-
数据存储策略——lsm-tree
一、背景
由于传统机械磁盘的原理,它在读写时有个寻道的操作,在读写时都需要消耗一个寻道时间。

这就造成了顺序读写的速度远远快于随机读写的速度。这之间存在几个数量级的差距。
二、lsm-tree简介
LSM-tree起源于 1996 年的一篇论文《The Log-Structured Merge-Tree (LSM-Tree)》,今天的内容和图片主要来源于 FAST’16 的《WiscKey: Separating Keys from Values in SSD-conscious Storage》。
LSM-tree 是专门为 key-value 存储系统设计的,key-value 类型的存储系统最主要的就两个个功能,put(k,v):写入一个(k,v),get(k):给定一个 k 查找 v。
三、lsm-tree设计思想
之前我们说过,在传统磁盘上,顺序读写的性能要远高于随机读写。而这也是lsm-tree的设计出发点。
它通过一种方法,将对数据的写操作变为顺序写操作,以此来优化数据写性能。
而后台的压缩进程将数据不断压缩成有序结构,使得顺序读成为可能。
四、lsm-tree原理
1.写操作
当进行写操作时,先将该写操作以日志的形式追加写到文件中,这样就是以顺序写的形式写数据。
同时将其加入内存中的有序表结构当中。(作为kv数据库,内存中势必会有那种排序表结构用于快速查找)
2.读操作
先找内存,看内存中是否有,如果没有,那么就去持久化的文件中依次查找,因为每个文件的kv对是有序的,所以我们可以利用一些算法(比如二分)来加快查找速度。
又因为持久化的文件可能有多个,所以在极端情况下,lsm-tree需要读取多个文件才可能查找到对应的kv对。
3.有序表持久化
尽管lsm-tree写操作已经是顺序写,但是其有个弊端,那就是磁盘中的数据存储并不是有序的。
PS:仔细想想如果磁盘中的数据不是有序的那会有什么问题?当我们需要按顺序遍历时,对于非有序存储的磁盘数据,那么会造成多次的随机读,这对于传统磁盘而言是不可接受。
为了保证有序,真正的磁盘数据持久化应该是根据内存中有序表来持久化的,这样之前写的日志文件作用只是保证数据写入操作不会因为宕机等原因而丢失。
而这种持久化往往是周期性触发,比如内存中有序表kv键值对达到一定数量或者到达一定时间,会触发数据持久化。
可以这么理解,每隔一段时间,操作系统中的文件系统就会多一个存储有序数据的文件,每个文件都是一个小型的有序表。
4.后台压缩
文件多了怎么办,之前说了经过lsm-tree的处理,数据持久化为多个小文件,而对于数据的查找往往需要遍历多个小文件。
这样查找效率可就低了,为了加快查找效率,也为了减少文件描述符(因为这是有限的),lsm-tree需要在后台进行压缩。主要目的就是将多个小文件进行合并,合并成大文件。
五、lsm-tree的应用
lsm-tree在工业界应用十分广泛,比如leveldb,rocketdb等等。因为随机写优化成了顺序写,所以性能非常可观。
六、lsm-tree优缺点分析
我们仔细回顾下lsm-tree到底做了什么来使性能提升的。
其实一句话就是将随机写改为顺序写,不管是日志持久化,还是有序表持久化,亦或者是后台压缩,其写操作皆是顺序写。但是我们仔细思考下,它所做的事情真的减少了吗?
其实不然,非但没有减少,实际的写入的数据还有增加。
不考虑后台压缩操作,光日志持久化和有序表持久化就将数据写放大到两倍。更别提还有极度消耗资源的后台压缩操作。而它能提升性能的原因仅仅是顺序写和随机写操作在传统磁盘上的性能差距实在太大了,大到即使是多了这些额外的操作,lsm-tree所带来的性能收益也要大于其消耗。
但是这个前提正在被逐渐打破,注意到我之前的用词了吗?
传统磁盘!
在传统磁盘中,这种优化是没有任何毛病的,但已渐渐成为主流的SSD正在将这种前提打破!
尽管SSD的顺序写操作性能依旧要比随机写要好,但是其性能差距并没有像传统磁盘那么大。
在2019年SOSP上有一篇论文——KVell: the Design and Implementation of a Fast Persistent Key-Value Store中,就提到了现代硬盘SSD针对lsm-tree的一些问题。
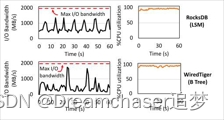
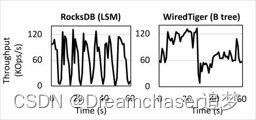
在这篇论文中提到了lsm-tree在现代磁盘上的两个问题,一个是CPU成为瓶颈,另一个是性能波动问题。
在lsm-tree中,之前提到的后台压缩操作实际上是个CPU大户,我们经常可以看到请求量不多,但是CPU耗费拉满的情况。
这是因为随着技术的发展,SSD无论是带宽还是性能都已有了巨大的提升。在论文中提到一个明显现象就是,LSM-tree始终无法利用整个设备的I/O带宽,而CPU往往处于高负荷运转的状态。
同时,后台压缩操作在请求量大的情况下势必影响客户端的吞吐量,因为有时更新需要等待压缩完成,从而导致LSM-tree性能的波动。
总结
lsm-tree是一个以优化写操作的存储策略,核心思路就是顺序写替换随机写。
lsm-tree在传统磁盘上的读写性能表现非常出色,在工业界非常流行,比如腾讯tendis和360的pika底层用的Rocksdb就是采用lsm-tree来实现的。但是随着时代的发展,SSD性能的提升和读写方式的变化,使得lsm-tree渐渐暴露出一些问题,也让我们不禁去探寻一种更为高效的存储方式。
-
相关阅读:
增益与功率:lg|dB|dBm|mW计算
学会安装Redis数据库到服务器或计算机(Windows版)
C++阶段05笔记06【C++提高编程资料(常用遍历算法、常用查找算法、常用排序算法、常用拷贝和替换算法、常用算术生成算法、常用集合算法)】
华为云低代码技术:让矿区管理“智变”,一览无遗
Azure Devops Create Project TF400711问题分析解决
Nacos 安装与部署
DAQ高频量化平台:引领Ai高频量化交易模式变革
sqlserver 常用日期操作
智慧法院档案数字化解决方案
第二证券|比特币重拾升势 新高背后风险涌动
- 原文地址:https://blog.csdn.net/qq_46101869/article/details/127965956