-
【JAVA】基础语法
【JAVA】基础语法
JAVA面向对象三大特征:封装、继承、多态
1 类型转换
1.1 自动类型转换
自动类型转换:类型范围小的变量,可以直接赋值给类型范围大的变量。
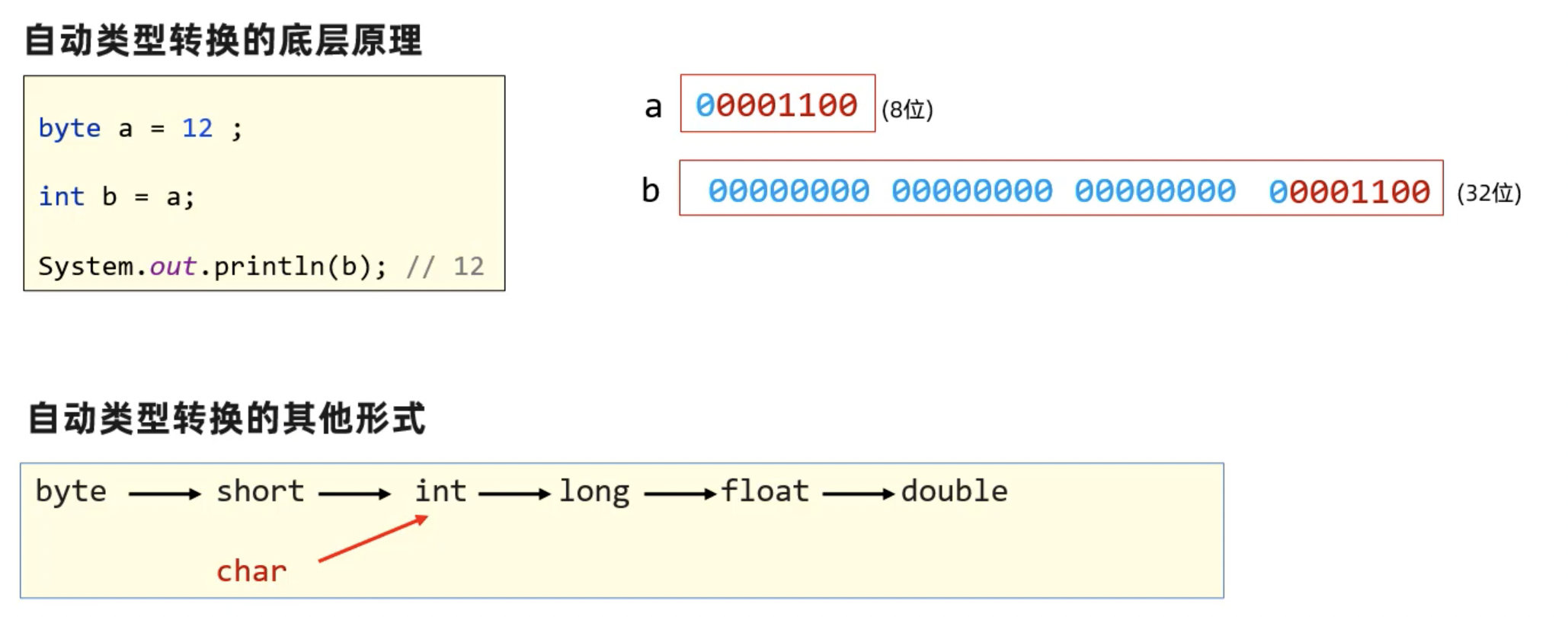
1.2 表达式的自动类型转换
在表达式中,小范围类型的变量会自动转换成当前较大范围的类型再运算。表达式的最终结果类型由表达式中的最高类型决定。

Note:在表达式中,
byte,short,char是直接转换成int类型参与运算。1.3 强制类型转换
当需要把大范围变量赋值给小范围变量时,需要使用强制类型转换。
Note:
- 强制类型转换可能会导致数据丢失(溢出);
- 浮点型强转为整型,直接丢掉小数部分,保留整数部分返回。
2 数组
2.1 数组的静态初始化
数组的静态初始化写法:
// 完整写法 int[] ages = new int[]{ 1, 2, 3}; double[] agess = new double[]{ 1.0, 2.0, 3.0}; // 简化写法 int[] ages = { 1, 2, 3}; double[] agess = { 1.0, 2.0, 3.0};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
数组变量名中存储的是数组的地址,属于 引用类型:
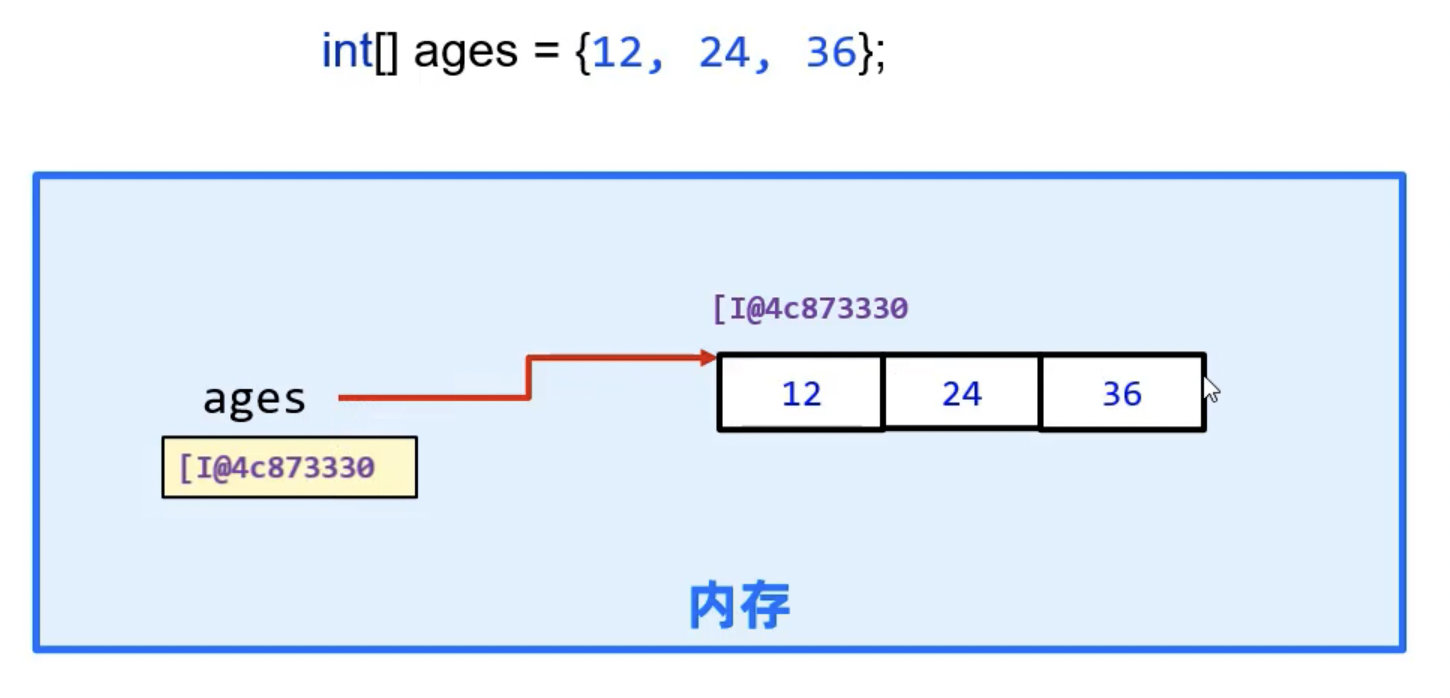
2.2 访问数组元素
直接通过索引访问即可:

访问数组长度:
数组名称.length()2.3 动态初始化数组
定义数组类型的时候,只定义数组的长度,之后再存入数据。

2.4 数组内存图解
Java 中的内存分配(先看这三个):
- 堆内存:new 出来的东西(对象)会在这块内存中开辟空间并产生地址;
- 栈内存:方法运行时所进入的内存,变量也存放于此;
- 方法区:
.class字节码文件加载时进入的内存。

