-
机器学习 —— 计算评估指标
计算评估指标
- 假设有100个数据样本,其中有正样本70个,负样本30个
- 现在模型查出有50个正样本,其中真正的正样本是30个
- 求:精确率precision,召回率recall, F1值,准确率Accuracy
TP = 30
FP = 20
TN = 10
FN = 40# 精确率(查准率)
precision = TP / (TP + FP) = 30 / 50 = 0.6
# 召回率(查全率)
recall = TP / (TP + FN) = 30 / 70 = 3/7
# F1值
f1 = (2 * precision * recall) / (precision + recall) = 0.5
# 准确率
accuracy = (TN + TP) / (TN + TP + FN + FP) = 0.4画ROC曲线 和 计算auc值
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn.datasets import load_iris
- data,target = load_iris(return_X_y=True)
- # 二分类
- target2 = target[0:100].copy()
- data2 = data[:100].copy()
使用LR模型
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import train_test_split
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import train_test_split
- x_train,x_test,y_train,y_test = train_test_split(data2,target2,test_size=0.2)
- lr = LogisticRegression()
- lr.fit(x_train,y_train)
- # 预测
- y_pred = lr.predict(x_test)
- y_pred
- # array([0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1])
- # ROC
- # metrics:评估
- from sklearn.metrics import roc_curve,auc
ROC 曲线
- # y_true:真是结果
- # y_score:预测结果
- fpr,tpr,_ = roc_curve(y_test,y_pred) # 返回值:fpr,tpr,thresholds
- # fpr:伪阳率
- # tpr:真阳率
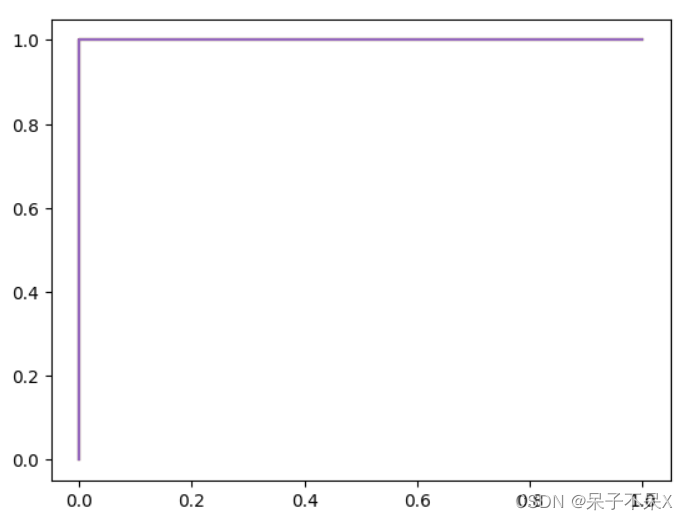
- display(fpr,tpr)
- '''
- array([0., 0., 1.])
- array([0., 1., 1.])
- '''
- plt.plot(fpr,tpr)

