-
Java进阶3 - 易错知识点整理(待更新)
Java进阶3 - 易错知识点整理(待更新)
该章节是Java进阶2- 易错知识点整理的续篇;
在前一章节中介绍了ORM框架,中间件相关的面试题,而在该章节中主要记录关于项目部署中间件,监控与性能优化等常见面试题。14、ElasticSearch(倒排索引、集群/节点、分片/副本、分布式全文检索引擎、master/slave)
参考
以下是常见的面试题:
-
【问】Elasticsearch是什么?ES的三大特点是什么?(
Elasticsearch是一个开源的高扩展的分布式全文检索引擎;ES的三大特点:支持复杂查询、可扩展性强、容灾性能好且支持高可用),参考什么是ElasticSearch?看完这一篇你就懂了,Elasticsearch和mysql最直观的区别介绍Note:
-
Elaticsearch简写是ES,Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。 -
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,通过面向文档从而让全文搜索变得简单。 -
ES的三大特点:-
轻松支持各种复杂的查询条件:分布式实时文件存储,采用倒排索引及自定义打分、排序能力与丰富的分词插件等,实现复杂查询条件的全文检索需求。
-
可拓展性强:天然支持分布式存储,可简单实现上千台服务器的分布式横向扩容。
-
高可用,容灾性能好:通过主备节点及故障自动检测与恢复,实现高可用。
-
-
-
【问】Elasticsearch的核心概念有哪些?并从整体架构的角度简单概述?(倒排索引,集群、节点、分片、副本,全文检索、全文数据库),参考什么是ElasticSearch?看完这一篇你就懂了,Elasticsearch和mysql最直观的区别介绍
Note:
-
1. 倒排索引
首先要了解索引表:由关键词为key,关键词位置属性为value组成的一张表。由于该表不是由key来确定value值,而是由value的属性值来确定key的位置,所以称为倒排索引,带有倒排索引的文件称为倒排文件。通俗的讲倒排索引就好比书的目录,通过目录咱们可以准确的找到相应的数据。 -
2. Cluster(集群)
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。 -
3. Node(节点)
形成集群的每个服务器称为节点。 -
4. Shard(分片)
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。 -
5.Replia(副本)
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。 -
6.全文检索 / 全文数据库
- 全文检索就是对一篇文章进行索引搜索,可以根据关键字搜索,类似于
mysql里的like语句。全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。 - 关于全文检索需要理解的就是:全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能(也即是分词的功能),而且所有全文数据库基本都离不开有海量的信息数据库。
- 全文检索就是对一篇文章进行索引搜索,可以根据关键字搜索,类似于
-
ES的整体结构如下:

-
一个 ES Index 在集群模式下,有多个 Node (节点)组成。每个节点就是 ES 的Instance (实例)。
-
每个节点上会有多个 shard (分片), P1 P2 是主分片, R1 R2 是副本分片
-
每个分片上对应着就是一个 Lucene Index(底层索引文件)
-
Lucene Index是一个统称,由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。 -
commit point记录了所有 segments 的信息
-
-
底层和数据文件包括:
-
倒排索引(词典+倒排表)
-
doc values - 列式存储
-
正向文件 - 行式存储

-
-
-
-
【问】MySQL与ElasticSearch的对比?(概念上的对比,架构设计的初衷:MySQL创建之初是为了做大量数据存储来使用的;而
ES的设计初衷是为了支持海量数据的秒级甚至毫秒级查询),参考什么是ElasticSearch?看完这一篇你就懂了,Elasticsearch和mysql最直观的区别介绍,ElasticSearch与Mysql对比(ElasticSearch常用方法大全,持续更新)Note:
-
Elasticsearch与mysql的概念对比:Elasticsearch MySQL Index(索引) Database(关系型数据库) Type(类型) Table(数据表) Document(文档) Row(行) Schema Mapping(映射) Everything is indexed index(索引) Fields(字段) Column(列) GET http://...SELECT * FROM table...PUT http://...UPDATE table SET... -
Elasticsearch的分布式架构设计如何支持海量数据的秒级甚至毫秒级查询,主要有两点原因:-
最主要的原因就是它所用的倒排索引方式生成索引,避免全文扫描。
-
正排索引说的是通过文档来查找关键词:要把每个文档的内容拿出来查找是否有此单词,毫无疑问这样的话会导致全表扫描;
-
倒排索引反之,是通过关键词来查找文档的形式:首先会将每个文档内容进行分词,然后建立每个分词与包含有此分词的文档之前的映射关系,如果有多个文档包含此分词,那么就会按文档的权重将文档进行排序;
-
-
除了我们所提到的倒排索引以外,
Elasticsearch分布式同样让其适合数据查询:- 一个集群有多个
node节点组成,每个index(索引)也是以分片的数据存在以多个node节点上,然后当有查询条件请求过来的时候,分别在各个node查询相应的结果并整合后便可。将查询压力分散到各个节点上,也避免了其对于磁盘、内存等处理能力与空间的不足; - 它还采用了主备分片提升搜索吞率,使用节点故障探测,
RESTful的选主机制等提升了容灾能力等等(因为Elasticsearch是基于RESTful web接口);
- 一个集群有多个
-
-
-
【问】elasticsearch 的倒排索引是什么?倒排索引是如何生成的?(
ES的倒排索引是基于Lucene实现的;正排索引说的是通过文档来查找关键词,而倒排索引则是通过关键词来查找文档;倒排索引在生成时需要对文档进行分词,然后将分词作为key(索引表),文档编号等信息作为value(value用list存储,即为记录表),进而得到一张map),参考ElasticSearch倒排索引详解Note:
-
倒排索引是区别于正排索引的概念:
- 正排索引:是以文档对象的唯一
ID作为索引,以文档内容作为记录。 - 倒排索引:
Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档ID作为记录。

- 正排索引:是以文档对象的唯一
-
倒排索引的生成过程:假设目前有以下两个文档内容:
苏州街维亚大厦
桔子酒店苏州街店其处理步骤如下:
1、正排索引给每个文档进行编号,作为其唯一的标识。

2、生成倒排索引:
- 首先要对字段的内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词,这里两个文档包含的关键词有:苏州街、维亚大厦…
- 然后按照单词来作为索引,对应的文档
id建立一个链表,就能构成上述的倒排索引结构。

3、有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。例如,如果需要在上述两个文档中查询 “苏州街桔子” ,可以通过分词后 “苏州街” 查到 1、2,通过 “桔子” 查到 2,然后再进行取交取并等操作得到最终结果。

-
-
【问】elasticsearch 的倒排索引的结构是怎样的?
Lucene如何降低倒排索引的存储成本以及如何提高倒排索引的搜索性能?(ES的倒排索引是基于Lucene实现的;倒排索引的结构包括索引表和记录表:索引表(key,Term Dictionary)由分词构成,而记录表(value,Postings List)由文档id、分词词频、位置、偏移量(可用于高亮显示)等信息构成;在Lucene中,Postings List通过.doc,.pay,.pos文件对所有Term的id、位置等进行信息独立存储,而Term Dictionary存储了每个Term和其对应的 Postings 文件位置指针),参考ElasticSearch倒排索引详解Note:
-
Elasticsearch的倒排索引是基于Lucene实现的。Lucene是一个开源的全文搜索引擎库,而Elasticsearch则是构建在Lucene之上的分布式搜索和分析引擎。Elasticsearch利用Lucene的强大搜索功能和索引结构,提供了更简单、更易于使用的API和分布式特性。 -
根据倒排索引的概念,我们可以用一个
Map来简单描述这个结构。这个Map的Key的即是分词后的单词,这里的单词称为Term,这一系列的Term组成了倒排索引的第一个部分 ——Term Dictionary(索引表,可简称为Dictionary)。倒排索引的另一部分为
Postings List(记录表),也对应上述Map结构的Value部分集合。记录表由所有的
Term对应的数据(Postings) 组成,它不仅仅为文档 id 信息,可能包含以下信息:-
文档
id(DocId,Document Id),包含单词的所有文档唯一 id,用于去正排索引中查询原始数据。 -
词频(
TF,Term Frequency),记录 Term 在每篇文档中出现的次数,用于后续相关性算分。 -
位置(
Position),记录Term在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)。 -
偏移(
Offset),记录Term在每篇文档的开始和结束位置,用于高亮显示等。
-
-
Lucene倒排索引实现:全文搜索引擎在海量数据的情况下是需要存储大量的文本,所以面临以下问题:
-
Dictionary是比较大的(比如我们搜索中的一个字段可能有上千万个Term) -
Postings可能会占据大量的存储空间(一个Term多的有几百万个doc)
因此上面说的基于Map的实现方式几乎是不可行的。
在海量数据背景下,倒排索引的实现直接关系到存储成本以及搜索性能。
为此,
Lucene引入了多种巧妙的数据结构和算法。其倒排索引实现拥有以下特性:-
以较低的存储成本存储在磁盘 (索引大小大约为被索引文本的20-30%)
-
快速读写
-
-
下面将根据倒排索引的结构,按
Posting List和Terms Dictionary两部分来分析Lucene中的实现。-
Posting List实现:PostingList包含文档 id、词频、位置等多个信息,这些数据之间本身是相对独立的,因此Lucene将Postings List被拆成三个文件存储:-
doc后缀文件:记录Postings的docId信息和Term的词频 -
pay后缀文件:记录Payload信息和偏移量信息 -
pos后缀文件:记录位置信息
基本所有的查询都会用
.doc文件获取文档id,且一般的查询仅需要用到.doc文件就足够了,只有对于近似查询等位置相关的查询则需要用位置相关数据。三个文件整体实现差不太多,这里以
.doc文件为例分析其实现。-
.doc文件存储的是每个Term对应的文档 Id 和词频。 -
每个
Term都包含一对TermFreqs和SkipData结构。其中TermFreqs存放docId和词频信息,SkipData为跳表信息,用于实现TermFreqs内部的快速跳转。

-
-
Term Dictionary实现:Terms Dictionary(索引表)存储所有的Term数据,同时它也是Term与Postings的关系纽带,存储了每个Term和其对应的Postings文件位置指针。
-
-
-
【问】elasticsearch 是如何实现 master 选举的(基于
ZooKeeper或内置的Zen Discovery协议的分布式协调机制实现集群的自动发现和自我调整(若选举的master节点失效/离线、则重新选举);每个节点都可以成为候选master节点、并向其他节点发送投票请求,其他节点会根据优先级计算要投给哪个候选master,最后广播统计选举结果并确认最终的master节点;master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理,而data节点可以关闭http功能),参考Elasticsearch是如何实现Master选举的?Note:下面部分参考
ChatGPT-
在
Elasticsearch中,Master节点的选举是通过集群中的节点协调机制(基于ZooKeeper或内置的Zen Discovery协议的分布式协调机制)实现的。如果当前的Master节点失效或离线,集群中的其他节点会触发新一轮的Master选举过程,确保集群的高可用性。当一个Elasticsearch集群启动时,所有的节点都会参与Master节点的选举(ChatGPT)。以下是
Master选举的大致过程:-
启动阶段:每个节点在启动时都会尝试成为
Master候选节点。它们会发送选举请求(Election Request)到集群中的其他节点。 -
选举开始:当一个节点收到选举请求后,会比较各个候选节点的优先级(通过配置的节点名称或IP地址进行比较)。节点会选择优先级最高的候选节点作为
Master。 -
选举结果广播:选举成功的候选节点将发送选举结果(
Election Response)给其他节点,通知它们新的Master节点的身份。 -
Master节点确认:所有节点都会接收到选举结果,并确认新的Master节点。节点将更新自己的集群状态,并将其作为参考用于后续的请求和协调操作。
-
-
Zen Discovery是Elasticsearch内置的一种分布式协调机制,用于在Elasticsearch集群中实现节点的发现和协调。它的主要功能是帮助新加入或离开集群的节点与现有节点进行通信和协调,以实现集群的自动发现和动态调整(ChatGPT)。Zen Discovery协议的工作原理如下:-
初始节点列表:在启动
Elasticsearch时,每个节点都会配置一个初始的节点列表,用于引导集群的启动过程。 -
节点发现:当一个新的节点加入集群时,它会尝试连接初始节点列表中的任意一个节点,并发送节点发现请求。
-
发现节点信息:已存在的节点接收到节点发现请求后,会将自己的信息(包括节点
ID、IP地址、端口等)发送给新加入的节点。 -
集群状态更新:新加入的节点收集到足够的节点信息后,会更新自己的集群状态,将这些节点信息作为集群的一部分。
-
节点加入:新加入的节点被接受并加入集群后,会与其他节点建立连接,并参与后续的数据交换和协调操作。
Zen Discovery协议的优点是它能够自动发现新节点和离开的节点,动态调整集群的拓扑结构,使得集群可以在节点变动时继续正常运行,而无需手动配置和干预。它提供了简单而可靠的节点发现机制,帮助构建稳定和可扩展的Elasticsearch集群。 -
-
ES的选举是由ES内置的一种分布式协调机制ZenDiscovery模块实现的,用于在ES集群中实现节点的发现和协调。它的主要功能是帮助新加入或离开集群的节点与现有节点进行通信和协调,以实现集群的自动发现和动态调整。主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;-
对所有可以成为
master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。 -
如果对某个节点的投票数达到一定的值(可以成为
master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
-
-
这里需要注意的是:
master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
-
-
【问】Elasticsearch 中的节点(比如共 20 个),其中的 10 个选了一个 master,另外 10 个选了另一个 master,怎么办?(平票会出现脑裂问题,候选节点不小于3个可通过设置投票数阈值解决,候选节点等于两个则直接修改为其中一个作为
master),参考Elasticsearch是如何实现Master选举的?Note:
-
当集群
master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题; -
当候选数量为两个时,只能修改为唯一的一个
master候选,其他作为data节点,避免脑裂问题。
-
-
【问】Elasticsearch 如何避免脑裂问题(修改主节点的最小投票阈值;修改因节点发生故障导致无法收到投票结果的时延),参考Elasticsearch是如何实现Master选举的?
Note:
-
1):修改集群中每个节点的配置文件(
elasticsearch.yml)参数discovery.zen.minimum_master_nodes,这个参数决定了主节点在投票过程中最少需要多少个 master 节点,默认配置是1。一个基本原则是这里需要设置成N/2+1,N是集群中节点的数量。 -
2):修改集群中每个节点的配置文件(
elasticsearch.yml)参数discovery.zen.ping.timeout,默认值是3,它确定节点在假定节点发生故障之前将等待集群中其他节点响应的时间。在网络速度较慢的情况下,稍微增加默认值绝对是个好主意。此参数不仅可以满足更高的网络延迟,而且在节点由于过载而响应较慢的情况下也很有用。 -
3):修改集群中每个节点的配置文件(
elasticsearch.yml)参数discovery.zen.ping.unicast.hosts,把集群中可能成为主节点的机器节点都配置到这个参数中。
-
-
【问】详细描述一下 Elasticsearch 索引文档的过程(索引文档即对文档建立索引的过程,包括客户端发送索引请求(发送请求、参数检查、数据预处理、自动创建索引、请求预处理、检测集群状态、路由算法及构建
shard请求、转发请求并等待响应)、主分片节点流程(先将文档写入到index Buffer缓存中,接着Refresh内存中的文档到Segment中(此时支持查询,以及定期将多个小Segment合并到大Segment中),最后Flush清空index Buffer并将Segment写入到磁盘中)、副本分片索引文档(主分片完成后,循环处理要写的所有副本分片)、请求返回),参考ElasticSearch索引过程,ElasticSearch系列 - 分布式文档索引、搜索、更新和删除文档的过程Note:
-
ES索引文档流程图如下:
-
ES索引文档具体流程分析如下:-
客户端发送索引请求:
-
客户端向
ES节点发送索引请求 -
参数检查:对请求中的参数进行检查,检查参数是否合法,不合法的参数直接返回失败给客户端。
-
数据预处理:如果请求指定了
pipeline参数,则对数据进行预处理,数据预处理的节点为Ingest Node,如果接受请求的节点不具有数据处理能力,则转发给其他能处理的节点。在
Ingest Node上有定义好的处理数据的Pipeline,Pipeline中有一组定义好的Processor,每个Processor分别具有不同的处理功能,ES提供了一些内置的Processor,如:split、join、set、script等,同时也支持通过插件的方式,实现自定义的Processor。数据经过Pipeline处理完毕后继续进行下一步操作。 -
自动创建索引:创建索引请求被发送到
Master节点,由Master节点负责进行索引的创建,索引创建成功后,Master节点会更新集群状态clusterstate,更新完毕后将索引创建的情况返回给Coordinate节点,收到Master节点返回的所有创建索引的响应后,进入下一流程。 -
请求预处理:
- 检查参数、自动生成
ID、处理routing等 - 获取集群状态信息,遍历所有请求,从集群状态中获取对应索引的元信息,检查
mapping、routing、id信息,如果请求没有指定文档的id,则会生成一个UUID作为文档的id。
- 检查参数、自动生成
-
检测集群状态:
Coordinate协调节点在开始处理时会检查集群状态,若集群异常(如果Master节点不存在)则取消写入。 -
路由算法及构建
shard请求:-
路由算法(在对文档创建索引时,计算该文档被索引到哪个分片ID):
路由算法即根据请求的
routing和文档id信息计算文档应该被索引到那个分片ID的过程。计算公式如下:shard_num = hash(_routing) % num_primary_shards- 1
默认情况下,
_routing就是文档id,num_primary_shards是主分片个数,所以从算法中即可以看出索引的主分片个数一旦指定便无法修改,因为文档利用主分片的个数来进行定位。
当使用自定义
_routing或者id时,按照上面的公式计算,数据可能会大量聚集于某些分片,造成数据分布不均衡,所以ES提供了routing_partition_size参数,routing_partition_size越大,数据的分布越均匀。分片的计算公式变为:shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards- 1
也就是说,
_routing字段用于计算索引中的一组分片,然后使用_id来选择该组内的分片。index.routing_partition_size取值应具有大于1且小于index.number_of_shards的值。 -
构建
shard请求:将用户的
bulkRequest重新组织为基于 shard 的请求列表。例如,原始用户请求可能有
10个写操作,如果这些文档的主分片都属于同一个,则写请求被合并为1个。根据路由算法计算某文档属于哪个分片。遍历所有的用户请求,重新封装后添加到上述map结构。Map<ShardId, List<BulkItemRequest>> requestsByShard = new HashMap<>();- 1
-
-
转发请求并等待响应:
-
根据集群状态中的内容路由表确定主分片所在节点,转发请求并等待响应。
-
遍历所有需要写的
shard,将位于某个 shard 的请求封装为BulkShardRequest类,调用TransportShardBulkAction#execute执行发送,在listener中等待响应,每个响应也是以shard为单位的。如果某个shard的响应中部分doc写失败了,则将异常信息填充到Response中,整体请求做成功处理。待收到所有响应后(无论成功还是失败的),回复给客户端。
-
-
-
主分片节点流程:
当主分片所在节点接受到请求后,节点开始进行本节点的文档写入,文档写入过程如下:

-
文档写入时,不会直接写入到磁盘中,而是先将文档写入到
Index Buffer内存空间中,到一定的时间,Index Buffer会Refresh把内存中的文档写入Segment中。当文档在Index Buffer中时,是无法被查询到的,这就是ES不是实时搜索,而是近实时搜索的原因。-
因为文档写入时,先写入到内存中,当文档落盘之前,节点出现故障重启、宕机等,会造成内存中的数据丢失,所以索引写入的同时会同步向
Transaction Log写入操作内容。 -
每隔固定的时间间隔
ES会将Index Buffer中的文档写入到Segment中,这个写入的过程叫做Refresh,Refresh的时间可以通过index.refresh_interval,默认情况下为1秒。 -
写入到
Segment中并不代表文档已经落盘,因为Segment写入磁盘的过程相对耗时,Refresh时会先将Segment写入缓存,开放查询,也就是说当文档写入Segment后就可以被查询到。 -
每次
refresh的时候都会生成一个新的segment,太多的Segment会占用过多的资源,而且每个搜索请求都会遍历所有的Segment,Segment过多会导致搜索变慢,所以ES会定期合并Segment,减少Segment的个数,并将Segment合并为一个大的Segment; -
在操作
Segment时,会维护一个Commit Point文件,其中记录了所有Segment的信息;同时维护.del文件用于记录所有删除的Segment信息。单个倒排索引文件被称为Segment。多个Segment汇总在一起,就是Lucene的索引,对应的就是ES中的shard。 -
Lucene倒排索引由单词词典及倒排列表组成:单词词典:记录所有文档的单词,记录单词到倒排列表的关系,数据量比较大,一般采用B+树,哈希拉链法实现。倒排列表:记录单词对应的文档集合,由倒排索引项组成。倒排索引项结构如表所示:其中,文档ID:记录单词所在文档的ID;词频:记录单词在文档中出现的次数;位置:记录单词在文档中的位置;偏移:记录单词的开始位置,结束位置。
-
-
每隔一定的时间(默认30分钟),
ES会调用Flush操作,Flush操作会调用Refresh将Index Buffer清空;然后调用fsync将缓存中的Segments写入磁盘;随后清空Transaction Log。同时当Transaction Log空间(默认512M)后也会触发Flush操作。
-
-
副本分片索引文档:
当主分片完成索引操作后,会循环处理要写的所有副本分片,向副本分片所在的节点发送请求。副本分片执行和主分片一样的文档写入流程,然后返回写入结果给主分片节点。
新建、索引和删除 请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片,如图所示:新建,索引和删除单个文档