3 方法
3.1 方法定义格式


3.2 方法的内存图解
方法在没有被调用时,在 方法区 的字节码中存放。
方法在被调用的时候,需要进入到 栈内存 中运行。

3.3 方法参数传递机制
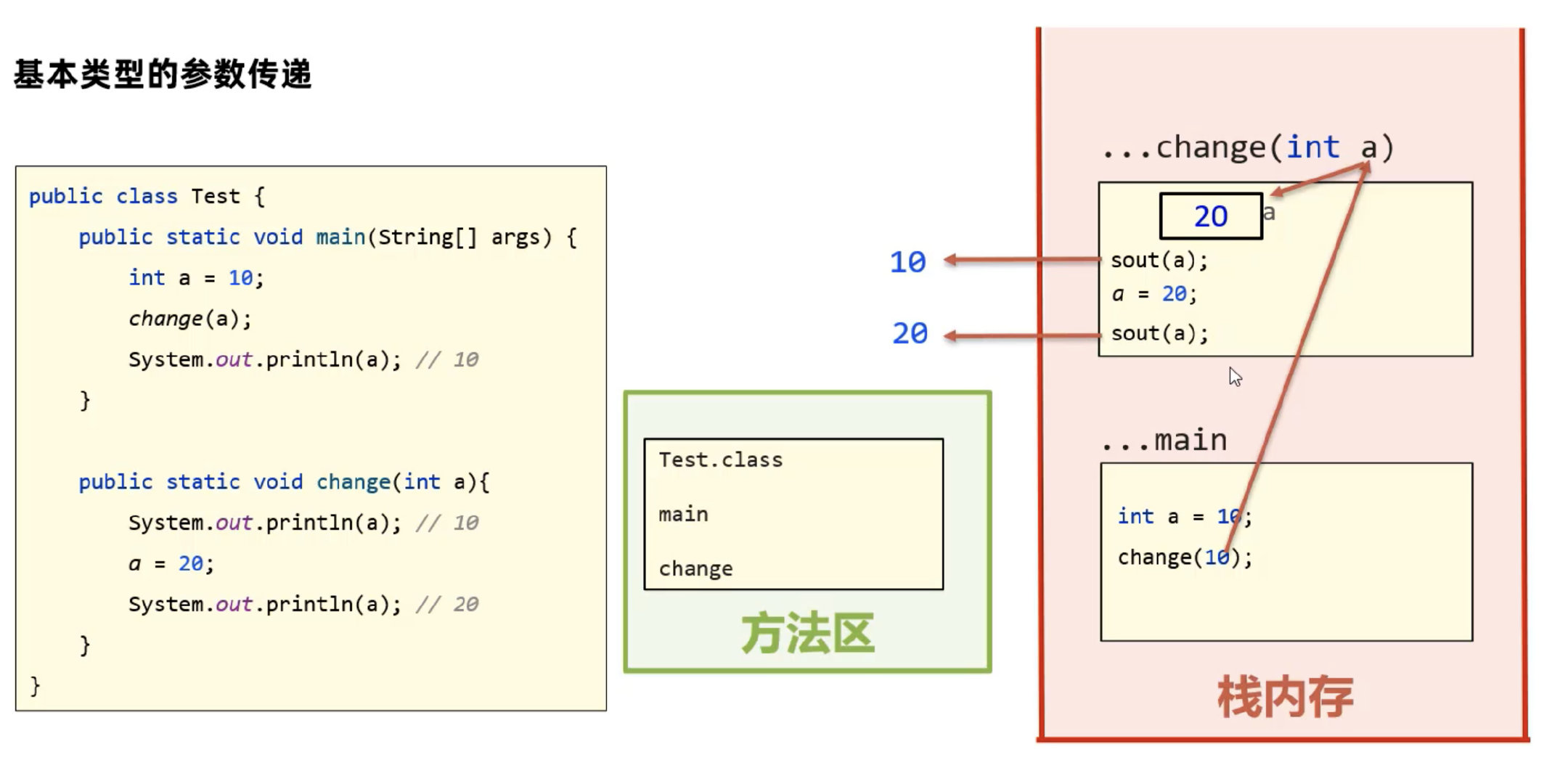
3.3.1 基本类型参数传递
在传递实参给方法的形参时,并不是传输实参变量本身,而是传输实参变量中存储的值,这称为 值传递。
- 实参:如方法内部定义的变量;
- 形参:在定义方法时,
()中所包含的参数。
3.3.2 引用类型参数传递
引用类型变量传递的是一个地址值。

基本类型与引用类型参数传递的异同:
- 都是值传递;
- 基本类型传输的是数据值;
- 引用类型传输的是地址值。
3.4 方法重载
同一个类 中,出现多个方法名称相同,但是形参列表是不同的,那么这些方法就是 重载方法。
形参列表不同:形参的 个数、类型、顺序 不同,不关心形参的名称。
优点:对于相似功能的业务场景:可读性好,方法名称相同提示是同一类型的功能,通过形参不同实现功能差异化的选择。
3.5 可变参数
可变参数:
- 用在形参中可接收多个数据;
- 格式:
数据类型...参数名称

可变参数在方法内部其实就是一个数组。

4 面向对象
先定义类,再通过类
new出对象。
Q:类和对象是什么?
A:类是共同特征的描述;对象是真实存在的具体案例。
注意:一个
class文件中,只能有一个类使用public修饰,并且该类名称需要作为文件名称。4.1 对象成员默认值规则

