-
Discrete Optimization课程笔记(2)—Constraint Programming约束规划(上)
目录
1.约束规划(Constraint Programming)
2.约束传播(constraint propagation)
Case6: Balanced Incomplete Block Designs (BIBDs)
6. 冗余约束(Redundant constraints)
7. 全局约束案例(Implement global constraints)
Case9: Binary Knapsack(dynamic program)
Case10: Alldifferent(matching algorithm)
Case11: Euler Knight(First-fail principle)
Case4: 8位皇后(Variable/Value Labeling)
Case12: The ESDD Deployment Problem(not)
Case13: The perfect square problem(Value/variable labeling)
Case14: The magic square problem(Domain splitting)
Case8: Car Sequencing problem(Domain splitting)
Case7: Scene allocation(symmetry breaking during search)
Case14: The magic square problem(Randomization and restarts)
1.约束规划(Constraint Programming)
(1)约束规划
- 使用约束减少每个变量取值集合
- 移除不可能出现在任何解的值
- 精确解而非启发式解:足够时间,能找到满意解和最优解
- 重点:怎么使用约束缩小搜索空间,排除不可能出现在任何解的取值
(2)经典问题
- 8个皇后:将8个棋子摆放在8*8的棋盘上,要求每两个棋子不能在相同行,列以及对角线
- 地图着色:给一张地图上色,要求相邻国家不能颜色相同
四色定理:任何一张地图只用四种颜色就能使具有共同边界的国家着上不同的颜色
(3)约束(constraint )的作用
- 检查在变量域里是否存在可行解(Feasibility checking)
- 如果有可行解,约束能决定变量域中的某些值是否是可行解(Pruning)
域(domain):一个变量的域即为其可能取值的集合,D(x)={1,2,3}
2.约束传播(constraint propagation)
(1)约束传播过程

Case1: Send More Money
以Send More Money为例说明constraint propagation过程,按照下面的公式找到每个字母对应的数字,引入4个辅助变量代表进位。模型如下,字母取值0-9,进位取值0-1,每个字母代表不同的数字,S和M是首位,不能为0,每列有计算等式

(1)前四个约束:左图为搜索空间,根据前四个约束得出value[M]=carry[4]=1

(2)约束5:carry[3] + value[S] + value[M] = value[O] + 10 * carry[4]
- carry[3]为0~1,value[S]为2~9,value[M]=1,左边等式为3~12
- carry[4]=1,value[O]为0和2~9,右边等式10~19
- 取左右两边交集为[10,11]
- 10 <= carry[3] + value[S] + 1 <= 11,因此8 <= value[S] <= 10
- 10 <= value[O] + 10 * carry[4] <= 11,因此0 <= value[O] <= 1,即value[O]=0
- 更新搜索空间,字母取值不能相通


(3)约束6:carry[2] + value[E] + value[O] = value[N] + 10 * carry[3]
- value[O] = 0,0 <= carry[2] <= 1,2 <= value[E] <= 9,2 <= 左边 <= 10
- 2 <= value[N] + 10 * carry[3] <= 10,因此-7 <= 10 * carry[3] <= 8,即carry[3] = 0

(4)回溯到约束5:carry[3] + value[S] + value[M] = value[O] + 10 * carry[4]
- carry[3] = 0,value[M] = carry[4] = 1,value[O] = 0,因此value[S] = 9
- 后面的约束条件得出的值可以再作用到前面的约束,再次缩小搜索空间


(2)通用形式
对于整数线性约束,有以下通用形式


3.元素约束(Element constraint)
用包含变量的表达式索引一个数组或者矩阵
Case2: Magic Series
如果在一个序列 S=(S0,S1,S2...Sn) 中,S(i)代表i在S中出现的次数,那么S称为Magic Series。如下为一个Magic Series,S[0]=2,表示0出现了两次。

Reification:将约束变成0/1变量,如果约束成立,变量取值为1,否则取值为0。对每一个k,引入0/1变量b[i],如果series[i] = k,那么b[i] = 1,否则b[i] = 0,series[k]为b的所有值和。