以下是在主副分片和任何副本分片上面成功新建,索引和删除文档所需要的步骤顺序:
-
① 客户端向 节点 1 发送新建文档请求 (节点 1就是协调节点)。
-
② 协调节点根据文档的 id 确定文档属于分片 0 (路由计算)。请求会被转发到 节点 2,因为分片0的主分片目前被分配在 节点 2 上。
-
③ 节点 2 在主分片上面执行请求写入文档。如果成功了,它将请求并行转发到 节点 1 和 节点 3 的副本分片上。一旦所有的副本分片都报告写入成功, 节点 2 将向协调节点报告成功,协调节点向客户端报告成功。
-
-
请求返回:
-
主分片收到副本分片的响应后,会执行
finish()操作,将收到的响应信息返回给Coordinate节点,告知Coordinate节点文档写入分片成功、失败的情况;coordinate节点收到响应后,将索引执行情况返回给客户端。 -
当文档写入失败时,主分片节点会向
Master节点返送shardFieled请求,因为主副本分片未同步,Master会更新集群的状态,将写失败的副本分片从in-sync-allocation中去除;同时在路由表中将该分片的状态改为unassigned,即未分配状态。
-
-
-
-
【问】详细描述一下 Elasticsearch 分布式检索的过程?(查询阶段接收请求的Node创建TopN队列并合并其他节点转发过来的分片的ID和排序值;取回阶段则需要通过协调节点判断哪些文档是需要取回的(会出现深分页的问题)),参考详细描述一下Elasticsearch搜索的过程,elasticsearch搜索过程 - 简书,查询阶段 | Elasticsearch: 权威指南 | Elastic (官方文档),取回阶段 | Elasticsearch: 权威指南 | Elastic(官方文档)
Note:
-
我们都知道
ES是一个分布式的存储和检索系统,在存储的时候默认是根据每条记录的_id字段做路由分发的,这意味着ES服务端是准确知道每个document分布在那个shard上的。-
相对比于
CRUD上操作,search一个比较复杂的执行模式,因为我们不知道哪些document会被匹配到,任何一个shard上都有可能,所以一个search请求必须查询一个索引或多个索引里面的所有shard才能完整的查询到我们想要的结果。 -
找到所有匹配的结果是查询的第一步,来自多个
shard上的数据集在分页返回到客户端的之前会被合并到一个排序后的list列表,由于需要经过一步取top N的操作,所以search需要经过两个阶段才能完成,分别是query和fetch。
-
-
query(查询阶段)-
在初始查询阶段(
search)时,这个query会被广播到索引里面的每一个shard(主shard或副本shard),每个shard会在本地执行查询请求后并构建一个匹配文档的优先级队列。 -
这个队列是一个排序好的
top N数据的列表,它的size等于from + size的和,也就是说如果你的from是90,size是10,那么这个队列的size就是100(所以这也是为什么深度分页不能用from + size这种方式,因为from越大,性能就越低,深度分页常用到scroll以及search_After)GET /_search { "from": 90, "size": 10 }- 1
- 2
- 3
- 4
- 5
-
查询阶段的过程如下图所示:

查询阶段包含以下三个步骤:
- 客户端发送一个
search请求到Node 3,Node 3会创建一个大小为from + size的空优先队列。 Node 3将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是
Node 3, 它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 客户端发送一个
-
-
fetch(读取阶段)-
查询阶段标识哪些文档满足搜索请求,但是我们仍然需要取回这些文档。这是取回阶段的任务。分布式搜索的取回阶段如下图所示

分布式阶段由以下步骤构成:
- 协调节点(
Node3)辨别出哪些文档需要被取回并向相关的分片提交多个GET请求。 - 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
协调节点首先决定哪些文档 确实 需要被取回。例如,如果我们的查询指定了
{ "from": 90, "size": 10 },最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。这些文档可能来自和最初搜索请求有关的一个、多个甚至全部分片。 - 协调节点(
-
-
-
【问】ElasticSearch如何进行深分页?(深分页存在的一个问题是:随着页数越来越大,ES或者关系数据库响应越来越慢,甚至内存溢出
OOM;单机数据库系统分页先对数据集根据order字段正序排列,接着倒序找到limit条数据;分布式数据库系统分页则需要将各个节点的"limit"条数据汇总到master节点。由master节点对limit*N(节点数)再排序,此时容易出现OOM;在ES中有三种方式可以实现分页:from+size(超出10000条容易出现OOM)、scroll(取上一步的_scroll_id进行查询,性能优但查询的是历史的快照,不适用实时性查询场景)、search_after(下一次分页通过上一次分页的唯一排序值(sort)定位)),参考ElasticSearch如何进行深分页_51CTO博客_elasticsearch 分页,取回阶段 | Elasticsearch: 权威指南 | Elastic(官方文档)Note:
-
业务背景:
在传统业务系统中,一个常见的信息展现方式就是“分页列表”,随着数据量的增大,就会遇到“深分页”问题。比如用户一页一页的翻,一直翻到第5万页。比如导出全部列表数据到
excel,实现时一页一页的把数据追加到excel,直到导出全部数据。“深分页”通常的一个问题就是:随着页数越来越大,ES或者关系数据库响应越来越慢,甚至内存溢出OOM! 其中的原理是什么呢?如何在ES中进行深分页呢? -
技术原理:

-
分页的本质分页的本质是从“大的数据集”中取出一部分。比如10000条记录,每页10条数据。取第二页即第11条到20条数据。
ES或者数据库怎么知道哪些数据是第二部分(第2页),哪些是第三部分(第3页)呢?答案是ES或者数据库不知道,所以正确的分页必须要指定分页的顺序,即要有order by或者sort语句。 -
单机数据库系统分页:单机数据库系统有一种分页实现叫做“先正序排后倒排序排”。即先对"
offset+limit"的数据集根据order字段正序排列,然后再倒序找到limit条数据。 -
分布式数据库系统分页:分布式数据库系统相对于单机数据库系统,在各个节点取出
limit条数据后,还要将各个节点的"limit"条数据汇总到master节点。由master节点对limit * N(节点数)再排序,找到最终的limit条数据返回给应用程序。所以在深分页时,offset+limit过大,要排序的数据过多,对于内存分页数据库很容易超过进程的内存限制,产生OOM!
-
-
分页方式:
在
ES中有三种方式可以实现分页:from+size、scroll、search_after-
方式一: from+size
ES的标准分页方法是
from+size。from相当于postgresql的offset,size相当于limit的作用。每页10条数据,获取第11页的数据,其语法如下:POST rzfx-sqlinfo/sqlinfo/_search { "query": { "bool": { "must": [ { "term": { "architect.keyword": { "value": "郭锋" } } }, { "range": { "NRunTime": { "lte": 100 } } } ] } }, "size": 10, "from": 100 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
ES为了保证分页不占用大量的堆内存,避免OOM,参数 index.max_result_window设置了 from+size的最大值为10000。即每页10条的话,最多可以翻到1000页。index的全部参数可以通过以下语句查看:GET /rzfx-sqlinfo/_settings?flat_settings=true&include_defaults=true- 1
对于结构比较简单、
size比较小的文档,可以适当的扩大index.max_result_window参数,部分实现深分页。调整方式PUT rzfx-sqlinfo/_settings { "index.max_result_window":100000 }- 1
- 2
- 3
- 4
- 5
-
方式二:scroll
scroll api提供了一个全局深度翻页的操作,首次请求会返回一个scroll_id,使用该scroll_id可以顺序获取下一批次的数据-
案例如下:初始的搜索请求在查询字符串中指定
scroll参数,例如?scroll=5m这个参数会告诉Elasticsearch将 “search context” 保存多久。 例如:GET /db10/_search?&scroll=5m { "query": { "match_all": {} } , "sort": [ { "_doc": { "order": "desc" } } ], "size": 2 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面的请求返回的结果里会包含一个
_scroll_id,我们需要把这个值传递给scroll API,用来取回下一批结果。"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAzVUWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ==", "took" : 0,- 1
- 2
执行下一页查询
GET _search/scroll { "scroll":"5m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAy_kWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ==" }- 1
- 2
- 3
- 4
- 5
删除
scroll:当超出了scroll timeout时,搜索上下文会被自动删除。保持scrolls打开是有成本的,当不再使用scroll时应当使用 clear-scroll API 进行显式清除DELETE _search/scroll { "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABZOkWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ==" }- 1
- 2
- 3
- 4
-
分页查询性能分析
假设设置
scroll=5m的滚动分页标识GET /filebeat-7.4.0-2019.10.17-000001/_search?&scroll=5m { "query": { "match_all": {} } , "sort": [ { "_doc": { "order": "desc" } } ], "size": 10 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果可获得
_scroll_id,观察took,此处消耗 15349ms"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFnssWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw==", "took" : 15349, "timed_out" : false, "_shards" : { "total" : 1,- 1
- 2
- 3
- 4
- 5
取上一步的
_scroll_idGET /_search/scroll { "scroll":"5m", "scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFm2IWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw==" }- 1
- 2
- 3
- 4
- 5
结果通过
_scroll_id,滚动翻页所消耗时间大致相同,观察took,此处消耗 2742ms"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFm2IWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw==", "took" : 2742, "timed_out" : false, "_shards" : { "total" : 1,- 1
- 2
- 3
- 4
- 5
-
-
方式三: search_after
5.0以后版本提供的功能
search_after分页方式,第一次搜索需要指定sort,并保证值是唯一的,用前一次查询结果中最后一条记录的sort结果值作为下一次的查询条件。-
案例分析
GET /db10/_search?pretty=true { "size": 1, "query": { "match_all": { } } , "sort": [ { "age": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
结果截取如下:
}, *"sort" : [ 22 ]*- 1
- 2
- 3
- 4
检索下一页:
search_after是基于上一页排序sort结果值检索下一页实现动态分页GET /db10/_search?pretty=true { "size": 1, "query": { "match_all": { } }, *"search_after": [ 22 ]* , "sort": [ { "age": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
性能分析
假设每页查询20个
GET /filebeat-7.4.0-2019.10.17-000001/_search?pretty { "size": 20, "query": { "match_all": { } } , "sort": [ { "@timestamp": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
观察“took”可知耗时为4825ms
"took" : 4825, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "sort" : [ 1571522951167 ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
取下一页:其中“search_after”是 [ 1571522951167 ] ,即取上一页最后一个
sort值GET /filebeat-7.4.0-2019.10.17-000001/_search?pretty { "size": 20 "query": { "match_all": { } }, "search_after": [ 1571522951167 ] , "sort": [ { "@timestamp": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
观察“took”可知耗时为4318ms
{ "took" : 4318, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1,- 1
- 2
- 3
- 4
- 5
- 6
-
-
-
总结:
-
from+size-
使用
from+size方式进行分页,受max_result_window默认参数10000条文档的限制,不建议针对该参数进行修改 -
默认分页方式,适用小数据量场景,大数据量场景应避免使用
-
通过性能测试,随着分页越来越深,执行时间和堆内存使用逐渐升高的趋势,在并发情况下
from+size容易 造成集群服务的OutOfMemory问题
-
-
Scroll-
Scroll游标方式分页查询适用大数据量场景,只能向后增量查找,无法向前或者跳页查询,适用增量滚动抽取、数据迁移、重建索引等场景 -
通过性能案例分析,滚动分页查找性能消耗相差不大,不会像
from+size方式随着分页的深入性能逐渐升高的问题,且不会存在OOM问题 -
该分页方式是查询的历史快照,对文档的更改(索引的更新或者删除)只会影响以后的搜索请求,不适用实时性查询场景
-
需要注意的是,
scroll_id的有效期限是通过初始查询时设置的存活时间(scroll参数)来确定的(历史快照的存活时间)。在每次后续查询时,Elasticsearch会更新scroll_id的存活时间,确保查询结果在指定时间内保持有效。
-
-
search_after-
分页方式弥补了
scroll方式打开scroll占用内存资源问题 -
search_after可并行的拉取大量数据 -
search_after分页方式通过唯一排序值定位,将每次需要处理的数据控制在一定范围,避免深度分页带来的开销,适用深度分页的场景
-
-
-
-
Note:
-
Scroll游标方式可以实现增量查找,而from+size方式不可以的原因主要有两点(
ChatGPT):-
数据变化:使用
from+size方式进行分页查询时,如果在两次查询之间有新的数据被添加、更新或删除,那么后续的分页结果可能会受到影响。因为from+size方式是基于结果集的位置进行分页的,如果数据发生变化,后续的分页结果可能会出现数据丢失或重复的情况。 -
结果排序:
from+size方式要求结果是有序的,以保证分页结果的准确性。如果结果集没有明确定义的排序字段或者排序字段有变动,那么后续的分页结果可能会出现数据丢失或重复的情况。
相比之下,
Scroll游标方式通过快照的方式来实现增量查找,具有以下特点:-
快照保持一致性:使用
Scroll方式时,初始查询会创建一个快照,并与scroll_id关联。后续的查询都是基于这个快照进行的,不会受到数据变化的影响。即使在两次查询之间有新的数据变化,已经生成的快照中的数据不会受到影响。 -
游标定位:
Scroll方式使用scroll_id作为游标来定位到下一批结果,而不是依赖于结果集的位置。每次查询都会基于快照和scroll_id来计算下一批结果,从而避免了from+size方式中可能出现的数据丢失或重复的问题。
因此,
scroll增量查找是从初次查询创建的历史快照中查找,而不是从数据集中去查找 -
-
Search After是一种基于排序字段的分页查询方法,相较于Scroll API,它更适用于需要分页查询但不需要实时一致性的场景。以下是Search After相对于 Scroll API 能够节约内存资源的几个方面(ChatGPT):-
数据不需要在内存中缓存:使用
Scroll API时,Elasticsearch会将查询结果存储在内存中的缓存中,以便客户端进行遍历和获取下一页数据。这会占用大量内存,特别是当数据集非常大时。而 Search After 则不需要将所有数据都缓存到内存中,它只需要保存最后一条结果记录的排序字段值,用于下一页的查询。 -
游标无需维护:
Scroll API通过scroll_id来标识游标,要求客户端在下一次查询时传递该scroll_id,以便继续获取下一页的结果。这需要维护游标的状态,包括传递scroll_id和保存历史快照等操作。而Search After没有游标的概念,它只需要在每次查询时指定上一页的最后一条结果记录的排序字段值,这样就可以准确地定位到下一页的数据。 -
无需全量数据集扫描:
Scroll API在初次查询时会创建一个历史快照,这需要扫描全量数据集并将其缓存到内存中。而Search After只需要根据排序字段值进行定位,无需扫描全量数据集,只会检索到满足条件的下一页数据。
-
-
-
【问】详细描述一下 Elasticsearch 更新和删除文档的过程?(协调节点查找文档id所在的主分片位置;修改主分片;将修改后的主分片文档转发到副分片中(而非转发更新请求)),参考ElasticSearch系列 - 分布式文档索引、搜索、更新和删除文档的过程,新建、索引和删除文档 | 官方文档
Note:
-
update API结合了读取和写入模式:
以下是部分更新一个文档的步骤:
-
① 客户端向
节点 1发送更新请求。 -
② 节点使用文档的
id来确定文档属于分片 0,它将请求转发到主分片所在的 节点 2 。 -
③
节点 2从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。 -
④ 如果
节点 2成功地更新文档,它将新版本的文档并行转发到节点 1和节点 3上的副本分片,重新建立索引。 一旦所有副本分片都返回成功, 节点 2 向协调节点也返回成功,协调节点向客户端返回成功。
-
-
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果
Elasticsearch仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
-
-
【问】Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法(关闭交换分区、设置单用户可以打开的最大文件数量、单用户线程数调大等),参考Elasticsearch索引和查询性能调优的21条建议【上】_51CTO博客_elasticsearch 参数调优
Note:
-
Linux操作系统调优-
关闭交换分区,防止内存置换降低性能。
将/etc/fstab 文件中包含swap的行注释掉 sed -i '/swap/s/^/#/' /etc/fstab swapoff -a- 1
- 2
- 3
-
单用户可以打开的最大文件数量,可以设置为官方推荐的65536或更大些
echo "* - nofile 655360" >> /etc/security/limits.conf- 1
-
单用户线程数调大
echo "* - nproc 131072" >> /etc/security/limits.conf- 1
-
单进程可以使用的最大map内存区域数量
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf- 1
-
参数修改立即生效
sysctl -p- 1
-
-
-
【问】lucence 内部结构是什么?(
ES的倒排索引是基于Lucene实现的,其倒排索引的结构包括索引表和记录表),参考lucence 内部结构是什么?-开发者客栈-帮助开发者面试的平台-顽强网络,ChatGPTNote:
- Lucene 是一个基于 Java 的全文搜索引擎库,其内部结构包括以下几个组成部分:
- 索引:Lucene 将文本数据以文档为单位进行索引,索引包含了文档的元数据和文本内容。在 Lucene 中,索引是由多个段(Segment)组成的,每个段包含了一部分文档的索引数据。Lucene 通过将多个段合并,来构建一个完整的索引。
- 文档:Lucene 中的文档(Document)是一个包含了多个字段(Field)的数据结构,每个字段包含了一个名称和一个值。Lucene 中的字段可以被分成两类:存储字段(Stored Field)和索引字段(Indexed Field)。存储字段会以原始形式存储在索引中,而索引字段则会进行分词处理,并存储分词后的词项(Term)。
- 分词器:Lucene 中的分词器(Tokenizer)将文本内容分解成一个个的词项(Term)。Lucene 默认使用 StandardAnalyzer 分词器,该分词器会将文本转换成小写字母,并去掉一些常用的停用词(Stop Word),例如 “and”、“or”、“the” 等。
- 查询:Lucene 支持多种类型的查询,包括词项查询、短语查询、模糊查询、通配符查询等。查询会通过索引进行搜索,并返回匹配查询条件的文档。
- Scoring:Lucene 使用
TF-IDF算法来计算文档与查询的相关度,并根据相关度进行排序。在计算相关度时,Lucene 还会考虑词项的位置、长度、频率等因素。 - 内存管理:Lucene 中有一个内存缓存(Memory Cache),用于缓存索引数据和查询结果。Lucene 也支持将索引数据和查询结果存储到磁盘上的文件中,以避免占用过多的内存。
- Lucene 是一个基于 Java 的全文搜索引擎库,其内部结构包括以下几个组成部分:
-
【问】客户端在和集群连接时,如何选择特定的节点执行请求的?(以 轮询的方式与这些集群节点进行通信),参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经
Note:
TransportClient利用transport模块远程连接一个elasticsearch集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的transport地址,并以 轮询 的方式与这些地址进行通信。
-
【问】在 Elasticsearch 中,是怎么根据一个词找到对应的倒排索引的?(如何通过一个词找到索引表,进而从索引表对应的记录表(posting list)中找到相应的文档id等信息;为了减少posting list占用的存储空间,用
.doc,.pay,.pos三种文件存储,参考前几问),参考ElasticSearch倒排索引详解 -
【问】对于 GC 方面,在使用 Elasticsearch 时要注意什么?(各类缓存设置合理大小,避免返回大量结果集,通过
tribe node连接多个集群),参考Day19 ES内存那点事Note:
- 倒排词典的索引需要常驻内存,无法GC,需要监控
data node上segmentmemory增长趋势。 - 各类缓存,
field cache,filter cache,indexing cache,bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。 - 避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用
scan&scroll api来实现。 cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。- 想知道
heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
- 倒排词典的索引需要常驻内存,无法GC,需要监控
-
【问】Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?(通过
HLL算法实现近似聚合(cardinality度量)),参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经Note:
-
Elasticsearch提供的首个近似聚合是cardinality度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL会先对我们的输入作哈希运算,然后根据哈希运算的结果中的bits做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存); -
小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
-
-
【问】在并发情况下,Elasticsearch 如果保证读写一致?(通过版本号使用乐观并发控制;对于写操作,一致性级别支持
quorum/one/all;对于读操作,可以设置replication为sync(默认)),参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经Note:
- 1、可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
- 2、另外对于写操作,一致性级别支持
quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。 - 3、对于读操作,可以设置
replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
-
【问】如何监控 Elasticsearch 集群状态?(
Marvel让你可以很简单的通过Kibana监控Elasticsearch),参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经Note:
Marvel让你可以很简单的通过Kibana监控Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标。
-
【问】介绍下你们电商搜索的整体技术架构,参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经
-
【问】介绍一下你们的个性化搜索方案?,参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经
-
【问】是否了解字典树?,参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经
Note:
-
【问】拼写纠错是如何实现的?,参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)_elasticsearch面经
Note:
-
【问】elasticsearch 索引数据多了怎么办,如何调优,部署?(查询性能优化(包括使用过滤器缓存和分片查询缓存、使用路由、强制合并只读索引并关闭历史数据索引、配置查询聚合节点、配置合适的分调器、设置壹询读取记录条数和字段、配置teminate.after查询快速返回、避免前缀模糊匹配、迎免深度翻页、避免索引稀疏、扩容集群节点个数、升级节点规格等)、写入性能优化(设置合理的索引分片数和副本数、使用批量请求、通过多进程/线程发送数据、调大refresh interval、配置事务日志参数、设计mapping配置合适的字段类型等)、部署建议(选择合理的硬件配置,尽可能使用SSD、给JVM配置机器一半的内存但不建议超过32G、规模较大的集群配置专有主节点,避免脑裂问题、Linux操作系统调优、设置内存熔断参数,防止写入或查询压力过高导致OOM等)),参考索引性能技巧 | Elasticsearch: 权威指南 | Elastic,30 个 ElasticSearch 调优知识点,都给你整理好了! - 文章详情,Elasticsearch索引和查询性能调优的21条建议【上】_51CTO博客_elasticsearch 参数调优,Elasticsearch索引和查询性能调优的21条建议【下】 - 墨天轮
Note:
-
索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。如何调优,这里划分成“查询性能优化”、“写入性能优化” 以及 ”部署建议“三个方面:

-
查询性能调优建议:参考Elasticsearch索引和查询性能调优的21条建议【下】 - 墨天轮
-
使用过滤器缓存和分片查询缓存:
-
默认情况下,
Elasticsearch的查询会计算返回的每条数据与查询语句的相关度,但对于非全文索引的使用场景,用户并不关心查询结果与查询条件的相关度,只是想精确地查找目标数据。此时,可以通过filter来让Elasticsearch不计算评分,并且尽可能地缓存filter的结果集,供后续包含相同filter的查询使用,提高查询效率。 -
普通查询:
curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d' { "query": { "match": { "user": "kimchy" } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
过滤器(
filter)查询:curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d' { "query": { "bool": { "filter": { "match": { "user": "kimchy" } } } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
分片查询缓存的目的是缓存聚合、提示词结果和命中数(它不会缓存返回的文档,因此,它只在
search_type=count时起作用)。通过下面的参数我们可以设置分片缓存的大小,默认情况下是JVM堆的1%大小,当然我们也可以手动设置在
config/elasticsearch.yml文件里:indices.requests.cache.size: 1%- 1
-
查看缓存占用内存情况:
name表示节点名,query_cache表示过滤器缓存,request_cache表示分片缓存,fielddata表示字段数据缓存,segments表示索引段curl -XGET "http://localhost:9200/_cat/nodes?h=name,query_cache.memory_size,request_cache.memory_size,fielddata.memory_size,segments.memory&v"- 1
-
-
使用路由
routing:-
Elasticsearch写入文档时,文档会通过一个公式路由到一个索引中的一个分片上。默认的公式如下:shard_num = hash(_routing) % num_primary_shards- 1
_routing字段的取值,默认是_id字段,可以根据业务场景设置经常查询的字段作为路由字段。例如可以考虑将用户id、地区作为路由字段,查询时可以过滤不必要的分片,加快查询速度。 -
写入时指定路由
curl -XPUT "http://localhost:9200/my_index/my_type/1?routing=user1" -H 'Content-Type: application/json' -d' { "title": "This is a document", "author": "user1" }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
查询时不指定路由,需要查询所有分片
curl -XGET "http://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d' { "query": { "match": { "title": "document" } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
返回结果
{ "took": 2, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 } ...... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
查询时指定路由,只需要查询1个分片
curl -XGET "http://localhost:9200/my_index/_search?routing=user1" -H 'Content-Type: application/json' -d' { "query": { "match": { "title": "document" } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
返回结果
{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 } ...... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
-
强制合并只读索引,关闭历史数据索引:
-
只读索引可以从合并成一个单独的大
segment中收益,减少索引碎片,减少JVM堆常驻内存。强制合并索引操作会耗费大量磁盘IO,尽量配置在业务低峰期(例如凌晨)执行。索引
forcemergeAPI:curl -XPOST "http://localhost:9200/abc20180923/_forcemerge?max_num_segments=1"- 1
-
历史数据索引如果业务上不再支持查询请求,可以考虑关闭索引,减少
JVM内存占用。索引关闭API
curl -XPOST "http://localhost:9200/abc2017*/_close"- 1
-
-
配置合适的分词器:
Elasticsearch内置了很多分词器,包括standard、cjk、nGram等,也可以安装自研/开源分词器。根据业务场景选择合适的分词器,避免全部采用默认standard分词器。常用分词器:
-
standard: 默认分词,英文按空格切分,中文按照单个汉字切分。
-
cjk: 根据二元索引对中日韩文分词,可以保证查全率。
-
nGram: 可以将英文按照字母切分,结合ES的短语搜索(match_phrase)使用。
-
IK: 比较热门的中文分词,能按照中文语义切分,可以自定义词典。
-
pinyin: 可以让用户输入拼音,就能查找到相关的关键词。
-
aliws: 阿里巴巴自研分词,支持多种模型和分词算法,词库丰富,分词结果准确,适用于电商等对查准要求高的场景。
分词效果测试API:
curl -XPOST "http://localhost:9200/_analyze" -H 'Content-Type: application/json' -d' { "analyzer": "ik_max_word", "text": "南京市长江大桥" }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

