-
李宏毅2021《机器学习/深度学习》——学习笔记(4)
分类问题
Loss function
Loss function 的定义与回归问题不同,这里 Loss function 的定义是分类错误的次数。

Function
概率模型
贝叶斯公式与分类问题的关系贝叶斯公式


如上图所示,对于某个 x ,想知道它属于哪个类别,把类别当成盒子。如果知道从类别1中抽到 x 的概率、从类别2中抽到 x 的概率、从类别1抽的概率、从类别2抽的概率,再根据贝叶斯公式就可以计算 x 属于类别1的概率了。
所以只要从训练数据估算出上图框出的四个概率就好了。
P ( C 1 ) P(C_1) P(C1) 和 P ( C 2 ) P(C_2) P(C2) 的计算方式如图所示。

计算出四个概率后可以算出 x 属于类别1的概率。

Three Steps

逻辑回归
逻辑回归和线性回归的区别

机器学习任务攻略
如果模型效果不好,首先检查训练数据集上 loss 的大小。

过拟合
解决过拟合的一个办法是增加训练数据。

另一个方法是给模型增加限制。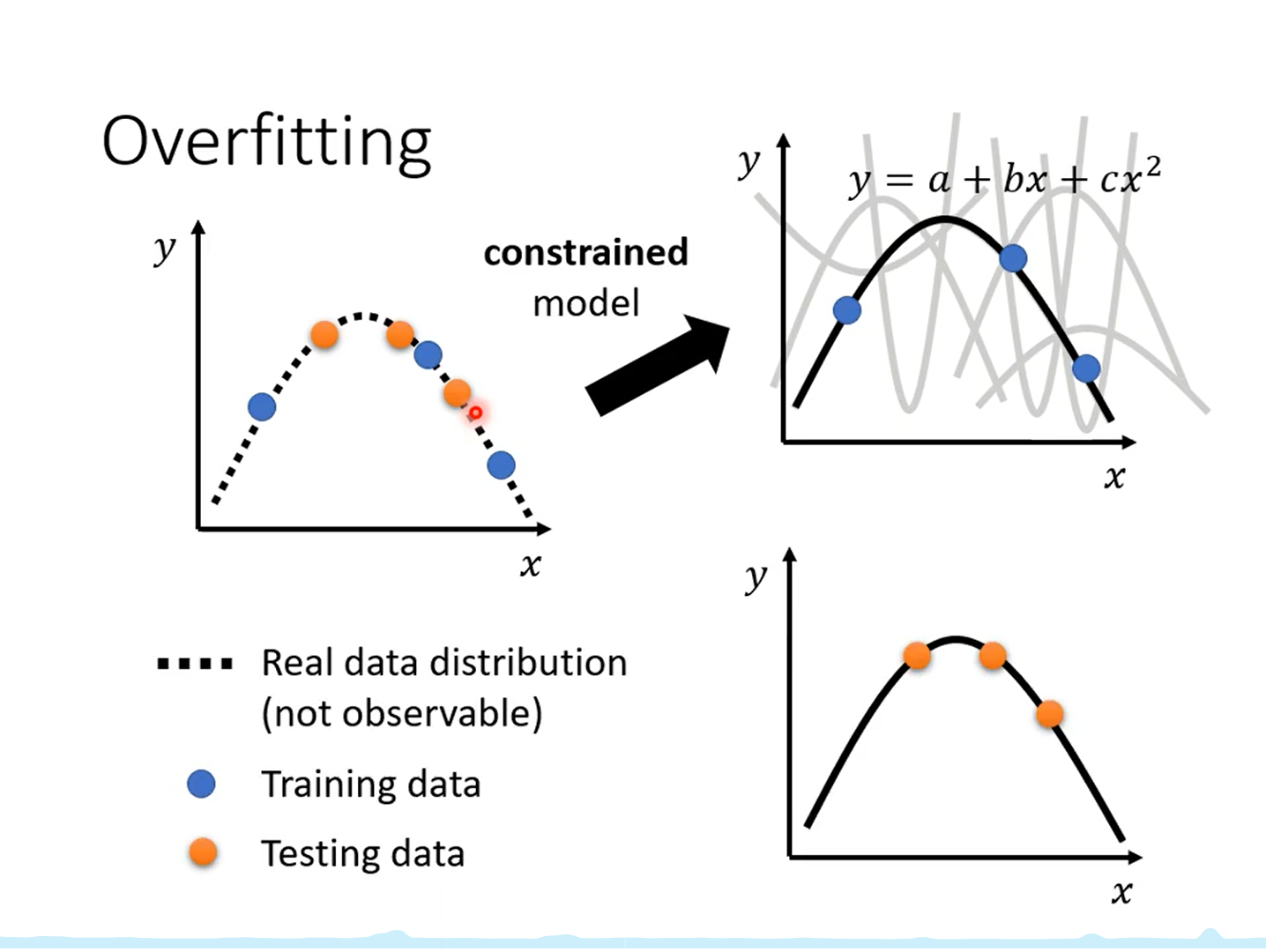
增加限制的方法有:
- 减少参数或共享参数
- 减少特征
- 早一点结束
- 正则化
- dropout