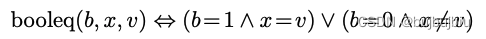
Case3: Stable Marriages
假设有四个男生分别是George,Hugh,Will,Clive,四个女生分别是Julia,Halle,Angelina,Keira,每个女生(男生)都对所有男生(女生)有一个偏好等级。例如对于Halle,男生的排名分别为Clive,George,Will,Hugh;对于Hugh,女生的排名分别为Angelina,Halle,Clive,George。什么情况下婚姻是稳定的?以Hugh和Angelina为例,如果Angelina喜欢George多过Hugh,那么George一定要喜欢他配偶多过Angelina,如果Hugh喜欢Julia多余Angelina,那Julia一定要喜欢他配偶多过Hugh,满足上述两个条件的婚姻才是稳定的。建模如下
- wrank[Men,Women] 代表对于Men来说,Women的排序;mrank[Women,Men] 代表对于Women来说,Men的排序
- 决策变量:wife[Men]代表Men的妻子,husband[Women]代表Women的丈夫
- 约束条件(一致):对于每一个男人,他的妻子对应的丈夫是他自己,即 husband[wife[m]] = m;同样对于每一个女人,他的丈夫对应的妻子是她自己,即 wife[husband[w]] = w
- 约束条件(稳定):对于每一个m,如果m比起他的妻子更喜欢w(wrank[m,w] < wrank[w,wife[m]]),那么对于w,她要比起m更喜欢她的丈夫(mrank[w,husband[w]] < mrank[w,m])。对于每一个w,也是同理。

4. 全局约束(Global Constraints)
全局约束是捕获非固定数量的变量之间的关系的约束
Case4: 8位皇后
例如要求所有变量取值不同,可以用全局约束alldifferent表示。在8个皇后问题问题,原始模型如下图左,每列放一个值1,行不确定,所有元素的行不同row[i] ≠ row[j],上对角线不能相同row[i] + i ≠ row[j] + j,下对角线不能相同row[i] - i ≠ row[j] - j。转化成全局约束如下图右,用一个alldifferent可表示原先的三个约束。

(1)那为什么需要全局约束?
- 全局约束能更快检测是否有可行解
从全局约束角度:要求x1,x2,x3不能相同,域中只有1,2取值,因此无可行解。从元素约束角度:包含三个约束x1 ≠ x2, x2 ≠ x3, x3 ≠ x1,对每一个约束都能找到满意的解,因此会判断有可行解。即一个全局约束和3个元素约束表达意思相同,但是最终结果不同,在约束规划中约束的设置非常重要。


- 全局约束使得可以更多地修剪搜索空间
从全局约束角度:可得x3 ≠ 2。从元素约束角度:对每一个约束,并不能缩小搜索空间。

Case5: 九宫格
九宫格模型如下:第一个约束代表每行不重复,第二个约束代表每列不重复,第三个约束代表3*3的方框元素不重复。

根据约束条件可以选出第一个确定的位置放2(不重复性),最终只有个两个位置是任意选择就能完成整个九宫格。

(2)最简单的全局约束(表格约束)

5. 对称性破缺(symmetry breaking)
许多问题都表现出对称性,搜索解空间的对称部分是无用的,对称性包括值对称和变量对称,使用对称性破缺可以解决该问题
Case6: Balanced Incomplete Block Designs (BIBDs)
平衡不完全区组设计(BIBDs)
- 输入:(v,b,r,k,l)
- 输出:v行b列的0/1矩阵,矩阵每行有r个1,每列有k个1,矩阵内积为l,即任意两行向量内积值为l
如下图为BIBDs矩阵,7*7矩阵,每行3个1,每列3个1,每两行内积为1,BIBDs矩阵是不唯一的,因此交换任意两行或者两列,都满足条件,即有很多解。为此引入词典排序(Lexicographic ordering),a = 0 1 1 0 0 1 0,b = 1 0 1 0 1 0 0,则a <= b,反之如果a = 1 1 1 0 0 1 0,则a >= b。调整所有行和所有列得到右图。