4.2 对象内存图
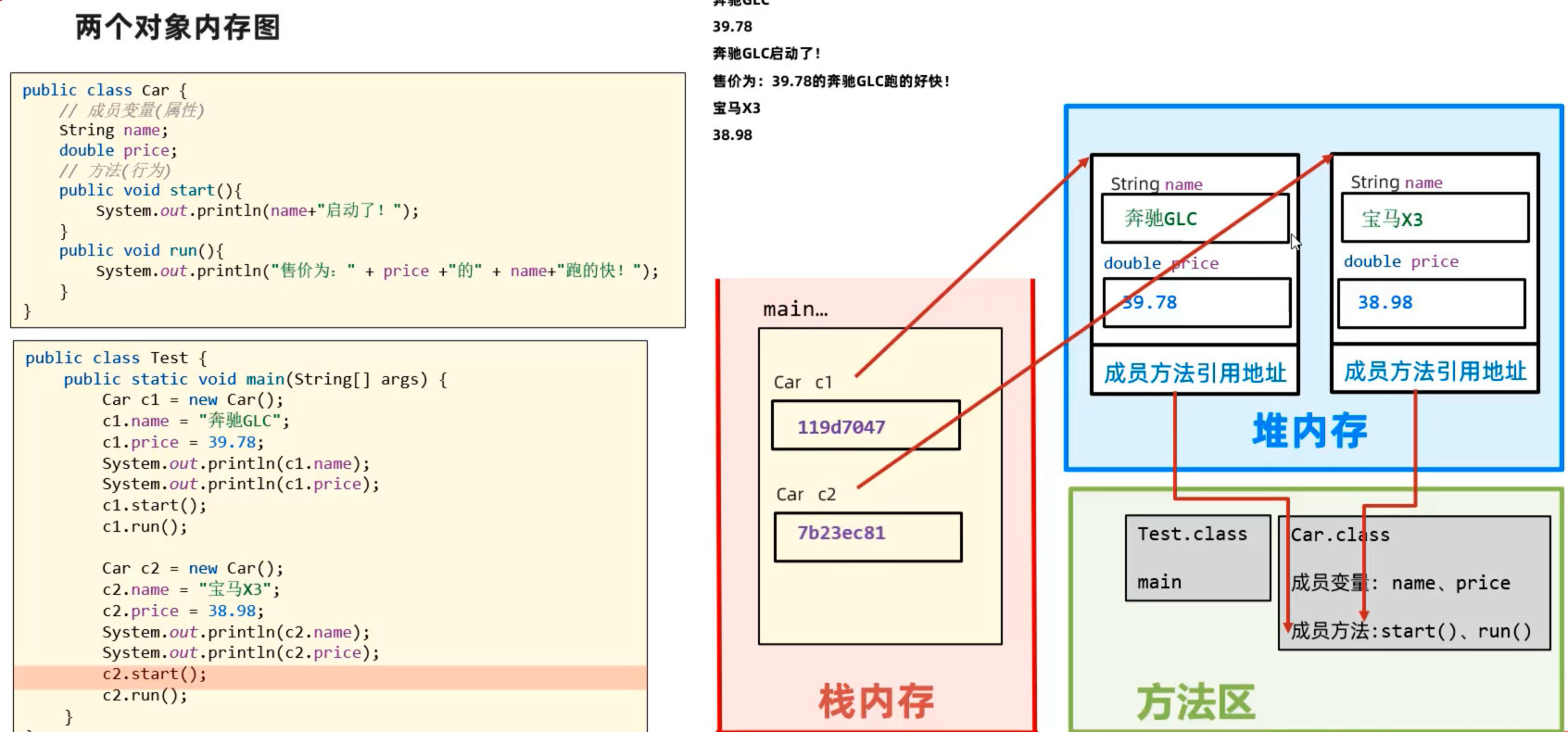

垃圾回收机制:
当堆内存中的 类对象 或 数组对象,没有被任何变量引用时,就会判定为内存中的“垃圾”。
Java 存在自动垃圾回收器,会定期进行清理。
4.3 构造器
构造器的作用:用于初始化一个雷的对象,并返回对象的地址。

构造器的分类:
- 无参数构造器(默认存在的):初始化对象时,成员变量的数据均采用默认值。
- 有参数构造器:在初始化对象时,同时可以为对象进行赋值。

注意:如果写了一个有参构造器,那么需要定义无参构造器,否则无法使用无参构造器。
4.4 this 关键字
this关键字的作用:出现在成员方法、构造器中代表当前对象的地址,用于访问当前对象的成员变量、成员方法。在构造器中:

在成员方法中:

4.5 封装
封装就是 合理隐藏、合理暴露。
封装的实现步骤:
- 一般对成员变量使用
private关键字修饰进行隐藏,private修饰后该成员变量就 只能在当前类中访问。 - 提供
public修饰的公开的getter和setter方法,暴露其取值与赋值。
优点:
- 加强了代码安全性;
- 适当的封装可以提升开发效率,便于维护。
4.6 标准 JavaBean
JavaBean:可以理解为实体类,其对象可以用于在程序中封装数据。
标准 JavaBean 必须满足如下要求:
- 成员变量使用
private修饰; - 提供每一个成员变量对应的
setXXX()和getXXX(); - 必须提供一个无参构造器。
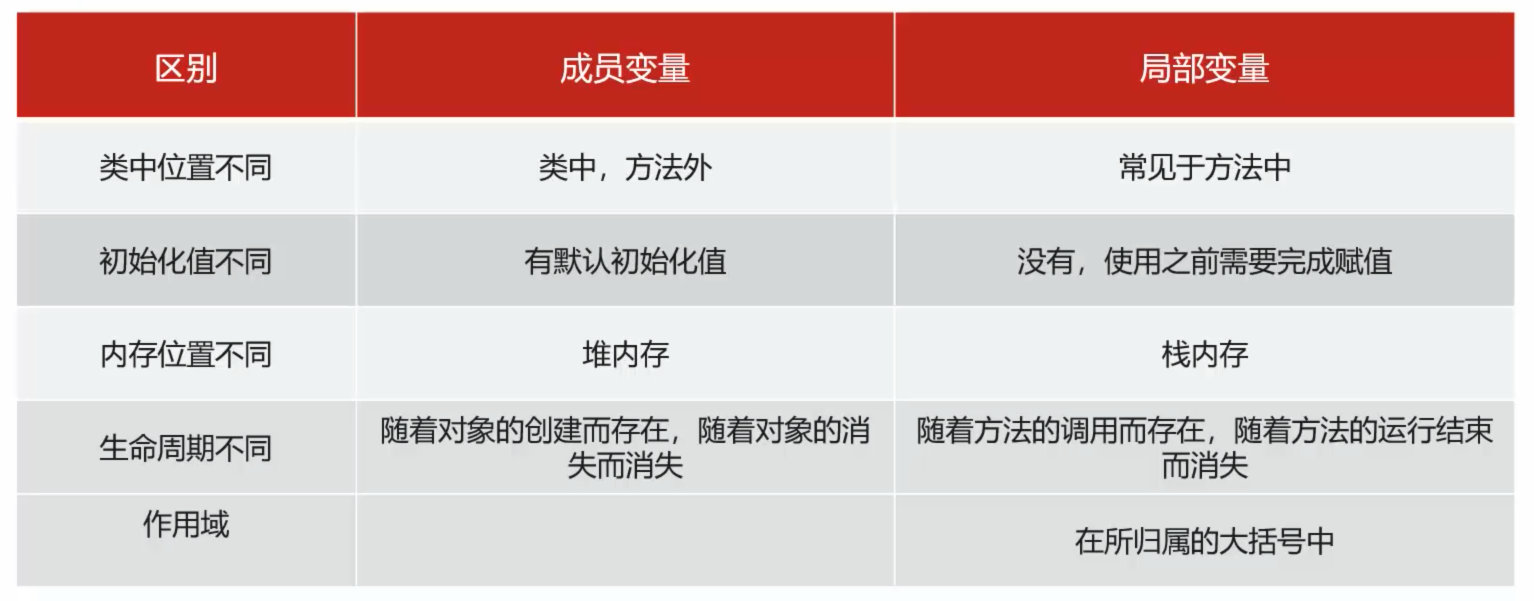
4.7 成员变量与局部变量的区别
4.8 static 静态关键字
static是什么?static是 静态 的意思,可修饰成员变量与成员方法;static修饰成员变量之后称为 静态成员变量(类变量),修饰方法之后称为 静态方法(类方法);static修饰的成员变量表示 该成员变量在内存中只存储一份,可以被 共享访问、修改。
4.8.1 静态成员变量
成员变量可以分为两类:

【static静态成员变量内存图解】
注意:在
User.class加载到方法区时,静态成员变量onLineNumber也同步加载到堆内存,随后才是main方法进入栈内存。
4.8.2 静态成员方法
成员方法的分类:

【static静态成员方法内存图解】
注意:方法还是在方法区中,而不会放在堆中。
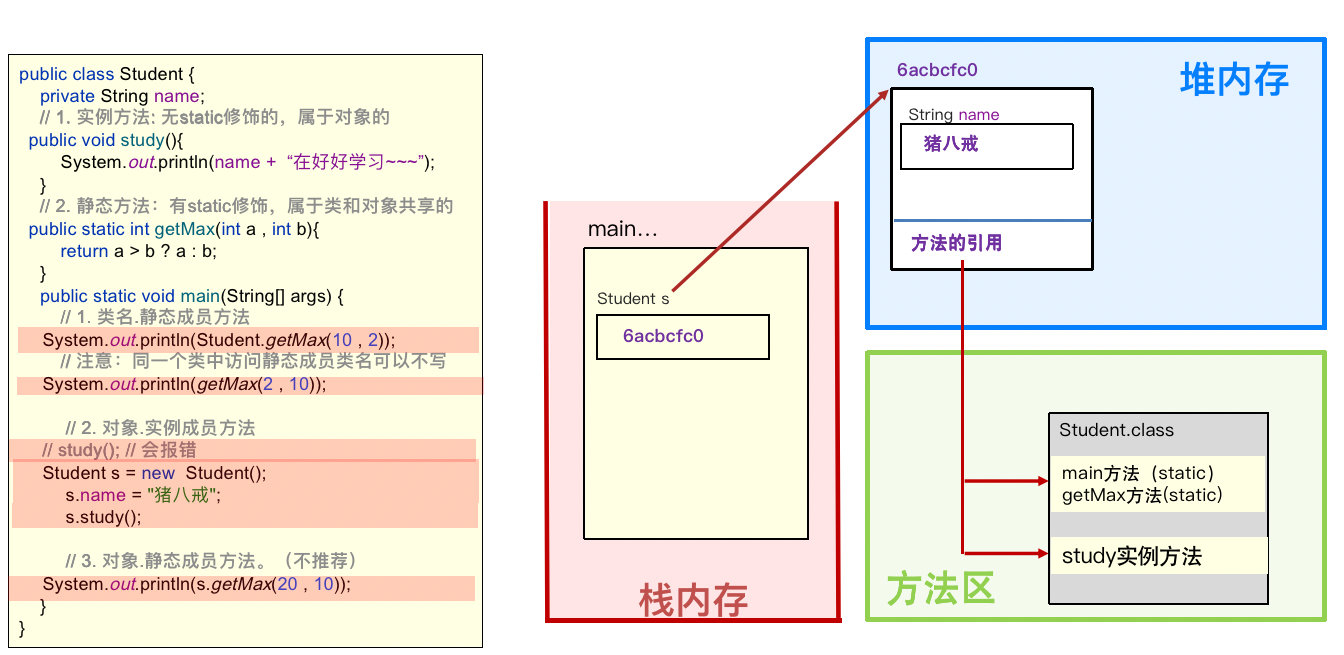
重点注意:
- 静态方法只能访问静态的成员,不可以直接访问实例成员;
- 实例方法可以访问静态的成员,也可以访问实例成员;
- 静态方法中是不可以出现
this关键字的。
4.8.3 static 工具类
类中都是一些 静态方法,每个方法都是以完成一个 共用的功能 为目的,这个类用来给系统开发人员共同使用的。
- 调用方便
- 代码可重用性高
由于工具类无需创建对象,建议将工具类的构造器进行私有。
4.8.4 静态代码块
代码块是类的 5 大成分之一(成员变量、构造器,方法,代码块,内部类),定义在类中方法外。
在 Java 类下,使用
{ }括起来的代码被称为 代码块 。
4.9 继承

继承的好处:提高代码的复用性、增强类的扩展性
继承的设计规范:子类们相同特征(共性属性、共性方法)放在父类中定义,子类独有的属性和方法定义在自己类中。
【继承的内存图解】
无论是父类空间还是子类空间,对外都是一个子类对象。
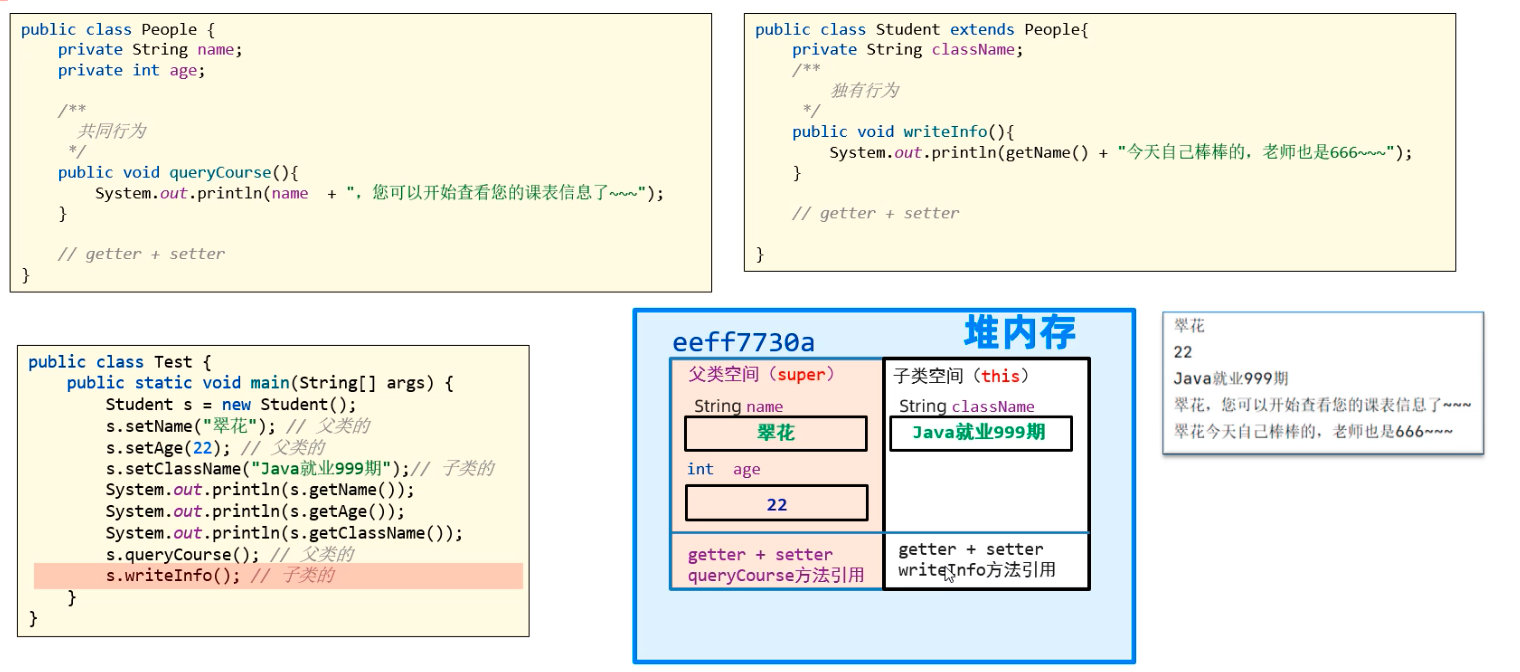
继承的特点:
- 子类可以继承父类的属性和行为,但子类不能继承父类的构造器
- Java 是单继承模式,一个类只能继承一个直接父类
- Java 不支持多继承,但是支持多层继承
- Java 中所有的类都是 Object 类的子类
为什么不支持多继承?

4.9.1 继承后成员变量、方法的访问特点
继承后成员的访问特点:就近原则。那此时如果一定想在子类中使用父类的怎么办?
可以使用
super关键字,指定访问父类的成员。4.9.2 继承后方法重写
在继承体系中,子类出现了和父类中一模一样的方法声明,则称子类这个方法是 重写 的方法。

重要!!
@override重写校验注解:- 加上注解后,这个方法必须是正确重写的,更安全
- 提高程序可读性,代码优雅

4.9.3 继承后子类构造器的特点
子类中所有的构造器默认都会先访问父类中无参的构造器,再执行自己。


4.10 this 和 super 总结


4.11 包

4.12 权限修饰符
权限修饰符:用来控制一个成员能够被访问的范围。
可以修饰 成员变量、方法、构造器、内部类,不同权限修饰符修饰的成员能够被访问的范围将受到限制。

自己定义成员(方法,成员变量,构造器等)一般需要满足如下要求:
- 成员变量一般私有
- 方法一般公开
- 如果该成员只希望本类访问,使用 private 修饰
- 如果该成员只希望本类,同一个包下的其他类和子类访问,使用 protected 修饰
4.13 final 关键字
final关键字可修饰类、方法、变量:- 修饰类:该类为最终类,不能被继承
- 修饰方法:该方法是最终方法,不能被重写
- 修饰变量:该变量第一次赋值后,不能再次被赋值(有且仅能赋值一次)

4.14 常量
常量是使用了
public static final修饰的 成员变量,必须有初始化值,而且执行的过程中其值不能被改变。常量名的命名规范:英文单词全部大写,多个单词下划线连接起来。
常量的作用:通常用来记录系统的配置数据。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qzQN5pDh-1668166963695)(/Users/mac/Library/Application%20Support/typora-user-images/image-20221107220201446.png)]
4.15 枚举
枚举是 Java 中的一种特殊类型。作用:做 信息标志 和 信息分类。