auc
- auc(fpr,tpr)
- # 1.0
使用交叉验证来计算auc值,平均auc值
- from sklearn.model_selection import KFold, StratifiedKFold
- from sklearn.model_selection import KFold, StratifiedKFold
- skf = StratifiedKFold()
- data2.shape
- # (100, 4)
- list(skf.split(data2,target2))
- '''
- [(array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
- 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43,
- 44, 45, 46, 47, 48, 49, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70,
- 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87,
- 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]),
- array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 50, 51, 52, 53, 54, 55, 56,
- 57, 58, 59])),
- (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 20, 21, 22, 23, 24, 25, 26,
- 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43,
- 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 70,
- 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87,
- 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]),
- array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 60, 61, 62, 63, 64, 65, 66,
- 67, 68, 69])),
- (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
- 17, 18, 19, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43,
- 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
- 61, 62, 63, 64, 65, 66, 67, 68, 69, 80, 81, 82, 83, 84, 85, 86, 87,
- 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]),
- array([20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 70, 71, 72, 73, 74, 75, 76,
- 77, 78, 79])),
- (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
- 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 40, 41, 42, 43,
- 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
- 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
- 78, 79, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]),
- array([30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 80, 81, 82, 83, 84, 85, 86,
- 87, 88, 89])),
- (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
- 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
- 34, 35, 36, 37, 38, 39, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
- 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
- 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89]),
- array([40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 90, 91, 92, 93, 94, 95, 96,
- 97, 98, 99]))]
- '''
- for train,test in skf.split(data2,target2):
- x_train = data2[train]
- y_train = target2[train]
- x_test = data2[test]
- y_test = target2[test]
- # LR
- lr = LogisticRegression()
- lr.fit(x_train,y_train)
- y_pred = lr.predict(x_test)
- # roc
- fpr,tpr,_ = roc_curve(y_test,y_pred)
- plt.plot(fpr,tpr)
- print(auc(fpr,tpr))
- '''
- 1.0
- 1.0
- 1.0
- 1.0
- 1.0
- '''
添加噪声
- 给data2添加500列随机值
- data2.shape
- # (100, 4)
- data3 = np.random.randn(100,500)
- data3.shape
- # (100, 500)
- # 左右拼接:水平拼接
- data4 = np.hstack((data2,data3))
- data4.shape
- # (100, 504)
- skf = StratifiedKFold()
- auc_list = []
- for train,test in skf.split(data4,target2):
- x_train = data4[train]
- y_train = target2[train]
- x_test = data4[test]
- y_test = target2[test]
- # LR
- lr = LogisticRegression()
- lr.fit(x_train,y_train)
- # 预测
- # y_pred = lr.predict(x_test)
- # 预测概率
- y_proba = lr.predict_proba(x_test)
- print('y_proba:',y_proba)
- # roc
- fpr,tpr,_ = roc_curve(y_test,y_proba[:,1])
- # 画图
- plt.plot(fpr,tpr)
- print('fpr:',fpr)
- print('tpr:',tpr)
- print('auc:',auc(fpr,tpr))
- print('*'*100)
- auc_list.append(auc(fpr,tpr))
- # 平均 auc
- np.array(auc_list).mean()
- '''
- y_proba: [[0.3267921 0.6732079 ]
- [0.96683557 0.03316443]
- [0.77520064 0.22479936]
- [0.65359444 0.34640556]
- [0.28117064 0.71882936]
- [0.51257663 0.48742337]
- [0.89757814 0.10242186]
- [0.70565166 0.29434834]
- [0.95428978 0.04571022]
- [0.79620831 0.20379169]
- [0.11122497 0.88877503]
- [0.14503562 0.85496438]
- [0.09769969 0.90230031]
- [0.1427527 0.8572473 ]
- [0.64864805 0.35135195]
- [0.77964905 0.22035095]
- [0.50532259 0.49467741]
- [0.88917687 0.11082313]
- [0.20508718 0.79491282]
- [0.22918407 0.77081593]]
- fpr: [0. 0. 0. 0.2 0.2 0.3 0.3 0.6 0.6 0.7 0.7 1. ]
- tpr: [0. 0.1 0.6 0.6 0.7 0.7 0.8 0.8 0.9 0.9 1. 1. ]
- auc: 0.82
- ****************************************************************************************************
- y_proba: [[0.81694936 0.18305064]
- [0.58068561 0.41931439]
- [0.95133392 0.04866608]
- [0.40420908 0.59579092]
- [0.3271581 0.6728419 ]
- [0.99027305 0.00972695]
- [0.64918216 0.35081784]
- [0.90200046 0.09799954]
- [0.63054898 0.36945102]
- [0.93316453 0.06683547]
- [0.53006938 0.46993062]
- [0.17861305 0.82138695]
- [0.006705 0.993295 ]
- [0.09477154 0.90522846]
- [0.56917531 0.43082469]
- [0.03227622 0.96772378]
- [0.22280499 0.77719501]
- [0.15966529 0.84033471]
- [0.02610573 0.97389427]
- [0.01608401 0.98391599]]
- fpr: [0. 0. 0. 0.2 0.2 1. ]
- tpr: [0. 0.1 0.8 0.8 1. 1. ]
- auc: 0.9600000000000001
- ****************************************************************************************************
- y_proba: [[0.73755142 0.26244858]
- [0.81486985 0.18513015]
- [0.98155993 0.01844007]
- [0.62469409 0.37530591]
- [0.86580681 0.13419319]
- [0.93865476 0.06134524]
- [0.76684129 0.23315871]
- [0.26828926 0.73171074]
- [0.95379293 0.04620707]
- [0.82872899 0.17127101]
- [0.0450968 0.9549032 ]
- [0.4752642 0.5247358 ]
- [0.38068224 0.61931776]
- [0.56844634 0.43155366]
- [0.49825931 0.50174069]
- [0.05526257 0.94473743]
- [0.04108483 0.95891517]
- [0.00417408 0.99582592]
- [0.09069155 0.90930845]
- [0.42708884 0.57291116]]
- fpr: [0. 0. 0. 0.1 0.1 1. ]
- tpr: [0. 0.1 0.5 0.5 1. 1. ]
- auc: 0.9500000000000001
- ****************************************************************************************************
- y_proba: [[0.89441894 0.10558106]
- [0.65744045 0.34255955]
- [0.67092317 0.32907683]
- [0.78029511 0.21970489]
- [0.69217484 0.30782516]
- [0.97861482 0.02138518]
- [0.711046 0.288954 ]
- [0.94908913 0.05091087]
- [0.62170149 0.37829851]
- [0.57082372 0.42917628]
- [0.59759391 0.40240609]
- [0.53269573 0.46730427]
- [0.08361238 0.91638762]
- [0.3546565 0.6453435 ]
- [0.13494363 0.86505637]
- [0.01205661 0.98794339]
- [0.04489417 0.95510583]
- [0.57049956 0.42950044]
- [0.3636283 0.6363717 ]
- [0.13165516 0.86834484]]
- fpr: [0. 0. 0. 0.1 0.1 1. ]
- tpr: [0. 0.1 0.9 0.9 1. 1. ]
- auc: 0.99
- ****************************************************************************************************
- y_proba: [[0.85161531 0.14838469]
- [0.9726683 0.0273317 ]
- [0.53251231 0.46748769]
- [0.72269431 0.27730569]
- [0.87414963 0.12585037]
- [0.79130481 0.20869519]
- [0.98550565 0.01449435]
- [0.56034861 0.43965139]
- [0.55647585 0.44352415]
- [0.72393126 0.27606874]
- [0.03734951 0.96265049]
- [0.16550755 0.83449245]
- [0.28703024 0.71296976]
- [0.1594562 0.8405438 ]
- [0.07379419 0.92620581]
- [0.48656743 0.51343257]
- [0.3818963 0.6181037 ]
- [0.23117614 0.76882386]
- [0.4644294 0.5355706 ]
- [0.46337177 0.53662823]]
- fpr: [0. 0. 0. 1.]
- tpr: [0. 0.1 1. 1. ]
- auc: 1.0
- ****************************************************************************************************
- 0.944
- '''