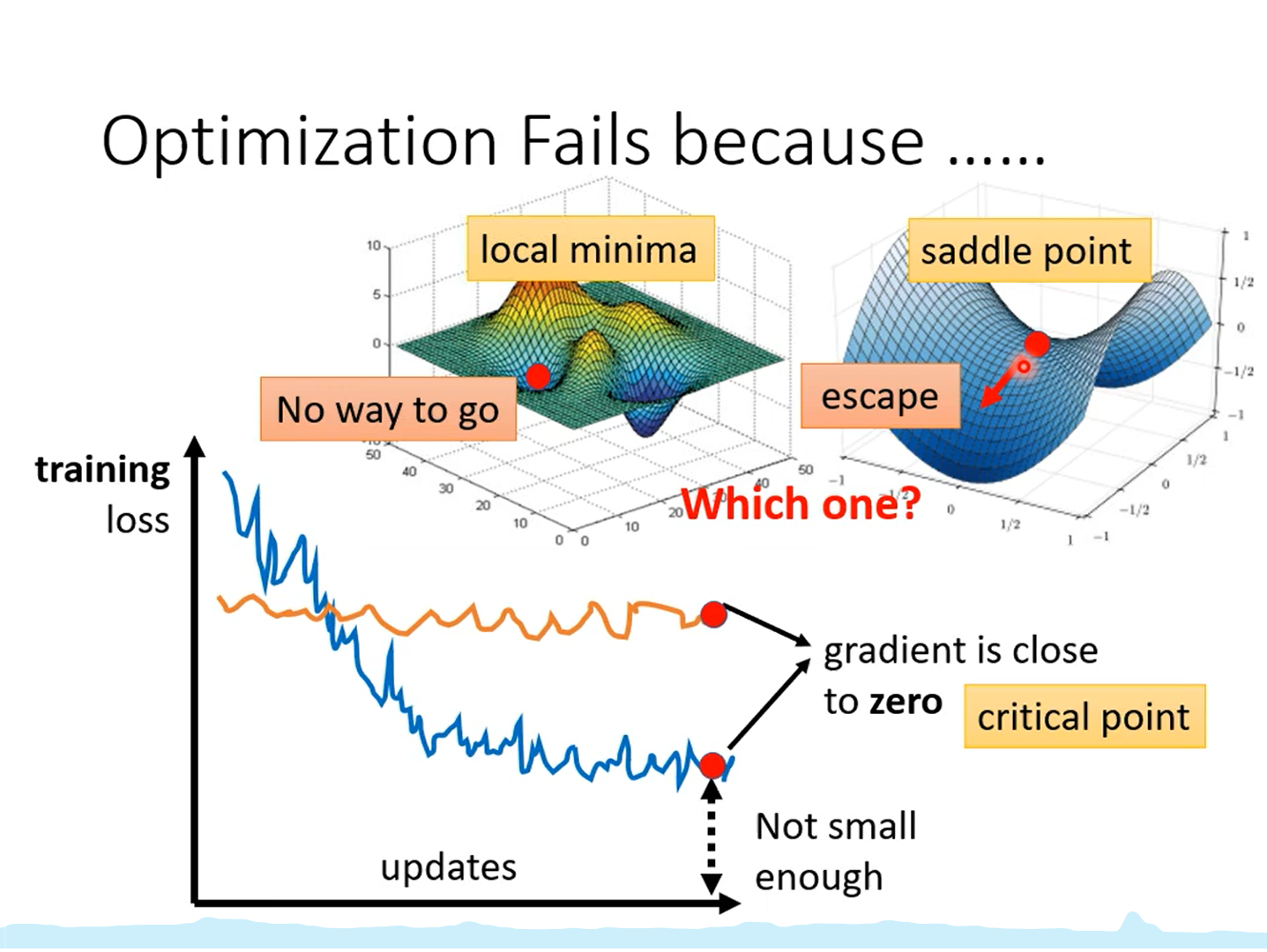
神经网络训练不起来(一)局部最小值与鞍点
train不成功的原因可能是遇到了局部最小值和鞍点。如果是局部最小值那暂时没办法,如果是鞍点,就还有路可以走。
神经网络训练不起来(二)批次(batch)与动量(momentum)
小批次与大批次的区别

