-
Linux_gdb_进程概念
目录
进度条
学习过程

首先创建源文件,这个源文件就是我们要写的进度条的定义
接下来,我们创建文件Makefile,在这个文件中,我们来实现依赖关系和依赖方法

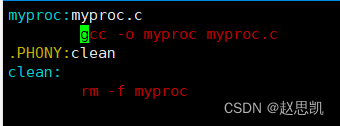
依赖关系:myproc依赖于myproc.c
依赖方法: 通过myproc.c的源文件通过编译汇编链接形成对应的可执行程序myproc
.PHONY表示对于clean,我们可以重复使用
clean没有依赖关系,也就是不需要其他文件也可以执行。
clean的依赖方法是删除myproc
我们对源文件myproc.c这样写

我们先来测试makefile写的是否正确。

make默认执行的是Makefile中的第一个指令。

完成了编译链接形成可执行程序,我们对可执行程序进行调用。

我们成功打印出hello world ,表示我们的makefile的书写没有错误。
接下来,我们用多文件的形式写进度条

我们创建三个文件,两个源文件main.c和process.c以及一个头文件process.h。

在process.h中,我们写一个防止头文件被多次包含,并且写一个进度条函数的声明。
在process.c中,我们主要完成进度条函数的定义。
在main.c中,我们主要完成进度条函数的调用。
我们使用vim对Makefile内容进行编辑。

我们要形成的文件叫做ProcessOn,我们的依赖方法是两个源文件。
注意:当源文件和头文件在同一个目录里面,我们就不需要把头文件也写入依赖关系之中,编译器会帮我们寻找头文件。
我们的依赖方法是通过main.c和process.c两个源文件以及未写出来的process.h一个头文件经过编译链接形成可执行程序ProcessOn
我们使用make


我们多出来了一个可执行程序ProcessOn
我们进行执行

证明我们写的多文件是没有问题的。
对于我们的依赖方法,我们这样写也是可以的。


我们创建一个数组bar,数组的元素个数为101,我们先把数组全部初始化为0,当cnt小于等于100时,我们以字符的形式打印数组,并对数组赋值,每次进入while循环都会休眠一秒,我们进行调用。
但是我们打印的结果却是这样:

原因是我们打印的时候误加上了\n

我们去掉这里的\n

这时候,我们执行代码

却又什么都刷新不出来。
原因是printf打印的数据被放在了缓冲区上面,假如我们要显示输出,我们需要使用fflush刷新一下缓冲区。

刷新标准输出
但是我们却又发现打印的速度不均匀,打印的速度是越来愈快的。
原因是我们每一次输出就会将前一次的数据也进行输出。
所以我们可以使用/r,表示回车(回到这一行的开头)

我们进行调用

这时候,我们是的速度是均匀打印的了。
但是我们发现刷新的速度太慢了,我们有没有办法加快刷新速度呢?
我们查看usleep指令


usleep和sleep的作用类似,不同点在于sleep的单位是秒,而usleep的单位是微秒,而一秒等于10^6微秒。
假如我们想要实现5s打印完毕

我们成功实现
接下来,我们实现最简单的进度条

%%表示显示%,我们进行调用展示

我们也可以多一些显示方式:
例如:

我们让进度条的数字后面的加一个动态的旋转。

我们再让动态条多几种格式


我们可以通过修改n值来使符号发生改变
这里的N我们可以在Makefile中进行修改

表示在编译链接形成可执行程序之前,已经设置了N为3
我们可以把N修改成为4,查看结果


这时候符号变成了加号。
自主实现:
main函数:
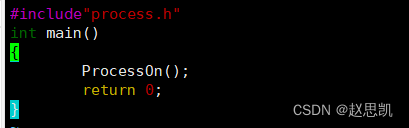
process.c文件

process.h

Linux的git操作
首先,我们创建一个学习Linux的仓库

接下来,我们点击克隆/下载,复制仓库链接

使用https这个复制方法
接下来,打开xshell
输入git clone+复制的链接

接下来,我们输入git的用户名和密码


然后克隆成功,我们使用ll显示文件

这个learn -linux就是我们本地的仓库,我们使用cd指令进入该仓库的目录
我们使用ll显示全部文件的详细信息

我们发现,我们本地的仓库缺了一个文件

这个.开头的文件是隐藏文件,我们需要使用ls -al才能看到这个隐藏文件

.gitignore
我们使用vim来查看这个文件的内容

我们可以发现,这个文件中的内容全部都是后缀,这个.gitignore文件起的作用就与这些后缀有关。
.gitignore文件中的内容中出现的后缀对应的文件,即使我们上传到远端,远端也不会被同步。
总的来说.gitignore文件中出现的后缀对应的文件是被忽略的。
.git
这个.git对应的文件就是我们的本地仓库,我们可以使用tree命令以树状结构的形式显示一下。


所以git仓库,本质上就是.git文件中的内容,把文件上传到远端本质是将你的.git中的文件同步到远端gitee上。
我们把一个目录上传到我们的learn.linux文件中。

git add .
我们使用git add .

表示我们把新增加的process文件添加到本地仓库.git中。
接下来,我们使用commit命令,提交的意思
git commit
格式为git commit -m '信息',这里的信息是不能胡乱写的。


commit的意思是提交,不是将代码提交到远端,而是把新增的变化的代码提交到本地仓库.git
add是吧这些文件放到了.git的临时区域,而commit是直接把文件提交到了本地仓库。
git push

git push相当于把本地仓库和远端的仓库进行同步。
 这时候,我们的远端就成功上传了该文件。
这时候,我们的远端就成功上传了该文件。git log
git log显示我们的提交日志


这就是为什么git commit -m这里的显示信息我们不可以乱写的原因。
git status
git status可以显示仓库状态

git pull

假如我们对远端的仓库进行重命名,实质上是进行了修改,然后我们在本地仓库也对process文件中的内容进行修改
我们多打印一行换行。
然后我们使用git commit 和git push

这里就会显示出现了冲突,我们需要使用git pull
git push是本地的同步远端,那么git pull就是远端同步本地。

这时候,我们就把远端的仓库同步到了本地
然后我们重复git commit git push即可。

我们这里就完成了修改。
-
相关阅读:
Mybatis KeyGenerator生成主键
已解决 Bug——SyntaxError: Unexpected token o in JSON at position 1问题
自定义子组件的v-model
通过随机平滑验证对抗鲁棒性
Qt编译MySQL数据库驱动
Java/Python/Go不同开发语言基础数据结构和相关操作总结-GC篇
腾讯云发送短信
代码解释【待解决】
LQ0266 巧排扑克牌【模拟】
Movicon软件
- 原文地址:https://blog.csdn.net/qq_66581313/article/details/127772463