-
机器学习之决策树【西瓜书】
当一个有经验的老农看一个瓜是不是好瓜时,他可能会先看下瓜的颜色,一看是青绿的,心想有可能是好瓜;接着他又看了下根蒂,发现是蜷缩着的,老农微微点头,寻思着五成以上是好瓜;最后他又敲了下瓜,一听发出浑浊的响声,基本确定这个瓜是个好瓜!
决策树便是模拟“老农判瓜”的过程,通过对属性的层层筛选从而得到当前样本的分类。
可是,问题在于,老农判瓜依据的是其多年判瓜经验,计算机如何获得这些“识瓜经验”呢?又如何知道哪些属性是更为重要的属性呢?这便是实现决策树需要解决的重要问题。
信息熵
信息熵是度量样本集合纯度最常用的一种指标,信息熵 E n t ( D ) Ent(D) Ent(D) 的值越小,则样本 D D D 的纯度越高【即越有序,比如 D D D 中全是好瓜,则其信息熵就会很小】
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum_{k=1}^{\vert y\vert}p_klog_2p_k\\ Ent(D)=−k=1∑∣y∣pklog2pk
其中 ∣ y ∣ \vert y\vert ∣y∣ 是分类个数,如最终分类为好瓜/坏瓜,则 ∣ y ∣ \vert y\vert ∣y∣ 为 2 2 2; D D D 为样本集,在训练数据时即为整个训练集 p k p_k pk 即在样本 D D D 中分类为 k k k 的可能性
信息增益
假定离散属性 a a a 有 V V V个可能的取值 { a 1 , a 2 , . . , a V } \{a^1,a^2,..,a^V\} {a1,a2,..,aV} 【如色泽可以为青绿,乌黑,浅白】,若使用 a a a 来对样本集合 D D D 进行划分,则会产生 V V V 个分支结点【如色泽会分为三部分】,其中第 v v v 个分支节点包含了 D D D 中所有在属性 a a a 上取值为 a v a^v av 的样本,记为 D v D^v Dv 【如色泽乌黑的样本】。
我们可以根接新的样本集计算出新的信息熵【注意:信息熵的 k k k 对应的是分类,即好瓜与坏瓜】,再考虑到不同的分支结点所包含样本数不同,给分支结点赋予权重 ∣ D v ∣ ∣ D ∣ \dfrac{\vert D^v\vert}{\vert D\vert} ∣D∣∣Dv∣ 【如色泽乌黑的瓜在所有瓜中的比重】,即样本数越多的分支节点造成的影响越大。
由此可以计算出用属性 a a a 对样本集 D D D 进行划分所获得的信息增益
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\dfrac{\vert D^v \vert}{\vert D \vert}Ent(D^v)\\ Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
一般而言,信息增益越大,则意味着使用属性 a a a 来进行划分所获得的纯度提升越大,因此我们可以使用信息增益来进行决策树的划分属性选择,著名的 I D 3 ID3 ID3 算法就是以信息增益为准则来选择划分属性

西瓜书 P 75 P75 P75 页中通过信息增益选择了纹理作为第一个节点

在选择了纹理属性后,接下来在纹理清晰这一分支中应该选择哪一属性继续划分,即计算各个属性在此分支的信息增益,此处以色泽属性为例,演示如何得到西瓜书 P 77 P77 P77 的 G a i n ( D 1 , c o l o r s ) = 0.043 Gain(D^1,colors)=0.043 Gain(D1,colors)=0.043,为避免上标下标混淆,下边 D 1 D_1 D1 代表纹理为清晰的样本集, D v D^{v} Dv 代表在纹理清晰的情况下,色泽 c o l o r s colors colors 属性为 v v v 的样本集
如下是已知纹理清晰的情况下,对属性色泽 c o l o r s colors colors 进一步进行决策,求此时的信息增益
G a i n ( D 1 , c o l o r s ) = E n t ( D 1 ) − ∑ v = 1 3 ∣ D v ∣ ∣ D 1 ∣ E n t ( D v ) Gain(D_1,colors)=Ent(D_1)-\sum_{v=1}^{3}\dfrac{\vert D^v \vert}{\vert D_1\vert}Ent(D^v)\\ Gain(D1,colors)=Ent(D1)−v=1∑3∣D1∣∣Dv∣Ent(Dv)色泽 c o l o r s colors colors 有 3 3 3 种取值,所以 v v v 最大值为 3 3 3 ; D v D^v Dv 代表色泽属性值为 v v v 的样本集