-
-
配置查询聚合节点:
-
查询聚合节点可以发送粒子查询请求到其他节点,收集和合并结果,以及响应发出查询的客户端。通过给查询聚合节点配置更高规格的CPU和内存,可以加快查询运算速度、提升缓存命中率。
某客户使用25台8核CPU32G内存节点
Elasticsearch集群,查询QPS(Queries Per Second每秒查询率)在4000左右。增加6台16核CPU32G内存节点作为查询聚合节点,观察服务器CPU、JVM堆内存使用情况,并调整缓存、分片、副本参数,查询QPS达到12000。 -
查询聚合节点配置(
conf/elasticsearch.yml):node.master:false node.data:false node.ingest:false- 1
- 2
- 3
-
-
设置查询读取记录条数和字段:
默认的查询请求通常返回排序后的前
10条记录,最多一次读取10000条记录-
通过
from和size参数控制读取记录范围,避免一次读取过多的记录。 -
通过
_source参数可以控制返回字段信息,尽量避免读取大字段。
查询请求示例:
curl -XGET http://localhost:9200/fulltext001/_search?pretty -H 'Content-Type: application/json' -d ' { "from": 0, "size": 10, "_source": "id", "query": { "bool": { "must": [ {"match": {"content":"虎嗅"}} ] } }, "sort": [ { "id": { "order": "asc" } } ] } '- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
-
-
设置
teminate_after查询快速返回:-
如果不需要精确统计查询命中记录条数,可以配
teminate_after指定每个shard最多匹配N条记录后返回,设置查询超时时间timeout。在查询结果中可以通过“terminated_early”字段标识是否提前结束查询请求。 -
teminate_after查询语法示例curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d' { "from": 0, "size": 10, "timeout": "10s", "terminate_after": 1000, "query": { "bool": { "filter": { "term": { "user": "elastic" } } } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
-
-
避免查询深度翻页:
-
Elasticsearch默认只允许查看排序前10000条的结果,当翻页查看排序靠后的记录时,响应耗时一般较长。使用search_after方式查询会更轻量级,如果每次只需要返回10条结果,则每个shard只需要返回search_after之后的10个结果即可,返回的总数据量只是和shard个数以及本次需要的个数有关,和历史已读取的个数无关。 -
search_after查询语法示例curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d' { "size": 10, "query": { "match": { "message": "Elasticsearch" } }, "sort": [ {"_score": {"order": "desc"}}, {"_id": {"order":"asc"}} ], "search_after": [ 0.84290016, //上一次response中某个doc的score "1024" //上一次response中某个doc的id ] }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
-
避免前缀模糊匹配(数据预处理):
-
Elasticsearch默认支持通过*?正则表达式来做模糊匹配,如果在一个数据量较大规模的索引上执行模糊匹配,尤其是前缀模糊匹配,通常耗时会比较长,甚至可能导致内存溢出。尽量避免在高并发查询请求的生产环境执行这类操作。 -
某客户需要对车牌号进行模糊查询,通过查询请求"车牌号:A8848"查询时,往往导致整个集群负载较高。通过对数据预处理,增加冗余字段"车牌号.keyword",并事先将所有车牌号按照1元、2元、3元…7元分词后存储至该字段,字段存储内容示例:沪,A,8,4,沪A,A8,88,84,48,沪A8…沪A88488。通过查询"车牌号.keyword:A8848"即可解决原来的性能问题。
-
-
避免索引稀疏(建议每个索引下只创建一个
type):-
Elasticsearch6.X之前的版本默认允许在一个index下面创建多个type,Elasticsearch6.X版本只允许创建一个type,Elasticsearch7.X版本只允许type值为“_doc”。在一个索引下面创建多个字段不一样的type,或者将几百个字段不一样的索引合并到一个索引中,会导致索引稀疏问题。 -
建议每个索引下只创建一个
type,字段不一样的数据分别独立创建index,不要合并成一个大索引。每个查询请求根据需要去读取相应的索引,避免查询大索引扫描全部记录,加快查询速度。
-
-
扩容集群节点个数,升级节点规格:
通常服务器节点数越多,服务器硬件配置规格越高,Elasticsearch集群的处理能力越强。
-
在不同节点规模下的查询性能测试(测试环境:Elasticsearch5.5.3集群,单节点16核CPU、64G内存、2T SSD盘,10亿条人口户籍登记信息,数据大小1TB, 20索引分片)
集群节点数 副本数 10并发检索平均响应时间 50并发检索平均响应时间 100并发检索平均响应时间 200并发检索平均响应时间 200并发QPS 200并发CPU使用率 200并发CPUIO等待 1 0 77ms 459ms 438ms 1001ms 200 16% 52% 3 0 38ms 103ms 162ms 298ms 669 45% 34% 3 2 271ms 356ms 577ms 818ms 244 19% 54% 10 0 21ms 36ms 48ms 81ms 2467 40% 10% -
不同集群节点规模写入性能测试(测试环境:Elasticsearch6.3.2集群,单节点16核CPU、64G内存、2T SSD盘,10亿条人口户籍登记信息,单条记录1KB,数据集大小1TB,20个并发写入线程)
集群节点数 副本数 写入TPS 耗时 集群CPU使用率 10 0 88945 11242s 50% 50 0 180638 5535s 20%
在条件允许的情况下,建议可以通过实际的数据和使用场景测试出适合自己的最佳实践。得益于阿里云
Elasticsearch提供的弹性扩容功能,阿里云Elasticsearch用户可以在实际使用时根据情况随时增加磁盘大小、扩容节点个数、升级节点规格。 -
-
-
-
写入性能优化建议:参考Elasticsearch索引和查询性能调优的21条建议【上】_51CTO博客_elasticsearch 参数调优
-
设置合理的索引分片数和副本数
-
索引分片数建议设置为集群节点的整数倍,初始数据导入时副本数设置为0,生产环境副本数建议设置为1(设置1个副本,集群任意1个节点宕机数据不会丢失;设置更多副本会占用更多存储空间,操作系统缓存命中率会下降,检索性能不一定提升)。
-
单节点索引分片数建议不要超过3个,每个索引分片推荐
10-40GB大小。索引分片数设置后不可以修改,副本数设置后可以修改。 -
Elasticsearch6.X及之前的版本默认索引分片数为5、副本数为1,从Elasticsearch7.0开始调整为默认索引分片数为1、副本数为1。 -
不同分片数对写入性能的影响(测试环境:7节点Elasticsearch 6.3集群,写入30G新闻数据,单节点56核CPU、380G内存、3TB SSD卡,0副本,20线程写入,每批次提交10M左右数据):
集群索引分片数 单节点索引分片数 写入耗时 2 0/1 600s 7 1 327s 14 2 258s 21 3 211s 28 4 211s 56 8 214s
-
-
使用批量请求:
-
使用批量请求将产生比单文档索引请求好得多的性能。写入数据时调用批量提交接口,推荐每批量提交
5~15MB数据。例如单条记录1KB大小,每批次提交10000条左右记录写入性能较优;单条记录5KB大小,每批次提交2000条左右记录写入性能较优。 -
批量请求接口API:
curl -XPOST "http://localhost:9200/_bulk" -H 'Content-Type: application/json' -d' { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } } { "field1" : "value1" } { "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } } { "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } } { "field1" : "value3" } { "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} } { "doc" : {"field2" : "value2"} } '- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
-
通过多进程/线程发送数据:
-
单线程批量写入数据往往不能充分利用服务器
CPU资源,可以尝试调整写入线程数或者在多个客户端上同时向Elasticsearch服务器提交写入请求。 -
与批量调整大小请求类似,只有测试才能确定最佳的worker数量。可以通过逐渐增加工作任务数量来测试,直到集群上的 I / O或CPU饱和。
-
-
调大
refresh interval(优化索引速度而不是在既存索引上近实时搜索):-
在
Elasticsearch中,写入和打开一个新段的轻量的过程叫做refresh。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。 -
并不是所有的情况都需要每秒刷新。可能你正在使用
Elasticsearch索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置refresh_interval,降低每个索引的刷新频率。 -
设置
refresh intervalAPI:curl -XPUT "http://localhost:9200/index" -H 'Content-Type: application/json' -d' { "settings" : { "refresh_interval": "30s" } }'- 1
- 2
- 3
- 4
- 5
- 6
refresh_interval可以在既存索引上进行动态更新。 -
在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来
curl -XPUT "http://localhost:9200/index/_settings" -H 'Content-Type: application/json' -d' { "refresh_interval": -1 }' curl -XPUT "http://localhost:9200/index/_settings" -H 'Content-Type: application/json' -d' { "refresh_interval": "1s" }'- 1
- 2
- 3
- 4
- 5
-
-
配置事务日志参数:
-
事务日志
translog用于防止节点失败时的数据丢失。它的设计目的是帮助shard恢复操作,否则数据可能会从内存flush到磁盘时发生意外而丢失。事务日志translog的落盘(fsync)是ES在后台自动执行的,-
默认每5秒钟提交到磁盘上;
-
或者当
translog文件大小大于512MB提交; -
或者在每个成功的索引、删除、更新或批量请求时提交。
-
-
索引创建时,可以调整默认日志刷新间隔5秒,例如改为60秒,
index.translog.sync_interval: "60s"。创建索引后,可以动态调整translog参数,"index.translog.durability":"async"相当于关闭了index、bulk等操作的同步flush translog操作,仅使用默认的定时刷新、文件大小阈值刷新的机制。 -
动态设置
translogAPI:curl -XPUT "http://localhost:9200/index" -H 'Content-Type: application/json' -d' { "settings" : { "index.translog.durability": "async", "translog.flush_threshold_size": "2gb" } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
-
设计
mapping配置合适的字段类型(配置合理的分片数、副本数,设置字段类型、分词器):-
Elasticsearch在写入文档时,如果请求中指定的索引名不存在,会自动创建新索引,并根据文档内容猜测可能的字段类型。但这往往不是最高效的,我们可以根据应用场景来设计合理的字段类型。例如写入一条记录:
curl -XPUT "http://localhost:9200/twitter/doc/1?pretty" -H 'Content-Type: application/json' -d' { "user": "kimchy", "post_date": "2009-11-15T13:12:00", "message": "Trying out Elasticsearch, so far so good?" }'- 1
- 2
- 3
- 4
- 5
- 6
查询
Elasticsearch自动创建的索引mapping,会发现将post_date字段自动识别为date类型,但是message和user字段被设置为text、keyword冗余字段,造成写入速度降低、占用更多磁盘空间。{ "twitter": { "mappings": { "doc": { "properties": { "message": { "type": "text", "felds": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "post_date": { "type": "date" }, "user": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }, "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1", } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
-
根据业务场景设计索引配置合理的分片数、副本数,设置字段类型、分词器。如果不需要合并全部字段,禁用
_all字段,通过copy_to来合并字段。curl -XPUT "http://localhost:9200/twitter?pretty" -H 'Content-Type: application/json' -d' { "settings" : { "index" : { "number_of_shards" : "20", "number_of_replicas" : "0" } } }' curl -XPOST "http://localhost:9200/twitter/doc/_mapping?pretty" -H 'Content-Type: application/json' -d' { "doc" : { "_all" : { "enabled" : false }, "properties" : { "user" : { "type" : "keyword" }, "post_date" : { "type" : "date" }, "message" : { "type" : "text", "analyzer" : "cjk" } } } }'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
-
-
-
部署建议:参考Elasticsearch索引和查询性能调优的21条建议【上】_51CTO博客_elasticsearch 参数调优
-
选择合理的硬件配置,尽可能使用SSD:
Elasticsearch最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能。使用SSD(PCI-E接口SSD卡/SATA接口SSD盘)通常比机械硬盘(SATA盘/SAS盘)查询速度快5~10倍,写入性能提升不明显。-
对于文档检索类查询性能要求较高的场景,建议考虑
SSD作为存储,同时按照1:10的比例配置内存和硬盘。 -
对于日志分析类查询并发要求较低的场景,可以考虑采用机械硬盘作为存储,同时按照
1:50的比例配置内存和硬盘。单节点存储数据建议在2TB以内,不要超过5TB,避免查询速度慢、系统不稳定。
在单机存储
1TB数据场景下,SATA盘和SSD盘的全文检索性能对比:磁盘类型 并发数 QPS 平均检索响应时间 50%请求响应时间 90%请求响应时间 IOPS SATA盘 10并发 17 563ms 478ms 994ms 1200 SATA盘 50并发 64 773ms 711ms 1155ms 1800 SATA盘 100并发 110 902ms 841ms 1225ms 2040 SATA盘 200并发 84 2369ms 2335ms 2909ms 2400 SSD盘 10并发 94 105ms 90ms 200ms 25400 SSD盘 50并发 144 346ms 341ms 411ms 66000 SSD盘 100并发 152 654ms 689ms 791ms 60000 SSD盘 200并发 210 950ms 1179ms 1369ms 60000 -
-
给JVM配置机器一半的内存,但是不建议超过32G:
-
修改
conf/jvm.options配置,-Xms和-Xmx设置为相同的值,推荐设置为机器内存的一半左右,剩余一半留给操作系统缓存使用。jvm内存建议不要低于2G,否则有可能因为内存不足导致ES无法正常启动或内存溢出 -
jvm建议不要超过32G,否则jvm会禁用内存对象指针压缩技术,造成内存浪费。机器内存大于64G内存时,推荐配置-Xms30g -Xmx30g。 -
JVM堆内存较大时,内存垃圾回收暂停时间比较长,建议配置ZGC或G1垃圾回收算法。
-
-
规模较大的集群配置专有主节点,避免脑裂问题:
-
Elasticsearch主节点(master节点)负责集群元信息管理、index的增删操作、节点的加入剔除,定期将最新的集群状态广播至各个节点。在集群规模较大时,建议配置专有主节点只负责集群管理,不存储数据,不承担数据读写压力。 -
Elasticsearch默认每个节点既是候选主节点,又是数据节点。最小主节点数量参数minimum_master_nodes推荐配置为候选主节点数量一半以上,该配置告诉Elasticsearch当没有足够的master候选节点的时候,不进行master节点选举,等master节点足够了才进行选举。
-
-
Linux操作系统调优-
关闭交换分区,防止内存置换降低性能。
将
/etc/fstab文件中包含swap的行注释掉sed -i '/swap/s/^/#/' /etc/fstab swapoff -a- 1
- 2
-
单用户可以打开的最大文件数量,可以设置为官方推荐的
65536或更大些echo "* - nofile 655360" >> /etc/security/limits.conf- 1
-
单用户线程数调大
echo "* - nproc 131072" >> /etc/security/limits.conf- 1
-
单进程可以使用的最大
map内存区域数量echo "vm.max_map_count = 655360" >> /etc/sysctl.conf- 1
-
参数修改立即生效
sysctl -p- 1
-
-
设置内存熔断参数,防止写入或查询压力过高导致
OOM -
JVM GC ZGC Vs G1 Vs CMS
-
-
【问】Elasticsearch 了解多少,说说你们公司 es 的集群架构(使用场景、规模),索引数据大小(有没有做过比较大规模的索引设计、规划),分片有多少,以及一些调优手段 ,参考【2021最新版】Elasticsearch面试题总结(24道题含答案解析)
Note:
15、Docker
参考Docker常用命令(以Anaconda为例搭建环境),
-
【问】docker如何拉取镜像?
Note:docker pull 镜像名:tags eg: docker pull continuumio/anaconda3 #默认拉取最新版本- 1
- 2
-
【问】docker如何查看,查找,删除本地镜像?
Note:docker images -a #查看镜像列表 docker search 镜像名 #查找镜像 docker rmi 镜像名 #删除镜像- 1
- 2
- 3
-
【问】docker如何更新本地镜像?
Note:docker run -t -i 镜像名:版本号 /bin/bash eg: docker run -t -i ubuntu:15.10 /bin/bash- 1
- 2
-
【问】docker如何通过镜像实例化容器?(该步骤在创建容器过程中,免去了
docker pull 镜像名:版本号的操作),参考修改Docker容器的映射IP地址域端口号
Note:docker run -it --name 容器名 镜像名:版本号 /bin/bash eg: docker run -it --name="anaconda" -p 8888:8888 continuumio/anaconda3 /bin/bash ---- 1
- 2
- 3
其中各个参数含义如下:
-i: 交互式操作。-t: 终端。--name="anaconda":是给容器起名字-p 8888:8888:是将容器的0.0.0.0:8888端口映射到本地的8888端口(注意docker容器内是没有ip的,它的ip和宿主机一样)/bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是/bin/bash。
-
【问】docker如何启动,停止容器?
Note:启动容器:docker start 容器名/容器id 停止容器:docker stop 容器名/容器id- 1
- 2
-
【问】docker如何进入容器内部?(进入容器内就正常在linux系统下执行命令即可,建议先查看linux版本,比如
cat /etc/debian_version)
Note:docker exec -it 容器id /bin/bash- 1
-
【问】docker如何实现宿主机和docker容器的数据互传?
Note:- 将
docker容器内的文件拷贝到宿主机中# 将容器b7200c1b6150的文件test.json传到主机/tmp/,在Ubuntu命令行中输入 $ docker cp b7200c1b6150:/opt/gopath/src/github.com/hyperledger/fabric/test.json /tmp/- 1
- 2
- 将宿主机中的文件拷贝到
docker容器中# 将主机requirements.txt传到容器9cf7b3c196f3的/home目录下,在宿主机命令行中输入 $ docker cp /home/wangxiaoxi/Desktop/requirements.txt 9cf7b3c196f3:/home/- 1
- 2
- 将
-
【问】docker如何查看,删除本地容器?
Note:删除容器:docker rm -f 容器id 查看所有的容器:docker ps -a- 1
- 2
-
【问】docker如何将容器打包成镜像?
Note:docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] #OPTIONS说明: # -a :提交的镜像作者; # -c :使用Dockerfile指令来创建镜像; # -m :提交时的说明文字; # -p :在commit时,将容器暂停。 docker commit -a "wangxiaoxi" -m "fallDetection_toolkit_env" 2b1ad7022d19 fall_detection_env:v1- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
【问】docker如何将容器导出为tar,并由tar导入?
Note:导出容器快照:docker export 1e560fca3906 > ubuntu.tar 导入容器快照:cat docker/ubuntu.tar | docker import - test/ubuntu:v1- 1
- 2
docker import是指将快照文件ubuntu.tar导入到镜像test/ubuntu:v1中。 -
【问】docker如何编写
Dockerfile,以及如何利用Dockerfile构建本地镜像?,参考docker镜像的创建commit及dockerfile,Dockerfile文件详解
Note:- 常用指令:
FROM:基础镜像,当前新镜像是基于哪个镜像
MAINTAINER:镜像维护者的姓名和邮箱地址
RUN:容器构建时需要运行的命令
EXPOSE:当前容器对外暴露出的端口
WORKDIR:指定在创建容器后,终端默认登陆的进来工作目录,一个落脚点
ENV:用来在构建镜像过程中设置环境变量
ADD:将宿主机目录下的文件拷贝进镜像且 ADD 命令会自动处理 URL 和解压 tar 压缩包
COPY:类似 ADD,拷贝文件和目录到镜像中。(COPY src dest 或 COPY [“src”,“dest”])
VOLUME:容器数据卷,用于数据保存和持久化工作
CMD:指定一个容器启动时要运行的命令,Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,CMD 会被 docker run 之后的参数替换
ENTRYPOINT:指定一个容器启动时要运行的命令,ENTRYPOINT 的目的和 CMD 一样,都是在指定容器启动程序及参数
ONBUILD:当构建一个被继承的 Dockerfile 时运行命令,父镜像在被子继承后父镜像的 onbuild 被触发。 - 通过
Dockerfile构建镜像# . 表示当前路径(一定不要在最后忘了'.',否则会报"docker build" requires exactly 1 argument.) docker build -f mydockerfile -t mycentos:0.1 . #-f表示dockerfile路径 -t表示镜像标签- 1
- 2
- 常用指令:
-
【问】docker如何将镜像打包成tar包?
Note:# docker save -o 文件名.tar 镜像名 docker save -o /media/wangxiaoxi/新加卷/docker_dir/docker/test.tar hello-world #恢复镜像 docker load -i [docker备份文件.tar]- 1
- 2
- 3
- 4
16、Netty(核心:
channelPipeline双向链表(责任链),链表每个节点使用promise的wait/notify(事件监听者))参考黑马Netty笔记,尚硅谷Netty笔记,【硬核】肝了一月的Netty知识点,【阅读笔记】Java游戏服务器架构实战,代码参考:kebukeYi / book-code
-
【问】同步和异步的区别?阻塞和非阻塞IO的区别?(阻塞强调的是状态,而同步强调的是过程)
Note:
-
基本概念:
-
阻塞:等待缓冲区中的数据准备好过后才处理其他的事情,否则一直等待在那里。
-
非阻塞:当我们的进程访问我们的数据缓冲区的时候,如果数据没有准备好则直接返回,不会等待。如果数据已经准备好,也直接返回。
-
同步:当一个进程/线程在执行某个请求的时候,如果该请求需要一段时间才能返回信息,那么这个进程/线程会一直等待下去,直到收到返回信息才继续执行下去。
-
异步:进程不需要一直等待某个请求的处理结果,而是继续执行下面的操作,当这个请求处理完毕之后,可以通过回调函数通知该进程进行处理。
阻塞和同步(非阻塞和异步)描述相同,但强调内容不同:阻塞强调的是状态,而同步强调的是过程。
-
-
阻塞IO 和 非阻塞IO:(BIO vs NIO)
-
BIO(Blocking IO):
-
传统的 java.io 包,它基于流模型实现,提供了我们最熟知的一些 IO 功能,比如File抽象、输入输出流等。交互方式是同步、阻塞的方式,也就是说,在读取输入流或者写入输出流时,在读、写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。
-
在
Java网络通信中,Socket和ServerSocket套接字是基于阻塞模式实现的。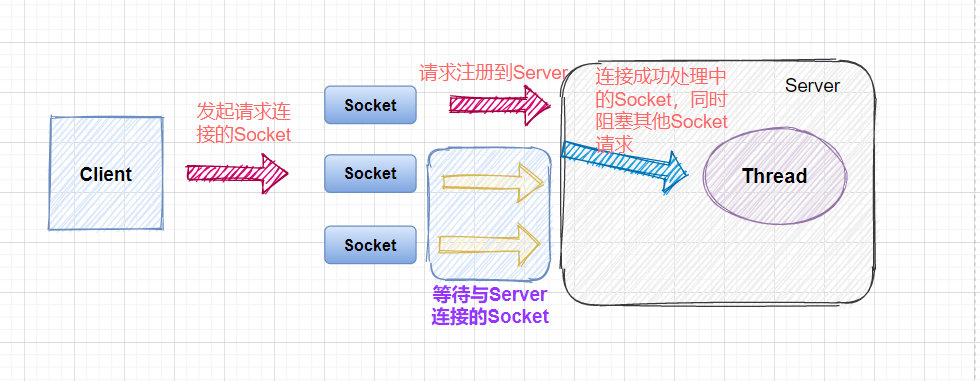
-
-
NIO(Non-Blocking IO):
-
在
Java 1.4中引入了对应java.nio包,提供了Channel,Selector,Buffer等抽象,它支持面向缓冲的,基于通道的 I/O 操作方法。 -
NIO 提供了与传统 BIO 模型中的
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,支持阻塞和非阻塞两种模式。对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
-
-
BIO和NIO的比较:IO模型 BIO NIO 通信 面向流 面向缓冲 处理 阻塞 IO 非阻塞IO 触发 无 选择器
-
-
-
【问】什么是CPU密集型/IO密集型?(有多种类型的任务则需要考虑使用多个线程池)
Note:
-
游戏业务处理框架中对线程数量的管理需要考虑任务的类型:I/O密集型,计算密集型还是两者都有;如果有多种类型的任务则需要考虑使用多个线程池:
-
业务处理是计算密集型(比如游戏中总战力的计算、战报检验、业务逻辑处理,如果有N个处理器,建议分配N+1个线程)
-
数据库操作是IO密集型,比如数据库和Redis读写、网络I/O操作(不同进程通信)、磁盘I/O操作(日志文件写入)等
分配两个独立的线程池可以使得业务处理不受数据库操作的影响
-
-
在对线程的使用上,一定要严格按照不同的任务类型,使用对应的线程池。在游戏服务开发中,要严格规定开发人员不可随意创建新的线程。如果有特殊情况,需要特殊说明,并做好其使用性的评估,防止创建线程的地方过多,最后不可控制。
-
-
【问】Netty是什么?为什么要学习Netty?(异步,基于事件驱动的网络框架)
Note:
-
Netty 是一个异步的、基于事件驱动的网络应用框架,在
java.nio基础上进行了封装(客户端SocketChannel封装成了NioSocketChannel,服务器端的ServerSocketChannel封装成了NioServerSocketChannel),用于快速开发可维护、高性能的网络服务器和客户端。Netty在Java网络应用框架中的地位就好比Spring框架在JavaEE开发中的地位。 -
为了保证网络通信的需求,以下的框架都使用了 Netty:
Cassandra- nosql 数据库Spark- 大数据分布式计算框架Hadoop- 大数据分布式存储框架RocketMQ- ali 开源的消息队列ElasticSearch- 搜索引擎gRPC- rpc 框架Dubbo- rpc 框架Spring 5.x- flux api 完全抛弃了 tomcat ,使用 netty 作为服务器端Zookeeper- 分布式协调框架
-
-
【问】Netty的核心组件有哪些?(线程池 + selector + channel(底层是文件缓存)+ 任务队列 + channelPipeline(责任链,包含多个handler处理不同事件)),参考Netty如何封装Socket客户端Channel,Netty的Channel都有哪些类型?,Netty的核心组件,netty执行流程及核心模块详解(入门必看系列)
Note:
-
核心组件基本概念:
-
事件循环组(EventLoopGroup):可以将事件循环组简单的理解为线程池,它里面包含了多个事件循环线程(也就是
EventLoop),初始化事件循环组的时候可以指定创建事件循环个数。 -
每个事件循环线程绑定一个任务队列,该任务队列用于处理非IO事件,比如通道注册,端口绑定等等,事件循环组中的
EventLoop线程均处于活跃状态,每个EventLoop线程绑定一个选择器(Selector),一个选择器(Selector)注册了多个通道(客户端连接),当通道产生事件的时候,绑定在选择器上的事件循环线程就会激活,并处理事件。 -
对于
BossGroup事件循环组来说,里面的事件循环只监听通道的连接事件(即accept())。 -
对于
WorkerGroup事件循环组来说,里面的事件循环只监听读事件(read())。如果监听到通道的连接事件(accept()),会交给BossGroup事件循环组中某个事件循环处理,处理完之后生成客户端通道(channel)注册至WorkerGroup事件循环组中的某个事件循环,并绑定读事件,这个事件循环就会监听读事件,客户端发起读写请求的时候,这个事件循环就会监听到并处理。-
选择器(selector) :
Selector绑定一个事件循环线程(EventLoop),其上可以注册多个通道(可以简单的理解为客户端连接),Selector负责监听通道的事件(连接、读写),当客户端发起读写请求的时候,Selector所绑定的事件线程(EventLoop)就会唤醒,并从通道中读取事件进行处理。 -
任务队列和尾任务队列:一个事件循环绑定一个任务队列和尾队列,用于存储通道事件。
-
通道(channel):Linux程序在执行任何形式的 IO 操作时,都是在操作文件(比如可以通过
sed|awk命令查看进程情况,查看进程的内容实际上还是个文件)。由于在UNIX系统中支持TCP/IP协议栈,就相当于引入了新的IO操作,也就是Socket IO,这个IO操作专用于网络传输。因此Linux系统把Socket也看作是一种文件。我们在使用Socket IO发送数据的时候,实际上就是操作文件:
-
首先打开文件,将数据写进文件(文件的上层也有一层缓存,叫文件缓存),再将文件缓存中的数据拷贝至网卡的发送缓冲区;
-
再通过网卡将缓冲区的数据发送至对方的网卡的接收缓冲区,对方的网卡接收到数据后,打开文件,将数据拷贝到文件,再将文件缓存中的数据拷贝至用户缓存,然后再处理数据。
Channel是对Socket的封装,因此它的底层也是在操作文件,所以操作Channel的就是在操作Socket,操作Socket(本身就是一种文件)就是在操作文件。Netty分别对JDK中客户端SocketChannel和服务器端的ServerSocketChannel进行再次封装,得到NioSocketChannel和NioServerSocketChannel。 -
-
-
管道(ChannelPipeline) :管道是以一组编码器为结点的链表,用于处理客户端请求,也是真正处理业务逻辑的地方。
-
处理器(ChannelHandler) :处理器,是管道的一个结点,一个客户端请求通常由管道里的所有处理器(handler)逐一的处理。
-
事件KEY(selectionKey) :当通道(
channel)产生事件的时候,Selector就会生成一个selectionKey事件,并唤醒事件线程去处理事件。 -
缓冲(Buffer) :NIO是面向块的IO,从通道读取数据之后会放进缓存(Buffer),向通道写数据的时候也需要先写进缓存(Buffer),总之既不能直接从通道读数据,也不能直接向通道写数据。
-
缓冲池(BufferPool) :这是
Netty针对内存的一种优化手段,通过一种池化技术去管理固定大小的内存。(当线程需要存放数据的时候,可以直接从缓冲池中获取内存,不需要的时候再放回去,这样不需要去频繁的重新去申请内存,因为申请内存是需要时间的,影响性能) -
ServerBootstrap 与 Bootstrap:
Bootstrap和ServerBootstrap被称为引导类,指对应用程序进行配置,并使他运行起来的过程。Netty处理引导的方式是使你的应用程序和网络层相隔离。-
Bootstrap是客户端的引导类,Bootstrap在调用bind()(连接UDP)和connect()(连接TCP)方法时,会新创建一个Channel,仅创建一个单独的、没有父 Channel 的Channel来实现所有的网络交换。 -
ServerBootstrap是服务端的引导类,ServerBootstrap在调用bind()方法时会创建一个ServerChannel来接受来自客户端的连接,并且该 ServerChannel 管理了多个子 Channel 用于同客户端之间的通信。
-
-
ChannelFuture:
Netty 中所有的 I/O 操作都是异步的,即操作不会立即得到返回结果,所以 Netty 中定义了一个ChannelFuture对象作为这个异步操作的“代言人”,表示异步操作本身。如果想获取到该异步操作的返回值,可以通过该异步操作对象的addListener()方法为该异步操作添加 NIO 网络编程框架 Netty 监听器,为其注册回调:当结果出来后马上调用执行。Netty的异步编程模型都是建立在Future与回调call_back()概念之上的。
-
-
组件与组件之间的关系如下:
- 一个事件循环组(
EventLoopGroup)包含多个事件循环(EventLoop) -1 ... *; - 一个选择器(
selector)只能注册进一个事件循环(EventLoop)-1 ... 1; - 一个事件循环(
EventLoop)包含一个任务队列和尾任务队列 -1 ... 1; - 一个通道(
channel)只能注册进一个选择器(selector)-1 ... 1; - 一个通道(
channel)只能绑定一个管道(channelPipeline) -1 ... 1; - 一个管道(
channelPipeline)包含多个服务编排处理器(channelHandler) - Netty通道(
NioSocketChannel/NioServerSocketChannel)和原生NIO通道(SocketChannel/SocketServerChannel)一一对应并绑定 -1 ... 1; - 一个通道可以关注多个IO事件;
- 一个事件循环组(
-
-
【问】Netty 执行流程是怎样的?(自顶向下分析 / 客户端服务器分析),参考一文了解Netty整体流程,netty执行流程及核心模块详解(入门必看系列)
Note:
-
自顶向下分析流程:NioEventLoopGroup -> NioEventLoop -> selector -> channel,NioEventLoop监听不同channel(BossGroup中的NioEventLoop监听accept,work Group中的NioEventLoop监听read/write事件)

