-
如何利用python将xmind转为Excel?
1.环境准备
需要先安装xmindparser模块,安装方法较为简单,直接运行pip命令即可。
pip install xmindparser- 1
2.源数据构造及流程解析
2.1 准备xmind文件
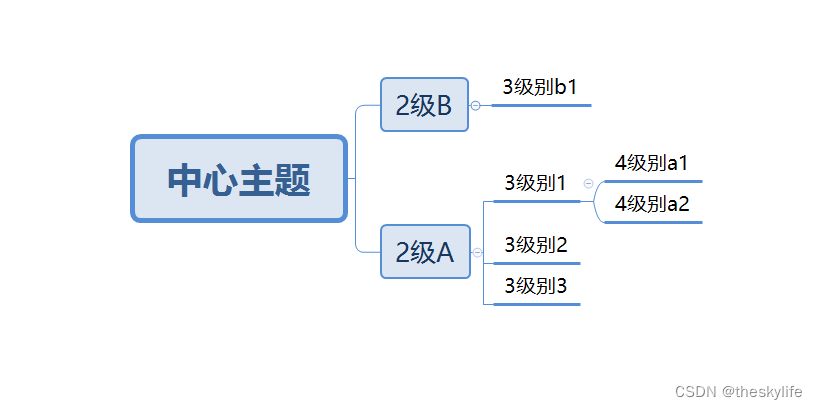
构建好xmind文件后,将其命名为test.xmind,其图像如下:
2.2 解析xmind文件
利用xmindparser对2.1中的xmind文件进行解析,解析后效果如下:

解析代码如下:from xmindparser import xmind_to_dict x_flie = r'Test.xmind' json_data= xmind_to_dict(x_flie)- 1
- 2
- 3
2.3 对解析后的数据进行处理
由于解析后的数据不符合写出的要求,故需要对这部分数据进行处理。由于本人喜欢用pandas进行数据处理,故在此构建dataframe进行输出。
2.3.1 处理1——提取数据
对2.2中解析后的数据进行处理,按照层次进行组合,得到效果如下的数据:

实现代码如下:# 可以设想为一个树结构,利用递归函数,获取由根至各叶子节点的路径。 def xm_parse(dic, pre_data=[]): """输入一个由xmindparser,转换而来的字典形式的数据,将之转换成列表""" title_list = [] topic_list = [] try: topics = dic.get("topics") title = dic.get("title") # 将前缀追加 title_list.append(title) title_list = pre_data + title_list # 如果到达末尾,就返回 if topics is None and title: yield title, title_list # print(title,title_list) return # 如果是列表,就暂存起来(若每个对象为标准的列表,即 topics= topic_list,则可以跳过该步骤) elif isinstance(topics, list) and title: for topic in topics: topic_list.append(topic) except AttributeError as e: print("异常结束") return # 若列表不为空,则需要递归寻找 if topic_list: for topic in topic_list: yield from xm_parse(topic,title_list)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.3.2 处理2——填充数据
经2.3.1的过程处理后的数据,并不能直接作为参数直接转换为DataFrame,需要将数据处理成以下形式:

实现代码如下:temp=[] max_cols=0 #提取数据,并找出最大深度(列数) for i,j in xm_parse(json_data[0]['topic']): temp.append(j) max_cols= max_cols if max_cols > len(j) else len(j) #对缺失数据采用补全 for i in range(len(temp)): temp[i] = temp[i] + (max_cols - len(temp[i])) * [None]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.3.3 处理3——转换成DataFrame
转换后,效果如下:

实现代码如下:
result=pd.DataFrame.from_records(temp,columns=["标题-{}".format(i+1) for i in range(max_cols)])- 1
3.完整代码
from xmindparser import xmind_to_dict import pandas as pd # 可以设想为一个树结构,利用递归函数,获取由根至各叶子节点的路径。 def xm_parse(dic, pre_data=[]): """输入一个由xmindparser,转换而来的字典形式的数据,将之转换成列表""" title_list = [] topic_list = [] try: topics = dic.get("topics") title = dic.get("title") # 将前缀追加 title_list.append(title) title_list = pre_data + title_list # 如果到达末尾,就返回 if topics is None and title: yield title, title_list # print(title,title_list) return # 如果是列表,就暂存起来(若每个对象为标准的列表,即 topics= topic_list,则可以跳过该步骤) elif isinstance(topics, list) and title: for topic in topics: topic_list.append(topic) except AttributeError as e: print("异常结束") return if topic_list: for topic in topic_list: yield from xm_parse(topic,title_list) def main(): x_flie=r"Test.xmind" out_file=r"xmind转换后.xlsx" temp=[] max_cols=0 json_data= xmind_to_dict(x_flie) #提取数据,并找出最大深度(列数) for i,j in xm_parse(json_data[0]['topic']): temp.append(j) max_cols= max_cols if max_cols > len(j) else len(j) #对缺失数据采用补全 for i in range(len(temp)): temp[i] = temp[i] + (max_cols - len(temp[i])) * [None] result=pd.DataFrame.from_records(temp,columns=["标题-{}".format(i+1) for i in range(max_cols)]) result.to_excel(out_file,index=False,encoding='utf-8-sig') if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
-
相关阅读:
深度学习笔记_1、定义神经网络
从数字化到智能化再到智慧化,智慧公厕让城市基础配套更“聪明”
分享股票下单API接口的方式和API攻略
第1章Python语言基础-1.1变量与表达式(二)
wayland(xdg_wm_base) + egl + opengles 渲染旋转的 3D 立方体实例(十一)
java毕业设计大学生学习时间规划平台服务端mybatis+源码+调试部署+系统+数据库+lw
全网独家:编译CentOS6.10系统的openssl-1.1.1多版本并存的rpm安装包
不定积分(原函数)存在性定理、定积分存在性定理、变限积分存在性定理
Spring Boot项目的搭建和运行
IDEA的使用(二)快捷键 (IntelliJ IDEA 2022.1.3版本)
- 原文地址:https://blog.csdn.net/qq_41780234/article/details/126153444