∴ E n t ( D 1 ) = − ( 7 9 l o g 2 7 9 + 2 9 l o g 2 2 9 ) = 0.7642 E n t ( D 1 ) = − ( 3 4 l o g 2 3 4 + 1 4 l o g 2 1 4 ) = 0.8113 E n t ( D 2 ) = − ( 3 4 l o g 2 3 4 + 1 4 l o g 2 1 4 ) = 0.8113 E n t ( D 3 ) = − ( 1 1 l o g 2 1 1 + 0 1 l o g 2 0 1 ) = 0 \therefore Ent(D_1)=-(\dfrac{7}{9}log_2\dfrac{7}{9}+\dfrac{2}{9}log_2\dfrac{2}{9})=0.7642\\ Ent(D^1)=-(\dfrac{3}{4}log_2\dfrac{3}{4}+\dfrac{1}{4}log_2\dfrac{1}{4})=0.8113\\ Ent(D^2)=-(\dfrac{3}{4}log_2\dfrac{3}{4}+\dfrac{1}{4}log_2\dfrac{1}{4})=0.8113\\ Ent(D^3)=-(\dfrac{1}{1}log_2\dfrac{1}{1}+\dfrac{0}{1}log_2\dfrac{0}{1})=0 ∴Ent(D1)=−(97log297+92log292)=0.7642Ent(D1)=−(43log243+41log241)=0.8113Ent(D2)=−(43log243+41log241)=0.8113Ent(D3)=−(11log211+10log210)=0
计算信息熵时约定,若 p = 0 p=0 p=0 ,则 p l o g 2 p = 0 plog_2p=0 plog2p=0
∴ G a i n ( D 1 , c o l o r s ) = 0.7212 − ( 4 9 ∗ 0.8113 + 4 9 ∗ 0.8113 + 1 9 ∗ 0 ) = 0.043 \therefore Gain(D_1,colors)=0.7212-(\dfrac{4}{9}*0.8113+\dfrac{4}{9}*0.8113+\dfrac{1}{9}*0)=0.043\\ ∴Gain(D1,colors)=0.7212−(94∗0.8113+94∗0.8113+91∗0)=0.043
同理,其他属性的信息增益也可以通过上述方法得到,选择信息增益最大的作为新的划分点,即根蒂增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C 4.5 C4.5 C4.5 决策树算法不直接使用信息增益,而是使用信息增益率
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ Gain\_ratio(D,a)=\dfrac{Gain(D,a)}{IV(a)}\\ IV(a)=-\sum_{v=1}^{V}\dfrac{\vert D^v \vert}{\vert D\vert}log_2\dfrac{\vert D^v\vert}{\vert D\vert}\\\\ Gain_ratio(D,a)=IV(a)Gain(D,a)IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
以选择根节点为例,计算属性色泽 c o l o r s colors colors 的信息增益率
G a i n _ r a t i o ( D , c o l o r s ) = G a i n ( D , c o l o r s ) I V ( c o l o r s ) G a i n ( D , c o l o r s ) = E n t ( D ) − ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ E n t ( D v ) E n t ( D ) = − ( 8 17 l o g 2 8 17 + 9 17 l o g 2 9 17 ) = 0.998 E n t ( D 1 ) = − ( 3 6 l o g 2 3 6 + 3 6 l o g 2 3 6 ) = 1 E n t ( D 2 ) = − ( 4 6 l o g 2 4 6 + 2 6 l o g 2 2 6 ) = 0.9183 E n t ( D 3 ) = − ( 1 5 l o g 2 1 5 + 4 5 l o g 2 4 5 ) = 0.7219 ∴ G a i n ( D , c o l o r s ) = 0.998 − ( 6 17 ∗ 1 + 6 17 ∗ 0.9183 + 5 17 ∗ 0.7219 ) = 0.1087 I V ( c o l o r s ) = − ( 6 17 l o g 2 6 17 + 6 17 l o g 2 6 17 + 5 17 l o g 2 5 17 ) = 1.580 ∴ G a i n _ r a t i o ( D , c o l o r s ) = 0.1087 1.580 = 0.0689 