-
Netty 抽象出两组线程池 ,
BossGroup专门负责接收客户端的连接,WorkerGroup专门负责网络的读写;BossGroup和WorkerGroup类型都是NioEventLoopGroup -
NioEventLoopGroup相当于一个事件循环组,这个组中含有多个事件循环,每一个事件循环是NioEventLoop;-
NioEventLoop表示一个不断循环的执行处理任务的线程(selector监听绑定事件是否发生),每个NioEventLoop都有一个Selector,用于监听绑定在其上的socket的网络通讯,比如NioServerSocketChannel绑定在服务器bossgroup的NioEventLoop的selector上,NioSocketChannel绑定在客户端的NioEventLoop的selector上,然后各自的selector就不断循环监听相关事件。 -
NioEventLoopGroup可以有多个线程,即可以含有多个NioEventLoop
-
-
每个
BossGroup下面的NioEventLoop循环执行的步骤有 3 步-
轮询
accept事件 -
处理
accept事件,与client建立连接,生成NioScocketChannel,并将其注册到某个workerGroup NIOEventLoop上的Selector -
继续处理任务队列的任务,即
runAllTasks
-
-
每个
WorkerGroup下面的NIOEventLoop循环执行的步骤-
轮询
read,write事件 -
处理
I/O事件,即read,write事件,在对应NioScocketChannel处理。 -
处理任务队列的任务,即
runAllTasks
-
-
每个
Worker下面的NIOEventLoop处理业务时,会使用pipeline(管道),pipeline中包含了channel(通道),即通过pipeline可以获取到对应通道,管道中维护了很多的处理器。 -
NioEventLoop内部采用串行化设计,从消息的 读取->解码->处理->编码->发送,始终由 IO 线程NioEventLoop负责 -
NioEventLoopGroup下包含多个NioEventLoop
每个NioEventLoop中包含有一个Selector,一个taskQueue
每个NioEventLoop的Selector上可以注册监听多个NioChannel
每个NioChannel只会绑定在唯一的NioEventLoop上
每个NioChannel都绑定有一个自己的ChannelPipeline
NioChannel可以获取对应的ChannelPipeline,ChannelPipeline也可以获取对应的NioChannel。
-
-
客户端服务器分析流程如下:
-
Server启动,Netty从ParentGroup(BossGroup)中选出一个NioEventLoop对指定port进行监听。 -
Client启动,Netty从ParentGroup(BossGroup)中选出个NioEventLoop连接Server。 -
Client连接Server的port,创建Channel -
Netty从ChildGroup(WorkGroup)中选出一个NioEventLoop与channel绑定,用于处理该Channel中所有的操作。 -
Client通过Channel向Server发送数据包。 -
Pipeline中的处理器采用责任链的模式对Channel中的数据包进行处理 -
Server 如需向Client发送数据。则需将数据经
pipeline中的处理器处理行
成ByteBuf数据包进行传输。 -
Server将数据包通过channel发送给Client -
Pipeline中的处理器采用责任链的模式对channel中的数据包进行处理
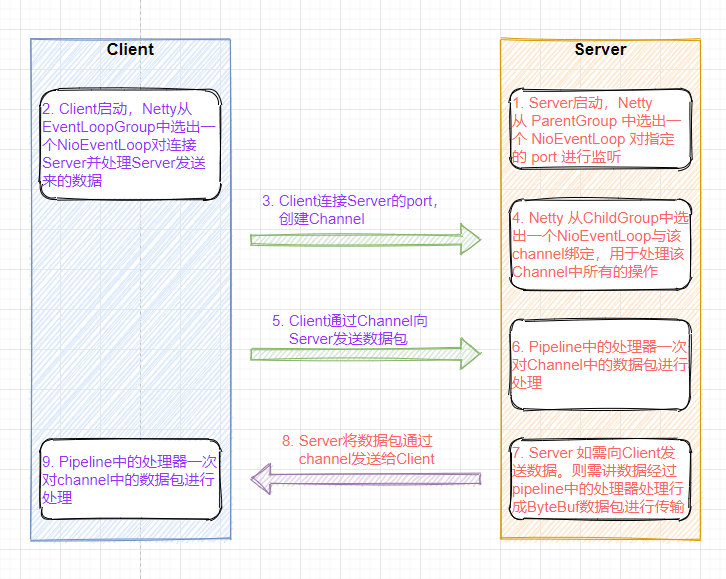
-
-
-
Note:
-
参考上一问中关于客户端/服务端的Netty执行流程,给出如下代码
-
服务端:
package org.example.code001_helloworld; import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.Channel; import io.netty.channel.ChannelHandlerContext; import io.netty.channel.ChannelInitializer; import io.netty.channel.SimpleChannelInboundHandler; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.nio.NioServerSocketChannel; import io.netty.channel.socket.nio.NioSocketChannel; import io.netty.handler.codec.string.StringDecoder; public class HelloServer { public static void main(String[] args) throws InterruptedException{ //通过ServerBootStrap引导类创建channel ServerBootstrap sb = new ServerBootstrap() .group(new NioEventLoopGroup()) //2、选择事件循环组为NioEventLoopGroup,返回ServerBootstrap .channel(NioServerSocketChannel.class) //3、选择通道实现类为NioServerSocketChannel,返回ServerBootstrap .childHandler( //为channel添加处理器,返回返回ServerBootstrap new ChannelInitializer<NioSocketChannel>(){ //4、初始化处理器,用来监听客户端创建的SocketChannel protected void initChannel(NioSocketChannel ch) throws Exception { ch.pipeline().addLast(new StringDecoder()); // 5、处理器1用于将ByteBuf解码为String ch.pipeline().addLast(new SimpleChannelInboundHandler<String>() { // 6、处理器2即业务处理器,用于处理上一个处理器的处理结果 @Override protected void channelRead0(ChannelHandlerContext ctx, String msg) { System.out.println(msg); //输出客户端往NioSocketChannel中发送端数据 } }); } } ); ); // sb.bind("127.0.0.1",8080); //监听客户端的socket端口 ChannelFuture channelFuture = sb.bind("127.0.0.1",8080); //监听客户端的socket端口(默认127.0.0.1) //设置监听器 channelFuture.addListener(new GenericFutureListener<Future<? super Void>>() { @Override public void operationComplete(Future<? super Void> future) throws Exception { if(future.isSuccess()){ System.out.println("端口绑定成功"); }else{ System.out.println("端口绑定失败"); } } }); while(true){ Thread.sleep(1000); //睡眠5s System.out.println("我干我的事情"); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
-
客户端:
package org.example.code001_helloworld; import io.netty.bootstrap.Bootstrap; import io.netty.channel.Channel; import io.netty.channel.ChannelInitializer; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.nio.NioSocketChannel; import io.netty.handler.codec.string.StringEncoder; import java.util.Date; public class HelloClient{ public static void main(String[] args) throws InterruptedException { int i = 3; while(i > 0) { Channel channel = new Bootstrap() //客户端启动类,用于引导创建channel;其中Bootstrap继承于AbstractBootstrap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
-
先开启服务器端,再开启三个客户端;服务端通过自定义处理器,从8080端口中监听到客户端发送过来的数据,并打印到控制台。
我干我的事情 我干我的事情 我干我的事情 我干我的事情 Thu Nov 10 23:17:03 CST 2022: hello world! My name is wang1 Thu Nov 10 23:17:03 CST 2022: hello world! My name is wang3 Thu Nov 10 23:17:03 CST 2022: hello world! My name is wang2 我干我的事情 我干我的事情 我干我的事情 我干我的事情- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
-
对上面的代码流程进行简单解析:
-
服务器端先从线程池中选择一个线程,用于监听服务器端绑定的
ip和端口(即127.0.0.1和8080)。这里的端口是客户端访问服务器端的唯一入口,当多个客户端在同一时间向服务器端发送大量请求,如果服务器端对每个客户端的请求进行一一接收,则会出现阻塞等待问题。
-
为了解决阻塞问题,客户端的不同请求通过不同的
channel(即文件缓存)以文件形式保存在服务器端监听的端口中,因此这里服务器端专门开启一个线程来监听这个端口,该线程与selector绑定,让selector完成事件处理工作。 -
待
channel传输完毕之后(文件缓存满了,写入到文件),selector会通过channelPipeline中自定义的channelHandler对数据进行处理。
-
-
-
Note:
这里分别使用
juc.Future,Consumer函数式接口,和netty的promise,模拟数据库数据查询过程:-
在等待获取
juc.Future返回结果时,主线程是阻塞的。package org.example.code000_JUC_test; import java.util.concurrent.Callable; import java.util.concurrent.CancellationException; import java.util.concurrent.FutureTask; public class code001_future_test { //模拟数据库查询操作 public String getUsernameById(Integer id) throws InterruptedException{ Thread.sleep(1000); //模拟IO过程 return "wangxiaoxi"; } public static void main(String[] args) { final code001_future_test obj = new code001_future_test(); //FutureTask处理的数据类型即为Callable异步返回的数据类型 FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>(){ public String call() throws Exception { System.out.println("thread1正在异步执行中"); String username = obj.getUsernameById(1); System.out.println("callable over"); return username; } }); //创建线程并异步执行 Thread thread = new Thread(futureTask); thread.start(); try{ System.out.println("mainThread开始操作"); String res = futureTask.get(); //主线程会阻塞,同步等待线程1执行结束,并返回值 System.out.println("thread1处理完毕," + "用户名为:" + res); int i = 5; while(i > 0){ System.out.println("mainThread正在执行中"); Thread.sleep(1000); i--; } System.out.println("mainThread结束操作"); }catch (InterruptedException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } } --- mainThread开始操作 thread1正在异步执行中 callable over thread1处理完毕,用户名为:wangxiaoxi mainThread正在执行中 mainThread正在执行中 mainThread正在执行中 mainThread正在执行中 mainThread正在执行中 mainThread结束操作- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
-
通过回调函数(
Consumer+consumer lambda8表达式)的方式来处理返回结果,此时主线程仍然可以完成其他操作,无需阻塞等待其他线程的返回结果。但是会存在consumer被多个线程同时使用的并发问题。package org.example.code000_JUC_test; import java.util.function.Consumer; public class code002_consumer_test { //模拟数据库查询操作, 其中consumer是回调函数, 所以该函数无返回值 public void getUsernameById(Integer id, Consumer<String> consumer) throws InterruptedException{ Thread.sleep(1000); //模拟IO过程 String username = "wangxiaoxi"; consumer.accept(username); } public static void main(String[] args) throws InterruptedException{ final code002_consumer_test obj = new code002_consumer_test(); Consumer<String> consumer = ((s) -> { System.out.println("thread1处理完毕,用户名为:" + s); }); //通过回调函数异步执行 Thread thread = new Thread(new Runnable(){ public void run() { try { System.out.println("thread1正在异步执行中"); obj.getUsernameById(1,consumer); //函数式编程: consumer有入参,无返回值 } catch (InterruptedException e) { throw new RuntimeException(e); } } }); thread.start(); System.out.println("mainThread开始操作"); int i = 5; while(i > 0){ System.out.println("mainThread正在执行中"); Thread.sleep(1000); i--; } System.out.println("mainThread结束操作"); } } --- mainThread开始操作 mainThread正在执行中 thread1正在异步执行中 mainThread正在执行中 thread1处理完毕,用户名为:wangxiaoxi mainThread正在执行中 mainThread正在执行中 mainThread正在执行中 mainThread结束操作- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
-
netty重写了juc.Future接口,并在此基础上派生出子接口promise,promise可以通过设置监听器来监听promise是否已被其他线程处理(此时listener通过promise.await阻塞等待promise处理结果,待promise已被其他线程处理,则该线程会通过promise.notify唤醒listener,通知其对结果进行处理;如果future.isSuccess()则表示处理成功,如果future.Cancelled()则表示处理失败)。package org.example.code000_JUC_test; import io.netty.util.concurrent.DefaultEventExecutor; import io.netty.util.concurrent.DefaultEventExecutorGroup; import io.netty.util.concurrent.DefaultPromise; import io.netty.util.concurrent.EventExecutor; import io.netty.util.concurrent.EventExecutorGroup; import io.netty.util.concurrent.Future; import io.netty.util.concurrent.GenericFutureListener; import io.netty.util.concurrent.Promise; import java.util.function.Consumer; public class code003_netty_test { public Future<String> getUsernameById(Integer id,Promise<String> promise) throws InterruptedException{ //模拟从数据库线程池中取出某一个线程进行操作 new Thread(new Runnable() { @Override public void run() { System.out.println("thread2正在异步执行中"); try { Thread.sleep(1000); //模拟IO过程 } catch (InterruptedException e) { throw new RuntimeException(e); } String username = "wangxiaoxi"; System.out.println("thread2处理完毕"); promise.setSuccess(username); } }).start(); return promise; //返回promise的线程和处理promise线程并不是同一个线程 } public static void main(String[] args) throws InterruptedException{ code003_netty_test obj = new code003_netty_test(); EventExecutor executor = new DefaultEventExecutor(); //通过netty创建线程 executor.execute(new Runnable() { @Override public void run() { System.out.println("thread1正在异步执行中"); //异步调用返回值(继承于netty.Future,可用于设置监听器) Promise<String> promise = new DefaultPromise<String>(executor); //设置监听器,阻塞等待(object.await)直到promise返回结果并对其进行处理 try { obj.getUsernameById(1,promise).addListener(new GenericFutureListener<Future<? super String>>() { @Override public void operationComplete(Future<? super String> future) throws Exception { System.out.println("thread1.listener监听完毕"); if(future.isSuccess()){ System.out.println("thread1.listener监听到promise的返回值"); String username = (String)future.get(); System.out.println("thread1处理完毕,用户名为:" + username); } } }); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); System.out.println("mainThread开始操作"); int i = 5; while(i > 0){ System.out.println("mainThread正在执行中"); Thread.sleep(1000); i--; } System.out.println("mainThread结束操作"); } } --- mainThread开始操作 mainThread正在执行中 thread1正在异步执行中 thread2正在异步执行中 mainThread正在执行中 thread2处理完毕 thread1.listener监听完毕 thread1.listener监听到promise的返回值 thread1处理完毕,用户名为:wangxiaoxi mainThread正在执行中 mainThread正在执行中 mainThread正在执行中 mainThread结束操作- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
promise结合了回调函数和Future的优点,回调函数的创建和处理可以不在同一个线程中(线程1创建promise,线程1的子线程2用于处理promise,因此不存在并发上的问题)
-
-
【问】ChannelFuture和Promise可用来干什么?两者有什么区别?(
ChannelFuture和Promise一样,都继承于netty的Future,可用于异步处理结果的返回),参考Netty异步回调模式-Future和Promise剖析Note:
-
Netty的Future继承JDK的Future,通过 Object 的wait/notify机制,实现了线程间的同步;使用观察者设计模式,实现了异步非阻塞回调处理。其中:-
ChannelFuture和Promise都是Netty的Future的子接口; -
ChannelFuture和Channel绑定,用于异步处理Channel事件;但不能根据Future的执行状态设置返回值。 -
Promise对Netty的Future基础上进行进一步的封装,增加了设置返回值和异常消息的功能,根据不同数据处理的返回结果定制化Future的返回结果,比如:@Override public void channelRegister(AbstractGameChannelHandlerContext ctx, long playerId, GameChannelPromise promise) { // 在用户GameChannel注册的时候,对用户的数据进行初始化 playerDao.findPlayer(playerId, new DefaultPromise<>(ctx.executor())).addListener(new GenericFutureListener<Future<Optional<Player>>>() { @Override public void operationComplete(Future<Optional<Player>> future) throws Exception { Optional<Player> playerOp = future.get(); if (playerOp.isPresent()) { player = playerOp.get(); playerManager = new PlayerManager(player); promise.setSuccess(); fixTimerFlushPlayer(ctx);// 启动定时持久化数据到数据库 } else { logger.error("player {} 不存在", playerId); promise.setFailure(new IllegalArgumentException("找不到Player数据,playerId:" + playerId)); } } }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
当消息设置成功后会立即通知
listener处理结果;一旦setSuccess(V result)或setFailure(V result)后,那些await()或sync()的线程就会从等待中返回。 -
ChannelPromise继承了ChannelFuture和Promise,是可写的ChannelFuture接口

-
-
ChannelFuture接口:Netty的I/O操作都是异步的,例如bind,connect,write等操作,会返回一个ChannelFuture接口。Netty源码中大量使用了异步回调处理模式,比如在接口绑定任务时,可以通过设置Listener实现异步处理结果的回调,这个过程被称为被动回调。... ChannelFuture channelFuture = sb.bind("127.0.0.1",8080); //监听客户端的socket端口 //设置监听器 channelFuture.addListener(new GenericFutureListener<Future<? super Void>>() { @Override public void operationComplete(Future<? super Void> future) throws Exception { if(future.isSuccess()){ System.out.println("端口绑定成功"); }else{ System.out.println("端口绑定失败"); } } }); ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
ChannelFuture和IO操作中的channel通道关联在一起了,用于异步处理channel事件,这个接口在实际中用的最多。ChannelFuture接口相比父类Future接口,就增加了channel()和isVoid()两个方法ChannelFuture接口定义的方法如下:public interface ChannelFuture extends Future<Void> { // 获取channel通道 Channel channel(); @Override ChannelFuture addListener(GenericFutureListener<? extends Future<? super Void>> listener); @Override ChannelFuture addListeners(GenericFutureListener<? extends Future<? super Void>>... listeners); @Override ChannelFuture removeListener(GenericFutureListener<? extends Future<? super Void>> listener); @Override ChannelFuture removeListeners(GenericFutureListener<? extends Future<? super Void>>... listeners); @Override ChannelFuture sync() throws InterruptedException; @Override ChannelFuture syncUninterruptibly(); @Override ChannelFuture await() throws InterruptedException; @Override ChannelFuture awaitUninterruptibly(); // 标记Futrue是否为Void,如果ChannelFuture是一个void的Future,不允许调// 用addListener(),await(),sync()相关方法 boolean isVoid(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
ChannelFuture就两种状态Uncompleted(未完成)和Completed(完成),Completed包括三种,执行成功,执行失败和任务取消。注意:执行失败和任务取消都属于Completed。
-
Promise接口:Promise是个可写的Future,接口定义如下public interface Promise<V> extends Future<V> { // 执行成功,设置返回值,并通知所有listener,如果已经设置,则会抛出异常 Promise<V> setSuccess(V result); // 设置返回值,如果已经设置,返回false boolean trySuccess(V result); // 执行失败,设置异常,并通知所有listener Promise<V> setFailure(Throwable cause); boolean tryFailure(Throwable cause); // 标记Future不可取消 boolean setUncancellable(); @Override Promise<V> addListener(GenericFutureListener<? extends Future<? super V>> listener); @Override Promise<V> addListeners(GenericFutureListener<? extends Future<? super V>>... listeners); @Override Promise<V> removeListener(GenericFutureListener<? extends Future<? super V>> listener); @Override Promise<V> removeListeners(GenericFutureListener<? extends Future<? super V>>... listeners); @Override Promise<V> await() throws InterruptedException; @Override Promise<V> awaitUninterruptibly(); @Override Promise<V> sync() throws InterruptedException; @Override Promise<V> syncUninterruptibly(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
Future接口只提供了获取返回值的get()方法,不可设置返回值。 -
Promise接口在Future基础上,还提供了设置返回值和异常信息,并立即通知listeners。而且,一旦setSuccess(...)或setFailure(...)后,那些await()或sync()的线程就会从等待中返回。同步阻塞有两种方式:sync()和await(),区别:
sync()方法在任务失败后,会把异常信息抛出;await()方法对异常信息不做任何处理,当我们不关心异常信息时可以用await()。通过阅读源码可知
sync()方法里面其实调的就是await()方法。// DefaultPromise 类 @Override public Promise<V> sync() throws InterruptedException { await(); rethrowIfFailed(); return this; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
通过继承
Promise接口,得到关于ChannelFuture的可写的子接口ChannelPromise;Promise的实现类为DefaultPromise,通过Object的wait/notify来实现线程的同步,通过volatile关键字保证线程间的可见性。ChannelPromise的实现类为DefaultChannelPromise,其继承关系如下:

-
-
【问】ChannelPipeline的执行过程(ChannelHandler在ChannelPipeline中被封装成ChannelHandlerContext,通过tail和head标识来实现读写处理),参考Netty的TCP粘包和拆包解决方案,黑马Netty教程
Note:
-
Selector轮询到网络IO事件后,会调用该Channel对应的ChannelPipeline来依次执行对应的ChannelHandler。基于事件驱动的Netty框架如下:

-
上面我们已经知道
ChannelPipeline和ChannelHandler的关系 :ChannelPipeline是一个存放各种ChannelHandler的管道容器。ChannelPipeline的执行流程如下(ChannelHandler也分为了两大类:ChannelInboundHandler是用于负责处理链路读事件的Handler,ChannelOutboundHandler是用于负责处理链路写事件的Handler):NioEventLoop触发读事件,会调用SocketChannel所关联的ChannelPipline- 由上一步读取到的消息会在
ChannelPipline中依次被多个ChannelInboundHandler处理。 - 处理完消息会调用
ChannelHandlerContext的write方法发送消息,此时触发写事件,发送的消息同样也会经过ChannelPipline中的多个ChannelOutboundHandler处理。

-
一个
channel绑定一个channelPipeline,可以通过channel获取channelPipeline进而添加channelHandler;channelPipeline初始化代码如下:eventGroup = new NioEventLoopGroup(gameClientConfig.getWorkThreads());// 从配置中获取处理业务的线程数 bootStrap = new Bootstrap(); bootStrap.group(eventGroup).channel(NioSocketChannel.class).option(ChannelOption.TCP_NODELAY, true).option(ChannelOption.SO_KEEPALIVE, true).option(ChannelOption.CONNECT_TIMEOUT_MILLIS, gameClientConfig.getConnectTimeout() * 1000).handler(new ChannelInitializer<Channel>() { @Override protected void initChannel(Channel ch) throws Exception { ch.pipeline().addLast("EncodeHandler", new EncodeHandler(gameClientConfig));// 添加编码 ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024 * 1024 * 4, 0, 4, -4, 0));// 添加解码 ch.pipeline().addLast("DecodeHandler", new DecodeHandler());// 添加解码 ch.pipeline().addLast("responseHandler", new ResponseHandler(gameMessageService));//将响应消息转化为对应的响应对象 // ch.pipeline().addLast(new TestGameMessageHandler());//测试handler ch.pipeline().addLast(new IdleStateHandler(150, 60, 200));//如果6秒之内没有消息写出,发送写出空闲事件,触发心跳 ch.pipeline().addLast("HeartbeatHandler",new HeartbeatHandler());//心跳Handler ch.pipeline().addLast(new DispatchGameMessageHandler(dispatchGameMessageService));// 添加逻辑处理 } }); ChannelFuture future = bootStrap.connect(gameClientConfig.getDefaultGameGatewayHost(), gameClientConfig.getDefaultGameGatewayPort()); channel = future.channel();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
ChannelHandler在ChannelPipline中的结构:
ChannelHandler在加入ChannelPipline之前会被封装成一个ChannelHandlerContext节点类加入到一个双向链表结构中。除了头尾两个特殊的ChannelHandlerContext实现类,我们自定义加入的ChannelHandler最终都会被封装成一个DefaultChannelHandlerContext类。
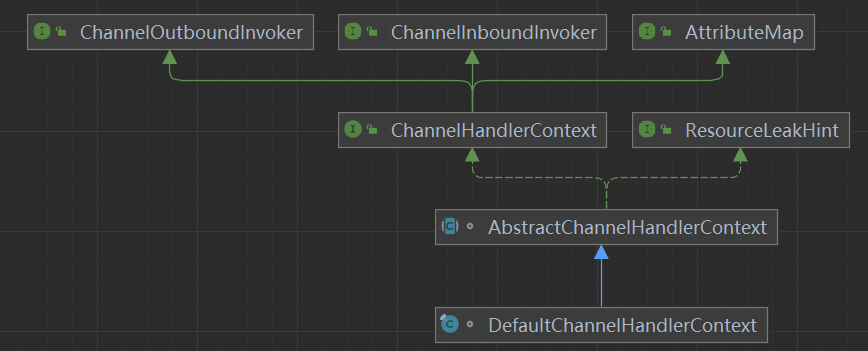
-
当有读事件被触发时,
ChannelHandler(会筛选类型为ChannelInboundHandler的Handler) 的 触发顺序是HeaderContext->TailContext -
当有写事件被触发时,
ChannelHandler(会筛选类型为ChannelOutboundHandler的Handler) 的 触发顺序与读事件相反是TailContext->HeaderContext
可以看到,nio 工人和 非 nio 工人也分别绑定了 channel(LoggingHandler 由 nio 工人执行,而自己的 handler 由非 nio 工人执行)