Case7: Scene Allocation
有一群演员Actor,一系列场景Scenes,拍摄天Days,fee[Actor]代表每个演员每天拍摄的费用,每个场景需要一些演员,每天最多拍摄k个场景。目的是安排每个场景在第几天拍摄能最小化总成本。下面模型中shoot[Scenes]代表决策变量,appears[Scenes]表示每个场景需要出现的演员,which[a in Actor] = setof(i in Scenes) member(a,appears[i])计算了每位演员需要参与的场景。目标函数fee[a] * or(s in which[a]) (shoot[s]=d)计算所有演员的拍摄费用。约束条件atmost(all(i in Days) 5,Days,shoot)限制每天最多拍摄k个场景。
该问题中的对称性在于:把第一天的所有场景和第二天的所有场景交换,解的目标值是一样的,也就是说,天和天没有区别。为了消除值的对称性,可以假设场景1只能安排在第一天,场景2可以安排在1,2天,以这样的规律每个场景只考虑已经使用过的天加上新一天。

6. 冗余约束(Redundant constraints)
冗余约束是可以在不改变可行区域的情况下从线性约束系统中省略的约束,捕捉到模型没有表现出来的关于解的性质。
- 语义冗余:不能排除任何解
- 计算意义(computationally significant):减少搜索空间
Case2: Magic Series(增加冗余约束)
以前文中的 Magic Series 为例,该问题有一些隐藏的可挖掘的约束条件,变量取值代表了这个数字在序列里出现的次数,因此取值是有边界的,比如不可能出现series[4] = 17,sum(i in D) series[i] = n表明所有数字出现的次数和应该等于序列长度。如果series[2] = 3,说明2出现了3次,有3个位置的取值为2,即有3个数字都出现了2次,按出现次数分类,还可以增加约束为sum(i in D) i * series[i] = n。这些约束条件不能影响可行域,但是能增加搜索效率。

- 表达解的性质;促进其它约束的传播
- 提供更全局的视角;结合已经存在的约束;改善交流
其中结合已经存在的约束也称为代理约束(Surrogate constraints)

Case8: Car Sequencing problem
有一些车Cars需要在一条装配线(assembly line)上生产 ,每类车都定制了一些可装配选项(Options)如空调,天窗等。装配线在移动而装配需要时间,因此每个生产单元都有容量约束,例如在相继到达的5辆车,最多只能有两辆车可以装配到天窗。汽车排序问题Car Sequencing problem是确定装配线上的汽车的顺序,以满足每组汽车选项的需求约束和每个生产单元的容量约束。
模型如下:Slots槽口,代表每台车的位置,Configs代表汽车类型,Options代表装配选项,demand[Configs]表示每类车的需求,nbCars表示总需求,lb[Options]和ub[Options]为容量约束上下界,requires[Options,Config] 为每类车需要装配的选项。

(1)决策变量
- lline[Slots]:每个槽口放置的汽车类型
- setup[Options,Slots]:0/1变量,如果slot[s] 有一个需要option o的车
(2)约束条件
- forall(c in Configs) sum(s in Slots) (line[s] = c) = demand[c]:汽车需求约束
- forall(s in Slots,o in Options) setup[o,s] = requires[o,line[s]]:定义setup变量
- forall(o in Options, s in 1..nbCars-ub[o]+1) sum(j in s..s+ub[o]-1) setup[o,s] <= lb[o]:容量约束,对每个slot的每个option,每ub[Options]个车组装该option最多只能有lb[Options]
(3)冗余约束
- forall(o in Options, i in 1..demand[o]) sum(s in 1..nbCars-i*ub[o]) setup[o,s] >= demand[o] - i*lb[o]:假设有一个option容量约束为2/3,总共需要生产12辆车,最后面3个槽口最多能装配2辆车,说明前面至少要有10个位置可以完成该option,同样思路从后往前推。