Gain\_ratio(D,colors)=\dfrac{Gain(D,colors)}{IV(colors)}\\ Gain(D,colors)=Ent(D)-\sum_{v=1}^{3}\dfrac{\vert D^v\vert}{\vert D\vert}Ent(D^v)\\ Ent(D)=-(\dfrac{8}{17}log_2\dfrac{8}{17}+\dfrac{9}{17}log_2\dfrac{9}{17})=0.998\\ Ent(D^1)=-(\dfrac{3}{6}log_2\dfrac{3}{6}+\dfrac{3}{6}log_2\dfrac{3}{6})=1\\ Ent(D^2)=-(\dfrac{4}{6}log_2\dfrac{4}{6}+\dfrac{2}{6}log_2\dfrac{2}{6})=0.9183\\ Ent(D^3)=-(\dfrac{1}{5}log_2\dfrac{1}{5}+\dfrac{4}{5}log_2\dfrac{4}{5})=0.7219\\ \therefore Gain(D,colors)=0.998-(\dfrac{6}{17}*1+\dfrac{6}{17}*0.9183+\dfrac{5}{17}*0.7219)=0.1087\\\\ IV(colors)=-(\dfrac{6}{17}log_2\dfrac{6}{17}+\dfrac{6}{17}log_2\dfrac{6}{17}+\dfrac{5}{17}log_2\dfrac{5}{17})=1.580\\ \therefore Gain\_ratio(D,colors)=\dfrac{0.1087}{1.580}=0.0689 Gain_ratio(D,colors)=IV(colors)Gain(D,colors)Gain(D,colors)=Ent(D)−v=1∑3∣D∣∣Dv∣Ent(Dv)Ent(D)=−(178log2178+179log2179)=0.998Ent(D1)=−(63log263+63log263)=1Ent(D2)=−(64log264+62log262)=0.9183Ent(D3)=−(51log251+54log254)=0.7219∴Gain(D,colors)=0.998−(176∗1+176∗0.9183+175∗0.7219)=0.1087IV(colors)=−(176log2176+176log2176+175log2175)=1.580∴Gain_ratio(D,colors)=1.5800.1087=0.0689
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此 C 4.5 C4.5 C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择信息增益率最高的。基尼指数
C A R T CART CART 决策树【二叉树形式,如对色泽 c o l o r s colors colors 只有两个属性,青绿,非青绿】使用基尼指数来选择划分属性,数据集 D D D 的纯度可用基尼值来度量。
基尼值反映了从数据集中随机抽取两个样本,其类别标记不一致的概率【即预测错误的概率】,因此基尼值越小,数据集 D D D 的纯度越高
G i n i ( D ) = ∑ k = 1 ∣ y ∣ ∑ k ′ ≠ k p k p k ′ = ∑ k = 1 ∣ y ∣ p k ( 1 − p k ) = 1 − ∑ k = 1 ∣ y ∣ p k 2 Gini(D)=\sum_{k=1}^{\vert y\vert}\sum_{k^{'}\ne k}^{}p_kp_k^{'} =\sum_{k=1}^{\vert y\vert}p_k(1-p_k)=1-\sum_{k=1}^{\vert y\vert}p_k^{2} Gini(D)=k=1∑∣y∣k′=k∑pkpk′=k=1∑∣y∣pk(1−pk)=1−k=1∑∣y∣pk2
其中 ∑ k ′ ≠ k p k ′ \sum_{k^{'}\ne k}^{}p_k^{'} ∑k′=kpk′ 意思为类别不为 k k k 的所有概率之和,实则就是 1 − p k 1-p_k 1−pk
另外,由于共有 ∣ y ∣ \vert y\vert ∣y∣ 种类别【在 C A R T CART CART 决策树中其值为 2 2 2 ,即好瓜、坏瓜】,
∴ p 1 + p 2 + . . . + p ∣ y ∣ = 1 \therefore p_1+p_2+...+p_{\vert y\vert}=1 ∴p1+p2+...+p∣y∣=1
由此我们可以得到基尼指数的定义:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini\_index(D,a)=\sum_{v=1}^{V}\dfrac{\vert D^v\vert}{\vert D\vert}Gini(D^v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
