-
突破大O(N的平方)的排序
堆排序(用的少)
预备知识
建立二叉堆的基本方法,这个阶段花费O(N)时间。然后执行N次deleteMin操作。按照顺序,最小的元素先离开堆。通过将这些元素记录到第.二.个数组然后再将数组拷贝回来,我们得到N个元素的排序。由于每个deleteMin花费O(logN)时间,因此总的运行时间是O(NlogM)。
简介
该算法的主要问题在于,它使用一个附加的数组。因此,存储需求增加一倍。在某些实例中这可能是个问题。注意,将第.二个数组复制回第一个数组的附加时间消耗只是O(N),这不可能显著影响运行时间。这个问题是空间的问题。
避免使用第二个数组的聪明的方法是利用这样的事实:在每次deleteMin之后,堆缩小了1。因此,堆中最后的单元可以用来存放刚刚删去的元素。例如,设我们有一个堆,它含有6个元素。第一次deleteMin产生a1j。现在该堆只有5个元素,因此可以把a放在位置6上。下一次deleteMin产生a2,由于该堆现在只有4个元素,因此把az放在位置5上。
在我们的实现方法中将使用-一个(max)堆,但由于速度的原因避免了具体的ADT。照通常的习惯,每一件事都是在数组中完成的。第一步以线性时间建立堆。然后通过将堆中的最后元素与第一个元素交换,缩减堆的大小并进行下滤,来执行N-1次deleteMax操作。当算法终止时,数组则以所排的顺序包含这些元素。
图像实例
例如,考虑输入序列31,41,59,26,53,58,97。
第一步 建立的max堆

第二步:deleteMax的堆

代码示例
- int leftchild(int i)
- {
- return 2*i +1;// 我们以下标 1开始
- }
- /*
- i 从那一层开始排序
- n 数组大小
- */
- template<typename Comparable>
- void precDown(vector
&ves,int i,int n) - {
- int child;
- Comparable tmp;
- for(tmp=a[i];leftchild(i){/*求出左孩子和右孩子的max*/if(child!=n-1&&1[child]child++;/*比较大小 father 和 child*/if(tmpa[i]=a[child];elsebreak;}a[i]=tmp;}template<typename Comparable>void heapsort(vecor
&a) {for(int i=a.size()/2;i>0;i--)precDown(a,i,a.size());for(int j=a.size()-1;j>0;j--){swap(a[0],a[j]);precDown(a,0,j);}}归并排序(基于递归和双指针 java)
描述
这个算法中基本的操作是合并两个已排序的表。因为这两个表是已排序的,所以若将输出放到第3个表中则该算法可以通过对输入数据--趟排序来完成。基本的合并算法是取两个输入数组A和B、一个输出数组C以及3个计数器(Actr、Bctr和Cctr),它们初始置于对应数组的开始端。A[Actr]和B[Bctr]中的较小者被复制到C中的下一个位置,相关的计数器向前推进一步。当两个输入表有-一个用完的时候,则将另一个表中的剩余部分拷贝到C中。合并例程如何工作的例子见下。