-
-
-
【问】ChannelPipeline中的事件是什么?(事件可以理解成一次IO操作,比如数据库查询、网络通信等;该函数可通过Promise对象完成回调)
Note:
-
自定义事件类 -
GetPlayerInfoEvent如下,可用于标识相同类型的I/O事件操作,比如在getPlayerName()和getPlayerLevel()时会触发相同的事件标识,这时监听该事件标识的线程会对监听到的结果进行处理(如上图中不同通道中的处理器节点可以用相同EventLoop事件线程来执行):public class GetPlayerInfoEvent { private Long playerId; public GetPlayerInfoEvent(Long playerId) { super(); this.playerId = playerId; } public Long getPlayerId() { return playerId; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
在不基于注解下,将事件发送到
channelPipeline,核心方法如下:@Override public void userEventTriggered(AbstractGameChannelHandlerContext ctx, Object evt, Promise<Object> promise) throws Exception { if (evt instanceof IdleStateEvent) { logger.debug("收到空闲事件:{}", evt.getClass().getName()); ctx.close(); } else if (evt instanceof GetPlayerInfoEvent) { GetPlayerByIdMsgResponse response = new GetPlayerByIdMsgResponse(); response.getBodyObj().setPlayerId(this.player.getPlayerId()); response.getBodyObj().setNickName(this.player.getNickName()); Map<String, String> heros = new HashMap<>(); this.player.getHeros().forEach((k,v)->{//复制处理一下,防止对象安全溢出。 heros.put(k, v); }); //response.getBodyObj().setHeros(this.player.getHeros());不要使用这种方式,它会把这个map传递到其它线程 response.getBodyObj().setHeros(heros); promise.setSuccess(response); } UserEventContext<PlayerManager> utx = new UserEventContext<>(playerManager, ctx); dispatchUserEventService.callMethod(utx, evt, promise); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
其中:
UserEventContext是对AbstractGameChannelHandlerContext进一步的封装AbstractGameChannelHandlerContext是一个自定义的双向链表节点(包含pre,next指针),用DefaultGameChannelHandlerContext来实现,其中每个节点封装着事件处理器ChannelHandler;- 将链表节点
DefaultGameChannelHandlerContext添加到GameChannelPipeline中,得到双向链表,不同处理方向代表不同操作(读/写)。 - 依次为
GameChannelPipeline中的处理器分配可执行的线程,用于事件监听和回调。 - 其中
Step1~Step4为ChannelHandler的封装,Step5则为ChannelHandler分配线程设置监听器
-
Step1:
UserEventContext是AbstractGameChannelHandlerContext的处理类:public class UserEventContext<T> { private T dataManager; private AbstractGameChannelHandlerContext ctx; public UserEventContext(T dataManager, AbstractGameChannelHandlerContext ctx) { super(); this.dataManager= dataManager; this.ctx = ctx; } public T getDataManager() { return dataManager; } public AbstractGameChannelHandlerContext getCtx() { return ctx; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
Step2:
AbstractGameChannelHandlerContext事件处理器节点的构造器public AbstractGameChannelHandlerContext(GameChannelPipeline pipeline, EventExecutor executor, String name, boolean inbound, boolean outbound) { this.name = ObjectUtil.checkNotNull(name, "name"); this.pipeline = pipeline; this.executor = executor; this.inbound = inbound; this.outbound = outbound; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
Step3:
DefaultGameChannelHandlerContext是AbstractGameChannelHandlerContext实现类,其中封装着channelHandlerpublic class DefaultGameChannelHandlerContext extends AbstractGameChannelHandlerContext{ private final GameChannelHandler handler; public DefaultGameChannelHandlerContext(GameChannelPipeline pipeline, EventExecutor executor, String name, GameChannelHandler channelHandler) { super(pipeline, executor, name,isInbound(channelHandler), isOutbound(channelHandler));//判断一下这个channelHandler是处理接收消息的Handler还是处理发出消息的Handler this.handler = channelHandler; } private static boolean isInbound(GameChannelHandler handler) { return handler instanceof GameChannelInboundHandler; } private static boolean isOutbound(GameChannelHandler handler) { return handler instanceof GameChannelOutboundHandler; } @Override public GameChannelHandler handler() { return this.handler; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
Step4:
GameChannelPipeline关于处理器的双向链表public class GameChannelPipeline { static final InternalLogger logger = InternalLoggerFactory.getInstance(DefaultChannelPipeline.class); private static final String HEAD_NAME = generateName0(HeadContext.class); private static final String TAIL_NAME = generateName0(TailContext.class); private final GameChannel channel; private Map<EventExecutorGroup, EventExecutor> childExecutors; //GameChannelPipeline构造器 protected GameChannelPipeline(GameChannel channel) { this.channel = ObjectUtil.checkNotNull(channel, "channel"); tail = new TailContext(this); head = new HeadContext(this); head.next = tail; tail.prev = head; } ... //生成处理器节点 private AbstractGameChannelHandlerContext newContext(GameEventExecutorGroup group, boolean singleEventExecutorPerGroup, String name, GameChannelHandler handler) { return new DefaultGameChannelHandlerContext(this, childExecutor(group, singleEventExecutorPerGroup), name, handler); } ... //将处理器节点添加到channelPipeline上 public final GameChannelPipeline addFirst(GameEventExecutorGroup group, boolean singleEventExecutorPerGroup, String name, GameChannelHandler handler) { final AbstractGameChannelHandlerContext newCtx; synchronized (this) { name = filterName(name, handler); newCtx = newContext(group, singleEventExecutorPerGroup, name, handler); addFirst0(newCtx); } return this; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
-
Step5:为每个
channelHandler设置监听器,GameChannelPipeline中的childExecutor方法如下:private EventExecutor childExecutor(GameEventExecutorGroup group, boolean singleEventExecutorPerGroup) { if (group == null) { return null; } if (!singleEventExecutorPerGroup) { return group.next(); } Map<EventExecutorGroup, EventExecutor> childExecutors = this.childExecutors; if (childExecutors == null) { // Use size of 4 as most people only use one extra EventExecutor. childExecutors = this.childExecutors = new IdentityHashMap<EventExecutorGroup, EventExecutor>(4); } // Pin one of the child executors once and remember it so that the same child executor // is used to fire events for the same channel. EventExecutor childExecutor = childExecutors.get(group); if (childExecutor == null) { childExecutor = group.next(); childExecutors.put(group, childExecutor); } return childExecutor; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
在基于注解下,只需要在当前事件方法上,在对象方法上标识
GetPlayerInfoEvent事件类,对象方法getPlayerInfoEvent会将事件发送到channelPipeline上,在处理过程中会有专门的事件监听器进行监听:@UserEvent(GetPlayerInfoEvent.class) public void getPlayerInfoEvent(UserEventContext<PlayerManager> ctx, GetPlayerInfoEvent event, Promise<Object> promise) { GetPlayerByIdMsgResponse response = new GetPlayerByIdMsgResponse(); Player player = ctx.getDataManager().getPlayer(); response.getBodyObj().setPlayerId(player.getPlayerId()); response.getBodyObj().setNickName(player.getNickName()); Map<String, String> heros = new HashMap<>(); player.getHeros().forEach((k, v) -> {// 复制处理一下,防止对象安全溢出。 heros.put(k, v); }); // response.getBodyObj().setHeros(this.player.getHeros());不要使用这种方式,它会把这个map传递到其它线程 response.getBodyObj().setHeros(heros); promise.setSuccess(response); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
UserEventContext作用同上,封装着ChannelHandler,并将ChannelHandler插入到GamePipeline中。
-
-
【问】如何理解事件系统的流程?(事件触发 - 监听者处理事件)
Note:- 在服务启动的时候,功能模块需要注册对事件监听的接口,监听的内容包括事件和事件源(事件产生的对象)。当事件触发的时候,就会调用这些监听的接口,并把事件和事件源传到接口的参数里面,然后在监听接口里面处理收到的事件。
- 事件只能从事件发布者流向事件监听者,不可以反向传播。

17、SpringSecurity & OAuth2.0
参考
以下是常见的面试题:
-
【问】什么是Spring Security?核心功能?(
Spring Security是一个基于Spring框架的安全框架,提供了完整的安全解决方案,包括认证、授权、攻击防护、会话管理、监视与管理等功能),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
Spring Security是一个基于Spring框架的安全框架,提供了完整的安全解决方案,包括认证、授权、攻击防护等功能。 -
其核心功能包括:
-
认证:提供了多种认证方式,如表单认证、
HTTP Basic认证、OAuth2认证等,可以与多种身份验证机制集成。 -
授权:提供了多种授权方式,如角色授权、基于表达式的授权等,可以对应用程序中的不同资源进行授权。
-
攻击防护:提供了多种防护机制,如跨站点请求伪造(CSRF)防护、注入攻击防护等。
-
会话管理:提供了会话管理机制,如令牌管理、并发控制等。
-
监视与管理:提供了监视与管理机制,如访问日志记录、审计等。
-
-
Spring Security通过配置安全规则和过滤器链来实现以上功能,可以轻松地为Spring应用程序提供安全性和保护机制。
-
-
【问】Spring Security的原理?(
Spring Security的核心原理是拦截器(Filter),使用责任链模式,如果遍历list(springSecurityFilterChain)且认证成功则返回),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
Spring Security是一个基于Spring框架的安全性认证和授权框架,它提供了全面的安全性解决方案,可以保护Web应用程序中的所有关键部分。 -
Spring Security的核心原理是拦截器(Filter)。Spring Security会在Web应用程序的过滤器链中添加一组自定义的过滤器,这些过滤器可以实现身份验证和授权功能。当用户请求资源时,Spring Security会拦截请求,并使用配置的身份验证机制来验证用户身份。如果身份验证成功,Spring Security会授权用户访问所请求的资源。
-
Spring Security的具体工作原理如下:-
1.用户请求Web应用程序的受保护资源。
-
2.
Spring Security拦截请求,并尝试获取用户的身份验证信息。 -
3.如果用户没有经过身份验证,
Spring Security将向用户显示一个登录页面,并要求用户提供有效的凭据(用户名和密码)。 -
4.一旦用户提供了有效的凭据,
Spring Security将验证这些凭据,并创建一个已认证的安全上下文(SecurityContext)对象。 -
5.安全上下文对象包含已认证的用户信息,包括用户名、角色和授权信息。
-
6.在接下来的请求中,
Spring Security将使用已经认证的安全上下文对象来判断用户是否有权访问受保护的资源。 -
7.如果用户有权访问资源,
Spring Security将允许用户访问资源,否则将返回一个错误信息。
-
-
-
【问】为什么要使用Spring Security?不能自己写一个认证和授权的模块吗?(因为
Spring Security已经通过责任链模式为我们封装了认证的过程,包括HTTP请求封装,密码加密,用户信息查询,token缓存,权限放行等操作),参考秒懂SpringBoot之全网最易懂的Spring Security教程 - ShuSheng007Note:
-
如果现在让你写一个登录功能(
Authentication)你怎么写?很自然的思路是不是把用户提交的信息和我们保存的信息做个比较,如果对上了就登录成功。其实spring security整体也是这样的,只是流程化后,兼顾扩展导致搞的很复杂。 -
Spring Security的整体原理为:- 当
http请求进来时,使用Servlet的Filter来拦截。 - 提取
http请求中的认证信息,例如username和password,或者Token。 - 从数据库(或者其他地方,例如
Redis)中查询用户注册时的信息,然后进行比对,相同则认证成功,反之失败。
主体就是这么简单,然后只有抓住这个主体思路才不容易被
Spring Security绕晕 - 当
-
一个请求过来
Spring Security会按照下图的步骤处理:
业务流程很清晰,之所以感觉复杂是因为经过框架的一顿设计,拉长了调用链。虽然在设计上复杂了,但是如果理解了这套设计流程,终端用户使用就会简单很多。
-
-
【问】有哪些控制请求访问权限的方法?(
permitAll(),denyAll(),anonymous(),authenticated(),hasRole(String role),hasAuthority(String authority)等),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
在
Spring Security中,可以使用以下方法来控制请求访问权限:-
permitAll():允许所有用户访问该请求,不需要进行任何身份验证。 -
denyAll():拒绝所有用户访问该请求。 -
anonymous():允许匿名用户访问该请求。 -
authenticated():要求用户进行身份验证,但是不要求用户具有任何特定的角色。 -
hasRole(String role):要求用户具有特定的角色才能访问该请求。 -
hasAnyRole(String... roles):要求用户具有多个角色中的至少一个角色才能访问该请求。 -
hasAuthority(String authority):要求用户具有特定的权限才能访问该请求。 -
hasAnyAuthority(String... authorities):要求用户具有多个权限中的至少一个权限才能访问该请求。
可以将这些方法应用于
Spring Security的配置类或者在Spring Security注解中使用。 -
-
-
【问】hasRole和hasAuthority有区别吗?(
hasRole检查用户是否有指定的角色,hasAuthority检查用户是否有指定的权限),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
在
Spring Security中,hasRole和hasAuthority都可以用来控制用户的访问权限,但它们有一些细微的差别。-
hasRole方法是基于角色进行访问控制的。它检查用户是否有指定的角色,并且这些角色以"ROLE_“前缀作为前缀(例如"ROLE_ADMIN”)。 -
hasAuthority方法是基于权限进行访问控制的。它检查用户是否有指定的权限,并且这些权限没有前缀。
因此,使用
hasRole方法需要在用户的角色名称前添加"ROLE_"前缀,而使用hasAuthority方法不需要这样做。 -
-
例如,假设用户有一个角色为"ADMIN" 和一个权限为"VIEW_REPORTS",可以使用以下方式控制用户对页面的访问权限:
.antMatchers("/admin/**").hasRole("ADMIN") .antMatchers("/reports/**").hasAuthority("VIEW_REPORTS")- 1
- 2
在这个例子中,只有具有"ROLE_ADMIN"角色的用户才能访问/admin/路径下的页面,而具有"VIEW_REPORTS"权限的用户才能访问/reports/路径下的页面。
-
-
【问】如何对密码进行加密?(提供了密码编码器,比如
BCryptPasswordEncoder、SCryptPasswordEncoder、StandardPasswordEncoder等),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
在
Spring Security中对密码进行加密通常使用的是密码编码器(PasswordEncoder)。PasswordEncoder的作用是将明文密码加密成密文密码,以便于存储和校验。Spring Security提供了多种常见的密码编码器,例如BCryptPasswordEncoder、SCryptPasswordEncoder、StandardPasswordEncoder等。 -
以
BCryptPasswordEncoder为例,使用步骤如下:-
1.在 pom.xml 文件中添加
BCryptPasswordEncoder的依赖:<dependency> <groupId>org.springframework.securitygroupId> <artifactId>spring-security-cryptoartifactId> <version>5.6.1version> dependency>- 1
- 2
- 3
- 4
- 5
-
2.在 Spring 配置文件中注入
BCryptPasswordEncoder:@Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); } // ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
3.在使用密码的地方调用
passwordEncoder.encode()方法对密码进行加密,例如注册时对密码进行加密:@Service public class UserServiceImpl implements UserService { @Autowired private PasswordEncoder passwordEncoder; @Override public User register(User user) { String encodedPassword = passwordEncoder.encode(user.getPassword()); user.setPassword(encodedPassword); // ... return user; } // ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
以上就是使用
BCryptPasswordEncoder对密码进行加密的步骤。使用其他密码编码器的步骤类似,只需将BCryptPasswordEncoder替换为相应的密码编码器即可。 -
-
-
【问】Spring Security基于用户名和密码的认证模式流程?(用户登录认证流程 + 受保护资源的授权过程,在认证和授权过程中会缓存认证结果在
SecurityContextHolder中),参考SpringSecurity常见面试题汇总(超详细回答)_spring security面试题_java路飞的博客-CSDN博客Note:
-
请求的用户名密码可以通过表单登录,基础认证,数字认证三种方式从
HttpServletRequest中获得,用于认证的数据源策略有内存,数据库,ldap,自定义等。 -
拦截未授权的请求,重定向到登录页面的过程:
-
1)当用户访问需要授权的资源时,
Spring Security会检查用户是否已经认证(即是否已登录),如果没有登录则会重定向到登录页面。 -
2)重定向到登录页面时,用户需要输入用户名和密码进行认证。
-
-
表单登录的过程:
-
1)用户在登录页面输入用户名和密码,提交表单。
-
2)
Spring Security的UsernamePasswordAuthenticationFilter拦截表单提交的请求,并将用户名和密码封装成一个Authentication对象。 -
3)
AuthenticationManager接收到Authentication对象后,会根据用户名和密码查询用户信息,并将用户信息封装成一个UserDetails对象。 -
4)如果查询到用户信息,则将
UserDetails对象封装成一个已认证的Authentication对象并返回,如果查询不到用户信息,则抛出相应的异常。 -
5)认证成功后,用户会被重定向到之前访问的资源。如果之前访问的资源需要特定的角色或权限才能访问,则还需要进行授权的过程。
-
-
Spring Security的认证流程大致可以分为两个过程,首先是用户登录认证的过程,然后是用户访问受保护资源时的授权过程。-
在认证过程中,用户需要提供用户名和密码,
Spring Security通过UsernamePasswordAuthenticationFilter将用户名和密码封装成Authentication对象,并交由AuthenticationManager进行认证。如果认证成功,则认证结果会存储在SecurityContextHolder中。在授权过程中,Spring Security会检查用户是否有访问受保护资源的权限,如果没有则会重定向到登录页面进行认证。-
拦截未授权的请求,重定向到登录页面

