-
Numpy手撸softmax regression
算法介绍
Softmax 回归(或多项逻辑回归)是将逻辑回归推广到我们想要处理多个类的情况。 在逻辑回归中,我们假设标签是二元的: y ( i ) ∈ { 0 , 1 } y^{(i)} \in \{0,1\} y(i)∈{0,1},我们使用这样的分类器来区分两种手写数字。 Softmax 回归允许我们处理 y ( i ) ∈ { 0 , 1 , . . . , C } y^{(i)} \in \{0,1,...,C\} y(i)∈{0,1,...,C}其中 C C C是类的数量。
数据集格式

模型
多组回归配合Softmax函数
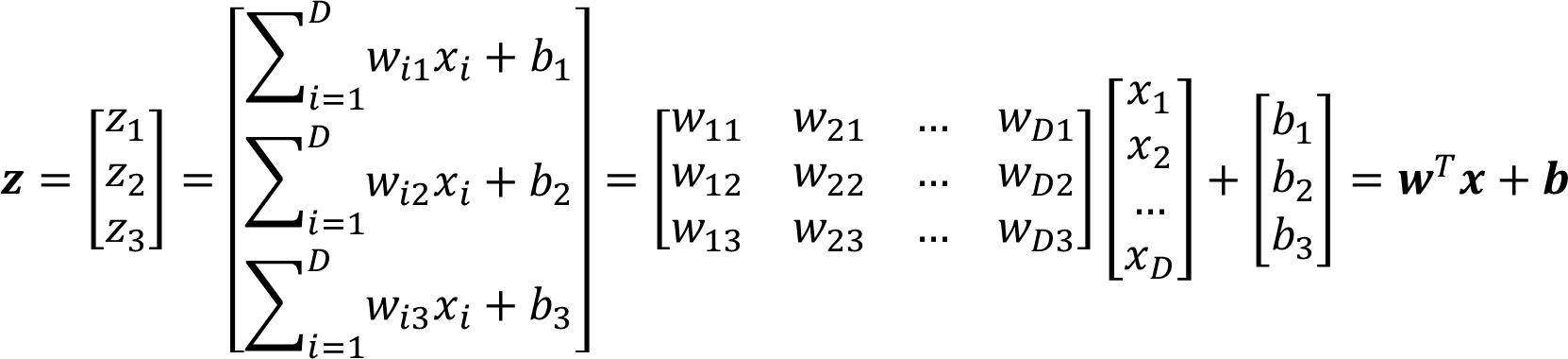

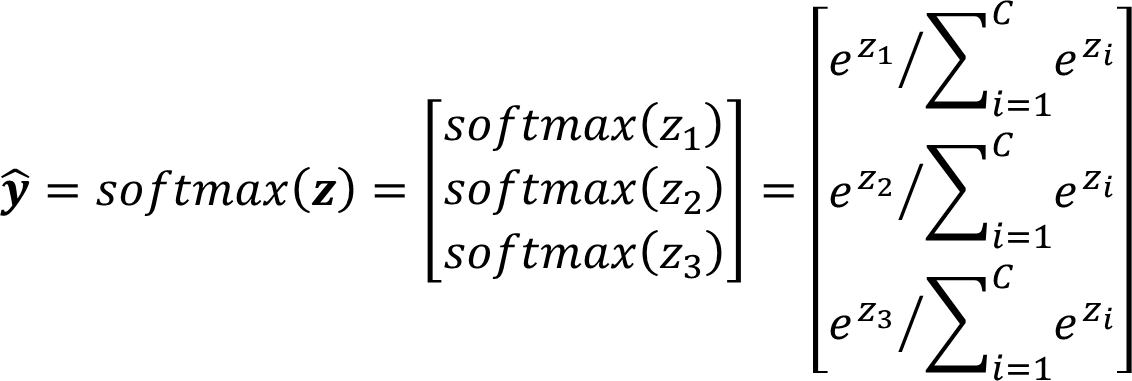
Softmax 函数定义
def softmax(z): hat_z = [0]*len(z) for i in range(len(z)): hat_z[i] = np.exp(z[i])/np.sum(np.exp(z)) return hat_z- 1
- 2
- 3
- 4
- 5
y 函数计算
z = np.dot(W[:,1:],x[1:]) + np.dot(W[:,0],x[0]) hat_y = softmax(z)- 1
- 2
Loss 和 Cost 函数
Loss Function(Cross Entropy):
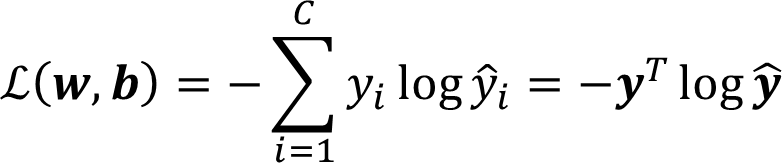
Cost Function:

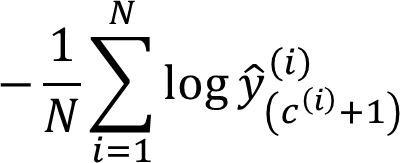
Cost 代码部分
j = j - np.dot(Y[i],np.log(hat_y).T)- 1
梯度
W矩阵梯度计算:
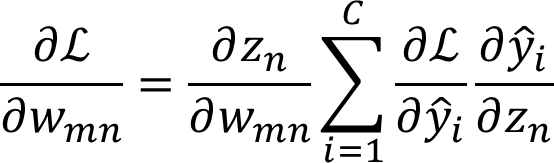
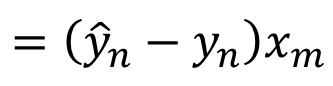
常数项梯度计算:
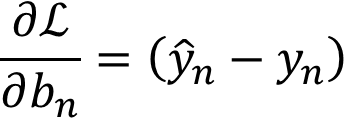
梯度代码部分
G 初始为 [C,D+1]的0矩阵,包含W和b的所有参数:
G[:,1:] = G[:,1:] + np.array(hat_y - Y[i]).reshape((3,1)).dot(np.array(x[1:]).reshape((1,3))) ###### Gradient G[:,0] = G[:,0] + (hat_y - Y[i])- 1
- 2
代码汇总
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt def softmax(z): hat_z = [0]*len(z) for i in range(len(z)): hat_z[i] = np.exp(z[i])/np.sum(np.exp(z)) return hat_z def cost_gradient(W, X, Y, n): G = np.zeros(W.shape) j = 0 for i in range(n): x = X[i] z = np.dot(W[:,1:],x[1:]) + np.dot(W[:,0],x[0]) hat_y = softmax(z) G[:,1:] = G[:,1:] + np.array(hat_y - Y[i]).reshape((3,1)).dot(np.array(x[1:]).reshape((1,3))) ###### Gradient G[:,0] = G[:,0] + (hat_y - Y[i]) j = j - np.dot(Y[i],np.log(hat_y).T)###### cost with respect to current W G = G/n j = j/n return (j, G) def train(W, X, Y, n, lr, iterations): J = np.zeros([iterations, 1]) for i in range(iterations): (J[i], G) = cost_gradient(W, X, Y, n) W = W - lr*G print("epoch:",i,"error:",error(W, X, Y)) return (W,J) def error(W, X, Y): Y_hat = [] for i in range(n): x = X[i] z = np.dot(W[:, 1:],x[1:]) + np.dot(W[:, 0], x[0]) Y_hat.append(softmax(z))###### Output Y_hat by the trained model pred = np.argmax(Y_hat, axis=1) label = np.argmax(Y, axis=1) return (1-np.mean(np.equal(pred, label))) iterations = 500###### Training loops lr = 1e-1###### Learning rate data = np.loadtxt('SR.txt', delimiter=',') n = data.shape[0] X = np.concatenate([np.ones([n, 1]), np.expand_dims(data[:,0], axis=1), np.expand_dims(data[:,1], axis=1), np.expand_dims(data[:,2], axis=1)], axis=1) Y = data[:, 3].astype(np.int32) c = np.max(Y)+1 Y = np.eye(c)[Y] W = np.random.random([c,X.shape[1]]) b = np.random.random(X.shape[1]) (W,J) = train(W, X, Y, n, lr, iterations) plt.figure() plt.plot(range(iterations), J) plt.show() print(error(W,X,Y))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
需要数据集的同学私我 -
相关阅读:
微信小程序毕业设计 电影购票+后台管理系统
Python 数据可视化:Matplotlib库的使用
业务需求不用等!低代码开发平台随需响应、快速搭建
【gtp&JavaScript】使用JavaScript实现套壳gtp与gtp打字输出效果
盘点 JavaScript 中类的继承
面试官:IoC 和 DI 有什么区别?
2732. 找到矩阵中的好子集
Android笔记: 设置PopupMenu宽度
Fast.ai 深度学习实战课程「中文字幕」
4. Linux-riscv内存管理17-20问
- 原文地址:https://blog.csdn.net/pylittlebrat/article/details/127767332
