-
【图像分割】2021-Swin-Unet CVPR
【图像分割】2021-Swin-Unet CVPR
论文题目:Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
论文链接:https://arxiv.org/abs/2105.05537
论文代码:https://github.com/HuCaoFighting/Swin-Unet
发表时间:2021年5月
引用:Cao H, Wang Y, Chen J, et al. Swin-unet: Unet-like pure transformer for medical image segmentation[J]. arXiv preprint arXiv:2105.05537, 2021.
引用数:336
1. 简介
1.1 问题
得益于深度学习的发展,计算机视觉技术在医学图像分析中得到了广泛的应用。图像分割是医学图像分析的重要组成部分。特别是准确、鲁棒的医学图像分割可以在计算机辅助诊断和图像引导的临床手术中发挥基石作用。
现有的医学图像分割方法主要依赖u型结构的全卷积神经网(FCNN)。典型的u型网络,U-Net,由一个具有跳跃连接的对称编码器-解码器组成。在编码器中,采用一系列卷积层和连续降采样层来提取接收感受野的深度特征。
然后,解码器将提取的深度特征向上采样到输入分辨率进行像素级语义预测,并通过跳跃连接融合来自编码器的不同尺度的高分辨率特征,以减轻降采样导致的空间信息丢失。由于这种优雅的结构设计,U-Net在各种医学成像应用中取得了巨大的成功。遵循这一技术路线,许多算法如3D U-Ne、Res-UNet、U-Net++和UNet3+被开发出来用于各种医学成像模式的图像和体积分割。这些基于fcnn的方法在心脏分割、器官分割和病变分割方面的优异性能证明了CNN具有很强的学习判别特征的能力。
1.2 思路来源
目前,虽然基于CNN的方法在医学图像分割领域取得了优异的性能,但仍不能完全满足医学应用对分割精度的严格要求。在医学图像分析中,图像分割仍然是一个具有挑战性的课题。由于卷积运算固有的局限性,基于CNN的方法很难学习显式的全局和长期语义信息交互。一些研究试图通过使用深度卷积层、自我注意机制和图像金字塔来解决这个问题。然而,这些方法在建模长期依赖时仍然有局限性。然而受Transformer在自然语言处理(NLP)领域的巨大成功的启发,研究人员试图将Transformer引入视觉领域。
在ViT被提出来执行图像识别任务。以具有位置嵌入的二维图像块为输入,在大数据集上进行预处理,与基于CNN的方法取得了相当的性能。此外,Dei中还提出了数据高效的图像变换,这表明transformer可以在中等规模的数据集上进行训练,并将其与蒸馏方法相结合,可以得到更鲁棒的transformer。在Swin transformer中,作者开发了一个分层的Swin transformer。作者以Swin Transformer为视觉中枢,在图像分类、目标检测和语义分割方面取得了最先进的性能。ViT、DeiT和Swin transformer在图像识别领域的成功证明了transformer在视觉领域的应用潜力。
在Swin Transformer成功的激励下,作者提出Swin- unet来利用Transformer实现2D医学图像分割。swin-unet是第一个纯粹的基于transformer的u型架构,它由编码器、瓶颈、解码器和跳跃连接组成。编码器、瓶颈和解码器都是基于Swin-transformer block构建的。将输入的医学图像分割成不重叠的图像patch。每个patch都被视为一个token,并被输入到基于transformer的编码器中,以学习深度特征表示。提取的上下文特征由带补丁扩展层的解码器上采样,通过跳跃连接与编码器的多尺度特征融合,恢复特征图的空间分辨率,进一步进行分割预测。在多器官和心脏数据集上的大量实验表明,该方法具有良好的分割精度和鲁棒泛化能力。1.3 贡献
具体来说,作者的贡献可以总结为:
- 基于Swin Transformer block,构建了一个具有跳跃连接的对称编码器-解码器体系结构。在编码器中实现了从局部到全局的自注意;在解码器中,将全局特征上采样到输入分辨率,进行相应的像素级分割预测。
- 开发了patch扩展层,无需卷积或插值操作即可实现上采样和特征维数的增加。
- 实验发现跳跃连接对transformer也是有效的,因此最终构建了一个纯基于transformer的u型编解码结构,具有跳跃连接,命名为swin-unet。
2. 网络
2.1 整体架构图
所提出的swin-unet的整体架构如图所示。
swin - unet由编码器、瓶颈、解码器和跳过连接组成。
swin - unet的基本单元是Swin transformer块。
-
对于编码器,为了将输入转换为序列嵌入,将医学图像分割成大小为4 × 4的非重叠patch。通过这种划分方法,每个patch的特征维数变为4×4×3=48。此外,将投影的特征维度应用线性嵌入层(以C表示),
转换后的patch标记经过几个Swin Transformer块和Patch Merging生成分层特征表示。
其中,Patch Merging负责下采样和增加维度,Swin Transformer块负责特征表示学习,受U-Net的启发,设计了一种基于对称transformer的解码器。
-
该解码器由
Swin transformer块和Patch Expanding组成。提取的上下文特征通过跳跃连接与编码器的多尺度特征融合,以弥补降采样造成的空间信息丢失。与Patch Merging不同,Patch Expanding被专门设计用于执行上采样。Patch Expanding通过2×上采样分辨率将相邻维度的特征地图重塑为一个大的特征地图。最后,利用最后一个Patch Expanding进行4×上采样,将特征映射的分辨率恢复到输入分辨率(W ×H),然后在这些上采样特征上应用线性投影层输出像素级分割预测。

2.2 Swin Transformer block

与传统的多头自注意(MSA)模块不同,swin transformer块是基于平移窗口构造的。在图2中,给出了两个连续的swin transformer块。每个swin transformer块由LayerNorm (LN)层、多头自注意模块、剩余连接和具有GELU非线性的2层MLP组成。在两个连续的transformer模块中分别采用了基于窗口的多头自注意(W-MSA)模块和位移的基于窗口的多头自注意(SW-MSA)模块。基于这种窗口划分机制,连续swin transformer块可表示为:
z ^ l = W − M S A ( L N ( z l − 1 ) ) + z l − 1 z l = M L P ( L N ( z ^ l ) ) + z ^ l z ^ l + 1 = S W − M S A ( L N ( z l ) ) + z l z l + 1 = M L P ( L N ( z ^ l + 1 ) ) + z ^ l + 1
z^l=W−MSA(LN(zl−1))+zl−1zl=MLP(LN(z^l))+z^lz^l+1=SW−MSA(LN(zl))+zlzl+1=MLP(LN(z^l+1))+z^l+1z ^ l = W − M S A ( L N ( z l − 1 ) ) + z l − 1 z l = M L P ( L N ( z ^ l ) ) + z ^ l z ^ l + 1 = S W − M S A ( L N ( z l ) ) + z l z l + 1 = M L P ( L N ( z ^ l + 1 ) ) + z ^ l + 1
自注意的计算方法:
Attention ( Q , K , V ) = SoftMax ( Q K T d + B ) V \operatorname{Attention}(Q, K, V)=\operatorname{SoftMax}\left(\frac{Q K^{T}}{\sqrt{d}}+B\right) V Attention(Q,K,V)=SoftMax(dQKT+B)V2.3 编解码器细节
- 在编码器中,将分辨率为H/4×W/4的c维标记化输入输入到连续的两个Swin Transformer块中进行表示学习,特征维度和分辨率保持不变。同时,patch 合并层会减少token的数量(2× down sampling),将特征维数增加到2×原始维数。此过程将在编码器中重复三次。
- patch合并层:
输入补丁被分为四部分,通过补丁合并层连接在一起。这样的处理会使特征分辨率下降2倍。并且,由于拼接操作的结果是特征维数增加了4倍,因此在拼接的特征上加一个线性层,将特征维数统一为原始维数的2倍 - Bottleneck:
由于Transformer太深,无法收敛,因此只使用连续两个Swin Transformer块构造瓶颈来学习深度特征表示。在瓶颈处,特征维度和分辨率保持不变。 - 解码器:
与编码器相对应的是基于Swin transformer模块的对称解码器。为此,与编码器中使用的patch 合并层不同,在解码器中使用patch扩展层对提取的深度特征进行上采样。patch 扩展层将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数减半 - patch扩展层:
以第一个patch扩展层为例,在上采样之前,在输入特征上加一个线性层(W/32×H/32×8C),将特征维数增加到原始维数的2倍(W/32×H/32×16C)。然后,利用重排操作将输入特征的分辨率扩展为输入分辨率的2倍,将特征维数降低为输入维数的1/4 (W/32×H/32×16C→W/16×H/16×4C)。
2.4 实验
1) 整体实验
Synapse多器官分割数据集(Synapse):包括30例3779张腹部轴向临床CT图像。
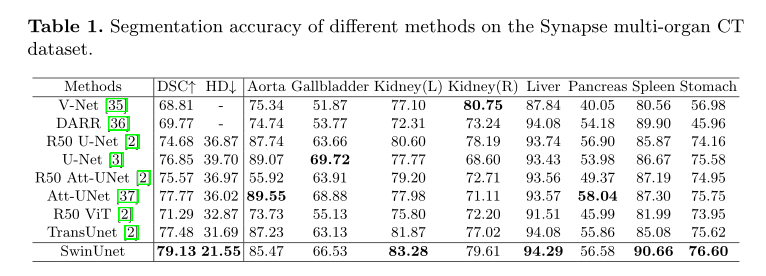
ACDC数据集上不同方法的分割精度
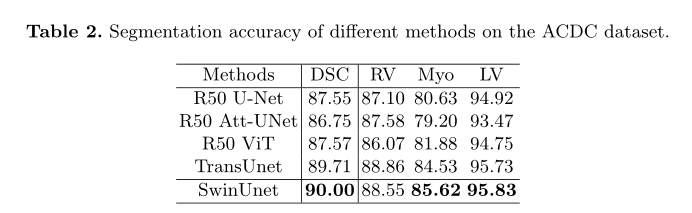
2) 消融实验
为了探讨不同因素对模型性能的影响,在Synapse数据集上进行了消融研究。具体来说,下面讨论了上采样、跳跃连接的数量、输入尺寸和模型尺度。
上采样的影响:
针对编码器中的patch 合并层,作者在解码器中专门设计了patch 扩展层,用于上采样和特征维数增加。为了探索所提出的补丁扩展层的有效性,在Synapse数据集上进行了双线性插值、转置卷积和补丁扩展层的Swin-Unet实验。下表中的实验结果表明,本文提出的Swin-Unet结合patch 扩展层可以获得更好的分割精度。

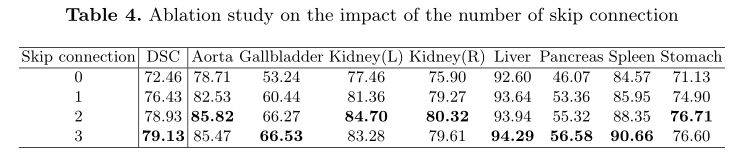
跳跃连接数目的影响:
Swin-UNet的跳跃连接被添加在1/4、1/8和1/16分辨率尺度的地方。通过将跳跃连接数分别更改为0、1、2和3,探讨了不同跳跃连接对模型分割性能的影响。从表4中可以看出,模型的分段性能随着跳过连接数的增加而提高。因此,为了使模型更加鲁棒,本工作中设置跳跃连接数为3。
输入大小的影响:
Swin-Unet在224 × 224、384 × 384输入分辨率下的测试结果如表5所示。随着输入尺寸从224 × 224增加到384 × 384,且patch尺寸保持4不变,Transformer的输入token序列会变大,从而提高模型的分割性能。然而,虽然模型的分割精度略有提高,但整个网络的计算负荷也有了显著增加。为了保证算法的运行效率,本文的实验以224 × 224的分辨率尺度作为输入。

模型大小的影响:
讨论了网络深化对模型绩效的影响。从表6可以看出,模型规模的增加并没有提高模型的性能,反而增加了整个网络的计算代价。考虑到精度和速度的权衡,采用基于tiny的模型进行医学图像分割。

3. 代码
import torch import torch.nn as nn import torch.utils.checkpoint as checkpoint from einops import rearrange from timm.models.layers import DropPath, to_2tuple, trunc_normal_ import copy from easydict import EasyDict class Mlp(nn.Module): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x def window_partition(x, window_size): """ Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) """ B, H, W, C = x.shape x = x.view(B, H // window_size, window_size, W // window_size, window_size, C) windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) return windows def window_reverse(windows, window_size, H, W): """ Args: windows: (num_windows*B, window_size, window_size, C) window_size (int): Window size H (int): Height of image W (int): Width of image Returns: x: (B, H, W, C) """ B = int(windows.shape[0] / (H * W / window_size / window_size)) x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1) x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1) return x class WindowAttention(nn.Module): r""" Window based multi-head self attention (W-MSA) module with relative position bias. It supports both of shifted and non-shifted window. Args: dim (int): Number of input channels. window_size (tuple[int]): The height and width of the window. num_heads (int): Number of attention heads. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0 proj_drop (float, optional): Dropout ratio of output. Default: 0.0 """ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.dim = dim self.window_size = window_size # Wh, Ww self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 # define a parameter table of relative position bias self.relative_position_bias_table = nn.Parameter( torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH # get pair-wise relative position index for each token inside the window coords_h = torch.arange(self.window_size[0]) coords_w = torch.arange(self.window_size[1]) coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2 relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0 relative_coords[:, :, 1] += self.window_size[1] - 1 relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww self.register_buffer("relative_position_index", relative_position_index) self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) trunc_normal_(self.relative_position_bias_table, std=.02) self.softmax = nn.Softmax(dim=-1) def forward(self, x, mask=None): """ Args: x: input features with shape of (num_windows*B, N, C) mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None """ B_, N, C = x.shape qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) q = q * self.scale attn = (q @ k.transpose(-2, -1)) relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view( self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww attn = attn + relative_position_bias.unsqueeze(0) if mask is not None: nW = mask.shape[0] attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0) attn = attn.view(-1, self.num_heads, N, N) attn = self.softmax(attn) else: attn = self.softmax(attn) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B_, N, C) x = self.proj(x) x = self.proj_drop(x) return x def extra_repr(self) -> str: return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}' def flops(self, N): # calculate flops for 1 window with token length of N flops = 0 # qkv = self.qkv(x) flops += N * self.dim * 3 * self.dim # attn = (q @ k.transpose(-2, -1)) flops += self.num_heads * N * (self.dim // self.num_heads) * N # x = (attn @ v) flops += self.num_heads * N * N * (self.dim // self.num_heads) # x = self.proj(x) flops += N * self.dim * self.dim return flops class SwinTransformerBlock(nn.Module): r""" Swin Transformer Block. Args: dim (int): Number of input channels. input_resolution (tuple[int]): Input resulotion. num_heads (int): Number of attention heads. window_size (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set. drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float, optional): Stochastic depth rate. Default: 0.0 act_layer (nn.Module, optional): Activation layer. Default: nn.GELU norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm): super().__init__() self.dim = dim self.input_resolution = input_resolution self.num_heads = num_heads self.window_size = window_size self.shift_size = shift_size self.mlp_ratio = mlp_ratio if min(self.input_resolution) <= self.window_size: # if window size is larger than input resolution, we don't partition windows self.shift_size = 0 self.window_size = min(self.input_resolution) assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size" self.norm1 = norm_layer(dim) self.attn = WindowAttention( dim, window_size=to_2tuple(self.window_size), num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop) self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) if self.shift_size > 0: # calculate attention mask for SW-MSA H, W = self.input_resolution img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1 h_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) w_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) cnt = 0 for h in h_slices: for w in w_slices: img_mask[:, h, w, :] = cnt cnt += 1 mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1 mask_windows = mask_windows.view(-1, self.window_size * self.window_size) attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0)) else: attn_mask = None self.register_buffer("attn_mask", attn_mask) def forward(self, x): H, W = self.input_resolution B, L, C = x.shape assert L == H * W, "input feature has wrong size" shortcut = x x = self.norm1(x) x = x.view(B, H, W, C) # cyclic shift if self.shift_size > 0: shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) else: shifted_x = x # partition windows x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C # W-MSA/SW-MSA attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C # merge windows attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C # reverse cyclic