-
python标准库之itertools
1. groupby
1.1 案例
先看一个例子
from itertools import groupby str = '42m偏差' ret = [''.join(list(g)) for k, g in groupby(str, key=lambda x: x.isdigit())] print(ret) # ['42', 'm偏差']- 1
- 2
- 3
- 4
- 5
- 6
- 7
例子
str = '42m偏差' for key, group in groupby(str): print(key, ' :', list(group)) print('------------------------------------') for key, group in groupby(str, key=lambda x: x.isdigit()): print(key, ' :', list(group)) print('------------------------------------') for key, group in groupby(str, key=lambda x: x.isdigit()): print(key, ' :', ''.join(list(group)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
4 : ['4'] 2 : ['2'] m : ['m'] 偏 : ['偏'] 差 : ['差'] ------------------------------------ True : ['4', '2'] False : ['m', '偏', '差'] ------------------------------------ True : 42 False : m偏差- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[k for k, g in groupby('150m', lambda x: x.isdigit())] Out[8]: [True, False] # 按[True, False]是否为数字进行分组 [k for k, g in groupby('150m')] Out[9]: ['1', '5', '0', 'm']- 1
- 2
- 3
- 4
# 无法拆分字母和汉字,只能将数字提取出来 [list(g) for k, g in groupby('100m水平0风向10', key=lambda x: x.isdigit())] Out[6]: [['1', '0', '0'], ['m', '水', '平'], ['0'], ['风', '向'], ['1', '0']] [''.join(list(g)) for k, g in groupby('100m水平0风向10', key=lambda x: x.isdigit())] Out[7]: ['100', 'm水平', '0', '风向', '10']- 1
- 2
- 3
- 4
- 5
- 6
1.2 原理
groupby()的作用就是
把可迭代对象中相邻的重复元素挑出来放一起,举个例子:for key, group in groupby('AAABBBCCAAA'): print(key, list(group))- 1
- 2
输出:
A ['A', 'A', 'A'] B ['B', 'B', 'B'] C ['C', 'C'] A ['A', 'A', 'A']- 1
- 2
- 3
- 4
其中变量
key表示的是重复元素,group是一个itertools._grouper类型的变量,也是个迭代对象,list(group)表示的是将迭代对象转化为列表。具体原理如下图所示:

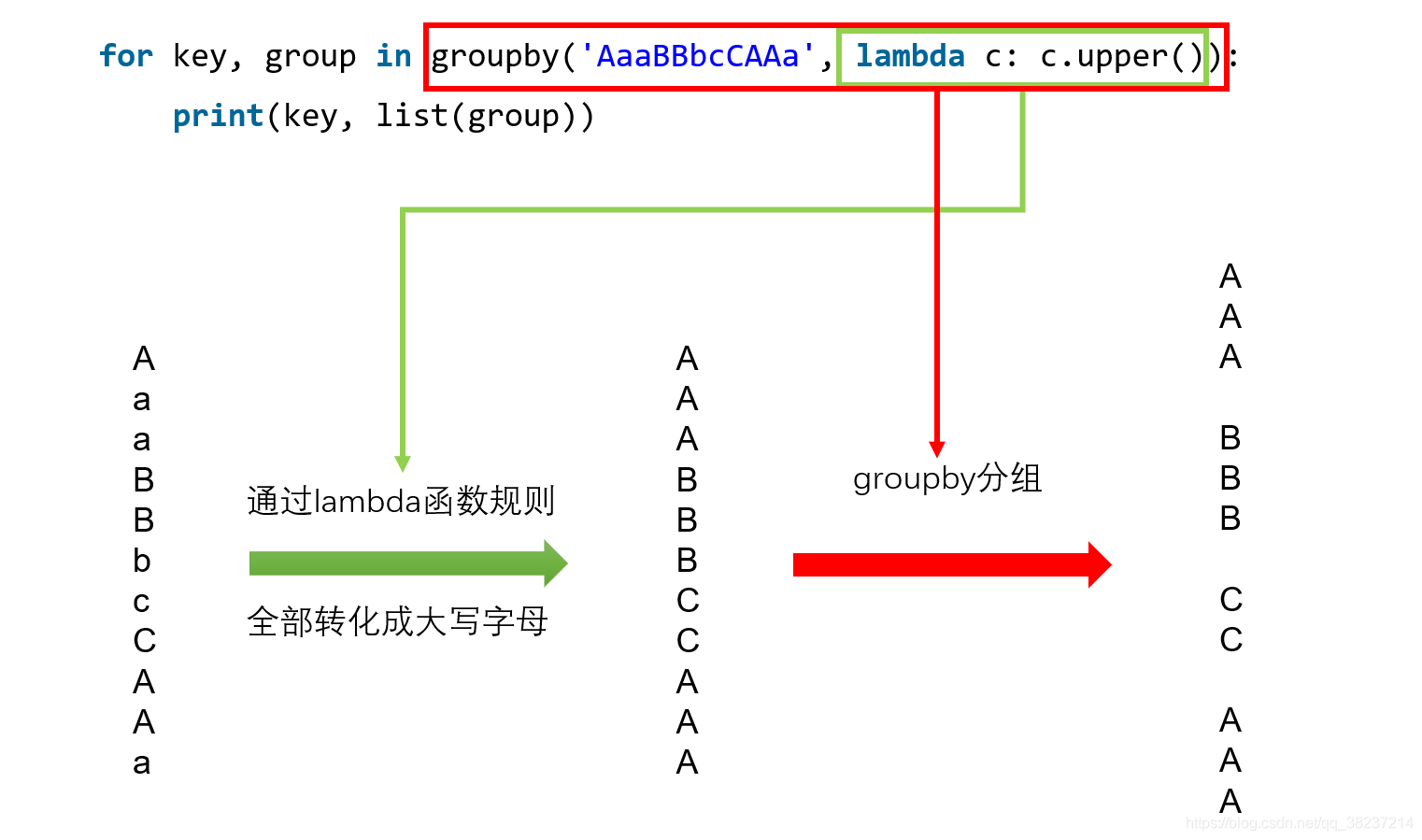
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果我们要忽略大小写分组,就可以让元素’A’和’a’都返回相同的key:for key, group in groupby('AaaBBbcCAAa', lambda c: c.upper()): print(key, list(group)) A ['A', 'a', 'a'] B ['B', 'B', 'b'] C ['c', 'C'] A ['A', 'A', 'a']- 1
- 2
- 3
- 4
- 5
- 6
- 7
具体原理如下图所示:
1.3 骚操作
有这么一个情形,要处理pandas.DataFrame表格数据,如下图所示,value 这一列有很多连续的空值,空值处理需求如下:
- 连续空值行数超过10次的行全部按行删掉;
- 连续空值行数小于等于10次的,则取上一个实数值和下一个实数值的均值来补全。
试问该怎么做?