4.16 抽象类
在 Java 中,
abstract可修饰类、成员方法,使其变为 抽象类 或 抽象方法。
抽象类的使用场景:
- 抽象类可以理解成不完整的设计图,一般作为父类,让子类来继承
- 当父类知道 子类一定要完成某些行为,但是 每个子类该行为的实现又不同,于是该父类就把该行为定义成抽象方法的形式,具体实现交给子类去完成。此时这个类就可以声明成抽象类
注意:
- 类有的成员(成员变量、方法、构造器)抽象类都有
- 抽象类可以没有抽象方法,但有抽象方法的类必须是抽象类
- 一个类如果继承了抽象类,那么这个类 必须重写完抽象类的全部抽象方法,否则这个类也必须定义成抽象类
- 不能用
abstract修饰变量、代码块、构造器 - 最重要的特征: 得到了抽象方法,失去了创建对象的能力(不能创建对象)
补充:
final与abstract是 互斥关系
4.17 接口

接口是用来被类 实现(implements) 的,实现接口的类称为 实现类。实现类可以理解成所谓的子类。

重点注意:
- 类与类:单继承
- 类与接口:多实现
- 接口与接口:多继承
JDK8后的接口类新增方法:



注意事项:
- 接口不能创建对象
- 一个类实现多个接口,多个接口的规范不能冲突
- 一个类实现多个接口,多个接口中有同样的静态方法不冲突
- 一个类继承了父类,同时又实现了接口,父类中和接口中有同名方法,默认用父类的
- 一个类实现了多个接口,多个接口中存在同名的默认方法,可以不冲突,这个类重写该方法即可
- 一个接口继承多个接口,是没有问题的,如果多个接口中存在规范冲突则不能多继承。
4.18 多态
多态:同类型的对象,执行同一个行为,会表现出不同的行为特征。
父类 对象名称 = new 子类构造器(); Animal a = new Dog(); 接口 对象名称 = new 实现类构造器();- 1
- 2
- 3
- 4
- 5
多态中成员访问特点:
- 方法调用:编译看左边,运行看右边
- 变量调用:编译看左边,运行也看左边
多态只是强调 行为 的多态!

4.18.1 多态下引用数据类型的类型转换
通过强制类型转换可以解决多态的弊端,即可调用子类独有方法。

4.19 内部类
内部类就是定义在一个类里面的类,里面的类可以理解成寄生,外部类可以理解成宿主。

4.19.1 静态内部类

Q:静态内部类中是否可以直接访问外部类的静态成员?
A:可以,外部类的静态成员只有一份,并且可以被共享访问。
Q:静态内部类中是否可以直接访问外部类的实例成员?
A:不可以的,外部类的实例成员必须用外部类对象访问。
4.19.2 成员内部类
成员内部类:无
static修饰,属于 外部类对象。
Q:成员内部类中是否可以直接访问外部类的静态成员?
A:可以,外部类 的静态成员只有一份可以被共享访问。
Q:成员内部类的实例方法中是否可以直接访问外部类的实例成员?
A:可以,因为必须 先有外部类对象,才能有成员内部类对象,所以可以直接访问外部类对象的实例成员。

4.19.3 局部内部类
-
局部内部类放在方法、代码块、构造器等执行体中。
-
局部内部类的类文件名为: 外部类$N内部类.class。
4.19.3 匿名内部类(重点)
匿名内部类,本质上是一个没有名字的局部内部类,定义在方法中、代码块等。

5 包装类
包装类是 8 种基本数据类型对应的引用类型。
基本数据类型 引用数据类型 byte Byte short Short int Integer long Long char Character float Float double Double boolean Boolean 为什么需要提供包装类?
- Java 为了实现一切皆对象,为 8 种基本类型提供了对应的引用类型
- 后面的 集合 和 泛型 其实也只能支持包装类型,不支持基本数据类型
自动装箱:基本类型的数据和变量可以直接赋值给包装类型的变量。
自动拆箱:包装类型的变量可以直接赋值给基本数据类型的变量。

6 正则表达式

正则表达式爬去信息:

7 Lambda表达式
Lambda 表达式是 JDK 8 开始后的一种新语法形式。
作用:简化函数式接口匿名内部类的代码写法。
Lambda 只能简化接口中只有一个抽象方法的匿名内部类形式(函数式接口)。
@FunctionalInterface interface Swimming{ void swim(); }- 1
- 2
- 3
- 4
- 5



8 集合
集合和数组都是容器。
- 数组定义完成并启动后,类型确定,长度固定。
不适合元素的个数和类型不确定的业务场景,更不适合做需要增删数据操作。
- 集合的大小不固定,启动后可以动态变化,类型也可以选择不固定。集合更像气球。
集合非常适合元素个数不能确定,且需要做元素的增删操作的场景。
8.1 集合的体系结构
-
Collection 单列集合,每个元素(数据)只包含一个值。
-
Map 双列集合,每个元素包含两个值(键值对)。

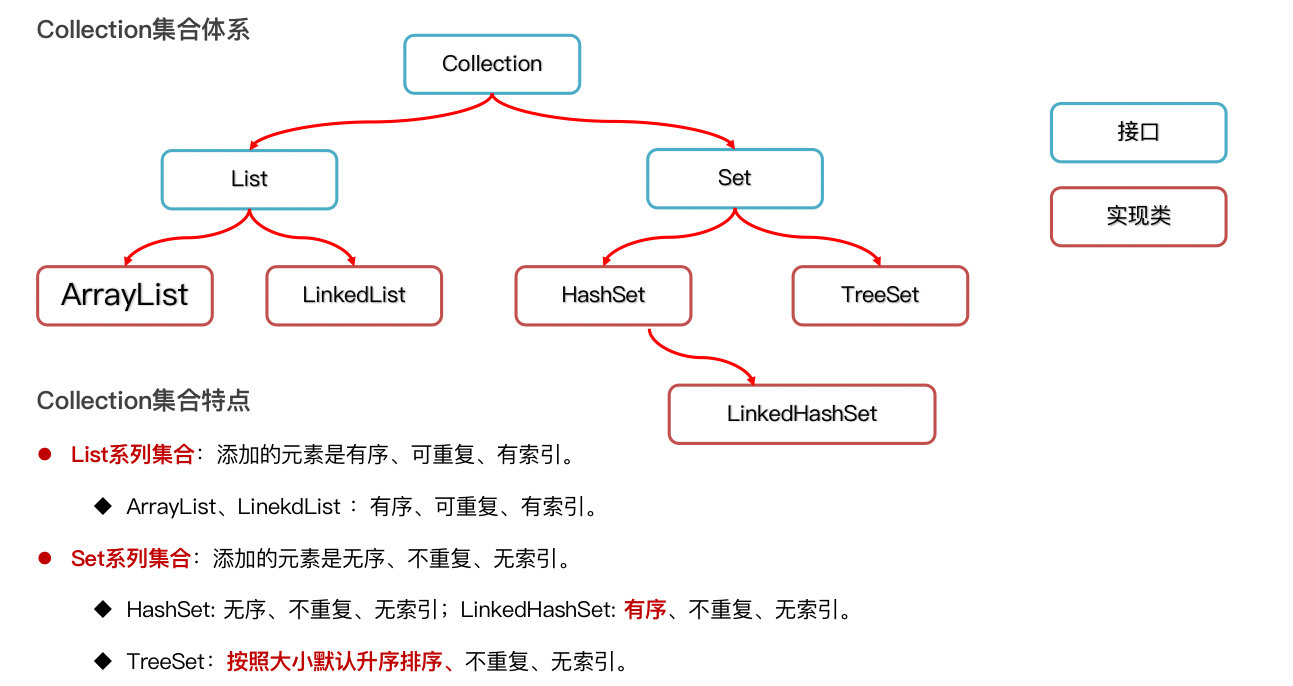
集合都是支持范型支持,可以在编译阶段约束集合只能操作某种数据类型。
注意:集合和泛型都 只能支持引用数据类型,不支持基本数据类型,所以集合中存储的元素都认为是 对象。