其中 a a a 属性有 V V V 个取值, G i n i ( D v ) Gini(D^v) Gini(Dv) 是取值为 v v v 时对应数据集的基尼值于是,我们在候选属性集合 A A A【表
4.1西瓜数据集2.0】 中,选择那个使得划分后基尼指数最小的属性作为划分属性
a ∗ = a r g min a ∈ A G i n i _ i n d e x ( D , a ) a_*=arg\min\limits_{a\in A} Gini\_index(D,a) a∗=arga∈AminGini_index(D,a)
我们再次使用色泽 c o l o r s colors colors 属性进行举例,计算此时的基尼指数
G i n i _ i n d e x ( D , c o l o r s ) = ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ G i n i ( D v ) G i n i ( D 1 ) = 1 − ( ( 3 6 ) 2 + ( 3 6 ) 2 ) = 1 2 G i n i ( D 2 ) = 1 − ( ( 4 6 ) 2 + ( 2 6 ) 2 ) = 4 9 G i n i ( D 3 ) = 1 − ( ( 1 5 ) 2 + ( 4 5 ) 2 ) = 8 25 ∴ G i n i _ i n d e x ( D , c o l o r s ) = 6 17 ∗ 1 2 + 6 17 ∗ 4 9 + 5 17 ∗ 8 25 = 0.4275 Gini\_index(D,colors)=\sum_{v=1}^{3}\dfrac{\vert D^v\vert}{\vert D\vert}Gini(D^v)\\ Gini(D^1)=1-((\dfrac{3}{6})^2+(\dfrac{3}{6})^2)=\dfrac{1}{2}\\ Gini(D^2)=1-((\dfrac{4}{6})^2+(\dfrac{2}{6})^2)=\dfrac{4}{9}\\ Gini(D^3)=1-((\dfrac{1}{5})^2+(\dfrac{4}{5})^2)=\dfrac{8}{25}\\ \therefore Gini\_index(D,colors)=\dfrac{6}{17}*\dfrac{1}{2}+\dfrac{6}{17}*\dfrac{4}{9}+\dfrac{5}{17}*\dfrac{8}{25}=0.4275 Gini_index(D,colors)=v=1∑3∣D∣∣Dv∣Gini(Dv)Gini(D1)=1−((63)2+(63)2)=21Gini(D2)=1−((64)2+(62)2)=94Gini(D3)=1−((51)2+(54)2)=258∴Gini_index(D,colors)=176∗21+176∗94+175∗258=0.4275假设在所有属性的基尼指数中,色泽的基尼指数最小,接下来我们比较三种划分带权重的基尼值情况
5 17 G i n i ( D 3 ) < 6 17 G i n i ( D 2 ) < 6 17 G i n i ( D 1 ) \dfrac{5}{17}Gini(D^3)<\dfrac{6}{17}Gini(D^2)<\dfrac{6}{17}Gini(D^1) 175Gini(D3)<176Gini(D2)<176Gini(D1)所以选择的色泽属性为浅白,非浅白
剪枝
剪枝是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身得一些特点当成所有数据都具有得一般兴致而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合得风险。
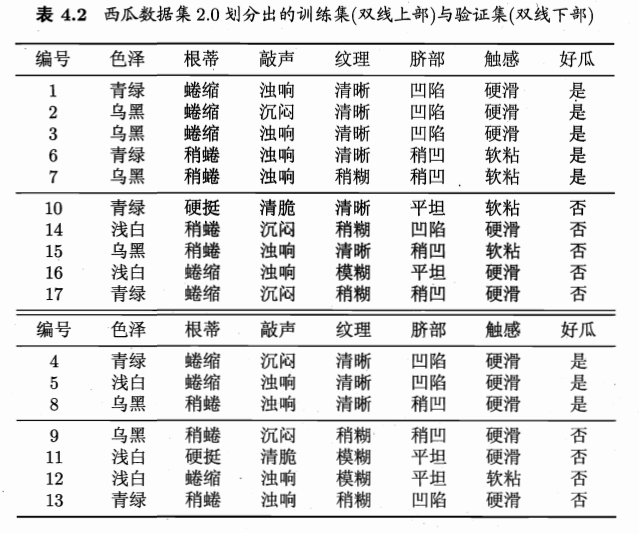
根据信息增益准则生成的决策树

预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点得划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点
西瓜书中对于脐部的计算已有详细步骤,因此不多赘述。此处对色泽属性是否需要划分进行计算,即计算划分前与划分后的验证集精度【测试集中预测正确的占比】

通过训练集发现,凹陷后色泽为青绿,乌黑的为好瓜,浅白的为坏瓜
当做此划分后,凹陷且青绿预测为好瓜,凹陷且乌黑预测为好瓜,凹陷且浅白预测为坏瓜
稍凹预测为好瓜,平坦预测为坏瓜
剪枝前的精确率: a c c u r a c y _ b e f o r e _ c u t = 1 + 1 + 2 7 = 4 7 = 57.1 % accuracy\_before\_cut=\dfrac{1+1+2}{7}=\dfrac{4}{7}=57.1\% accuracy_before_cut=71+1+2=74=57.1%