shift if self.shift_size > 0: x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)) else: x = shifted_x x = x.view(B, H * W, C) # FFN x = shortcut + self.drop_path(x) x = x + self.drop_path(self.mlp(self.norm2(x))) return x def extra_repr(self) -> str: return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \ f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}" def flops(self): flops = 0 H, W = self.input_resolution # norm1 flops += self.dim * H * W # W-MSA/SW-MSA nW = H * W / self.window_size / self.window_size flops += nW * self.attn.flops(self.window_size * self.window_size) # mlp flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio # norm2 flops += self.dim * H * W return flops class PatchMerging(nn.Module): r""" Patch Merging Layer. Args: input_resolution (tuple[int]): Resolution of input feature. dim (int): Number of input channels. norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm): super().__init__() self.input_resolution = input_resolution self.dim = dim self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False) self.norm = norm_layer(4 * dim) def forward(self, x): """ x: B, H*W, C """ H, W = self.input_resolution B, L, C = x.shape assert L == H * W, "input feature has wrong size" assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even." x = x.view(B, H, W, C) x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C x = self.norm(x) x = self.reduction(x) return x def extra_repr(self) -> str: return f"input_resolution={self.input_resolution}, dim={self.dim}" def flops(self): H, W = self.input_resolution flops = H * W * self.dim flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim return flops class PatchExpand(nn.Module): def __init__(self, input_resolution, dim, dim_scale=2, norm_layer=nn.LayerNorm): super().__init__() self.input_resolution = input_resolution self.dim = dim self.expand = nn.Linear(dim, 2 * dim, bias=False) if dim_scale == 2 else nn.Identity() self.norm = norm_layer(dim // dim_scale) def forward(self, x): """ x: B, H*W, C """ H, W = self.input_resolution x = self.expand(x) B, L, C = x.shape assert L == H * W, "input feature has wrong size" x = x.view(B, H, W, C) x = rearrange(x, 'b h w (p1 p2 c)-> b (h p1) (w p2) c', p1=2, p2=2, c=C // 4) x = x.view(B, -1, C // 4) x = self.norm(x) return x class FinalPatchExpand_X4(nn.Module): def __init__(self, input_resolution, dim, dim_scale=4, norm_layer=nn.LayerNorm): super().__init__() self.input_resolution = input_resolution self.dim = dim self.dim_scale = dim_scale self.expand = nn.Linear(dim, 16 * dim, bias=False) self.output_dim = dim self.norm = norm_layer(self.output_dim) def forward(self, x): """ x: B, H*W, C """ H, W = self.input_resolution x = self.expand(x) B, L, C = x.shape assert L == H * W, "input feature has wrong size" x = x.view(B, H, W, C) x = rearrange(x, 'b h w (p1 p2 c)-> b (h p1) (w p2) c', p1=self.dim_scale, p2=self.dim_scale, c=C // (self.dim_scale ** 2)) x = x.view(B, -1, self.output_dim) x = self.norm(x) return x class BasicLayer(nn.Module): """ A basic Swin Transformer layer for one stage. Args: dim (int): Number of input channels. input_resolution (tuple[int]): Input resolution. depth (int): Number of blocks. num_heads (int): Number of attention heads. window_size (int): Local window size. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set. drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0 norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False. """ def __init__(self, dim, input_resolution, depth, num_heads, window_size, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False): super().