线性插值
- x = np.linspace(0,10,30)
- y = np.sin(x)
- plt.scatter(x,y)

- x2 = np.linspace(0,10,100)
- # interp:线性插值
- # 让 x2,y2 之间的关系和 x,y之间的关系一样
- y2 = np.interp(x2,x,y)
- plt.scatter(x,y)
- plt.scatter(x2,y2,marker='*')

计算平均AUC值,和平均ROC曲线
- auc <= 0.5 : 模型很差
- auc > 0.6 : 模型一般
- auc > 0.7 : 模型还可以
- auc > 0.8 : 模型较好
- auc > 0.9 : 模型非常好
- # 算平均AUC值
- np.array(auc_list).mean()
- # 0.944
- # 相当于 x 轴
- fprs = np.linspace(0,1,101)
- tprs_list = []
- auc_list = []
- for train,test in skf.split(data4,target2):
- x_train = data4[train]
- y_train = target2[train]
- x_test = data4[test]
- y_test = target2[test]
- # LR
- lr = LogisticRegression()
- lr.fit(x_train,y_train)
- # 预测
- # y_pred = lr.predict(x_test)
- # 预测概率
- y_proba = lr.predict_proba(x_test)
- # roc
- fpr,tpr,_ = roc_curve(y_test,y_proba[:,1])
- auc_ = auc(fpr,tpr)
- auc_list.append(auc_)
- # 画图
- plt.plot(fpr,tpr,ls='--',label=f'auc:{np.round(auc_,2)}')
- # 线性插值
- # 让 fprs 与 tprs 的关系和 fpr 与 tpr 的关系一样
- tprs = np.interp(fprs,fpr,tpr)
- tprs_list.append(tprs)
- # 平均 tprs
- tprs_mean = np.array(tprs_list).mean(axis=0)
- auc_mean = np.array(auc_list).mean()
- # 画平均ROC图
- plt.plot(fprs,tprs_mean,label=f'auc_mean:{np.round(auc_mean,2)}')

-
相关阅读:
Android /android_vendor.32_arm64_armv8-a_shared/libtinyals a.so.abidiff报错
【前端面试常问】MVC与MVVM
(209)Verilog HDL:设计一个电路之Rule 90
STM32F103C8/BT6 USART1 DMA发送失败
【PAT】数据结构树和图月考复习1
鸿蒙项目实战-月木学途:1.编写首页,包括搜索栏、轮播图、宫格
elasticsearch 安装教程
shardingsphere分库分表示例(逻辑表,真实表,绑定表,广播表,单表)
面试十三、malloc 、calloc、realloc以及new的区别
关于类的继承
- 原文地址:https://blog.csdn.net/qq_52421831/article/details/127849837