对色泽进行剪枝后即将所有脐部凹陷,稍凹的都预测为好瓜,平坦的预测为坏瓜
剪枝后的精确率: a c c u r a c y _ a f t e r _ c u t = 5 7 = 71.4 % accuracy\_after\_cut=\dfrac{5}{7}=71.4\% accuracy_after_cut=75=71.4%
剪枝之后精确率提升, ∴ \therefore ∴ 色泽属性应该剪去,即禁止划分色泽属性
后剪枝
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶子结点
计算方法与预剪枝类似,西瓜书上也有详细步骤,不做过多赘述

剪枝总结
- 预剪枝和后剪枝唯一的区别就是前者在决策树生成过程中决定是否剪枝,后者在决策树构造完成后再次遍历各属性结点决定是否剪枝
- 一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多
- 预剪枝和后剪枝的算法有多种,这里只是展示了最简单的两种,不过基本思想都是一致的,即通过对比剪枝前后的某个指标来决定是否进行剪枝
连续值
由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术可派上用场。最简单的策略是采用二分法对连续属性进行处理,这正是 C 4.5 C4.5 C4.5 决策树算法中采用的机制

比如我们现在相对密度属性进行划分,则操作如下
首先获得划分点集合: T a = { a i + a i + 1 2 ∣ 1 ≤ i ≤ n − 1 } T_a=\{\dfrac{a^i+a^{i+1}}{2}\vert 1\le i\le n-1\} Ta={2ai+ai+1∣1≤i≤n−1}
即对连续属性a的所有可能取值进行排序,接着取相邻值得平均值作为划分点集合 T a T_a Ta 的元素
在上述训练集中,密度 d e n s i t y density density 的划分点集合如下👇
T d e n s i t y = { 0.244 , 0.294 , 0.351 , 0.381 , 0.420 , 0.459 , 0.518 , 0.574 , 0.600 , 0.621 , 0.636 , 0.648 , 0.661 , 0.681 , 0.708 , 0.746 } T_{density}=\{0.244,0.294,0.351,0.381,0.420,0.459,0.518,0.574,0.600,0.621,0.636,0.648,\\0.661,0.681,0.708,0.746\}\\ Tdensity={0.244,0.294,0.351,0.381,0.420,0.459,0.518,0.574,0.600,0.621,0.636,0.648,0.661,0.681,0.708,0.746}
接着便是计算各个划分点对应的信息增益,选择信息增益最大的划分点
G a i n ( D , a ) = max t ∈ T a E n t ( D ) − ∑ λ ∈ { + , − } ∣ D t λ ∣ ∣ D ∣ E n t ( D t λ ) Gain(D,a)=\max\limits_{t\in T_a}Ent(D)-\sum_{\lambda\in \{+,-\}}^{}\dfrac{\vert D_{t}^\lambda\vert}{\vert D \vert}Ent(D_{t}^\lambda) Gain(D,a)=t∈TamaxEnt(D)−λ∈{+,−}∑∣D∣∣Dtλ∣Ent(Dtλ)
其中 t t t 为 T a T_a Ta 集合中的划分点, λ \lambda λ 为正项或负项目,分别对应 a > t a>t a>t 以及 a ≤ t a\le t a≤t
接着以密度划分点 0.381 0.381 0.381 为例计算其对应的信息增益
G a i n ( D , d e n s i t y , 0.381 ) = E n t ( D ) − ∑ λ ∈ { + , − } ∣ D 0.381 λ ∣ ∣ D ∣ E n t ( D 0.381 λ ) Gain(D,density,0.381)=Ent(D)-\sum_{\lambda\in \{+,-\}}^{}\dfrac{\vert D_{0.381}^\lambda\vert}{\vert D \vert}Ent(D_{0.381}^\lambda)\\ Gain(D,density,0.381)=Ent(D)−λ∈{+,−}∑∣D∣∣D0.381λ∣Ent(D0.381λ)
λ \lambda λ 为 − - − 时, D 0.381 λ D^\lambda_{0.381} D0.381λ 表示密度小于等于 0.381 0.381 0.381 的样本集