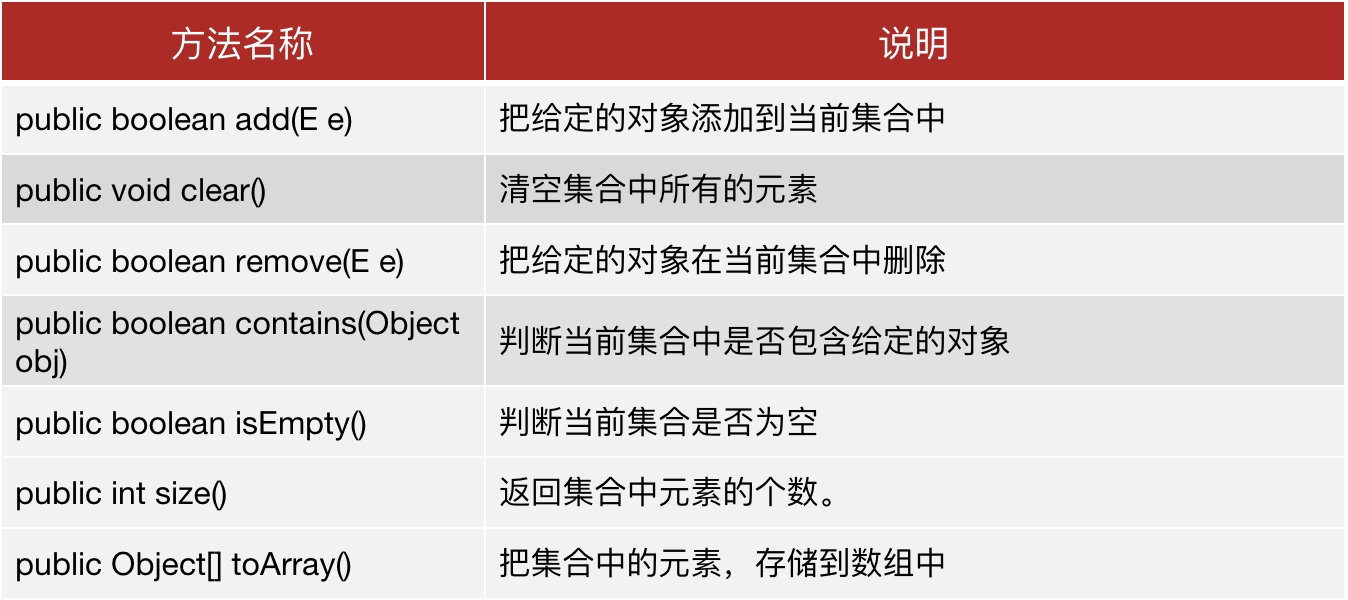
8.2 Collection集合API与遍历
Collection 是 单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。

遍历方式一:迭代器
迭代器 在 Java 中代表的是 Iterator,迭代器是集合的专用遍历方式。

如果使用迭代器取元素越界,会出现
NoSuchElementException异常。遍历方式二:增强for循环
既可以遍历集合,也可以遍历数组。

需要注意的是:修改第三方变量的值不会影响到集合中的元素。
遍历方法三:结合Lambda表达式

8.3 List系列集合
有序:存储和取出的元素顺序一致
有索引:可以通过索引操作元素
可重复:存储的元素可重复
ArrayList底层是基于 数组 实现的:根据索引定位元素快,增删相对慢;LinkedList底层基于 双链表 实现的:查询元素慢,增删首尾元素非常快。
ArrayList
// 多态风格,经典代码 List<String> list = new ArrayList<>(); list.add("java"); list.add("java2"); list.remove(1); list.get(1); list.set(1, "aaa");- 1
- 2
- 3
- 4
- 5
- 6
- 7
list集合的遍历方式:- 迭代器
Iterator<String> it = list.iterator(); while(it.hasNext()){ String ele = it.next(); }- 1
- 2
- 3
- 4
- 5
- 增强
for循环
for(String ele : list){ sout(ele); }- 1
- 2
- 3
- 4
- Lambda 表达式
lists.forEach(s -> { sout(s) })- 1
- 2
- 3
- 4
- For 循环(使用List索引)
LinkedList
底层数据结构是双链表,查询慢,首尾操作的速度是极快的,所以多了很多首尾操作的特有API。
由于有大量的首、尾操作,可以使用
LinkedList实现队列和栈。方法名称 说明 public void addFirst(E e) 在该列表开头插入指定的元素 public void addLast(E e) 将指定的元素追加到此列表的末尾 public E getFirst() 返回此列表中的第一个元素 public E getLast() 返回此列表中的最后一个元素 public E removeFirst() 从此列表中删除并返回第一个元素 public E removeLast() 从此列表中删除并返回最后一个元素 8.4 Set系列集合
特点:
- 无序:存取顺序不一致(但不是随机无序)
- 不重复:可以去重
- 无索引:没有带索引的方法,不能用for循环变量,也不能通过索引取元素
相关实现类:
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TresSet:可排序、不重复、无索引
HashSet底层原理
HashSet 的底层是采取 哈希表 存储数据的。哈希表是一种对增删查改数据性能都比较好的结构。
哈希表的组成:
- JDK 8 后,底层采用 数组 + 链表 + 红黑树。



哈希表的详细流程:
- 创建一个默认长度 16,默认加载因为 0.75 的数组,数组名 table
- 根据元素的哈希值跟数组的长度计算出应存入的位置
- 判断当前位置是否为 null,如果是 null 直接存入,如果位置不为 null,表示有元素,则调用equals 方法比较属性值,如果一样,则不存,如果不一样,则存入数组
- 当数组存满到 16*0.75=12 时,就自动扩容,每次扩容原先的两倍
HashSet去重原理

Object.hash()参数一样,则生成的哈希值就一样。LinkedHashSet特点与原理
特点:有序、无重复、无索引。这里的有序是指保证存储和取出的元素顺序一致。
原理: 底层数据结构仍然是哈希表,但每个元素又额外地多了一个 双链表的机制记录存储顺序。

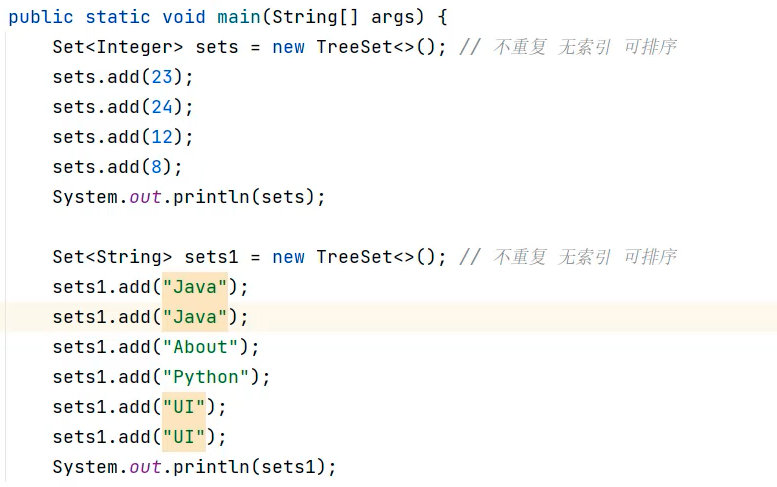
TreeSet特点与原理
特点:可排序、无重复、无索引。
可排序:按照元素的大小默认升序(小到大)排列。
TreeSet集合底层是基于 红黑树的数据结构 实现排序的,增删查改性能都比较好。
注意:TreeSet一定是要排序的,可以将元素按照制定规则排序。
数字默认从小到大,字母按照ASCII码从小到大排。
如何自定义排序规则呢?