答案:NUM_NAN = 10 nan_r, _ = np.where(np.isnan(df)) # 找到所有NaN的值位置,nan_r表示行标,占位符_表示列标 # 统计哪一块数据应该删除 nan_list = [] # 只收集连续空值超过NUM_NAN个数的行索引 fun = lambda x: x[1] - x[0] for k, g in groupby(enumerate(nan_r), fun): find_list = [j for i, j in g] # 连续数字的列表 if len(find_list) > NUM_NAN: # 时间连续的点超过NUM_NAN个就删掉 nan_list = nan_list + find_list # 存较大片的缺省值,进行删除 if len(nan_list) != 0: df = df.reset_index() df = df.drop(nan_list) df = df.set_index(df['time']) df = df.drop(['time'], axis=1) # 缺省值取前一行和后一行的均值 df = (df.fillna(method='backfill') + df.fillna(method='pad')) / 2 df.to_csv('test.csv')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.使用itertools.product()
它提供了一种称为
product的方法,该方法将所有元素配对。找到对后,我们可以过滤对。#导入模块 import itertools #初始化列表 list_1 = [1, 2, 3, 4, 5] list_2 = [5, 8, 7, 1, 3, 6] # 配对 pairs = itertools.product(list_1, list_2) print(pairs) #过滤配对 result = [pair for pair in pairs if pair[0] != pair[1]] print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果运行上面的代码,则将得到以下结果。
输出结果:Out[0]: <itertools.product at 0x20a19b0b980> # pairs Out[1]: [(1, 5), (1, 8), (1, 7), (1, 3), (1, 6), (2, 5), (2, 8), (2, 7), (2, 1), (2, 3), (2, 6), (3, 5), (3, 8), (3, 7), (3, 1), (3, 6), (4, 5), (4, 8), (4, 7), (4, 1), (4, 3), (4, 6), (5, 8), (5, 7), (5, 1), (5, 3), (5, 6)]- 1
- 2
- 3
- 4
- 5
3.itertools.combinations()
ws_list Out[1]: ['WS_150m_thies', 'WS_100m_thies', 'WS_30m_NRG'] ws_sum = list(itertools.combinations(ws_list, 2)) ws_sum Out[2]: [('WS_150m_thies', 'WS_100m_thies'), ('WS_150m_thies', 'WS_30m_NRG'), ('WS_100m_thies', 'WS_30m_NRG')]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
equal_ws = [57.5, 60, 80, 95, 110, 130, 150, 170, 190, 210, 222.5] a = map(lambda x,y: (x,y), equal_ws[0:-1],equal_ws[1::]) list(a) Out[30]: [(57.5, 60), (60, 80), (80, 95), (95, 110), (110, 130), (130, 150), (150, 170), (170, 190), (190, 210), (210, 222.5)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4. itertools.chain
二维数组降维1维数组
import numpy as np a = np.array([[1, 2], [3, 4], [9, 8]]) # 使用库函数 from itertools import chain a_a = list(chain.from_iterable(a)) print(a_a)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果为:[1, 2, 3, 4, 9, 8]
-
相关阅读:
DNS配置
每日一题 2258. 逃离火灾(手撕困难!!!)
单片机第三季-第一课:STM32基础
ubuntu20环境搭建+Qt6安装
Spring Boot如何实现统一异常处理呢?
观测云代金券使用后是否可以退换?
【操作系统】:操作系统概述
2022上海生物发酵展-品牌企业纷纷入驻抢占先机,谁来赴盛宴参邀您的参与
就以下数据怎么写代码弄成可视化数据,
【C++】二叉搜索树
- 原文地址:https://blog.csdn.net/weixin_46713695/article/details/127860355
