-
Curve 文件系统的重要特点之一就是适用于海量文件存储
如何支撑百亿级文件
Curve 文件系统的重要特点之一就是适用于海量文件存储,那么 Curve 文件系统如何保证可以支撑百亿级规模?如何保证在百亿级规模下的性能?从理论上来看:
-
规模方面,Curve 文件存储的元数据集群,每个节点存储一定范围的 inode (比如 1~10000) 和 dentry,如果文件数量增多,可以进行存储节点的扩充,所以理论上规模是没有上限的。
-
性能方面,当文件数量很多时,对于单个文件的操作是没有什么差别的,但对于一些需要元数据的聚合操作会出现性能问题,比如 du (计算当前文件系统的容量), ls (获取目录下所有文件信息) 等操作,需要做一定的优化来保障性能。
海量文件存储下性能如何
Curve 文件存储随着存量数据增长,性能可以相对保持平稳(stat 请求的下降在 15% 左右)。
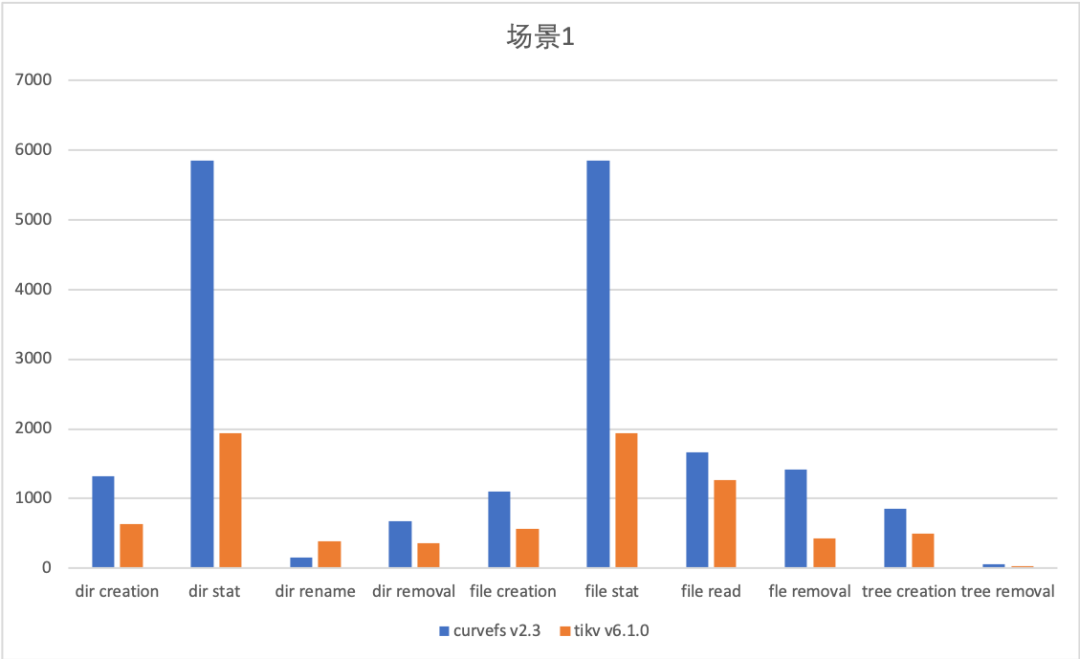
场景 1 (测试目录个数较多的情况):
测试命令 mdtest -z 2 -b 3 -I 10000 -d /mountpoint
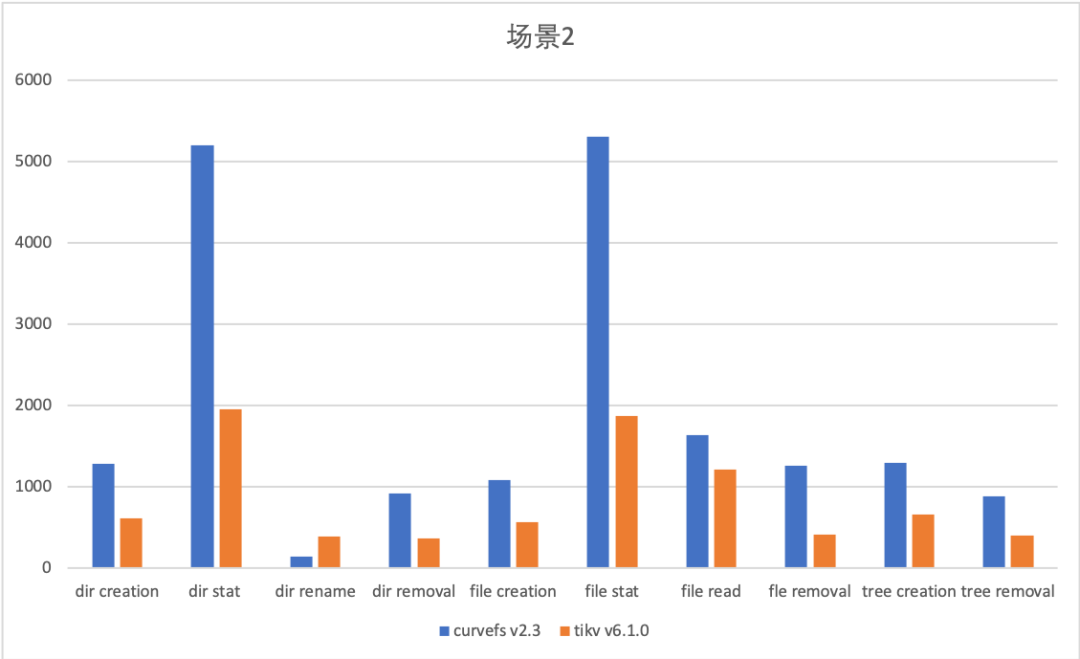
场景 2 (测试目录层级很深的情况):
测试命令 mdtest -z 10 -b 2 -I 100 -d /mountpoint


Curve 文件存储当前使用元数据集群,相对于使用分布式 kv 存储(如 TiKV)性能较优。
说明:本组测试打开了 fuseClient.enableMultiMountPointRename ,保证多挂载点 rename 的事务性,所以和上组的基础测试数据有偏差。
场景 1 (测试目录个数较多的情况):
测试命令 mdtest -z 2 -b 3 -I 10000 -d /mountpoint
场景 2 (测试目录层级很深的情况):
测试命令 mdtest -z 10 -b 2 -I 100 -d /mountpoint
当前,Curve 文件存储已经在 ES、AI 场景落地,后续会有相应的案例分享给大家。
< 原创作者:李小翠,Curve Maintainer>
-
-
相关阅读:
mermaid_starter简单使用/渲染问题和调整
ThreadPoolExecutor
如何解决4G摄像头在智能巡检中掉线的方案
行为型模式-观察者模式
遥感云计算的一个拐点
安卓APP(1)——安卓工程构建和第一APP运行
经纬度转笛卡尔坐标
模块如何访问内核子系统VFS的某个static链表变量?
数据加密标准(DES)的C++语言描述实现
Python 无废话-办公自动化Excel修改数据
- 原文地址:https://blog.csdn.net/zcypaicom/article/details/127819083