注意:如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序。
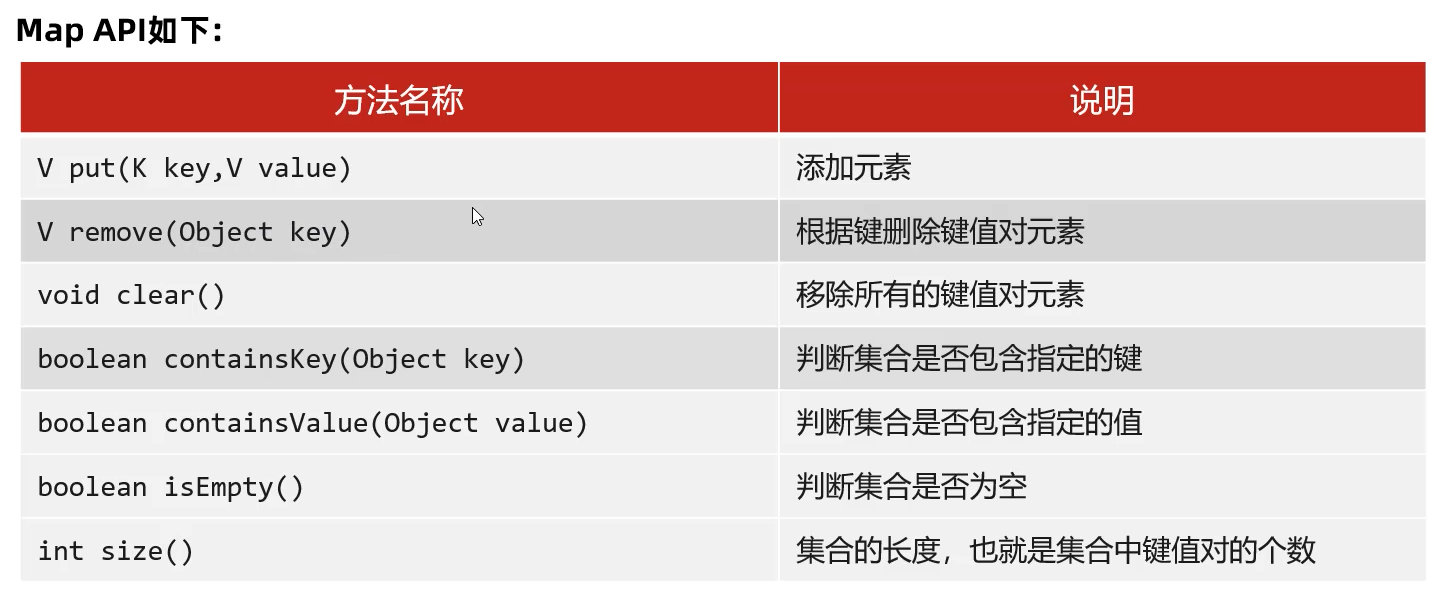
8.5 Map集合
Map集合:
- 是一种双列集合,每个元素包含两个数据
- 每个元素的格式:key=value(键值对)
- 也称为 “键值对” 集合


特点:
- 由键决定的
- 键是无序的、不重复、无索引的
- 后面重复的键会覆盖前面键的值
- 键值对都可以为null

Map的API
Map是双列集合的祖宗接口,它的功能是全部双列集合都可以继承使用的。
Map集合的遍历方式一:键找值
先
keySet()再get()。
Map集合的遍历方式一:键值对

Map集合的遍历方式一:Lambda表达式

HashMap底层原理


HashMap的特点和底层原理:
- 由键决定:无序、不重复、无索引。HashMap底层是哈希表结构的。
- 依赖hashCode方法和equals方法保证键唯一
- 如果键要存储的是自定义对象,需要重写hashCode和equals
- 基于哈希表,增删查改性能较好
LinkedHashMap底层原理

TreeSet底层原理

集合的并发修改问题
当我们从集合中找出某个元素并删除的时候可能出现一种 并发修改异常 问题。

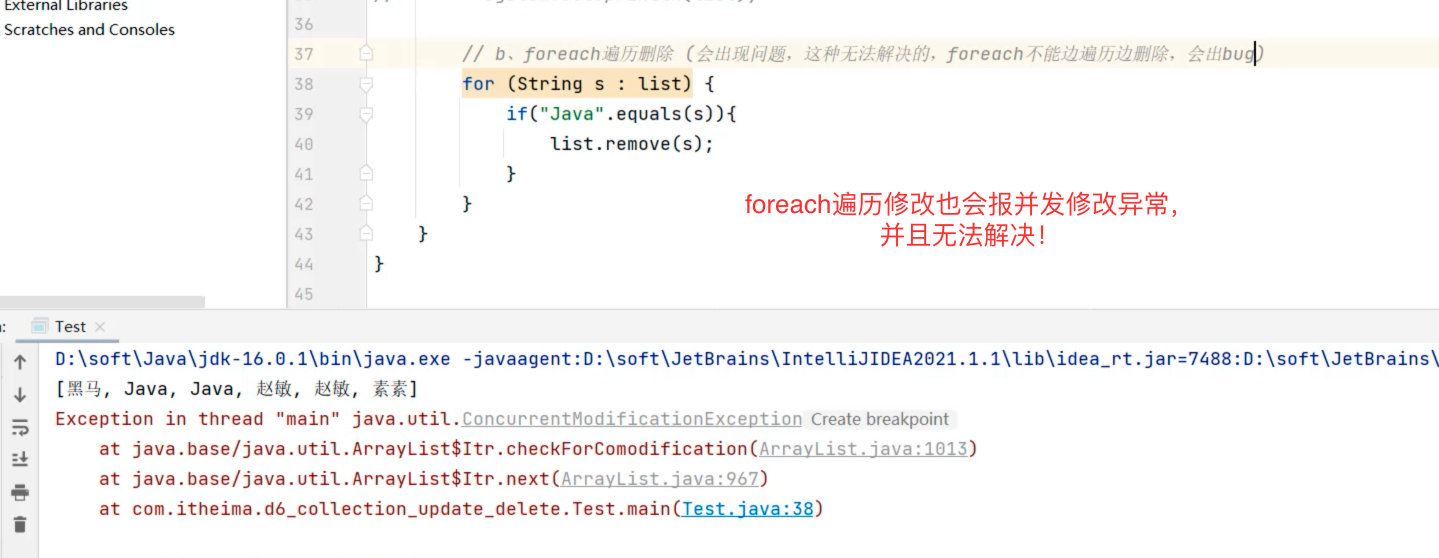
所以,foreach最好只用来查询,不要进行修改,同样lambda也不行。

哪些遍历存在问题?
- 迭代器遍历集合且直接用集合删除元素的时候可能出现。
- 增强for循环遍历集合且直接用集合删除元素的时候可能出现。
那种遍历且删除元素不出现问题?
- 迭代器遍历集合但是用 迭代器自己的删除方法 操作可以解决。
- 使用for循环遍历并删除元素不会存在这个问题(需要从后往前遍历)。
9 泛型
泛型:是 JDK5 中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型的格式:
<数据类型>; 注意:泛型只能支持引用数据类型。集合体系的全部接口和实现类都是支持泛型的使用的。
泛型的原理:把出现泛型变量的地方全部替换成传输的真实数据类型。
优点:
- 统一的数据类型;
- 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为编译阶段类型就能确定下来。
泛型类