以下面为例说明过程:两个表slots和setup假设先安排一个class1 在slot1,class1的demand=1,因此slots表的第一行和第一列填入❌,option3容量约束为1/3,option1容量约束为1/2,因此setup表的第二列不能加工option1和option3,slots表的第二列不能放class5和class6,setup表第三列不能加工option3,slots表的第三列不能放class5。假设安排class2在slot2,更新slots表,根据冗余约束可知,setup表中的options2在10个位置里至少需要安排6个,因此剩余可推出剩余内容。

Case4: 8位皇后(对偶模型)
一个问题的模型构建方式有很多种,比如决策变量不同,这两个模型可能有互补优势,很难选择哪一个,有些约束在这个模型里容易表达,但是另外一些约束更容易在另外模型里表达,对偶模型的意义在于用多个模型表达一个问题并且用约束将其连接起来。在皇后问题中,可以把每列当成决策变量,也可以把每行当成决策变量。通过(row[c] = r) <=> (col[r] = c)找到行列关系。

7. 全局约束案例(Implement global constraints)
Case9: Binary Knapsack(dynamic program)
对于背包问题的全局约束可以使用动态规划表找到可行解并剪枝
- Forward Phase:从x1开始,如果选择x1,使用实线,否则使用虚线,遍历所有变量
- Backward Phase:全局约束要求值在10-12,去除一些线和点后,x4全为实线,因此x4=1

Case10: Alldifferent(matching algorithm)
有6个变量,每个变量有取值集合,要求找到所有变量取值不同的解,可以转化为二分图。如下图所示,二分图一边顶点x为变量,一边顶点v为值,每条边对应每个变量可取值。

(1)Feasibility:找到该二分图的最大匹配,如果最大匹配(maximum matching )大小为变量数,则存在可行解
交错路(alternating path):匹配边和非匹配边交错构成的路
增广路(augmenting path):起始点都为非匹配点的交错路
如何找到最大匹配:从任何匹配开始,改善这个匹配,直到没有改善空间。 如何改善匹配:将二分图变成有向图,找到增广路。如下图,初始匹配从bottom指向top,其余边从top指向bottom,增广路是从未匹配的点x开始到另一个位匹配的点v结束。
- 选择未匹配点x2,找到交错路x2-3-x5-4,改变边的方向,匹配新增x2
- 选择未匹配点x1,找到交错路x1-2-x4-4-x5-5,改变边的方向,找到最大匹配
搜索增广路可以用depth-first或者best-first,时间复杂度为O(|X|+|E|)

(2)Prune:如果边 (x,v) 不出现在任何最大匹配里,则将v从x的域D(x)中移除,有两种方法。
Naive approach:强制边 (x,v) 留在匹配中,也就是去除所有其它的边 (x,w),搜索最大匹配,如果最大匹配比变量数小,说明值v要从D(x)中移除。这种方法效率比较低。
Basic property (Berge, 1970):如果给定一个最大匹配M,某条边属于从未匹配点开始的偶数交错路或者偶数交错圈,那么这条边属于某些最大匹配(不是全部)。因此如果某条边不满足这两种情况,那说明这条边不属于任何最大匹配,对应的值可以移除。
- 给定匹配M,将二分图变成有向图,但是方向与之前相反,匹配边从top指向bottom,非匹配边从bottom指向top
- 搜索从未匹配点开始的偶数交错路(even alternating path starting from a free vertex):P
- 搜索偶数交错圈(even alternating cycle):C
- 移除所有不在M,P,C中的边
如下图,经过prune后x4不能取值2,x5不能取值3,4。时间复杂度为O((|X| + |V|) * |E|)

8.约束搜索策略
设置约束条件后还需要搜索策略找到解。

Case11: Euler Knight(First-fail principle)
First-fail principle:首先尝试最容易失败的地方,不要花时间在容易的部分,直接处理最难的部分。例如在8个皇后中,优先安排可选位置数最少的,图着色问题中,优先选择邻国最多的国家。使用Knight访问棋盘所有位置正好一次,Knight骑士是国际象棋中的棋子,类似中国象棋中的马,只能走三乘二的“日”字格。按照First-fail principle原则,从可跳位置最少的点开始。