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k = − ( 8 17 l o g 2 8 17 + 9 17 l o g 2 9 17 ) = 0.9975 E n t ( D 0.381 + ) = − ( 8 13 l o g 2 8 13 + 5 13 l o g 2 5 13 ) = 0.9612 E n t ( D 0.381 + ) = − ( 0 4 l o g 2 0 4 + 4 4 l o g 2 4 4 ) = 0 ∴ G a i n ( D , d e n s i t y ) = 0.9975 − ( 13 17 ∗ 0.9612 + 4 17 ∗ 0 ) = 0.262 Ent(D)=-\sum_{k=1}^{\vert y\vert}p_klog_2p_k=-(\dfrac{8}{17}log_2\dfrac{8}{17}+\dfrac{9}{17}log_2\dfrac{9}{17})=0.9975\\ Ent(D^+_{0.381})=-(\dfrac{8}{13}log_2\dfrac{8}{13}+\dfrac{5}{13}log_2\dfrac{5}{13})=0.9612\\ Ent(D^+_{0.381})=-(\dfrac{0}{4}log_2\dfrac{0}{4}+\dfrac{4}{4}log_2\dfrac{4}{4})=0\\ \therefore Gain(D,density)=0.9975-(\dfrac{13}{17}*0.9612+\dfrac{4}{17}*0)=0.262 Ent(D)=−k=1∑∣y∣pklog2pk=−(178log2178+179log2179)=0.9975Ent(D0.381+)=−(138log2138+135log2135)=0.9612Ent(D0.381+)=−(40log240+44log244)=0∴Gain(D,density)=0.9975−(1713∗0.9612+174∗0)=0.262
假设在密度所有划分点中, 0.381 0.381 0.381 对应的信息增益最大,则此信息增益就当作密度属性的信息增益,代表密度属性在决策树构建中参与竞选【密度 ≤ 0.381 \le0.381 ≤0.381 为坏瓜是因为在训练集中坏瓜占比大 】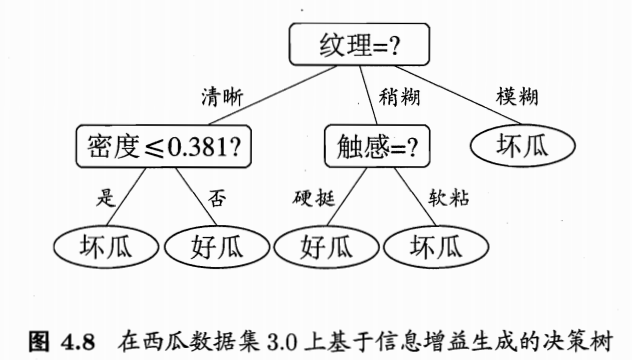
缺失值
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。若将有缺失值的样本全部丢弃,显然是对数据集的浪费,因此,使用有缺失值的训练样例来进行学习十分必要

此时信息增益公式再次进行修改
G a i n ( D , a ) = ρ ∗ G a i n ( D ~ , a ) = ρ ∗ ( E n t ( D ~ ) − ∑ v = 1 V r ~ v E n t ( D ~ v ) ) E n t ( D ~ ) = − ∑ k = 1 ∣ y ∣ p ~ k l o g 2 p ~ k Gain(D,a)=\rho*Gain(\tilde D,a)=\rho*(Ent(\tilde D)-\sum_{v=1}^{V}\tilde r_vEnt(\tilde D^v))\\ Ent(\tilde D)=-\sum_{k=1}^{\vert y\vert}\tilde p_klog_2\tilde p_k\\ Gain(D,a)=ρ∗Gain(D~,a)=ρ∗(Ent(D~)−v=1∑Vr~vEnt(D~v))Ent(D~)=−k=1∑∣y∣p~klog2p~k
其中 ρ \rho ρ 表示无缺失值样本所占比例【如上述数据集 ρ = 4 17 \rho=\dfrac{4}{17} ρ=174 】
p ~ k \tilde p_k p~k 表示无缺失值样本中第 k k k 类所占比例【如好瓜在无缺失值样本中的比例】
r ~ v \tilde r_v r~v 表示无缺失值样本在属性 a a a 上取值 a v a^v av 的样本所占的比例【如色泽青绿的瓜在无缺失值样本中的比例】由此可以计算出不同属性对应的信息增益,选择对应的属性结点构造决策树,西瓜书中有构造的详细步骤,此处不再赘述
-
相关阅读:
说说验证码功能的实现
vue computed作用特点及使用场景及示例
Vue2:官方路由 Vue-Router 3.x
清览题库--C语言程序设计第五版编程题解析(3)
Opencv_4_图像像素的读写操作
[Python私活案例]24行代码,轻松赚取400元,运用Selenium爬取39万条数据
incStrong() 和 decStrong()
Deep Image Matting:深度学习Matting开山之作
人工智能知识全面讲解:生活中的决策树
基于java的简易socket聊天程序
- 原文地址:https://blog.csdn.net/weixin_45488428/article/details/127942584