-
【智能优化算法-灰狼算法】基于翻筋斗觅食策略的灰狼优化算法求解单目标优化问题附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab仿真内容点击👇
⛄ 内容介绍
灰狼优化算法(grey wolf optimization,GWO)存在收敛的不合理性等缺陷,目前对 GWO 的收敛性改进方式较少,除此之外,在 GWO 迭代至后期,所有灰狼个体都逼近 α 狼、β 狼、δ 狼,导致算法陷入局部最优。为针对以上问题,提出了一种增强型的灰狼优化算法(disturbance and somersault foraging-grey wolf optimization,DSF-GWO),该算法首先引入了一种扰动因子,平衡了算法的开采和勘探能力;其次又引入翻筋斗觅食策略,在后期使其不陷入局部最优的同时也使得前期的群体多样性略有提升。
⛄ 部分代码
%___________________________________________________________________%
% Grey Wold Optimizer (GWO) source codes version 1.0 %
% %
% Developed in MATLAB R2011b(7.13) %
% %
% Author and programmer: Seyedali Mirjalili %
% %
% e-Mail: ali.mirjalili@gmail.com %
% seyedali.mirjalili@griffithuni.edu.au %
% %
% Homepage: http://www.alimirjalili.com %
% %
% Main paper: S. Mirjalili, S. M. Mirjalili, A. Lewis %
% Grey Wolf Optimizer, Advances in Engineering %
% Software , in press, %
% DOI: 10.1016/j.advengsoft.2013.12.007 %
% %
%___________________________________________________________________%
% Grey Wolf Optimizer
function [Alpha_score,Alpha_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iter,lb,ub,dim,fobj)
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
% Main loop
while l
for i=1:size(Positions,1)
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
% Calculate objective function for each search agent
fitness=fobj(Positions(i,:));
% Update Alpha, Beta, and Delta
if fitness
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness>Beta_score && fitness
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);
end
end
% a decreases linearly fron 2 to 0
a=sin(((l*pi)/Max_iter)+pi/2)+1;
% Update the Position of search agents including omegas
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % Equation (3.3)
C1=2*r2; % Equation (3.4)
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % Equation (3.3)
C3=2*r2; % Equation (3.4)
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
end
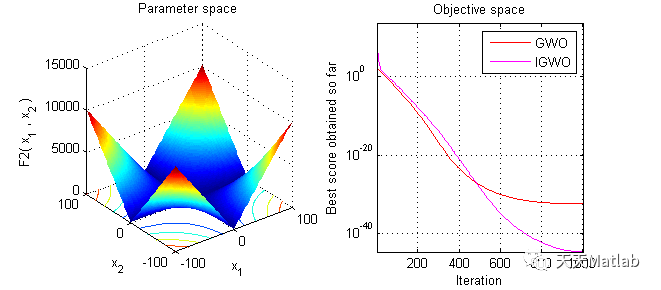
⛄ 运行结果


⛄ 参考文献
[1]王正通, 程凤芹, 尤文,等. 基于翻筋斗觅食策略的灰狼优化算法[J]. 计算机应用研究, 2021, 38(5):4.
❤️ 关注我领取海量matlab电子书和数学建模资料
❤️部分理论引用网络文献,若有侵权联系博主删除
-
相关阅读:
Win32 键盘鼠标模拟输入
cesium实现水面水流及淹没效果绘制的封装
踩大坑ssh免密登录详细讲解
软考-高级-系统架构设计师教程(清华第2版)【第1章-绪论-思维导图】
Motorola IPMC761 使用边缘TPU加速神经网络
854. 相似度为 K 的字符串(每日一难phase2--day20)
Leetcode《图解数据结构》刷题日志【第二周】(2022/10/24-2022/10/30)
wordpress添加评论过滤器
QT:绘图
QT+OSG/osgEarth编译之九十一:osgdb_pnm+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_pnm)
- 原文地址:https://blog.csdn.net/qq_59747472/article/details/127237254