-
【javaEE初阶】文件操作和IO
前言
今天不学习,明天变垃圾!本文主要内容:字节流、字符流的输入输出,文件的基本操作及文件内容读写操作(有练习题!)。
一、文件操作
1. 文件
-
狭义的文件:存储在硬盘上的数据,以“文件”为单位进行组织。
1)常见的就是平时的文件,如文本文件、图片、office系列、视频、音频、可执行程序等
2)文件夹也叫做“目录”,是一种特殊的文件。
3)硬盘的特点:
① 硬盘存储空间大,内存存储空间小
② 硬盘访问速度慢,内存访问速度快,可以差3-4个数量级
③ 硬盘的成本比较低,内存的成本比较高
④ 硬盘上的数据断电不会丢失,内存上的数据断电会丢失(也就是“持久化”的问题)
4)【ps: 操作系统都有“交换文件”操作,内存不够的时候就会往硬盘上写数据,使用硬盘来代偿内存(也就是让程序慢点,但是不会崩溃)】
5)(ps:台式机加内存一般好加,但是换CPU一般不好换,因为CPU是和主板适配的,换CPU很可能就一起换主板;主板又是和硬盘/内存都是适配的,一部小心就全换了。
笔记本一般是没法升级硬件的,因为笔记本厂商给的扩展性是非常低的) -
广义的文件
操作系统是要负责管理软硬件资源的,操作系统(如:Linux、Unix)往往就会把这些资源都统一成抽象的“文件”来进行管理。也就是“一切皆文件”的思想。
2. 路径
- 目录结构,是计算机中的“基本常识”,其构成一个N叉树。
- 通过“路径”概念来描述一个文件在电脑上的具体位置。分为“绝对路径”和“相对路径”。
1)绝对路径:从根目录开始。
(如:D:\WeChat\WeChat.exe D: 表示盘符,每个\分割的部分都是目录)
注:目录之间的分隔符,可以使用\(反斜杠),也可以使用/(斜杠)——这只是针对Windows系统,但是其默认还是使用反斜杆\。
对于Linux等系统,只支持斜杠/(但是在我们自己写代码的时候,建议使用斜杠/表示路径)
(ps:注意区分内存和外存)2)相对路径:(从当前目录开始。)首先得有一个“基准路径”,也叫“工作路径”。相对路径就是以基准路径为起点,往下继续咋走才能到达目标的路径表示方式。
在相对路径中使用.表示“当前目录”。
如:D:\Navicat\Navicat for MySQL\navicat.exe 是绝对路径,而如果基准路径是D:\Navicat,那么相对路径就是:.\Navicat for MySQL\navicat.exe- 相对路径中使用 . . 返回上级目录( . . 表示当前目录的上级路径)
如:当前的工作路径是:D:/program/Wechat/Bin,所要找的文件的绝对路径是D:/program/qq/Bin/QQ.exe,则使用相对路径该怎么找呢?
. ./ ->返回当前路径D:/program/Wechat/Bin的上一级路径D:/program/Wechat ;此时还是不行,再进行
. ./ -> 返回当前路径D:/program/Wechat的上一级路径D:/program
此时已经可以开始继续向下查找了,所以最后的相对路径就是: . ./. ./qq/Bin/QQ.exe谈到相对路径,务必要明确工作目录/基准目录是啥。
Windows下是无法通过. .来到“此电脑”这一级的,也就是盘之间没法使用. .切换;但是Linux下没有盘符的概念,也就不涉及这个问题。 Windows上盘之间的切换是通过直接输入盘符来改变的,如D:
-
如何确定工作目录是啥?(几种常见情况)
① 如果是通过命令行来执行程序,此时当前命令所在的目录就是工作目录
② 如果是使用IDEA来执行Java程序,此时的工作目录就是IDEA打开的项目的目录
③ 如果是使用TomCat来运行一个war包,工作目录就是TomCat的bin目录 -
实际开发中以相对路径为主,很少使用绝对路径,绝对路径可能导致程序在不同主机上无法正常运行,因为找不到文件。
-
文件操作是属于操作系统层面提供的一些API,不同的操作系统提供的API是不一样的。
-
Java作为一个跨平台的语言,为了统一代码,就在JVM中把不同系统的操作文件的API进行了封装;java就可以使用java中的库的代码来操作文件了。
3. 补充
- 即使是普通文件,根据其保存数据的不同,也经常被分为不同的类型,我们一般简单的划分为文本文件和二进制文件,分别指代保存被字符集编码的文本和按照标准格式保存的非被字符集编码过的文件。
- 文件由于被操作系统进行了管理,所以根据不同的用户会赋予用户不同的对待该文件的权限,一般地可以认为有可读、可写、可执行权限。
- Windows 操作系统上,还有一类文件比较特殊,就是平时我们看到的快捷方式(shortcut),这种文件只是对真实文件的一种引用而已。其他操作系统上也有类似的概念,例如,软链接(soft link)等。
二、文件操作相关类/方法
1.File类
- 在java.io中(IO是输入输出的意思,输入输出是以CPU/内存 为中心的)
- File的常见属性:

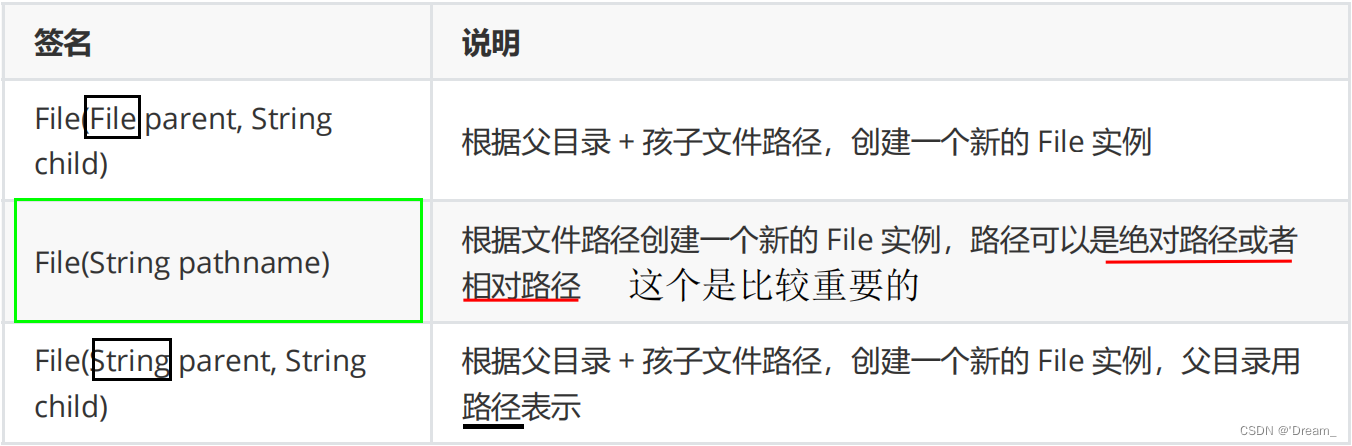
- File的构造方法
- File相关方法

- 以上的方法/操作,主要都是在操作“文件系统”,而不是针对文件内容的操作。
(“文件系统”是操作系统中管理文件的核心功能。) - 方法/操作就是如:新增文件、删除文件、新增目录、列出目录内容、重命名、获取路径…
- 方法的使用
(参考代码:Demo1-6)
- IOException:IO中常见的异常。
- 注意字符串数组打印方法:Arrays.toString(字符串数组名)
- 文件类型是啥?
——准确来说,文件类型是与文件内部的数据格式相关联的,与文件的后缀名无关。 - 针对文件内容操作,涉及到的关键操作是:读文件和写文件。
- 注:删除目录也用delete
三、文件内容的读写:流(stream)
- 把读写文件操作比喻成“水流”,接水的时候可以灵活分次数来接水。
- Java标准库就在“流”的概念上提供了一组类,以此来完成文件的操作。
这一组类按照不同的特点再进行细分:
① 字节流:以字节为基本单位,适用于二进制文件:
(父类)InputStream、OutputStream
② 字符流:以字符为基本单位,适用于文本文件:
(父类)Reader、Writer
标准库中给这些父类提供了各种子类的实现来适应不同场景下的读写
子类举例:
① InputStream的子类:FileInputStream
② OutputStream的子类 FileOutputStream
③ Reader的子类:FileReader
④ Writer的子类:FileWriter1. InputStream
-
InputStream是一个抽象类,不能实例化。
-
要想读写文件,就要在操作之前打开文件(创建实例),操作结束之后关闭文件(close)。
-
一定要关闭文件!否则可能会造成资源泄露,导致后续打不开该文件。
-
InputStream的相关方法:

-
FileInputStream的构造方法:

-
参考代码:Demo7字节流
2. OutputStream
- OutputStream写文件write的时候,只要打开文件成功,原来文件中的内容就会被清空!
(写入:同样是清空原文件的内容后重新写入!) - OutputStream方法