-
表单登录的过程,进行账号密码认证

-
-
-
-
【问】spring security所谓的全局上下文是如何实现的?(
SecurityContextHolder默认使用ThreadLocal策略来存储认证信息,也可以使用session进行存储,后续的访问则是通过sessionId来识别),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客,【老徐】Spring Security(一) —— Architecture Overview | 芋道源码 —— 纯源码解析博客 -
【问】了解spring security哪些核心组件,并介绍?(
AuthenticationManagerBuilder,SecurityContextHolder(通过ThreadLocal存储每个用户的安全上下文信息),Authentication(最高级别的身份/认证的抽象,过滤器先将获取到的用户名和密码被封装成该对象,接着获取数据库信息后回填至该对象中),AuthenticationManager(责任链模式,遍历list且认证成功则返回),UserDetails / UserDetailsService(从数据库中加载用户信息),DaoAuthenticationProvider(比对成功返回一个数据库中的用户信息)),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客Note:
-
AuthenticationManagerBuilder类:@Configuration @EnableWebSecurity public class WebSecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { auth .inMemoryAuthentication() .withUser("admin").password("admin").roles("USER"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
想要在
WebSecurityConfigurerAdapter中进行认证相关的配置,可以使用configure(AuthenticationManagerBuilder auth)暴露一个AuthenticationManager的建造器:AuthenticationManagerBuilder。如上所示,我们便完成了内存中用户的配置。但是在配置内存中的用户时,通常使用
configureGlobal来配置:@Configuration @EnableWebSecurity public class WebSecurityConfig extends WebSecurityConfigurerAdapter { @Autowired public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception { auth .inMemoryAuthentication() .withUser("admin").password("admin").roles("USER"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果你的应用只有唯一一个
WebSecurityConfigurerAdapter,那么他们之间的差距可以被忽略,从方法名可以看出两者的区别:使用@Autowired注入的AuthenticationManagerBuilder是全局的身份认证器,作用域可以跨越多个WebSecurityConfigurerAdapter,以及影响到基于Method的安全控制;而protected configure()的方式则类似于一个匿名内部类,它的作用域局限于一个WebSecurityConfigurerAdapter内部。官方文档中,也给出了配置多个WebSecurityConfigurerAdapter的场景以及demo。 -
SecurityContextHolder类:SecurityContextHolder用于存储安全上下文(security context)的信息。当前操作的用户是谁,该用户是否已经被认证,他拥有哪些角色权限…这些都被保存在SecurityContextHolder中。SecurityContextHolder默认使用ThreadLocal策略来存储认证信息。看到ThreadLocal也就意味着,这是一种与线程绑定的策略。Spring Security在用户登录时自动绑定认证信息到当前线程,在用户退出时,自动清除当前线程的认证信息。但这一切的前提,是你在web场景下使用Spring Security,而如果是Swing界面,Spring也提供了支持,SecurityContextHolder的策略则需要被替换。获取当前用户的信息 因为身份信息是与线程绑定的,所以可以在程序的任何地方使用静态方法获取用户信息。一个典型的获取当前登录用户的姓名的例子如下所示:
Object principal = SecurityContextHolder.getContext().getAuthentication().getPrincipal(); if (principal instanceof UserDetails) { String username = ((UserDetails)principal).getUsername(); } else { String username = principal.toString(); }- 1
- 2
- 3
getAuthentication()返回了认证信息,再次getPrincipal()返回了身份信息,UserDetails便是Spring对身份信息封装的一个接口。 -
Authentication类:package org.springframework.security.core;// <1> public interface Authentication extends Principal, Serializable { // <1> Collection<? extends GrantedAuthority> getAuthorities(); // <2> Object getCredentials();// <2> Object getDetails();// <2> Object getPrincipal();// <2> boolean isAuthenticated();// <2> void setAuthenticated(boolean var1) throws IllegalArgumentException; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Authentication是spring security包中的接口,直接继承自Principal类,而Principal是位于java.security包中的。可以见得,Authentication在spring security中是最高级别的身份/认证的抽象。由这个顶级接口,我们可以得到用户拥有的权限信息列表,密码,用户细节信息,用户身份信息,认证信息。authentication.getPrincipal()返回了一个Object,我们将Principal强转成了Spring Security中最常用的UserDetails,这在Spring Security中非常常见,接口返回Object,使用instanceof判断类型,强转成对应的具体实现类。接口详细解读如下:
-
getAuthorities(),权限信息列表,默认是GrantedAuthority接口的一些实现类,通常是代表权限信息的一系列字符串。 -
getCredentials(),密码信息,用户输入的密码字符串,在认证过后通常会被移除,用于保障安全。 -
getDetails(),细节信息,web应用中的实现接口通常为WebAuthenticationDetails,它记录了访问者的ip地址和sessionId的值。 -
getPrincipal(),最重要的身份信息,大部分情况下返回的是UserDetails接口的实现类,也是框架中的常用接口之一。
-
AuthenticationManager类:初次接触
Spring Security的朋友相信会被AuthenticationManager,ProviderManager,AuthenticationProvider…这么多相似的Spring认证类搞得晕头转向,但只要稍微梳理一下就可以理解清楚它们的联系和设计者的用意:-
AuthenticationManager(接口)是认证相关的核心接口,也是发起认证的出发点,因为在实际需求中,我们可能会允许用户使用用户名+密码登录,同时允许用户使用邮箱+密码,手机号码+密码登录,甚至,可能允许用户使用指纹登录,所以说AuthenticationManager一般不直接认证,AuthenticationManager接口的常用实现类ProviderManager内部会维护一个List列表,存放多种认证方式,实际上这是委托者(责任链)模式的应用(Delegate)。也就是说,核心的认证入口始终只有一个:AuthenticationManager,不同的认证方式:用户名+密码(
UsernamePasswordAuthenticationToken),邮箱+密码,手机号码+密码登录则对应了三个AuthenticationProvider。 -
只保留了关键认证部分的
ProviderManager源码:public class ProviderManager implements AuthenticationManager, MessageSourceAware, InitializingBean { // 维护一个AuthenticationProvider列表 private List<AuthenticationProvider> providers = Collections.emptyList(); public Authentication authenticate(Authentication authentication) throws AuthenticationException { Class<? extends Authentication> toTest = authentication.getClass(); AuthenticationException lastException = null; Authentication result = null; // 依次认证 for (AuthenticationProvider provider : getProviders()) { if (!provider.supports(toTest)) { continue; } try { result = provider.authenticate(authentication); if (result != null) { copyDetails(authentication, result); break; } } ... catch (AuthenticationException e) { lastException = e; } } // 如果有Authentication信息,则直接返回 if (result != null) { if (eraseCredentialsAfterAuthentication && (result instanceof CredentialsContainer)) { //移除密码 ((CredentialsContainer) result).eraseCredentials(); } //发布登录成功事件 eventPublisher.publishAuthenticationSuccess(result); return result; } ... //执行到此,说明没有认证成功,包装异常信息 if (lastException == null) { lastException = new ProviderNotFoundException(messages.getMessage( "ProviderManager.providerNotFound", new Object[] { toTest.getName() }, "No AuthenticationProvider found for {0}")); } prepareException(lastException, authentication); throw lastException; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
ProviderManager中的List,会依照次序去认证, 认证成功则立即返回,若认证失败则返回null,下一个AuthenticationProvider会继续尝试认证,如果所有认证器都无法认证成功,则ProviderManager会抛出一个ProviderNotFoundException异常。
-
-
UserDetails类和UserDetailsService类:UserDetails这个接口,它代表了最详细的用户信息,这个接口涵盖了一些必要的用户信息字段,具体的实现类对它进行了扩展。public interface UserDetails extends Serializable { Collection<? extends GrantedAuthority> getAuthorities(); String getPassword(); String getUsername(); boolean isAccountNonExpired(); boolean isAccountNonLocked(); boolean isCredentialsNonExpired(); boolean isEnabled(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
它和
Authentication接口很类似,比如它们都拥有username,authorities,区分他们也是本文的重点内容之一。Authentication的getCredentials()与UserDetails中的getPassword()需要被区分对待,前者是用户提交的密码凭证,后者是用户正确的密码,认证器其实就是对这两者的比对。Authentication中的getAuthorities()实际是由UserDetails的getAuthorities()传递而形成的,而Authentication接口中的getUserDetails()方法的用户详细信息则是经过了AuthenticationProvider之后被填充的。public interface UserDetailsService { UserDetails loadUserByUsername(String username) throws UsernameNotFoundException; }- 1
- 2
- 3
UserDetailsService和AuthenticationProvider两者的职责常常被人们搞混,关于他们的问题在文档的FAQ和issues中屡见不鲜。记住一点即可,UserDetailsService只负责从特定的地方(通常是数据库)加载用户信息,仅此而已,记住这一点,可以避免走很多弯路。UserDetailsService常见的实现类有JdbcDaoImpl,InMemoryUserDetailsManager,前者从数据库加载用户,后者从内存中加载用户,也可以自己实现UserDetailsService,通常这更加灵活。
-
DaoAuthenticationProvider类:AuthenticationProvider最最最常用的一个实现便是DaoAuthenticationProvider。顾名思义,Dao正是数据访问层的缩写,也暗示了这个身份认证器的实现思路。
按照我们最直观的思路,怎么去认证一个用户呢?用户前台提交了用户名和密码,而数据库中保存了用户名和密码,认证便是负责比对同一个用户名,提交的密码和保存的密码是否相同便是了。-
在
Spring Security中。提交的用户名和密码,被封装成了UsernamePasswordAuthenticationToken; -
而根据用户名加载用户的任务则是交给了
UserDetailsService; -
在
DaoAuthenticationProvider中,对应的方法便是retrieveUser,虽然有两个参数,但是retrieveUser只有第一个参数起主要作用,返回一个UserDetails。 -
接着还需要完成
UsernamePasswordAuthenticationToken和UserDetails密码的比对,这便是交给additionalAuthenticationChecks方法完成的,如果这个void方法没有抛异常,则认为比对成功。比对密码的过程,用到了PasswordEncoder和SaltSource,密码加密和盐的概念是为保障安全而设计。
DaoAuthenticationProvider类是:它获取用户提交的用户名和密码,比对其正确性,如果正确,返回一个数据库中的用户信息(假设用户信息被保存在数据库中)。 -
-
-
【问】关于Spring Security的架构图?(结合上面
Spring Security的核心组件进行理解),参考【老徐】Spring Security(一) —— Architecture Overview | 芋道源码 —— 纯源码解析博客Note:
-
为了更加形象的理解上述我介绍的这些核心类(核心组件),附上一张
Spring Security的一张非典型的UML架构图:
-
-
【问】Spring Security是如何完成身份认证的?(先是将用户名和密码封装成
Authentication对象; 接着根据该对象(比对密码)查询用户信息,并封装成UserDetails对象; 接着通过SecurityContextHolder和UserDetails,回填Authentication对象;最后如果认证成功后,用户会被重定向到之前访问的资源。参考上面几问进行学习),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客,【老徐】Spring Security(一) —— Architecture Overview | 芋道源码 —— 纯源码解析博客 -
【问】简述一下spring security核心过滤器?(
SecurityContextPersistenceFilter,HeaderWriterFilter,CsrfFilter,LogoutFilter,UsernamePasswordAuthenticationFilter,RequestCacheAwareFilter,SecurityContextHolderAwareRequestFilter,AnonymousAuthenticationFilter,SessionManagementFilter等),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客Note:
-
SecurityContextPersistenceFilter两个主要职责:- 1)请求来临时,创建
SecurityContext安全上下文信息 - 2)请求结束时清空
SecurityContextHolder。
- 1)请求来临时,创建
-
HeaderWriterFilter(文档中并未介绍,非核心过滤器) 用来给http响应添加一些Header,比如X-Frame-Options,X-XSS-Protection*,X-Content-Type-Options. -
CsrfFilter在spring4这个版本中被默认开启的一个过滤器,用于防止csrf攻击,了解前后端分离的人一定不会对这个攻击方式感到陌生,前后端使用json交互需要注意的一个问题。 -
LogoutFilter顾名思义,处理注销的过滤器 -
UsernamePasswordAuthenticationFilter这个会重点分析,表单提交了username和password,被封装成token进行一系列的认证,便是主要通过这个过滤器完成的,在表单认证的方法中,这是最最关键的过滤器。 -
RequestCacheAwareFilter(文档中并未介绍,非核心过滤器) 内部维护了一个RequestCache,用于缓存request请求 -
SecurityContextHolderAwareRequestFilter此过滤器对ServletRequest进行了一次包装,使得request具有更加丰富的API -
AnonymousAuthenticationFilter匿名身份过滤器,这个过滤器个人认为很重要,需要将它与UsernamePasswordAuthenticationFilter放在一起比较理解,spring security为了兼容未登录的访问,也走了一套认证流程,只不过是一个匿名的身份。 -
SessionManagementFilter和session相关的过滤器,内部维护了一个SessionAuthenticationStrategy,两者组合使用,常用来防止session-fixation protection attack,以及限制同一用户开启多个会话的数量 -
ExceptionTranslationFilter直译成异常翻译过滤器,还是比较形象的,这个过滤器本身不处理异常,而是将认证过程中出现的异常交给内部维护的一些类去处理,具体是那些类后面会详细介绍,可在主页的顶置或分栏里找到相应的链接。 -
FilterSecurityInterceptor这个过滤器决定了访问特定路径应该具备的权限,访问的用户的角色,权限是什么?访问的路径需要什么样的角色和权限?这些判断和处理都是由该类进行的。
-
-
【问】能说一下spring security配置类中permitAll的原理么?(直接放过过滤链的所有条件,赋予超级管理员用户的权限)),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客
Note:
permitAll是可以直接放过相应的条件的,在spring security内部会有一个超级管理员的用户赋予permitAll,这个超级管理员用户拥有超级权限,可以通过所有过滤链。
-
【问】介绍一下SecurityContextPersistenceFilter?(
SecurityContextPersistenceFilter和HttpSessionSecurityContextRepository配合使用,构成了Spring Security整个调用链路的入口;SecurityContextHolder存放用户(上下文/认证)信息,而用户登录过一次后,认证相关的信息会通过SecurityContextPersistenceFilter保存在session中,以便后续在session作用域使用),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客Note:
-
试想一下,如果我们不使用
Spring Security,如果保存用户信息呢,大多数情况下会考虑使用Session对吧?在Spring Security中也是如此,用户在登录过一次之后,后续的访问便是通过sessionId来识别,从而认为用户已经被认证。SecurityContextHolder存放用户信息,认证相关的信息是如何被存放到其中的,便是通过SecurityContextPersistenceFilter。-
SecurityContextPersistenceFilter的两个主要作用:在请求来临时,创建SecurityContext安全上下文信息,并在请求结束时清空SecurityContextHolder。 -
微服务的一个设计理念需要实现服务通信的无状态,而http协议中的无状态意味着不允许存在
session,这可以通过setAllowSessionCreation(false)实现,这并不意味着SecurityContextPersistenceFilter变得无用,因为它还需要负责清除用户信息。在Spring Security中,虽然安全上下文信息被存储于Session中,但我们在实际使用中不应该直接操作Session,而应当使用SecurityContextHolder。
-
-
源码分析:
org.springframework.security.web.context.SecurityContextPersistenceFilter public class SecurityContextPersistenceFilter extends GenericFilterBean { static final String FILTER_APPLIED = "__spring_security_scpf_applied"; //安全上下文存储的仓库 private SecurityContextRepository repo; public SecurityContextPersistenceFilter() { //HttpSessionSecurityContextRepository是SecurityContextRepository接口的一个实现类 //使用HttpSession来存储SecurityContext this(new HttpSessionSecurityContextRepository()); } public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException { HttpServletRequest request = (HttpServletRequest) req; HttpServletResponse response = (HttpServletResponse) res; if (request.getAttribute(FILTER_APPLIED) != null) { // ensure that filter is only applied once per request chain.doFilter(request, response); return; } request.setAttribute(FILTER_APPLIED, Boolean.TRUE); //包装request,response HttpRequestResponseHolder holder = new HttpRequestResponseHolder(request, response); //从Session中获取安全上下文信息 SecurityContext contextBeforeChainExecution = repo.loadContext(holder); try { //请求开始时,设置安全上下文信息,这样就避免了用户直接从Session中获取安全上下文信息 SecurityContextHolder.setContext(contextBeforeChainExecution); chain.doFilter(holder.getRequest(), holder.getResponse()); } finally { //请求结束后,清空安全上下文信息 SecurityContext contextAfterChainExecution = SecurityContextHolder .getContext(); SecurityContextHolder.clearContext(); repo.saveContext(contextAfterChainExecution, holder.getRequest(), holder.getResponse()); request.removeAttribute(FILTER_APPLIED); if (debug) { logger.debug("SecurityContextHolder now cleared, as request processing completed"); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
-
过滤器一般负责核心的处理流程,而具体的业务实现,通常交给其中聚合的其他实体类,这在
Filter的设计中很常见,同时也符合职责分离模式。例如存储安全上下文和读取安全上下文的工作完全委托给了HttpSessionSecurityContextRepository去处理,而这个类中也有几个方法可以稍微解读下,方便我们理解内部的工作流程org.springframework.security.web.context.HttpSessionSecurityContextRepository public class HttpSessionSecurityContextRepository implements SecurityContextRepository { // 'SPRING_SECURITY_CONTEXT'是安全上下文默认存储在Session中的键值 public static final String SPRING_SECURITY_CONTEXT_KEY = "SPRING_SECURITY_CONTEXT"; ... private final Object contextObject = SecurityContextHolder.createEmptyContext(); private boolean allowSessionCreation = true; private boolean disableUrlRewriting = false; private String springSecurityContextKey = SPRING_SECURITY_CONTEXT_KEY; private AuthenticationTrustResolver trustResolver = new AuthenticationTrustResolverImpl(); //从当前request中取出安全上下文,如果session为空,则会返回一个新的安全上下文 public SecurityContext loadContext(HttpRequestResponseHolder requestResponseHolder) { HttpServletRequest request = requestResponseHolder.getRequest(); HttpServletResponse response = requestResponseHolder.getResponse(); HttpSession httpSession = request.getSession(false); SecurityContext context = readSecurityContextFromSession(httpSession); if (context == null) { context = generateNewContext(); } ... return context; } ... public boolean containsContext(HttpServletRequest request) { HttpSession session = request.getSession(false); if (session == null) { return false; } return session.getAttribute(springSecurityContextKey) != null; } private SecurityContext readSecurityContextFromSession(HttpSession httpSession) { if (httpSession == null) { return null; } ... // Session存在的情况下,尝试获取其中的SecurityContext Object contextFromSession = httpSession.getAttribute(springSecurityContextKey); if (contextFromSession == null) { return null; } ... return (SecurityContext) contextFromSession; } //初次请求时创建一个新的SecurityContext实例 protected SecurityContext generateNewContext() { return SecurityContextHolder.createEmptyContext(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
SecurityContextPersistenceFilter和HttpSessionSecurityContextRepository配合使用,构成了Spring Security整个调用链路的入口,为什么将它放在最开始的地方也是显而易见的,后续的过滤器中大概率会依赖Session信息和安全上下文信息。
-
-
【问】介绍一下UsernamePasswordAuthenticationFilter?(用于输入用户名和密码进行登录的表单验证),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客
Note:
-
表单认证是最常用的一个认证方式,一个最直观的业务场景便是允许用户在表单中输入用户名和密码进行登录,而这背后的
UsernamePasswordAuthenticationFilter,在整个Spring Security的认证体系中则扮演着至关重要的角色。 -
源码分析:
org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter#attemptAuthentication public class UsernamePasswordAuthenticationFilter extends AbstractAuthenticationProcessingFilter { ... public Authentication attemptAuthentication(HttpServletRequest request, HttpServletResponse response) throws AuthenticationException { //获取表单中的用户名和密码 String username = obtainUsername(request); String password = obtainPassword(request); ... username = username.trim(); //组装成username+password形式的token UsernamePasswordAuthenticationToken authRequest = new UsernamePasswordAuthenticationToken( username, password); // Allow subclasses to set the "details" property setDetails(request, authRequest); //交给内部的AuthenticationManager去认证,并返回认证信息 return this.getAuthenticationManager().authenticate(authRequest); } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
UsernamePasswordAuthenticationFilter本身的代码只包含了上述这么一个重要方法,非常简略,而在其父类AbstractAuthenticationProcessingFilter中包含了大量的细节,值得我们分析:public abstract class AbstractAuthenticationProcessingFilter extends GenericFilterBean implements ApplicationEventPublisherAware, MessageSourceAware { //包含了一个身份认证器 private AuthenticationManager authenticationManager; //用于实现remeberMe private RememberMeServices rememberMeServices = new NullRememberMeServices(); private RequestMatcher requiresAuthenticationRequestMatcher; //这两个Handler很关键,分别代表了认证成功和失败相应的处理器 private AuthenticationSuccessHandler successHandler = new SavedRequestAwareAuthenticationSuccessHandler(); private AuthenticationFailureHandler failureHandler = new SimpleUrlAuthenticationFailureHandler(); public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException { HttpServletRequest request = (HttpServletRequest) req; HttpServletResponse response = (HttpServletResponse) res; ... Authentication authResult; try { //此处实际上就是调用UsernamePasswordAuthenticationFilter的attemptAuthentication方法 authResult = attemptAuthentication(request, response); if (authResult == null) { //子类未完成认证,立刻返回 return; } sessionStrategy.onAuthentication(authResult, request, response); } //在认证过程中可以直接抛出异常,在过滤器中,就像此处一样,进行捕获 catch (InternalAuthenticationServiceException failed) { //内部服务异常 unsuccessfulAuthentication(request, response, failed); return; } catch (AuthenticationException failed) { //认证失败 unsuccessfulAuthentication(request, response, failed); return; } //认证成功 if (continueChainBeforeSuccessfulAuthentication) { chain.doFilter(request, response); } //注意,认证成功后过滤器把authResult结果也传递给了成功处理器 successfulAuthentication(request, response, chain, authResult); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
整个流程理解起来也并不难,主要就是内部调用了
authenticationManager完成认证,根据认证结果执行successfulAuthentication或者unsuccessfulAuthentication,无论成功失败,一般的实现都是转发或者重定向等处理,不再细究AuthenticationSuccessHandler和AuthenticationFailureHandler,有兴趣的朋友,可以去看看两者的实现类。
-
-
【问】介绍一下AnonymousAuthenticationFilter?(
Spirng Security为了整体逻辑的统一性,即使是未通过认证的用户,也给予了一个匿名身份;常位于常用的身份认证过滤器之后),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客Note:
-
匿名认证过滤器,可能有人会想:匿名了还有身份?我自己对于
Anonymous匿名身份的理解是Spirng Security为了整体逻辑的统一性,即使是未通过认证的用户,也给予了一个匿名身份。而AnonymousAuthenticationFilter该过滤器的位置也是非常的科学的,它位于常用的身份认证过滤器(如UsernamePasswordAuthenticationFilter、BasicAuthenticationFilter、RememberMeAuthenticationFilter)之后,意味着只有在上述身份过滤器执行完毕后,SecurityContext依旧没有用户信息,AnonymousAuthenticationFilter该过滤器才会有意义—-基于用户一个匿名身份。 -
源码分析:
org.springframework.security.web.authentication.AnonymousAuthenticationFilter public class AnonymousAuthenticationFilter extends GenericFilterBean implements InitializingBean { private AuthenticationDetailsSource<HttpServletRequest, ?> authenticationDetailsSource = new WebAuthenticationDetailsSource(); private String key; private Object principal; private List<GrantedAuthority> authorities; //自动创建一个"anonymousUser"的匿名用户,其具有ANONYMOUS角色 public AnonymousAuthenticationFilter(String key) { this(key, "anonymousUser", AuthorityUtils.createAuthorityList("ROLE_ANONYMOUS")); } /** * * @param key key用来识别该过滤器创建的身份 * @param principal principal代表匿名用户的身份 * @param authorities authorities代表匿名用户的权限集合 */ public AnonymousAuthenticationFilter(String key, Object principal, List<GrantedAuthority> authorities) { Assert.hasLength(key, "key cannot be null or empty"); Assert.notNull(principal, "Anonymous authentication principal must be set"); Assert.notNull(authorities, "Anonymous authorities must be set"); this.key = key; this.principal = principal; this.authorities = authorities; } ... public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException { //过滤器链都执行到匿名认证过滤器这儿了还没有身份信息,塞一个匿名身份进去 if (SecurityContextHolder.getContext().getAuthentication() == null) { SecurityContextHolder.getContext().setAuthentication( createAuthentication((HttpServletRequest) req)); } chain.doFilter(req, res); } protected Authentication createAuthentication(HttpServletRequest request) { //创建一个AnonymousAuthenticationToken AnonymousAuthenticationToken auth = new AnonymousAuthenticationToken(key, principal, authorities); auth.setDetails(authenticationDetailsSource.buildDetails(request)); return auth; } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
其实对比
AnonymousAuthenticationFilter和UsernamePasswordAuthenticationFilter就可以发现一些门道了,UsernamePasswordAuthenticationToken对应AnonymousAuthenticationToken,他们都是Authentication的实现类,而Authentication则是被SecurityContextHolder(SecurityContext)持有的,一切都被串联在了一起。
-
-
【问】介绍一下ExceptionTranslationFilter?(异常转换过滤器,一般其只处理两大类异常:
AccessDeniedException访问异常和AuthenticationException认证异常;ExceptionTranslationFilter内部的AuthenticationEntryPoint至关重要,用于处理过滤器检测到的异常),参考spring security面试题_springsecurity面试题_「已注销」的博客-CSDN博客Note:
-
ExceptionTranslationFilter异常转换过滤器位于整个springSecurityFilterChain的后方,用来转换整个链路中出现的异常,将其转化,顾名思义,转化以意味本身并不处理。一般其只处理两大类异常:AccessDeniedException访问异常和AuthenticationException认证异常。这个过滤器非常重要,因为它将
Java中的异常和HTTP的响应连接在了一起,这样在处理异常时,我们不用考虑密码错误该跳到什么页面,账号锁定该如何,只需要关注自己的业务逻辑,抛出相应的异常便可。-
如果该过滤器检测到
AuthenticationException,则将会交给内部的AuthenticationEntryPoint去处理; -
如果检测到
AccessDeniedException,需要先判断当前用户是不是匿名用户,如果是匿名访问,则和前面一样运行AuthenticationEntryPoint,否则会委托给AccessDeniedHandler去处理,而AccessDeniedHandler的默认实现,是AccessDeniedHandlerImpl。所以ExceptionTranslationFilter内部的AuthenticationEntryPoint是至关重要的,顾名思义:认证的入口点。
-
-
源码分析:
-
剩下的便是要搞懂
AuthenticationEntryPoint和AccessDeniedHandler就可以了。选择了几个常用的登录端点,以其中第一个为例来介绍,看名字就能猜到是认证失败之后,让用户跳转到登录页面。还记得我们一开始怎么配置表单登录页面的吗?@Configuration @EnableWebSecurity public class WebSecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/", "/home").permitAll() .anyRequest().authenticated() .and() .formLogin()//FormLoginConfigurer .loginPage("/login") .permitAll() .and() .logout() .permitAll(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
我们顺着
formLogin返回的FormLoginConfigurer往下找,看看能发现什么,最终在FormLoginConfigurer的父类AbstractAuthenticationFilterConfigurer中有了不小的收获:public abstract class AbstractAuthenticationFilterConfigurer extends …{ … //formLogin不出所料配置了AuthenticationEntryPoint private LoginUrlAuthenticationEntryPoint authenticationEntryPoint; //认证失败的处理器 private AuthenticationFailureHandler failureHandler; … }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
具体如何配置的就不看了,我们得出了结论,
formLogin()配置了之后最起码做了两件事:-
其一,为
UsernamePasswordAuthenticationFilter设置了相关的配置 -
其二配置了
AuthenticationEntryPoint。
-
登录端点还有
Http401 AuthenticationEntryPoint,Http403 ForbiddenEntryPoint这些都是很简单的实现,有时候我们访问受限页面,又没有配置登录,就看到了一个空荡荡的默认错误页面,上面显示着401,403,就是这两个入口起了作用。 -
还剩下一个
AccessDeniedHandler访问决策器未被讲解,简单提一下:AccessDeniedHandlerImpl这个默认实现类会根据errorPage和状态码来判断,最终决定跳转的页面org.springframework.security.web.access.AccessDeniedHandlerImpl#handle public void handle(HttpServletRequest request, HttpServletResponse response, AccessDeniedException accessDeniedException) throws IOException, ServletException { if (!response.isCommitted()) { if (errorPage != null) { // Put exception into request scope (perhaps of use to a view) request.setAttribute(WebAttributes.ACCESS_DENIED_403, accessDeniedException); // Set the 403 status code. response.setStatus(HttpServletResponse.SC_FORBIDDEN); // forward to error page. RequestDispatcher dispatcher = request.getRequestDispatcher(errorPage); dispatcher.forward(request, response); } else { response.sendError(HttpServletResponse.SC_FORBIDDEN, accessDeniedException.getMessage()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
-
-
【问】什么是Oauth2?(Oauth2是一种授权协议,用于进行第三方程序的授权,进而访问第三方程序中受保护的资源;Oauth2相关概念包括:client,HTTP服务提供商,资源所有者,用户代理,认证服务器,资源服务器),参考【老徐】从零开始的 Spring Security OAuth2(一) | 芋道源码 —— 纯源码解析博客,理解OAuth 2.0 - 阮一峰的网络日志
Note:
-
OAuth 2.0(Open Authorization 2.0)是一种用于授权的开放标准协议,用于授权第三方应用程序代表用户访问受保护的资源。它提供了一种安全的方式来授权和认证用户,并使用户能够控制第三方应用程序对其资源的访问权限。 -
假设现在有个问题:有一个"云冲印"的网站,可以将用户储存在
Google的照片,冲印出来。用户为了使用该服务,必须让"云冲印"读取自己储存在Google上的照片。问题是只有得到用户的授权,Google才会同意"云冲印"读取这些照片。那么,"云冲印"怎样获得用户的授权呢?传统方法是:用户将自己的
Google用户名和密码,告诉"云冲印",后者就可以读取用户的照片了。这样的做法有以下几个严重的缺点。-
1)"云冲印"为了后续的服务,会保存用户的密码,这样很不安全。
-
2)
Google不得不部署密码登录,而我们知道,单纯的密码登录并不安全。 -
3)"云冲印"拥有了获取用户储存在Google所有资料的权力,用户没法限制"云冲印"获得授权的范围和有效期。
-
4)用户只有修改密码,才能收回赋予"云冲印"的权力。但是这样做,会使得其他所有获得用户授权的第三方应用程序全部失效。
-
5)只要有一个第三方应用程序被破解,就会导致用户密码泄漏,以及所有被密码保护的数据泄漏。
-
-
OAuth2.0中几个专用名词:-
1) Third-party application:第三方应用程序,本文中又称"客户端"(client),即上一节例子中的"云冲印"。
-
2)HTTP service:HTTP服务提供商,本文中简称"服务提供商",即上一节例子中的Google。
-
3)Resource Owner:资源所有者,本文中又称"用户"(user)。
-
4)User Agent:用户代理,本文中就是指浏览器。
-
5)Authorization server:认证服务器,即服务提供商专门用来处理认证的服务器。
-
6)Resource server:资源服务器,即服务提供商存放用户生成的资源的服务器。它与认证服务器,可以是同一台服务器,也可以是不同的服务器。
-
-
OAuth的思路是:OAuth在"客户端"与"服务提供商"之间,设置了一个授权层(authorization layer)。“客户端"不能直接登录"服务提供商”,只能登录授权层,以此将用户与客户端区分开来。"客户端"登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。"客户端"登录授权层以后,"服务提供商"根据令牌的权限范围和有效期,向"客户端"开放用户储存的资料。具体流程如下:
-
A)用户打开客户端以后,客户端要求用户给予授权。
-
B)用户同意给予客户端授权。
-
C)客户端使用上一步获得的授权,向认证服务器申请令牌。
-
D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
-
E)客户端使用令牌,向资源服务器申请获取资源。
-
F)资源服务器确认令牌无误,同意向客户端开放资源。
-
-
-
【问】SpringSecurity如何实现Oauth2?SpringSecurity使用Oauth2保护应用的三个步骤(配置资源服务器,配置认证服务器,配置
spring security),参考【老徐】从零开始的 Spring Security OAuth2(一) | 芋道源码 —— 纯源码解析博客Note:
-
Spring Security是一个功能强大且灵活的身份验证和授权框架,它提供了对OAuth 2.0的支持。通过Spring Security,可以轻松地实现OAuth 2.0的认证和授权流程。(下面是ChatGPT的答案)Spring Security 实现
OAuth 2.0的主要组件包括:-
Authorization Server(授权服务器):授权服务器负责颁发访问令牌(Access Token)给第三方应用程序,验证用户身份并授权其访问受保护的资源。在 Spring Security 中,可以使用
@EnableAuthorizationServer注解配置授权服务器。 -
Resource Server(资源服务器):资源服务器存储受保护的资源,需要对访问资源的请求进行验证和授权。在
Spring Security中,可以使用@EnableResourceServer注解配置资源服务器。 -
Client(客户端):客户端是需要访问受保护资源的第三方应用程序。客户端需要进行身份验证,并向授权服务器请求访问令牌。Spring Security 提供了 OAuth2Client 支持,可以轻松配置和管理客户端。
-
User(用户):用户是授权服务器中的注册用户,其身份需要验证,并根据其权限授予访问令牌。
通过使用
Spring Security的OAuth 2.0功能,可以方便地配置和管理授权服务器、资源服务器和客户端,实现基于OAuth 2.0的身份验证和授权。可以使用注解和配置文件来定义安全规则、访问令牌的生成和验证方式,并根据需要进行自定义扩展。 -
-
使用
oauth2保护你的应用,可以分为简易的分为三个步骤(下面部分是ChatGPT答案)-
配置资源服务器(
Resource Server):资源管理器负责管理受保护的资源,验证请求的访问权限。在Spring Security中,可以通过@EnableResourceServer注解开启资源服务器,并进行相应的配置。- 定义资源服务器配置类,使用
@EnableResourceServer注解标注类,并继承ResourceServerConfigurerAdapter类。 - 通过
configure(HttpSecurity http)方法配置资源服务器的安全规则,包括对受保护资源的访问权限、请求路径的拦截等。
- 定义资源服务器配置类,使用
-
配置认证服务器(
Authentication Manager):认证管理器负责对用户进行身份认证。在 Spring Security 中,可以通过@EnableWebSecurity注解开启 Web 安全,并进行相应的配置。- 定义安全配置类,使用
@EnableWebSecurity注解标注类,并继承WebSecurityConfigurerAdapter类。 - 通过
configure(AuthenticationManagerBuilder auth)方法配置认证管理器,包括定义用户的身份验证方式、用户信息的存储位置等。
- 定义安全配置类,使用
-
配置
spring security
前两点是
oauth2的主体内容,spring security oauth2是建立在spring security基础之上的,所以有一些体系是公用的。 -
-
下面是一个示例代码,演示如何配置资源管理器和认证管理器:
@Configuration @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { // 配置用户的身份验证方式,这里使用内存存储方式 auth.inMemoryAuthentication() .withUser("user") .password("{noop}password") .roles("USER"); } @Override protected void configure(HttpSecurity http) throws Exception { // 配置资源服务器的安全规则 http.authorizeRequests() .antMatchers("/api/**").authenticated() .anyRequest().permitAll(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在上述示例中,我们使用了内存存储方式配置了一个用户,用户名为 “user”,密码为 “password”,具有 “USER” 角色。资源服务器配置中,我们定义了 “/api/**” 路径下的请求需要进行身份验证。
通过以上配置,我们实现了对资源的管理和用户身份认证,确保只有经过认证的用户可以访问受保护的资源。当访问受保护资源时,系统将自动进行身份验证,如果身份验证成功,则允许访问资源;如果身份验证失败,则返回未授权的错误。
-
-
【问】oauth2定义了哪4种授权方式?(授权码模式,简化模式),参考理解OAuth 2.0 - 阮一峰的网络日志
Note:
-
客户端必须得到用户的授权(
authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。- 授权码模式(authorization code)
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
-
授权码模式:
授权码模式(
authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动(QQ、微信、钉钉三方登录)。
它的步骤如下:
-
A)用户访问客户端,后者将前者导向认证服务器。
-
B)用户选择是否给予客户端授权。
-
C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。
-
D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
-
E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
-
-
简化模式:
简化模式(
implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证(APP-ID,APP-Secrect)。
它的步骤如下:
-
A)客户端将用户导向认证服务器。
-
B)用户决定是否给于客户端授权。
-
C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。
-
D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。
-
E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。
-
F)浏览器执行上一步获得的脚本,提取出令牌。
-
G)浏览器将令牌发给客户端。
-
-
密码模式:
密码模式(
Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。在这种模式中,用户必须把自己的密码给客户端(“云冲印”),但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。

