-
Redis常用命令
目录
前言
在开始前,先在复习一下redis中的五大基本数据类型

这篇文章讲的就是五大基本数据类型的常用命令~
贴心小提示:以下所有都代码块是命令行窗口复制过来的,包括命令和结果哦~
1 Redis命令-String命令
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
-
string:普通字符串
-
int:整数类型,可以做自增.自减操作
-
float:浮点类型,可以做自增.自减操作

String类型的常见命令有:
-
SET:添加或者修改已经存在的一个String类型的键值对
-
GET:根据key获取String类型的value
-
MSET:批量添加多个String类型的键值对
-
MGET:根据多个key获取多个String类型的value
-
INCR:让一个整型的key自增1
-
INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
-
INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
-
SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
-
SETEX:添加一个String类型的键值对,并且指定有效期
贴心小提示:以上命令除了INCRBYFLOAT 都是常用命令
SET 和GET: 如果key不存在则是新增,如果存在则是修改
- 127.0.0.1:6379> set name Rose //原来不存在
- OK
- 127.0.0.1:6379> get name
- "Rose"
- 127.0.0.1:6379> set name Jack //原来存在,就是修改
- OK
- 127.0.0.1:6379> get name
- "Jack"
MSET和MGET:批量新增和批量查找(如果存在是修改)
- 127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
- OK
- 127.0.0.1:6379> MGET name age k1 k2 k3
- 1) "Jack" //之前存在的name
- 2) "10" //之前存在的age
- 3) "v1"
- 4) "v2"
- 5) "v3"
INCR和INCRBY:给value增加值,前者固定增加1,后者自定义增加值
- 127.0.0.1:6379> get age
- "10"
- 127.0.0.1:6379> incr age //增加1
- (integer) 11
- 127.0.0.1:6379> get age //获得age
- "11"
- 127.0.0.1:6379> incrby age 2 //一次增加2
- (integer) 13 //返回目前的age的值
- 127.0.0.1:6379> incrby age 2
- (integer) 15
- 127.0.0.1:6379> incrby age -1 //也可以增加负数,相当于减
- (integer) 14
- 127.0.0.1:6379> incrby age -2 //一次减少2个
- (integer) 12
- 127.0.0.1:6379> DECR age //相当于 incr 负数,减少正常用法
- (integer) 11
- 127.0.0.1:6379> get age
- "11"
SETNX:增加key,前提是这个key不存在,否则无法添加(真正意义上的新增)
- 127.0.0.1:6379> help setnx
- SETNX key value
- summary: Set the value of a key, only if the key does not exist
- since: 1.0.0
- group: string
- 127.0.0.1:6379> set name Jack //设置名称
- OK
- 127.0.0.1:6379> setnx name lisi //如果key不存在,则添加成功
- (integer) 0
- 127.0.0.1:6379> get name //由于name已经存在,所以lisi的操作失败
- "Jack"
- 127.0.0.1:6379> setnx name2 lisi //name2 不存在,所以操作成功
- (integer) 1
- 127.0.0.1:6379> get name2
- "lisi"
SETEX :新增并指定有效期
- 127.0.0.1:6379> setex name 10 jack
- OK
- 127.0.0.1:6379> ttl name
- (integer) 8
- 127.0.0.1:6379> ttl name
- (integer) 7
- 127.0.0.1:6379> ttl name
- (integer) 5
2 Redis命令-Hash命令
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:

Hash类型的常见命令(命令执行都是针对field)
-
HSET key field value:添加或者修改hash类型key的field的值
-
HGET key field:获取一个hash类型key的field的值
-
HMSET:批量添加多个hash类型key的field的值
-
HMGET:批量获取多个hash类型key的field的值
-
HGETALL:获取一个hash类型的key中的所有的field和value
-
HKEYS:获取一个hash类型的key中的所有的field
-
HINCRBY:让一个hash类型key的字段值自增并指定步长
-
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
贴心小提示:哈希结构也是我们以后实际开发中常用的命令哟
HSET和HGET:添加或者修改hash类型key的field的值
- 127.0.0.1:6379> HSET heima:user:3 name Lucy//大key是 heima:user:3 小key是name,小value是Lucy
- (integer) 1
- 127.0.0.1:6379> HSET heima:user:3 age 21// 如果操作不存在的数据,则是新增
- (integer) 1
- 127.0.0.1:6379> HSET heima:user:3 age 17 //如果操作存在的数据,则是修改
- (integer) 0
- 127.0.0.1:6379> HGET heima:user:3 name
- "Lucy"
- 127.0.0.1:6379> HGET heima:user:3 age
- "17"
HMSET和HMGET:批量添加和获取多个hash类型key的field的值
- 127.0.0.1:6379> HMSET heima:user:4 name HanMeiMei
- OK
- 127.0.0.1:6379> HMSET heima:user:4 name LiLei age 20 sex man
- OK
- 127.0.0.1:6379> HMGET heima:user:4 name age sex
- 1) "LiLei"
- 2) "20"
- 3) "man"
HGETALL:获取一个hash类型的key中的所有的field和value
- 127.0.0.1:6379> HGETALL heima:user:4
- 1) "name"
- 2) "LiLei"
- 3) "age"
- 4) "20"
- 5) "sex"
- 6) "man"
HKEYS和HVALS:获取一个hash类型的key中的所有的field和value
- 127.0.0.1:6379> HKEYS heima:user:4
- 1) "name"
- 2) "age"
- 3) "sex"
- 127.0.0.1:6379> HVALS heima:user:4
- 1) "LiLei"
- 2) "20"
- 3) "man"
HINCRBY:让一个hash类型key的字段值自增并指定步长
- 127.0.0.1:6379> HINCRBY heima:user:4 age 2
- (integer) 22
- 127.0.0.1:6379> HVALS heima:user:4
- 1) "LiLei"
- 2) "22"
- 3) "man"
- 127.0.0.1:6379> HINCRBY heima:user:4 age -2
- (integer) 20
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
- 127.0.0.1:6379> HSETNX heima:user4 sex woman
- (integer) 1
- 127.0.0.1:6379> HGETALL heima:user:3
- 1) "name"
- 2) "Lucy"
- 3) "age"
- 4) "17"
- 127.0.0.1:6379> HSETNX heima:user:3 sex woman
- (integer) 1
- 127.0.0.1:6379> HGETALL heima:user:3
- 1) "name"
- 2) "Lucy"
- 3) "age"
- 4) "17"
- 5) "sex"
- 6) "woman"
贴心小提示:Hash类型的常用命令大多都是在String类型的基础上加上了H,可以做做比较哦~
3 Redis命令-List命令
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
-
有序
-
元素可以重复
-
插入和删除快
-
查询速度一般
List的常见命令有:
-
LPUSH key element ... :向列表左侧插入一个或多个元素
-
LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
-
RPUSH key element ... :向列表右侧插入一个或多个元素
-
RPOP key:移除并返回列表右侧的第一个元素
-
LRANGE key star end:返回一段角标范围内的所有元素
-
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

此图先右插入AB,在左插入CD,最后右插入E LPUSH和RPUSH:从元素左边/右边依次插入
- 127.0.0.1:6379> LPUSH users 1 2 3
- (integer) 3
- 127.0.0.1:6379> RPUSH users 4 5 6
- (integer) 6
上面代码得到的值如下:

LPOP和RPOP:从元素最左边/右边取值:
- 127.0.0.1:6379> LPOP users
- "3"
- 127.0.0.1:6379> RPOP users
- "6"
LRANGE:返回一段角标范围内的所有元素
- 127.0.0.1:6379> LRANGE users 1 2
- 1) "1"
- 2) "4"
BLPOP和BRPOP:延迟取值(在规定的时间内取值)
如图:设置一个取user2 的值,等待时间为100秒,进入阻塞模式