__init__() self.dim = dim self.input_resolution = input_resolution self.depth = depth self.use_checkpoint = use_checkpoint # build blocks self.blocks = nn.ModuleList([ SwinTransformerBlock(dim=dim, input_resolution=input_resolution, num_heads=num_heads, window_size=window_size, shift_size=0 if (i % 2 == 0) else window_size // 2, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer) for i in range(depth)]) # patch merging layer if downsample is not None: self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer) else: self.downsample = None def forward(self, x): for blk in self.blocks: if self.use_checkpoint: x = checkpoint.checkpoint(blk, x) else: x = blk(x) if self.downsample is not None: x = self.downsample(x) return x def extra_repr(self) -> str: return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}" def flops(self): flops = 0 for blk in self.blocks: flops += blk.flops() if self.downsample is not None: flops += self.downsample.flops() return flops class BasicLayer_up(nn.Module): """ A basic Swin Transformer layer for one stage. Args: dim (int): Number of input channels. input_resolution (tuple[int]): Input resolution. depth (int): Number of blocks. num_heads (int): Number of attention heads. window_size (int): Local window size. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set. drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0 norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False. """ def __init__(self, dim, input_resolution, depth, num_heads, window_size, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0., norm_layer=nn.LayerNorm, upsample=None, use_checkpoint=False): super().__init__() self.dim = dim self.input_resolution = input_resolution self.depth = depth self.use_checkpoint = use_checkpoint # build blocks self.blocks = nn.ModuleList([ SwinTransformerBlock(dim=dim, input_resolution=input_resolution, num_heads=num_heads, window_size=window_size, shift_size=0 if (i % 2 == 0) else window_size // 2, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer) for i in range(depth)]) # patch merging layer if upsample is not None: self.upsample = PatchExpand(input_resolution, dim=dim, dim_scale=2, norm_layer=norm_layer) else: self.upsample = None def forward(self, x): for blk in self.blocks: if self.use_checkpoint: x = checkpoint.checkpoint(blk, x) else: x = blk(x) if self.upsample is not None: x = self.upsample(x) return x class PatchEmbed(nn.Module): r""" Image to Patch Embedding Args: img_size (int): Image size. Default: 224. patch_size (int): Patch token size. Default: 4. in_chans (int): Number of input image channels. Default: 3. embed_dim (int): Number of linear projection output channels. Default: 96. norm_layer (nn.Module, optional): Normalization layer. Default: None """ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None): super().__init__() img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size) patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]] self.img_size = img_size self.patch_size = patch_size self.patches_resolution = patches_resolution self.num_patches = patches_resolution[0] * patches_resolution[1] self.in_chans = in_chans self.embed_dim = embed_dim self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) if norm_layer is not None: self.norm = norm_layer(embed_dim) else: self.norm = None def forward(self, x): B, C, H, W = x.shape # FIXME look at relaxing size constraints assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C if self.norm is not None: x = self.norm(x) return x def flops(self): Ho, Wo = self.patches_resolution flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1]) if self.norm is not None: flops += Ho * Wo * self.embed_dim return flops class SwinTransformerSys(nn.Module): r""" Swin Transformer