梯度下降加上动量:每次更新参数的方向不只是梯度下降的方向,而是上一次更新参数的方向和梯度下降方向的合成(考虑了惯性)。

考虑惯性,或许可以越过局部最小值。

神经网络训练不起来(三)自动调整学习率(Learning Rate)
loss很小了,不一定到局部最小值或者鞍点了,还要看梯度的模。如果梯度的模反复跳跃,说明有可能在山谷的两个谷壁间来回震荡。
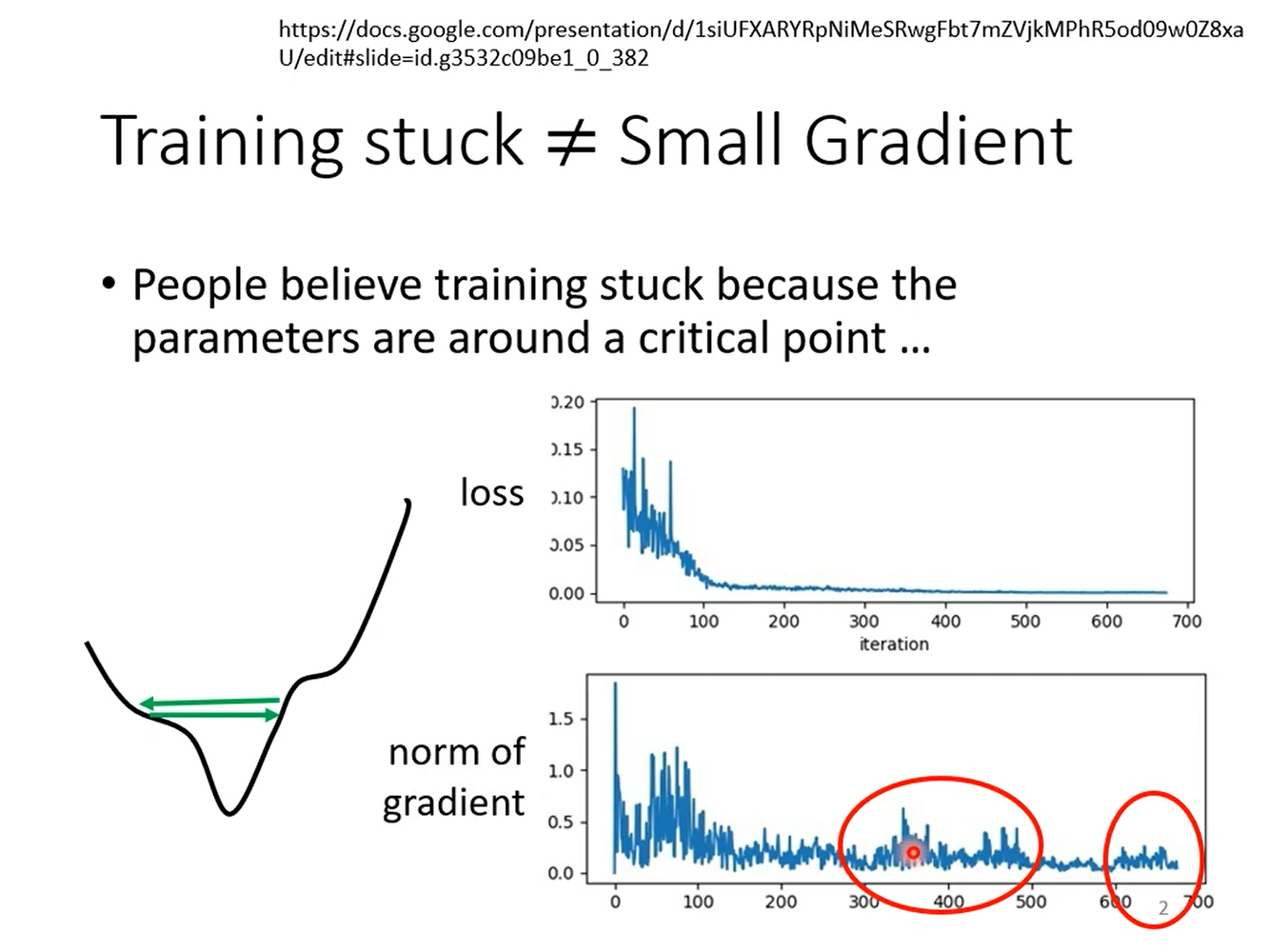
学习速率太大,会在山谷两端来回震荡。学习速率太小,在比较平滑的地方前进很慢,无法到达终点。

因此需要自适应调节学习速率。我们希望在比较平坦的地方,学习速率大一些;在比较陡峭的地方,学习速率小一些。

神经网络训练不起来(四)损失函数(Loss)也可能有影响
直接把分类问题当作回归问题来做不行。这就是说class1和class2比较有关系,而class1和class3比较没有关系,实际上可能并没有关系。

可以使用 one-hot vector来解决

分类问题一般用交叉熵做损失函数。

参考资料
-
相关阅读:
论文阅读 Exploring Temporal Information for Dynamic Network Embedding
求区间内共有多少种数字(莫队、树状数组、线段树、主席树)
如何获取高质量的微信私域客户?
NewStarCTF2023week2-R!!C!!E!!
使用PyTorch处理多维特征输入的完美指南
云原生之容器化:Docker的使用
如何设计一个好的游戏剧情(Part 1:主题的设定)
一键搞定!黑群晖虚拟机+内网穿透实现校园公网访问攻略!
SQL注入漏洞 其他注入
5G之ULCL
- 原文地址:https://blog.csdn.net/m0_46283220/article/details/127519482