打开另一个窗口,设置值

第一个窗口就可以取到啦,还附带了时间52.83s

小扩展:如何用一个List结构来表示一个栈?如何表示一个队列?又如何表示一个阻塞队列?
首先,栈通常表示先进后出,就是先进来的最后出去,出入口都在同一边。
而队列表时先进先出,就是先进来的先出去,出口和入口在不同的边。
有一个很形象的表示:
就是你去喝酒的时候,你吃进去的东西,吐出来的时候,就表示栈,因为吐出来的东西都是最后进到你的肚子里的,就是所谓的先进后出,且出入口都是嘴巴。
而你喝酒上厕所时,就可以表示为队列,因为上厕所先出来的,是进到你肚子里的,就是先进先出,且出口和入口分别是嘴巴和。。出入口不同。
回到那个小问题,
栈就可以表示成出口和入口都一样,所以我们可以用LPUSH来插入,LPOP来取出,就可以模拟啦~(RPUSH和RPOP同理)
而队列就表示为出口和入口不一样,所以我们可以用LPUSH来插入,RPOP来取出,以此来表示队列~(RPUSH和LPOP同理)
而阻塞队列,和队列的区别就是取出时有等待时间,以LPUSH和RPOP表示的队列为例,那我们取出的时候就可以用BRPOP来取代RPOP,这样就可以表示阻塞队列啦~
4 Redis命令-Set命令
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
-
无序
-
元素不可重复
-
查找快
-
支持交集.并集.差集等功能
Set类型的常见命令
-
SADD key member ... :向set中添加一个或多个元素
-
SREM key member ... : 移除set中的指定元素
-
SCARD key: 返回set中元素的个数
-
SISMEMBER key member:判断一个元素是否存在于set中
-
SMEMBERS:获取set中的所有元素
-
SINTER key1 key2 ... :求key1与key2的交集
-
SDIFF key1 key2 ... :求key1与key2的差集
-
SUNION key1 key2 ..:求key1和key2的并集
具体命令 (前面5个基本的增删改查操作)
- 127.0.0.1:6379> sadd s1 a b c
- (integer) 3
- 127.0.0.1:6379> smembers s1
- 1) "c"
- 2) "b"
- 3) "a"
- 127.0.0.1:6379> srem s1 a
- (integer) 1
- 127.0.0.1:6379> SISMEMBER s1 a
- (integer) 0
- 127.0.0.1:6379> SISMEMBER s1 b
- (integer) 1
- 127.0.0.1:6379> SCARD s1
- (integer) 2
最终得到的如下图

