-
1、自然语言和单词的分布式表示(上)
目录
一、什么是自然语言处理
自然语言处理(NLP):是一种能够让计算机理解人类语言的技术。换言之,NLP的目标就是让计算机理解人说的话,进而完成对我们有帮助的事情。
单词是语义的最小单位,为了让计算机理解自然语言,必须让它理解单词含义。单词含义的表示方法:
-
基于同义词词典的方法
-
基于计数的方法
-
基于推理的方法(word2vec)
二、基于同义词词典的方法
同义词词典:在同义词词典中,具有相同含义的单词(同义词)或含义类似的单词(近义词)被归类到同一个组会中。最著名的同义词词典:WordNet
用图结构定义了各个单词之间的关系。例如:

同义词词典存在的问题:
-
难以顺应时代变化
-
人力成本高
-
无法表示单词之间的微妙差异
使用同义词词典,即人工定义单词含义的方法存在很多问题。基于计数的方法和利用神经网络的基于推理的方法将可以从海量的文本数据中自动提取单词含义。
三、基于计数的方法
1、语料库
语料库就是大量的文本数据。基于计数的方法的目标是语料库中,自动且高效地提取本质。
2、针对语料库的预处理
将文本分割成单词,并将分割后的单词列表转化为单词ID列表。例如,我们这里使用由单个句子构成的文本作为语料库:

(1)对语料库进行分词

(2)创建单词ID与单词的对应表

(3)生成单词ID列表

3、将单词表示为向量
分布式表示:将单词表示为固定长度的向量。
分布式假设:某个单词的含义1由它周围的单词形成。也就是说单词本身没有含义,单词的含义由它所在的上下文(语境)组成。上下文是指某个单词周围的单词。上下文大小称为窗口大小。例如:

该例子窗口大小为2,故在关注“goodbye”时,其上下文就是左边两个单词和右边两个单词。
如何基于分布式假设使用向量表示单词?
使用基于计数的方法:对周围单词的数量进行计数,也就是在关注某个单词的情况下,对它的周围出现了多少次什么单词进行计数,然后汇总。继续以上述一个语句的语料库为例:

1)在这个例子中,我们将窗口设为1,从单词ID为0的you开始,查看'you'的上下文:

2)用表格统计在‘you’的上下文中出现的单词的频数:

说明:表格中的这一串数字就可以用来表示单词‘you’。
3)按照上述方法,依次统计语料库中其他字符:

这个表格的各行对应相应单词的向量。这样的矩阵被称为共现矩阵。
4、单词间的相似程度
单词经过上面的步骤已经转化为了向量,故单词之间的相似度,就转化为了向量间的相似度。测量向量之间的相似度的方法有:向量内积和余弦相似度...
相似单词的排序:当某个单词作为查询词时,将与这个查询词相似的单词按降序显示出来。具体做法:

例如:

create_co_martrix()用于生成共现矩阵,most_similar()用于计算相似度。输出结果如下:

四、基于计数的方法的改进
1、点互信息
在上一部分中,我们用共现矩阵的行向量作为单词的向量表示,但是这样的做法存在一个问题:将每个单词的重要性同等考虑,忽略了对一些高频词的处理。例如,‘the’、'a'这样的词。
解决方法:使用点互信息(PMI)这一指标。
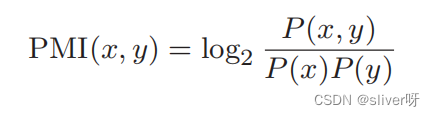
通过共现矩阵,得到单词之间的点互信息:

说明:将共现矩阵表示为C,将单词x和单词y的共现次数表示为c(x,y),将单词x和单词y的出现次数分别表示为C(x)、C(y).
为避免得到负无穷,对PMI进行改进,用正的点互信息(PPMI):

同样以上述只有一个句子的语料库生成的共现矩阵为例:

经转换,生成的PPMI矩阵:

得到PPMI矩阵之后,似乎得到了一个比较好的向量表示,其仍然存在一个问题:矩阵的维数太大,且稀疏。
2、矩阵降维
降维指的是:在尽可能保留重要信息的基础上,将矩阵的维数减少。如下是降维的示意图:

降维的主要方法是奇异值分解(SVD),SVD示意图:

进行SVD之后,得到的效果:

参考资料:《深度学习进阶:自然语言处理》
-
-
相关阅读:
22个代码的坏味道
Dubbo 原理和机制详解 (非常全面)
Flutter:安装依赖报错doesn‘t support null safety
rust从0开始写项目-03-多样话错误处理
爱上开源之DockerUI-xterm.js实现Web控制台
Android 开发常见问题
Raft 共识算法
unity图片`fillAmount`填充方法
php __destruct反序列化原理
请解释一下 CSS3 的 Flexbox(弹性盒布局模型), 以及适用场景?
- 原文地址:https://blog.csdn.net/qq_55202378/article/details/127651242