它的步骤如下:
-
A)用户向客户端提供用户名和密码。
-
B)客户端将用户名和密码发给认证服务器,向后者请求令牌。
-
C)认证服务器确认无误后,向客户端提供访问令牌。
-
-
客户端模式:
客户端模式(
Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。
它的步骤如下:
-
A)客户端向认证服务器进行身份认证,并要求一个访问令牌。
-
B)认证服务器确认无误后,向客户端提供访问令牌。
-
-
18、WebSocket
参考WebSocket知识点整理,轮询/长轮询(Comet)/长连接(SSE)/WebSocket(全双工),简单的搭建Websocket(java+vue)
-
【问】什么是websocket?原理是什么?(HTML5中用到的技术,是一种
tcp全双工通信协议,支持实时通讯),参考WebSocket 百度百科,HTML5_百度百科Note:
-
在
websocket出现之前,web交互一般是基于http协议的短连接或者长连接; -
HTML5是 HyperText Markup Language 5 的缩写,HTML5技术结合了HTML4.01的相关标准并革新,符合现代网络发展要求,在 2008 年正式发布。HTML5 由不同的技术构成,其在互联网中得到了非常广泛的应用,提供更多增强网络应用的标准。HTML5在 2012 年已形成了稳定的版本。2014年10月28日,W3C发布了HTML5的最终版。 -
HTML5于2011年定义了WebSocket协议(WebSocket通信协议于2011年被IETF 6455,并由RFC7936补充规范。WebSocketAPI也被W3C定为标准),其本质上是一个基于tcp的协议,通过HTTP/1.1协议的101状态码进行握手,能够实现浏览器与服务器全双工通信,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。 -
websocket是一种全新的持久化协议,不属于http无状态协议,协议名为"ws";
-
-
【问】socket和http的区别?(
socket不是协议,而是一个API,是对TCP/IP协议的封装)Note:
-
socket并不是一个协议:-
Http协议是简单的对象访问协议,对应于应用层。Http协议是基于TCP连接的,主要解决如何包装数据;TCP协议对应于传输层,主要解决数据如何在网络中传输; -
Socket是对TCP/IP协议的封装,Socket本身并不是协议,而是一个调用接口(API),通过Socket实现TCP/IP协议。
-
-
socket通常情况下是长连接:-
Http连接:http连接就是所谓的短连接,及客户端向服务器发送一次请求,服务器端响应后连接即会断掉。 -
socket连接:socket连接是所谓的长连接,理论上客户端和服务端一旦建立连接,则不会主动断掉;但是由于各种环境因素可能会是连接断开,比如说:服务器端或客户端主机down了,网络故障,或者两者之间长时间没有数据传输,网络防火墙可能会断开该链接已释放网络资源。所以当一个
socket连接中没有数据的传输,那么为了维持连续的连接需要发送心跳消息,具体心跳消息格式是开发者自己定义的。
-
-
-
【问】websocket与http的关系?(3次握手的时候是基于
HTTP协议,传输时基于TCP信道,不需要HTTP协议)Note:
-
相同点:
-
都是基于
tcp的,都是可靠性传输协议; -
都是应用层协议;
-
-
不同点:
-
WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息;而
HTTP是单向的; -
WebSocket是需要浏览器和服务器握手进行建立连接的而
http是浏览器发起向服务器的连接,服务器预先并不知道这个连接
-
-
联系:
WebSocket在建立握手时,数据是通过HTTP传输的。但是建立之后,在真正传输时候是不需要HTTP协议的; -
总结(总体过程):
-
首先,客户端发起
http请求,经过3次握手后,建立起TCP连接;http请求里存放WebSocket支持的版本号等信息,如:Upgrade、Connection、WebSocket-Version等; -
然后,服务器收到客户端的握手请求后,同样采用
HTTP协议回馈数据; -
最后,客户端收到连接成功的消息后,开始借助于TCP传输信道进行全双工通信。
-
-
-
【问】websocket和webrtc技术的联系与区别?(webrtc在视频流传输时用到了websocket协议),参考WebRTC_百度百科
Note:
-
相同点:
-
都是基于
socket编程实现的,是用于前后端实时通信的的技术;都是基于浏览器的协议; -
原理都是在于数据流传输至服务器,然后服务器进行分发,这两个连接都是长链接;
-
这两个协议在使用时对服务器压力比较大,因为只有在对方关闭浏览器或者服务器主动关闭的时候才会关闭
websocket或webrtc;
-
-
不同点:
-
websocket保证双方可以实时的互相发送数据,具体发啥自己定 -
webrtc则主要从浏览器获取摄像头(网页考试,刷题系统 一般基于这个技术) 一般webrtc技术(音视频采集,编解码,网络传输和渲染,音视频同步等),是一个关于摄像头的协议,在网络传输上要配合websocket技术才能使用,毕竟光获取了个摄像头也没啥用啊,得往服务器发。
-
-
-
【问】http存在什么问题?即时通讯包括哪些连接维持的方法?(http存在问题:无状态协议,解析请求头header耗时(比如包含身份认证信息),单向消息发送),参考轮询、长轮询(comet)、长连接(SSE)、WebSocket
Note:
-
http存在的问题:-
http是一种无状态协议,每当一次会话完成后,服务端都不知道下一次的客户端是谁,需要每次知道对方是谁,才进行相应的响应,因此本身对于实时通讯就是一种极大的障碍; -
http协议采用一次请求,一次响应,每次请求和响应就携带有大量的header头,对于实时通讯来说,解析请求头也是需要一定的时间,因此,效率也更低下 -
最重要的是,
http协议需要客户端主动发,服务端被动发,也就是一次请求,一次响应,不能实现主动发送。
-
-
实现即时通讯常见的有四种方式,分别是:轮询、长轮询(comet)、长连接(SSE)、WebSocket。
-
轮询(客户端在时间间隔内发起请求,客户端接收到数据后关闭连接):
很多网站为了实现推送技术,所用的技术都是轮询。轮询是在特定的的时间间隔(如每1秒),由客户端浏览器对服务器发出
HTTP请求,然后由服务器返回最新的数据给客户端的浏览器。-
优点:后端编码比较简单
-
缺点:这种传统的模式带来很明显的缺点,即客户端的浏览器需要不断的向服务器发出请求,然而HTTP请求可能包含较长的头部,其中真正有效的数据可能只是很小的一部分,显然这样会浪费很多的带宽等资源。

-
-
长轮询(客户端发起一个请求,服务器端维持连接,客户端接收到数据后关闭连接):
客户端向发起一个到服务端的请求,然后服务端一直保持连接打开,直到数据发送到客户端为止。
-
优点:避免了服务端在没有信息更新时的频繁请求,节省流量
-
缺点:服务器一直保持连接会消耗资源,需要同时维护多个线程,而服务器所能承载的 TCP 连接是有上限的,所以这种轮询很容易导致连接上限。

-
-
长连接(通过通道来维持连接,客户端可以断开连接,但服务器端不可以)
客户端和服务端建立连接后不进行断开,之后客户端再次访问这个服务端上的内容时,继续使用这一条连接通道
-
优点:消息即时到达,不发无用请求
-
缺点:与长轮询一样,服务器一直保持连接是会消耗资源的,如果有大量的长连接的话,对于服务器的消耗是巨大的,而且服务器承受能力是有上限的,不可能维持无限个长连接。

-
-
WebSocket(支持双向实时通信,客户端和服务器端一方断开连接,则连接中断)
客户端向服务器发送一个携带特殊信息的请求头(
Upgrade:WebSocket)建立连接,建立连接后双方即可实现自由的实时双向通信。优点:
- 较少的控制开销。在连接创建后,服务器和客户端之间交换数据时,用于协议控制的数据包头部相对较小。
- 更强的实时性。由于协议是全双工的,所以服务器可以随时主动给客户端下发数据。相对于
HTTP请求需要等待客户端发起请求服务端才能响应,延迟明显更少;即使是和Comet等类似的长轮询比较,其也能在短时间内更多次地传递数据。 - 保持连接状态。与
HTTP不同的是,Websocket需要先创建连接,这就使得其成为一种有状态的协议,之后通信时可以省略部分状态信息。而HTTP请求可能需要在每个请求都携带状态信息 (如身份认证等)。
缺点:相对来说,开发成本和难度更高

-
轮询、长轮询、长连接和
WebSocket的总结比较:轮询(Polling) 长轮询(Long-Polling) WebSocket 长连接(SSE) 通信协议 http http tcp http 触发方式 client(客户端) client(客户端) client、server(客户端、服务端) client、server(客户端、服务端) 优点 兼容性好容错性强,实现简单 比短轮询节约资源 全双工通讯协议,性能开销小、安全性高,可扩展性强 实现简便,开发成本低 缺点 安全性差,占较多的内存资源与请求数 安全性差,占较多的内存资源与请求数 传输数据需要进行二次解析,增加开发成本及难度 只适用高级浏览器 延迟 非实时,延迟取决于请求间隔 非实时,延迟取决于请求间隔 实时 非实时,默认3秒延迟,延迟可自定义
-
-
-
相关阅读:
JS封装防抖(代码持续优化)
C++ Qt开发:QTcpSocket网络通信组件
3C认证所需要的条件和流程
MIT 6.858 计算机系统安全讲义 2014 秋季(二)
ChatGLM 项目集合
jquery操作DOM对象
【前端面试题】
React框架的基本运行原理与组件定义方式
5G与Wi-Fi 接入的网络融合发展分析
PostgreSQL ON CONFLICT冲突时进行额外操作
- 原文地址:https://blog.csdn.net/qq_33934427/article/details/127747693