后面三个呢,是实现两个集合间的交集,差集和并集的
SINTER key1 key2 ... :求key1与key2的交集:
如图两个集合:
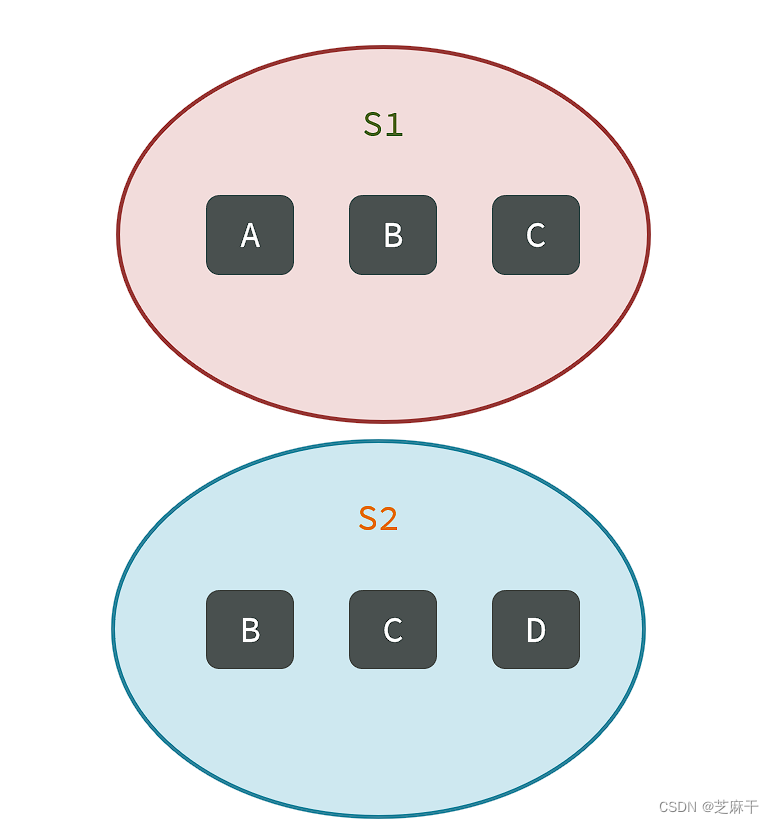
他们的交集就是S1和S2都有的
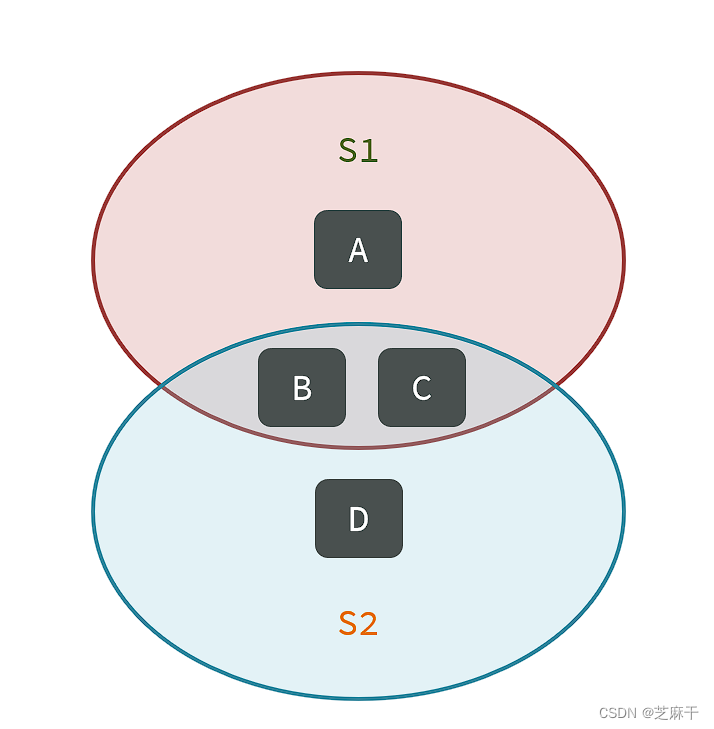
SDIFF key1 key2 ... :求key1与key2的差集。
所谓差集,就是S1有的,S2没有的
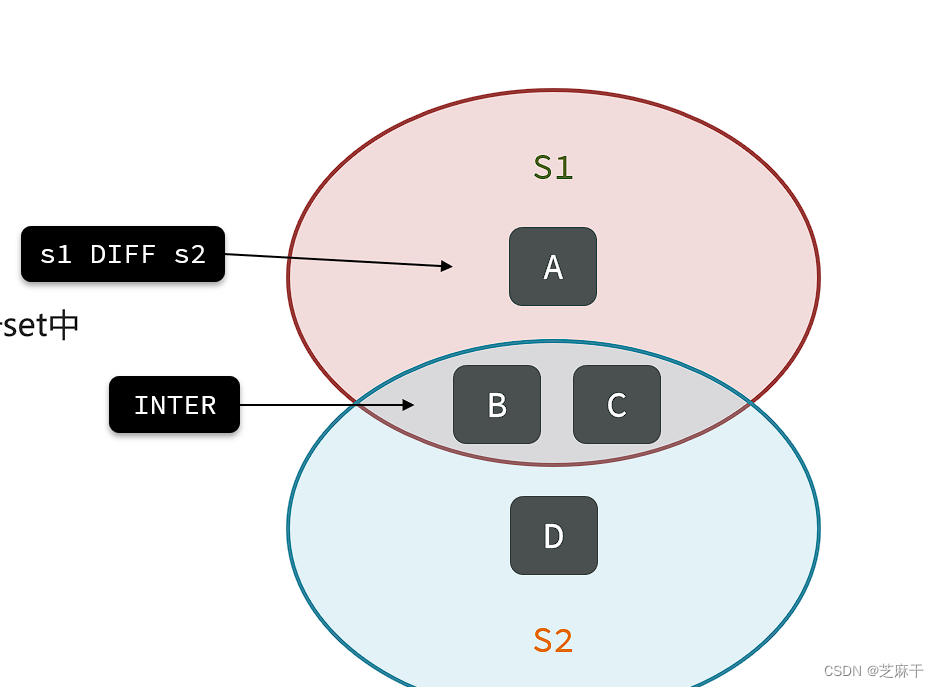
SUNION key1 key2 ..:求key1和key2的并集。
并集,就是两个集合结合起来的集合。
SET小练习:

实现代码如下 :
- 127.0.0.1:6379> sadd zhangsan lisi wangwu zhaoliu // 张三的好友
- (integer) 3
- 127.0.0.1:6379> sadd lisi wangwu mazi ergou //李四的好友
- (integer) 3
- 127.0.0.1:6379> SCARD zhangsan //查询张三有多少个好友
- (integer) 3
- 127.0.0.1:6379> SINTER zhangsan lis
- (empty array)
- 127.0.0.1:6379> SINTER zhangsan lisi //查询张三和李四的共同好友
- 1) "wangwu"
- 127.0.0.1:6379> SDIFF zhangsan lisi //查询是张三的朋友却不是李四的朋友(差集)
- 1) "lisi"
- 2) "zhaoliu"
- 127.0.0.1:6379> SUNION zhangsan lisi//查询张三和李四的所有好友(并集)
- 1) "zhaoliu"
- 2) "ergou"
- 3) "wangwu"
- 4) "lisi"
- 5) "mazi"
- 127.0.0.1:6379> SISMEMBER zhangsan lisi //查询李四是否是张三的好友
- (integer) 1
- 127.0.0.1:6379> SISMEMBER lisi zhangsan //查询张三是否是李四的好友
- (integer) 0
- 127.0.0.1:6379> SREM zhangsan lisi //李四不再是张三的好友
- (integer) 1
- 127.0.0.1:6379> SMEMBERS zhangsan
- 1) "zhaoliu"
- 2) "wangwu"
温馨提示:做人不要和张三一样哦~ 拒接唱独角戏~
5 Redis命令-SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性(分数)对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF.ZINTER.ZUNION:求差集.交集.并集
由于方法数量较多,我们直接用一个小练习来熟悉这些方法~

首先,添加下列学生的元素 ZADD
- 127.0.0.1:6379> ZADD student 85 Jack 89 Lucy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles
- (integer) 7
得到以下结果: (默认是升序排序)

- 127.0.0.1:6379> ZREM student Tom //删除Tom同学
- (integer) 1
- 127.0.0.1:6379> ZSCORE student Amy //查询Amy的分数
- "92"
- 127.0.0.1:6379> ZRANK student Rose //查询Rose的排序,默认是升序,从0开始,所以下面的2表示倒三
- (integer) 2
- 127.0.0.1:6379> ZREVRAnk student Rose //使用降序查询,Rose的排名为第4
- (integer) 3
- 127.0.0.1:6379> ZCARD student //查询共有多少个学生
- (integer) 6
- 127.0.0.1:6379> ZCOUNT student 0 80 //查询0-80分的学生个数
- (integer) 2
- 127.0.0.1:6379> ZINCRBY student 2 Amy //给Amy同学的分数加2
- "94"
- 127.0.0.1:6379> ZRANGE student 0 2 //查询排名倒数后三名的同学,前三名用ZREVRANGE
- 1) "Miles"
- 2) "Jerry"
- 3) "Rose"
- 127.0.0.1:6379> ZRANGEBYSCORE student 0 80 //查询0-80分以内的学生
- 1) "Miles"
- 2) "Jerry"
-
-
相关阅读:
Java安全之深入了解SQL注入
【毕设专用开发模板】前后端分离,基于 Vue 和 SpringBoot 的通用管理系统
1141 PAT Ranking of Institutions
TLS及HTTP2.0指纹的修改实现
CSS 合法颜色值
【C++】C++的IO流
JavaScript/uni-app对接海康ISC openapi
Problem E: 4*4矩阵填充
java版Spring Cloud+Mybatis+Oauth2+分布式+微服务+实现工程管理系统
redis6.0引入多线程
- 原文地址:https://blog.csdn.net/qq_59212867/article/details/127911241