Case4: 8位皇后(Variable/Value Labeling)
两个步骤:选择分配的变量;选择该变量的值
原始过程:forall(r in R)迭代所有queens;tryall(v in R)非确定性的探索所有值,每次只尝试分配一个值,如果下一步增加该约束后无解,则返回该步重新赋值;row[r] = v增加一个约束到约束空间里。
优化搜索后:
- variable:forall(r in R) by row[r].getSize() 按照First-fail原则选择有最小域的变量,每一次新增约束后,各变量的域会发生变化,每次选择都保持First-fail原则。
- value:tryall(v in R) by col[v].getSize() 选择能尽可能移除其它变量域的值。

Case12: The ESDD Deployment Problem(not)
Generalized quadratic assignment problem(广义二次分配模型)
f代表组件之间的交流频率,h代表机器之间的距离,x为决策变量,表示每个组件在哪台机器上,C是组件集合,有两个约束条件:separation constraints分离约束,colocation constraints并置约束。通过决定每个组件放在哪台机器上使通信负担最小。
- selectMax(i in C:!x[i].bound(),j in C)(f[i,j]):首先选择有最大通信频率的组件
- tryall(n in N) by (min(l in x[j].memberOf(l)) h[n,l]) :尝试安排到距离最小的机器

Case13: The perfect square problem(Value/variable labeling)
Value/variable labeling有两个步骤:选择下一次要分配的值;选择这个值要分配给哪个变量。
在The perfect square problem问题中,需要将多个尺寸不一的正方形放进一个大正方形中

决策变量:每个正方形左下角的坐标 x[Square]和y[Square]
约束条件:
- 任何坐标都不超过大正方形的顶点坐标
- 各个正方形不能重叠
- 冗余约束:对于任何直线x=p(y=p),其穿过的正方形边长之和等于大正方形的边长

如何使用 Value/variable labeling 搜索解:选择一个x坐标p,遍历所有方块,考虑方块i,决定是否将方块i放置在位置p。对所有的x坐标和y坐标重复上述过程。
Case14: The magic square problem(Domain splitting)
正方形里填入数字,每行,每列,斜对角线和相同,数学模型如左下,在搜索该问题解时,不能使用 Variable/Value Labeling等策略,当规模变大时,如何选择分配的变量是很难抉择的。Domain splitting选择一个变量将其域分成好几个集合

Case8: Car Sequencing problem(Domain splitting)
前面的模型是为每个slot分配option,现在遍历所有的option,决定slot是否接受该option,从松弛时间最少的option开始。

Case7: Scene allocation(symmetry breaking during search)
在Scene allocation案例中,为了破坏对称性,限制了每个场景可选天。每次选择一个场景分配拍摄天时,都是从已经存在的days加上new day中按照启发式规则选择具体的日期(选择拍摄费用最小的日期),因此对称性破坏的约束条件可以动态的添加到搜索过程中,就像给图着色时,每着色一个点要更新其它的点的域,动态着色。

Case14: The magic square problem(Randomization and restarts)
对于有些问题没有明显的搜索顺序,可以先尝试随机顺序,设定搜索时间,在限定时间内没有找到解就重置搜索。 下面的搜索过程结合了Domain splitting和Randomization and restarts

9.图着色编程作业
用networkx求解图着色问题,代码GitHub - bujibujibiuwang/Discrete-Optimization-Solution: The University of Melbourne Discrete Optimization Course
-
相关阅读:
【snmp离线安装】了解国产操作系统OS以及离线安装教程
ARM_day9 按钮控制LED灯、蜂鸣器、风扇实验
题解_notion(持续更新ing)
SSID简介
redis的三种启动方式(后台运行)
MATLAB编程:绘制折线图 以及 画图的一些小技巧
如何看待unity新的收费模式
Node直接执行ts文件
10、文本处理工具
2024全国水科技大会暨土壤和地下水污染防治与修复技术创新论坛(七)
- 原文地址:https://blog.csdn.net/weixin_45526117/article/details/127637489