- OutputStream 同样只是一个抽象类,要使用还需要具体的实现类。我们现在还是只关心写入文件中,所以使用 FileOutputStream。
- 参考代码:字节流
3. 字符流文件的操作
-
字符流文件的读取:Reader、Scanner, 字符流文件的写入:Writer、PrintWriter。
-
针对文本文件,使用字符流的时候,其实还可以使用Scanner进行读取。
-
进行文件操作的时候,必须要进行close!
理由:1)每个进程都对应着PCB(可能是多个),PCB里面有一个字段叫“文件描述符表”(同一个进程里多个PCB共同使用同一份文件描述符表)。
2)“文件描述符表”就相当于是一个数组/顺序表,进程每次打开一个文件就会在该表中创建一个项,这个项就表示一个文件。如果关闭文件,就会将表里对应的项给释放掉;如果不关闭,意味着这个表项就一直在该表中占着位置;如果是持续打开文件且从不进行关闭,此时表项就会被耗尽(因为存储的最大长度是有上限的),导致后续再打开文件就会打开失败。——这种行为称为:文件资源泄露,这是一个非常严重的问题,比程序崩溃还严重。 -
补充:JVM是有自动释放的策略的:对应的流对象如果被GC销毁了,是会关闭对应的文件(释放文件描述符表的元素/表项)。但是“对应的流对象被GC销毁”是不一定会发生的,如果我们写的代码有问题,但仍然保持了流对象的引用,此时就不会触发GC,文件就始终保持打开的状态,文件描述符表中的表项也不会被释放。
-
客户端一般不怕资源泄露问题,因为客户端一般运行一段时间后就会关闭;
服务器端是害怕资源泄露问题的,因为服务器要长期运行。
(ps. 建议使用hasNext与next,而不是hasNextLine与nextLine,后面这两个方法有很多坑)
- 参考代码:Demo9-12字符流
如何确保文件一定执行到close呢?
① 使用try…finally {file.close(); }
② 使用 try with resources:把要关闭的对象写到try()中(也就是说直接在()中new实例对象!),当try结束后就会自动调用到对应对象的close方法!而且支持一个()中放多个对象, 多个对象的创建之间使用分号; 进行分割就ok了。
四、小程序练习
- 扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件。
思路:
① 先让用户输入:要扫描的路径+你要查找的词/指定字符
② 遍历目录,找到名字匹配的文件遍历目录需要借助核心方法listFiles():能够把当前目录里的文件和子目录列举出来,但是这个方法只能列出一层,没法列出子目录中的内容。
解决方法:遍历listFiles的结果,针对每个元素进行判定,看它是一个普通文件还是一个目录,如果是普通文件就直接判定是否包含了要查的关键词,如果是目录就递归的调用listFiles。
(目录结构本质上是“树”,树的遍历使用递归) ③ 询问用户是否删除
注意:String类型比较相等如果使用==,则会一直false,因为String是引用类型,会new对象,比较的是地址!!
引用类型比较大小使用equals!!- 进行普通文件的复制
思路:
把第一个文件打开,将里面的内容逐个字节的读取出来写到第二个文件中即可。
“逐个字节”就是要使用字节流来进行操作,字节流是可以用来拷贝文本文件的。
① 输入源文件、目标文件 + 判断是否存在该文件(路径是否正确)② 源文件按字节读出InputStream,目标文件按字节写入OutStream
try with resources的使用,可以在try之后自动关闭文件(此时针对的是两个对象)- 扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
注意:我们现在的方案性能较差,所以尽量不要在太复杂的目录下或者大文件下实验 (低性能)
逻辑:
① 输入扫描的路径和要查询的关键词 + 判断文件是否存在
② 递归的扫描目录
③查看是否包含关键字:
检查文件名中是否包含关键字;
检查内容中是否包含关键字(读取内容InputStream:同样使用try with source 避免忘记close文件—打开文件之后使用Scanner进行读文件:按行读取)
(注意:StringBuilder的拼接+按行读取+使用indexOf判定关键词是否存在!)参考代码:Demo1-3
五、补充
- 如果发现PrintWriter无法写入数据,大概率原因是没有调用flush来刷新缓冲区。
- 缓冲区其实就是一个“内存空间”,而文件是在硬盘上的,写文件其实就是在写硬盘,但是写硬盘是一个低效的操作;所以就借助缓冲区来减少写硬盘的开销。
- 啥时候会把内存缓冲区的数据写入到硬盘中呢?
① 缓冲区满了
② 没满但是可以手动刷新 flush
③ 其他情况(此处不做过多讨论)
缓冲区buffer 和缓存cache是不一样的。
- 啥是cache(高速缓存)?
① 广义:有些计算比较复杂、比较耗时,此时为了提高速度、减少计算次数就可以把重复的结果记录下来(本质上也就是记录了中间结果),用于记录中间结果的数据结构就是cache。
② 狭义:
动态规划中经常会保存中间结果,此时可以视为是cache;
计组中,CPU里面也是有一些“缓存”这样的硬件设备,也是cache;
写一些数据的时候,比如读取mysql成了性能瓶颈,就可以使用内存把一些常用的数据保存起来,降低读取mysql的次数,这个内存(此时的“内存”可以自己写,也可以使用redis)也相当于是cache。
THINK
- 字节流:InputStream(read)、OutputStream(write)
- 字符流:Reader、Scanner, Writer、PrintWriter
- 文件一定要close(try with resourses)!!!
- 小程序练习重要!!!
- listFiles、递归、StringBuilder拼接+按行读取+indexOf判定是否存在key、判定文件/目录
-
-
相关阅读:
【Python】环境搭建详细过程
C#【必备技能篇】Release下的pdb文件有什么用,是否可以删除?
不好意思,Nginx 该换了!
php后台接口异步操作的实践
css 文字溢出问题
小熊听书项目的测试
【C++笔试强训】第五天
TC3-Vision应用笔记
简单说说ConcurrentHashMap的结构和实现
【嵌入式开源库】cJSON的使用,高效精简的json解析库
- 原文地址:https://blog.csdn.net/weixin_54150521/article/details/127810986