A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` - https://arxiv.org/pdf/2103.14030 Args: img_size (int | tuple(int)): Input image size. Default 224 patch_size (int | tuple(int)): Patch size. Default: 4 in_chans (int): Number of input image channels. Default: 3 num_classes (int): Number of classes for classification head. Default: 1000 embed_dim (int): Patch embedding dimension. Default: 96 depths (tuple(int)): Depth of each Swin Transformer layer. num_heads (tuple(int)): Number of attention heads in different layers. window_size (int): Window size. Default: 7 mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4 qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None drop_rate (float): Dropout rate. Default: 0 attn_drop_rate (float): Attention dropout rate. Default: 0 drop_path_rate (float): Stochastic depth rate. Default: 0.1 norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm. ape (bool): If True, add absolute position embedding to the patch embedding. Default: False patch_norm (bool): If True, add normalization after patch embedding. Default: True use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False """ def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 2, 2], depths_decoder=[1, 2, 2, 2], num_heads=[3, 6, 12, 24], window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1, norm_layer=nn.LayerNorm, ape=False, patch_norm=True, use_checkpoint=False, final_upsample="expand_first", **kwargs): super().__init__() print( "SwinTransformerSys expand initial----depths:{};depths_decoder:{};drop_path_rate:{};num_classes:{};in_channel:{}".format( depths, depths_decoder, drop_path_rate, num_classes, in_chans)) self.num_classes = num_classes self.num_layers = len(depths) self.embed_dim = embed_dim self.ape = ape self.patch_norm = patch_norm self.num_features = int(embed_dim * 2 ** (self.num_layers - 1)) self.num_features_up = int(embed_dim * 2) self.mlp_ratio = mlp_ratio self.final_upsample = final_upsample # split image into non-overlapping patches self.patch_embed = PatchEmbed( img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim, norm_layer=norm_layer if self.patch_norm else None) num_patches = self.patch_embed.num_patches patches_resolution = self.patch_embed.patches_resolution self.patches_resolution = patches_resolution # absolute position embedding if self.ape: self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim)) trunc_normal_(self.absolute_pos_embed, std=.02) self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule # build encoder and bottleneck layers self.layers = nn.ModuleList() for i_layer in range(self.num_layers): layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer), input_resolution=(patches_resolution[0] // (2 ** i_layer), patches_resolution[1] // (2 ** i_layer)), depth=depths[i_layer], num_heads=num_heads[i_layer], window_size=window_size, mlp_ratio=self.mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], norm_layer=norm_layer, downsample=PatchMerging if (i_layer < self.num_layers - 1) else None, use_checkpoint=use_checkpoint) self.layers.append(layer) # build decoder layers self.layers_up = nn.ModuleList() self.concat_back_dim = nn.ModuleList() for i_layer in range(self.num_layers): concat_linear = nn.Linear(2 * int(embed_dim * 2 ** (self.num_layers - 1 - i_layer)), int(embed_dim * 2 ** ( self.num_layers - 1 - i_layer))) if i_layer > 0 else nn.Identity() if i_layer == 0: layer_up = PatchExpand( input_resolution=(patches_resolution[0] // (2 ** (self.num_layers - 1 - i_layer)), patches_resolution[1] // (2 ** (self.num_layers - 1 - i_layer))), dim=int(embed_dim * 2 ** (self.num_layers - 1 - i_layer)), dim_scale=2, norm_layer=norm_layer) else: layer_up = BasicLayer_up(dim=int(embed_dim * 2 ** (self.num_layers - 1 - i_layer)), input_resolution=( patches_resolution[0] // (2 ** (self.num_layers - 1 - i_layer)), patches_resolution[1] // (2 ** (self.num_layers - 1 - i_layer))), depth=depths[(self.num_layers - 1 - i_layer)], num_heads=num_heads[(self.num_layers - 1 - i_layer)], window_size=window_size, mlp_ratio=self.mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[sum(depths[:(self.num_layers - 1 - i_layer)]):sum( depths[:(self.num_layers - 1 - i_layer) + 1])], norm_layer=norm_layer, upsample=PatchExpand if (i_layer < self.num_layers - 1) else None, use_checkpoint=use_checkpoint) self.layers_up.append(layer_up) self.concat_back_dim.append(concat_linear) self.norm = norm_layer(self.num_features) self.norm_up = norm_layer(self.embed_dim) if self.final_upsample == "expand_first": print("---final upsample expand_first---") self.up = FinalPatchExpand_X4(input_resolution=(img_size // patch_size, img_size // patch_size), dim_scale=4, dim=embed_dim) self.output = nn.Conv2d(in_channels=embed_dim, out_channels=self.num_classes, kernel_size=1, bias=False) self.apply(self._init_weights) def _init_weights(self, m): if isinstance(m, nn.Linear): trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.LayerNorm): nn.init.constant_(m.bias, 0) nn.init.constant_(m.weight, 1.0) @torch.jit.ignore def no_weight_decay(self): return {'absolute_pos_embed'} @torch.jit.ignore def no_weight_decay_keywords(self): return {'relative_position_bias_table'} # Encoder and Bottleneck def forward_features(self, x): x = self.patch_embed(x) if self.ape: x = x + self.absolute_pos_embed x = self.pos_drop(x) x_downsample = [] for layer in self.layers: x_downsample.append(x) x = layer(x) x = self.norm(x) # B L C return x, x_downsample # Dencoder and Skip connection def forward_up_features(self, x, x_downsample): for inx, layer_up in enumerate(self.layers_up): if inx == 0: x = layer_up(x) else: x = torch.cat([x, x_downsample[3 - inx]], -1) x = self.concat_back_dim[inx](x) x = layer_up(x) x = self.norm_up(x) # B L C return x def up_x4(self, x): H, W = self.patches_resolution B, L, C = x.shape assert L == H * W, "input features has wrong size" if self.final_upsample == "expand_first": x = self.up(x) x = x.view(B, 4 * H, 4 * W, -1) x = x.permute(0, 3, 1, 2) # B,C,H,W x = self.output(x) return x def forward(self, x): x, x_downsample = self.forward_features(x) x = self.forward_up_features(x, x_downsample) x = self.up_x4(x) return x def flops(self): flops = 0 flops += self.patch_embed.flops() for i, layer in enumerate(self.layers): flops += layer.flops() flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers) flops += self.num_features * self.num_classes return flops class SwinUnet(nn.Module): def __init__(self, config, num_classes=21843, zero_head=False): super(SwinUnet, self).__init__() self.num_classes = num_classes self.zero_head = zero_head self.config = config self.swin_unet = SwinTransformerSys(img_size=config.IMG_SIZE, patch_size=config.PATCH_SIZE, in_chans=config.IN_CHANS, num_classes=self.num_classes, embed_dim=config.EMBED_DIM, depths=config.DEPTHS, num_heads=config.NUM_HEADS, window_size=config.WINDOW_SIZE, mlp_ratio=config.MLP_RATIO, qkv_bias=config.QKV_BIAS, qk_scale=config.QK_SCALE, drop_rate=config.DROP_RATE, drop_path_rate=config.DROP_PATH_RATE, ape=config.APE, patch_norm=config.PATCH_NORM, use_checkpoint=config.USE_CHECKPOINT) def forward(self, x): if x.size()[1] == 1: x = x.repeat(1, 3, 1, 1) logits = self.swin_unet(x) return logits def load_from(self, config): pretrained_path = config.MODEL.PRETRAIN_CKPT if pretrained_path is not None: print("pretrained_path:{}".format(pretrained_path)) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') pretrained_dict = torch.load(pretrained_path, map_location=device) if "model" not in pretrained_dict: print("---start load pretrained modle by splitting---") pretrained_dict = {k[17:]: v for k, v in pretrained_dict.items()} for k in list(pretrained_dict.keys()): if "output" in k: print("delete key:{}".format(k)) del pretrained_dict[k] msg = self.swin_unet.load_state_dict(pretrained_dict, strict=False) # print(msg) return pretrained_dict = pretrained_dict['model'] print("---start load pretrained modle of swin encoder---") model_dict = self.swin_unet.state_dict() full_dict = copy.deepcopy(pretrained_dict) for k, v in pretrained_dict.items(): if "layers." in k: current_layer_num = 3 - int(k[7:8]) current_k = "layers_up." + str(current_layer_num) + k[8:] full_dict.update({current_k: v}) for k in list(full_dict.keys()): if k in model_dict: if full_dict[k].shape != model_dict[k].shape: print("delete:{};shape pretrain:{};shape model:{}".format(k, v.shape, model_dict[k].shape)) del full_dict[k] msg = self.swin_unet.load_state_dict(full_dict, strict=False) # print(msg) else: print("none pretrain") def get_swin_unet(image_size=224, num_classes=3, in_channel=1): if image_size % 7 == 0: ws = 7 if image_size % 8 == 0: ws = 8 config = EasyDict() config.IMG_SIZE = image_size config.PATCH_SIZE = 4 config.IN_CHANS = in_channel config.num_classes = 4 config.EMBED_DIM = 96 config.DEPTHS = [2, 2, 6, 2] config.DECODER_DEPTHS = [2, 2, 6, 2] config.NUM_HEADS = [3, 6, 12, 24] config.MLP_RATIO = 4 config.QKV_BIAS = True config.QK_SCALE = None config.APE = False config.PATCH_NORM = True config.FINAL_UPSAMPLE = "expand_first" config.WINDOW_SIZE = ws config.DROP_RATE = 0.1 config.DROP_PATH_RATE = 0.1 config.USE_CHECKPOINT = False return SwinUnet(config=config, num_classes=num_classes) if __name__ == '__main__': x = torch.randn(2, 1, 256, 256) model = get_swin_unet(num_classes=4, image_size=256, in_channel=3) y = model(x) print(y.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
- 702
- 703
- 704
- 705
- 706
- 707
- 708
- 709
- 710
- 711
- 712
- 713
- 714
- 715
- 716
- 717
- 718
- 719
- 720
- 721
- 722
- 723
- 724
- 725
- 726
- 727
- 728
- 729
- 730
- 731
- 732
- 733
- 734
- 735
- 736
- 737
- 738
- 739
- 740
- 741
- 742
- 743
- 744
- 745
- 746
- 747
- 748
- 749
- 750
- 751
- 752
- 753
- 754
- 755
- 756
- 757
- 758
- 759
- 760
- 761
- 762
- 763
- 764
- 765
- 766
- 767
- 768
- 769
- 770
- 771
- 772
- 773
- 774
- 775
- 776
- 777
- 778
- 779
- 780
- 781
- 782
- 783
- 784
- 785
- 786
- 787
- 788
- 789
- 790
- 791
- 792
- 793
- 794
- 795
- 796
- 797
- 798
- 799
- 800
- 801
- 802
- 803
- 804
- 805
- 806
- 807
- 808
- 809
- 810
- 811
- 812
- 813
- 814
- 815
- 816
- 817
- 818
- 819
- 820
- 821
- 822
- 823
- 824
- 825
- 826
- 827
- 828
- 829
- 830
- 831
- 832
- 833
- 834
- 835
- 836
- 837
- 838
- 839
- 840
- 841
- 842
- 843
- 844
- 845
- 846
- 847
- 848
- 849
- 850
- 851
- 852
- 853
- 854
- 855
- 856
- 857
- 858
- 859
- 860
- 861
- 862
- 863
- 864
- 865
- 866
- 867
- 868
- 869
- 870
- 871
- 872
- 873
- 874
参考资料
[2105.05537] Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation (arxiv.org)
[(5条消息) 深度学习论文笔记]Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation_Slientsake的博客-CSDN博客
-
相关阅读:
java运行以jar包的形式运行和tomcat运行的区别和联系?
上传大文件至 Git 仓库并使用 Git LFS 管理
Salesforce ServiceCloud考证学习(5)
关于Ubuntu18.04安装后没有gcc、make、网卡驱动的问题总结以及解决办法
【AI视野·今日NLP 自然语言处理论文速览 第五十期】Mon, 9 Oct 2023
以梦为马,不负韶华|电巢科技&延安大学飞鹰计划实习班精彩回顾
linux下telnet不能使用
MCU软核 2. Xilinx Artix7上运行tinyriscv
Qt基础 界面镜像
【GlobalMapper精品教程】023:Excel数据通过相同字段连接到属性表中(气温降水连接到气象台站)
- 原文地址:https://blog.csdn.net/wujing1_1/article/details/127946187