如果数组A含有1、13、24、26,数组B含有2、15、27、38,那么该算法如下进行:首先,比较在1和2之间进行,1被添加到c中,然后13和2进行比较。

2被添加到C中,然后13和15进行比较。

13被添加到C中,接下来比较24和15,这样一直到26和27进行比较。

26被添加到C中,数组A已经用完。

将数组B的其余部分复制到C中。

归并排序算法很容易描述。如果N= 1,那么只有一个元素需要排序,答案是显而易见的。
否则,递归地将前半部分数据和后半部分数据各自归并排序,得到排序后的两部分数据,然后再使用上面描述的合并算法将这两部分合并到-起。例如,欲将8元素数组24,13,26,1,2,27,38,15排序,我们递归地将前4个数据和后4个数据分别排序,得到1,13,24,26,2,15,27,38。然后,将这两部分合并,得到最后的表1,2,13,15,24,26,27,38。该算法是经典的分治( divide-and-conquer)策略,它将问题分(divide)成一些小的问题然后递归求解,而治( conquering)的阶段则是将分的阶段解得的各答案修补在一起。分治是递归非常有力的用法,我们将会多次
- template<typename Comparable>
- void mergeSort(vector
&a) - {
- vector
tmp(a.size()) - mergeSort(a,tmp,0,a.size()-1);
- }
- template<typename Comparable>
- void mergeSort(vector
a,vector tmp,int left,int rigth) - {
- if(left{int center=(left+rigth)/2;mergeSort(a,tmp,left,center);mergeSort(a,tmp,center+1,rigth);merger(a,tmp,left,center+1,right);}}
快速排序(c++库最常见)(小数组 用插入排序 大数组用它)
简述
数组S排序的基本算法由下列简单的四步组成:
(1)如果S中元素个数是0或1,则返回。
(2)取S中任一元素v,称之为枢纽元(pivot)。
(3)将S-{v}(S中其余元素)划分成两个不相交的集合: S1 ={x∈S-{v} |x≤v}和S={x∈S-{v}x≥v}。
(4)返回{quicksort(S),后跟v,继而quicksort(S2)}。
图像示例
下图解释了如何快速排序-个数集。这里的枢纽元(随机地)选为65,集合中其余元素分成两个更小的集合。递归地将较小的数的集合排序得到0,13,26,31,43,57(递归法则3),将较大的数的集合类似排序,此时很容易得到整个集合的排序。
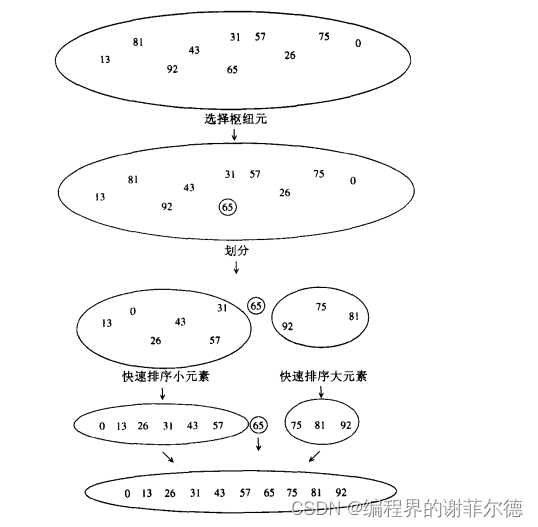
选取枢纽元
一组N个数的中值是第「N /2]个最大的数。枢纽元的最好的选择是数组的中值。可是,这很难算出,并且会明显减慢快速排序的速度。这样的中值的估计可以通过随机选取三个元素并用它们的中值作为枢纽元而得到。事实上,随机性并没有多大的帮助,因此一般的做法是使用左端、右端和中心位置上的三个元素的中值作为枢纽元。例如,输入为8,1,4,9,6,3,5,2,7,0,它的左边元素是8,右边元素是0,中心位置上的元素是6。于是枢纽元则是v=6。显然使用三数中值分割法消除了预排序输入的不好情形(在这种情形下,这些分割都是一样的),并且减少了快速排序大约14%的比较次数。
分割策略(双指针)
我们将会看到,这么做很容易出错或产生低效率,但使用一种已知方法却是安全的。该方法的第一步是通过将枢纽元与最后的元素交换使得枢纽元离开要被分割的数据段。i从第一个元素开始而j从倒数第二个元素开始。如果最初的输入与前面-一样,那么下面的图表示当前的状态。

我们暂时假设所有的元素互异,后面将着重考虑在出现重复元素时应该怎么办。作为一种限制性的情形,如果所有的元素都相同,那么我们的算法必须做相应的工作。然而奇怪的是,此时做错事却特别地容易。
在分割阶段要做的就是把所有小元素移到数组的左边而把所有大元素移到数组的右边。当然,“小”和“大”是相对于枢纽元而言的。
当i在j的左边时,我们将i右移,移过那些小于枢纽元的元素,并将j左移,移过那些大于枢纽元的元素。当i和j停止时,i指向一个大元素而j指向一个小元素。如果i在j的左边,那么将这两个元素互换,其效果是把一个大元素推向右边而把一个小元素推向左边。在上面的例子中,i不移动.而j滑过一个行置,

然后交换由i和i指向的元素,重复该过程直到i和i彼此

此时,i和j已经交错,故不再交换。分割的最后--步是将枢纽元与i所指向的元素交换。交错为止。

在最后-一-步,当枢纽元与i所指向的元素交换时,我们知道在位置p
我们必须考虑的--个重要的细节是如何处理那些等于枢纽元的元素
直接给结论:i j停止
代码示例
- template<typename Comparable>
- void quicksort(vector
&a) - {
- quicksort(a,0,a.size()-1);
- }
- template<template Comparable>
- const Comparable&medianthree(vector
&a,int left,int rigth) - {
- int center=(left+right)/2;
- if(a[center]{swap(a[left],a[center]);}if(a[rigth]swap(a[left],a[right]);if(a[right]{swap(a[center],a[right]);}//放置枢纽元swap(a[certer],a[right-1]);return a[right-1];}template<typename Comparable>void quicksort(vector
&a,int left,int rigth) ;{if(left+10<=rigth){Comparable pivot=medianthree(a,left,rigth);int i=left,j=right-1;for(;;){while(a[++i]while(pivotif(i{swap(a[i],a[j]);}elsebreak;}swap(a[i],a[rigth-1]);quicksort(a,left,i-1);quicksort(a,i+1,right);}}elseinsertSort(a,left,right);}- 相关阅读:
【汇编】其他转移指令、call指令和ret指令
常见的锁策略你了解多少?
Bus:消息总线
Electronica上海 Samtec 验证演示 | FireFly™Micro Flyover System™
JVM 方法区
2022-9-20-C++11新特性
常见的抓包检测及抓包方案
NumPy数组与矩阵(二)
算法竞赛入门【码蹄集进阶塔335题】(MT2311-2315)
高项 11 风险管理
- 原文地址:https://blog.csdn.net/qq_62309585/article/details/127658810
