSize=size+-XX:MaxNewSize=size)幸存区比例(动态) -XX:InitialSurvivorRatio=ratio和-XX:+UseAdaptiveSizePolicy幸存区比例 -XX:SurvivorRatio=ratio晋升阈值 -XX:MaxTenuringThreshold=threshold晋升详情 -XX:+PrintTenuringDistributionGC详情-XX:+PrintGCDetails-verbose:gcFullGC前MinorGC-XX:+ScavengeBeforeFullGc代码例子待补充
3.3 垃圾回收器
3.3.1 串行
- 单线程
- 堆内存较小,适合个人电脑
例子:
-XX:+UseSerialGC = Serial + SerialOld- 1
- 在这一个 VM 参数中,采用了复制的算法。
- 并且
SerialOld属于老年代,采用 标记整理算法 。 - 要注意 新生代 和 老年代 属于两个垃圾回收器,分别运行。

若要进行垃圾回收,就在 四核CPU 运行到某一个安全点的时候,将其阻塞,然后进行单个线程的垃圾回收。
3.3.2 吞吐量优先
- 多线程
- 堆内存较大,多核
cpu - 让单位时间内,
STW的时间最短 (0.2 0.2 = 0.4)
-XX:+UseParallelGC ~ -XX:+UseParallelOldGC -XX:+UseAdaptiveSizePolicy // 采用自适应的大小调整策略 -XX:GCTimeRatio=ratio // 调整垃圾回收的时间和总时间的一个占比 1/(1+ratio) -XX:MaxGCPauseMillis=ms // 最大暂停毫秒数 默认为 200ms -XX:ParallelGCThreads=n // 线程数- 1
- 2
- 3
- 4
- 5

3.3.3 响应时间优先
- 多线程
- 堆内存较大,多核
cpu - 尽可能让
STW的时间最短 (0.1 0.1 0.1 0.1 0.1 = 0.5)
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld -XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads // 并发时的 GC 线程数 -XX:CMSInitiatingOccupancyFranction=percent // 预留一些空间给浮动垃圾 -XX:+CMSScavengeBeforeRemark //- 1
- 2
- 3
- 4

3.3.4 G1
定义
Garbage First- 2004 论文发布
- 2009 JDK 6u14 体验
- 2012 JDK 7u4 官方支持
- 2017 JDK 9 默认
适用场景:
- 同时注重吞吐量(
Throughput)和低延迟(Low latency),默认的暂停目标是200ms - 超大堆内存,会将堆划分为多个小大相等的
Region, - 整体上是
标记+整理算法,两个区域之间是复制算法。
相关
JVM参数-XX:+UseG1GC -XX:G1HeapRegionSize=size -XX:MaxGCPauseMillis=time- 1
- 2
- 3
3.3.4.1
G1垃圾回收阶段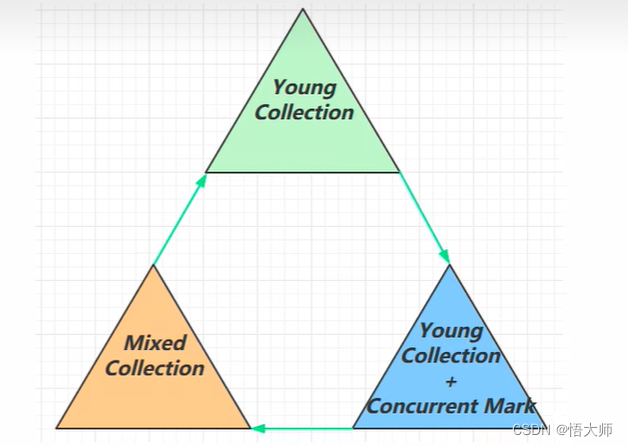
3.3.4.2 Young Collection
会 STW

-
相关阅读:
信创环境下分布式文件存储MinIO集群部署
【软件测试】03 -- 软件测试概述
DubboDemo(直连)测试代码
(01)ORB-SLAM2源码无死角解析-(19) 重投影误差,卡方检验→CheckFundamental,CheckHomography
牛掰的dd命令,cpi0配合find备份(不会主动备份),od查看
Unity丨自动巡航丨自动寻路丨NPC丨
net-java-php-python-网络在线考试系统计算机毕业设计程序
java毕业生设计新型冠状病毒防控咨询网站2020计算机源码+系统+mysql+调试部署+lw
python+nodejs+vue医院信息管理系统
动态链接库与可执行文件
- 原文地址:https://blog.csdn.net/qq_46371399/article/details/127975870