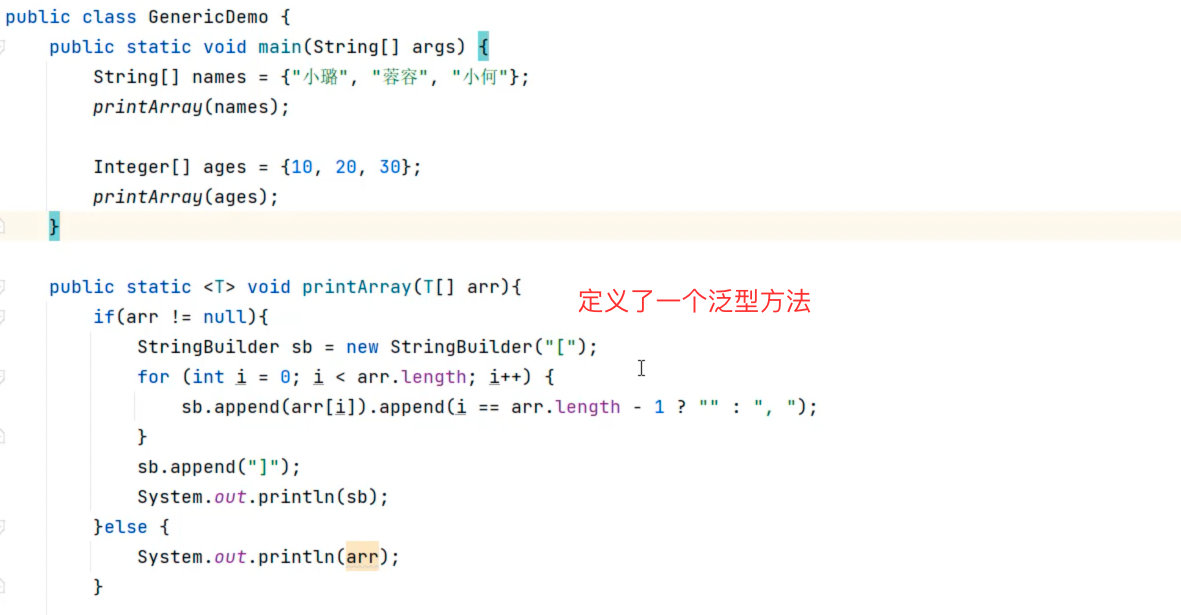
泛型方法
泛型方法:定义方法时同时定义了泛型的方法就是泛型方法。
泛型方法的格式:
修饰符 <泛型变量> 方法返回值 方法名称(形参列表){}
泛型接口
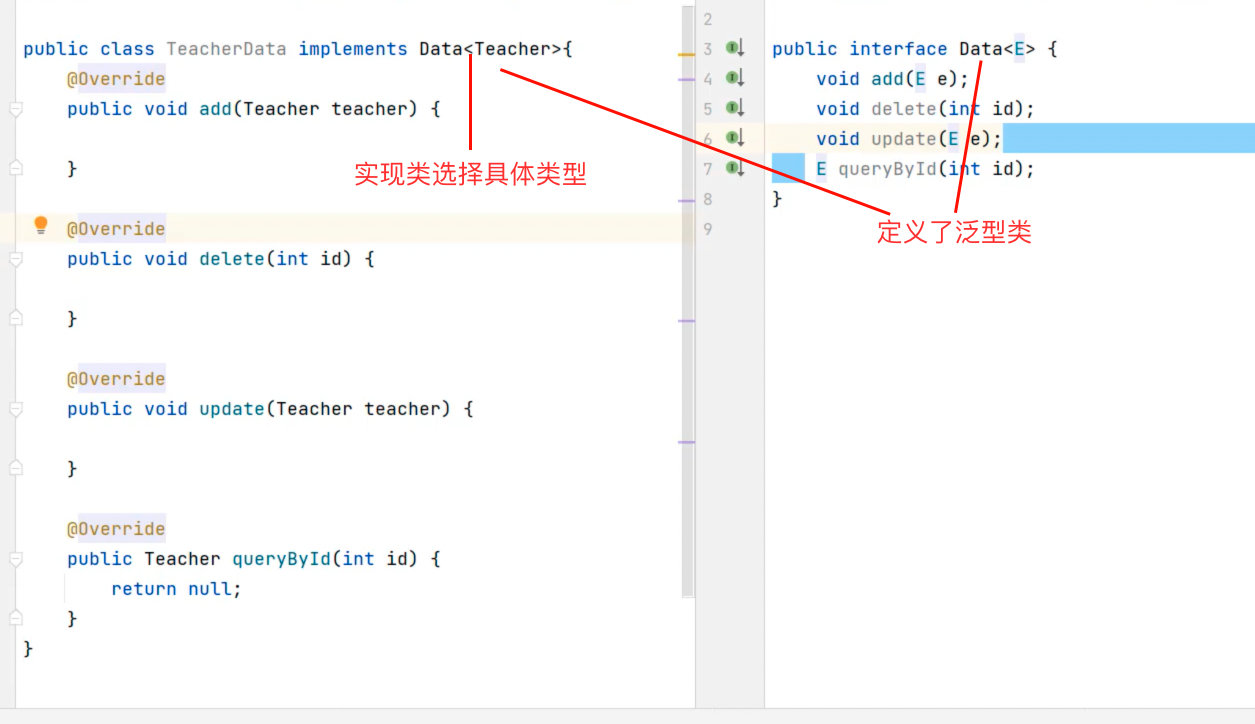
使用了泛型定义的接口就是泛型接口。
泛型接口的格式:
修饰符 interface 接口名称<泛型变量>{}作用:泛型接口可以让实现类选择当前功能需要操作的数据类型。
泛型通配符与上下限


go方法参数改成ArrayList也不行!需要改成这样!!!
10 不可变集合
不可变集合:不可被修改的集合。
**集合的数据项在创建的时候提供,并且在整个生命周期中都不可改变。**否则报错。
什么时候需要不可变集合?
- 如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践。
- 或者当集合对象被不可信的库调用时,不可变形式是安全的。

List<Double> lists = List.of(69.5, 99.1);- 1
11 Stream流
在 Java 8 中,得益于 Lambda 所带来的函数式编程, 引入了一个全新的 Stream 流概念。
目的:用于简化集合和数组操作的API。
Stream流式思想的核心:
- 先得到集合或者数组的 Stream 流(就是一根传送带)
- 把元素放上去
- 然后就用这个 Stream 流简化的 API 来方便的操作元素。
Stream流的三类方法:
- 获取Stream流:创建一条流水线,并把数据放到流水线上准备进行操作
- 中间方法:流水线上的操作。一次操作完毕之后,还可以继续进行其他操作
- 终结方法:一个Stream流只能有一个终结方法,是流水线上的最后一个操作
获取Stream流

Collection<String> list = new ArrayList<String>; Stream<String> s = list.stream(); Map<String, Integer> map = new HashMap<>(); // 键流 Stream<String> keyStream = map.keySet().stream(); // 值流 Stream<String> valueStream = map.valueSet().stream(); // 键值对流 Stream<Map.Entry<String, Integer>> = map.entrySet().stream(); String[] names = { "1", "2"}; Stream<String> nameStream = Arrays.stream(names); //或 Stream<String> nameStream2 = Stream.of(names);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Stream流常用API

list.stream().filter(s -> s.startWith("张")).forEach(s -> sout(s));- 1

收集Stream流:就是把 Stream 流 操作后的结果数据转回到集合或者数组中去。
-
Stream流:方便操作集合/数组的手段。
-
集合/数组
-
相关阅读:
QTableWidget 表格部件
借助这个宝藏神器,我成为全栈了
axios上传文件错误:Current request is not a multipart request
Linux常用命令
剑指YOLOv7改进最新重参数化结构RepViT| 最新开源移动端网络架构ICCV 2023,1.3ms 延迟,速度贼快
《Spring Guides系列学习》guide21 - guide25
Redis篇----第六篇
高效PPT制作与演示技巧大揭秘
MacOS 控制固态磁盘写入量,设置定时任务监控
Vue3 + Nodejs 实战 ,文件上传项目--实现拖拽上传
- 原文地址:https://blog.csdn.net/weixin_41960890/article/details/127812030
