-
FastDFS文件上传原理和负载均衡方法
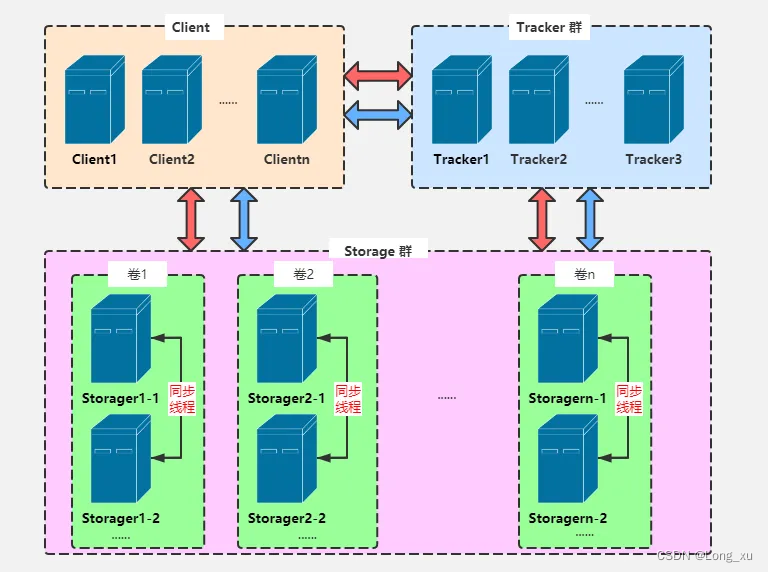
一、文件上传原理

1.1、选择tracker server
高可用,通过冗余的方式提供服务。当集群中不止一个tracker服务时,由于tracker之间是对等的关系,客户端在上传文件时可以任意选择一个tracker。
1.2、选择存储的group及其负载均衡算法
当tracker接收到上传文件的请求时,会为该文件分配一个可以存储该文件的group,支持如下选择group的规则:
(1)Round robin,所有的group间轮询。
(2)Specified group,指定某一个确定的group。
(3) Load balance,选择最大剩余空 间的组上传文件 。1.3、选择storage server及其负载均衡算法
当选定group后,tracker会在group内选择一个storage server给客户端,支持如下选择storage的规则:
- Round robin,在group内的所有storage间轮询。
- First server ordered by ip,按IP排序,也会轮询。
- First server ordered by priority,按优先级排序(优先级在storage上配置);可以理解为权重的方式,权重高的优先选择。比如,storage 1 为100M的带宽和storage 2为500M带宽,上传文件时优先使用500M带宽的storage。
1.4、选择storage path及其负载均衡算法
当分配好storage server后,客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录,支持如下规则:
(1) Round robin,多个存储目录间轮询。
(2)剩余存储空间最多的优先。可以配置多个磁盘路径。注意,同一个group中的storage的配置必须是一样的;这里的一样不是路径一样,而是path的数量要一致。多个路径对应多个磁盘,才能发挥多个磁盘并发读写能力。
# store path (disk or mount point) count, default value is 1store_path_count = 1 #存储路径(磁盘或挂载点)计数,默认值为1 store_path_count=1 # store_path#, based on 0, to configure the store paths to store filesif store_path0 not exists, it' s value is base_path (NOTrecommended)#the paths must be exist. #store_path#,基于0,要配置存储路径来存储filesif store_path 0不存在,它的值是base_path(NOT推荐的)#这些路径必须存在。 # # #工IMPORTANTNOTE:# #工IMPORTANTNOTE: #the store paths' order is very important, don 't mess up ! !! #store路径的排序很重要,不要搞砸了! # # the base_path should be independent (different) of the store paths # 基路径应该独立于存储路径(不同) store_path0 = /home/fastdfs/storage_group1_23000 #store_path1 = / home/yuqing/fastdfs2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
fastdfs适合小文件存储,大文件存储建议使用ceph。如果使用fastdfs存储大文件,那么是一个磁盘分摊写压力;而ceph的集群可以使用多台服务分摊写压力,写的速度会非常快。
1.5、生成Fileid
选定存储目录之后,storage会为文件生一个Fileid,由 storage server ip、文件创建时间、文件大小、文件crc32、一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。
4 bytes 4 bytes 8 bytes 4 bytes 2 bytes +--------+--------+----------------+--------+-----+ | IP | time | file_size | crc32 |校验值|- 1
- 2
- 3
- 4
1.5.1、选择两级目录
当选定存储目录之后,storage会为文件分配一个fileid,每个存储目录下有两级256*256的子目录,storage会路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。
1.5.2、生成文件名
当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由:group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

文件名规则:- storage_id,(ip的数值型)源storage server ID或IP地址。
- timestamp,文件创建时间戳。
- file_size,若原始值为32位则前面加入一个随机值填充,最终为64位。
- crc32,文件内容的检验码。
- 随机数 ,引入随机数的目的是防止生成重名文件。
eBuDxWCb2qmAQ89yAAAAKeR1iIo162 | 4bytes | 4bytes | 8bytes |4bytes | 2bytes | | ip | timestamp | file_size |crc32 | 校验值 |- 1
- 2
- 3
二、下载文件逻辑
客户端upload file成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。

跟upload file一样,在download file时客户端可以选择任意tracker server。
client发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到这样的storage,tracker按照如下规则选择group内可读的storage:
- 该文件上传到的源头storage, 源头storage只要存活着,肯定包含这个文件,源头的地址被编码在文件名中。
- 文件创建时间戳一定是storage被同步到的时间戳 且(当前时间-文件创建时间戳) > 文件同步最大时间(如5分钟) ,文件创建后,认为经过最大同步时间后,肯定已经同步到其他storage了。
- 文件创建时间戳 < storage被同步到的时间戳。 同步时间戳之前的文件确定已经同步了。
- (当前时间-文件创建时间戳) > 同步延迟阀值(如一天)。 经过同步延迟阈值时间,认为文件肯定已经同步了。
思考:fastdfs上传完文件后立即读取文件问题。因为fastdfs是弱一致性,可能其他storage还没有同步文件,这时应该怎么判断从哪个storage中读取文件?
可以根据时间来读取,因为fileid里有携带时间戳,可以根据时间进行匹配来进入storage ;如果某个storage没有同步
总结
上传文件逻辑:
下载文件逻辑:

-
相关阅读:
java-net-php-python-SSM城市管理综合执法系统计算机毕业设计程序
基于Qt的Model-View显示树形数据
Linux ARM平台开发系列讲解(调试篇) 1.3.2 RK3399移植Ubuntu文件系统步骤
【Javascript】编写⼀个函数,排列任意元素个数的数字数组,按从⼩到⼤顺序输出
java基于springboot+vue的二手车信息网站系统
PyTorch 中的乘法:mul()、multiply()、matmul()、mm()、mv()、dot()
Json对象
Mysql内置函数
微软想通了?Windows 11恢复一键改变默认浏览器功能
自学JavaScript第一天- JS 基础
- 原文地址:https://blog.csdn.net/Long_xu/article/details/127800867
