-
【自监督论文阅读笔记】Geography-Aware Self-Supervised Learning
对比学习方法在计算机视觉任务上显著 缩小了有监督学习和无监督学习之间的差距。在本文中,探讨了它们 在地理定位数据集上的应用,例如遥感,其中未标记的数据通常很丰富,但标记的数据很少。本文首先表明,由于它们的不同特点,在标准基准上的对比学习 和 监督学习之间存在着不小的差距。为了缩小差距,本文提出了 利用 遥感数据 时空结构 的新训练方法。
本文利用 随着时间 空间对齐的图像 在对比学习中构建 时间正对,和利用 地理位置 来设计前置任务。实验表明,本文提出的方法 缩小了对比学习和监督学习在图像分类、目标检测 和 遥感语义分割方面的差距。此外,本文证明了所提出的方法 也可以应用于 地理标记的 ImageNet 图像,从而提高各种任务的下游性能。
Introduction:
受自监督学习方法 [2, 12] 成功的启发,本文探索了它们在大规模遥感数据集(卫星图像)和地理标记自然图像数据集中的应用。最近的研究表明,自监督学习方法在传统计算机视觉数据集上的图像分类、目标检测 和 语义分割[20,9,12,2,1] 上表现得相当好,甚至比它们的监督学习方法更好。然而,尽管收集和标记遥感图像的成本特别高,因为注释 通常需要 领域专业知识[33,15,4],但它们在遥感图像中的应用 在很大程度上尚未得到探索。
在这个方向上,本文首先 通过实验 评估 现有的自监督对比学习方法 MoCo-v2 [12] 在遥感数据集上的性能,发现与使用标签的监督学习的性能差距。例如,在 Functional Map of the World (fMoW) 图像分类基准 [4] 中,本文观察到 监督和自监督方法之间的 top 1 准确度存在 8% 的差距。
为了弥合这一差距,本文提出了 地理感知对比学习 来 利用遥感数据的时空结构。与典型的计算机视觉图像相比,遥感数据 通常是 地理定位的,并且 随着时间的推移 可能会提供同一位置的多个图像。对比方法 鼓励 可能在语义上相似的图像表示(正对)的接近性。与传统的 计算机视觉图像的对比学习 不同,其中同一图像的不同视图(增强)用作正对,本文建议 使用 随着时间的推移空间对齐的图像 的时间正对。
利用这些信息可以 使 表示 对随时间的细微变化(例如,由于季节性)保持不变。这反过来可以 为 关注空间变化的任务(例如 目标检测 或 语义分割)带来更多的判别特征(但不一定适用于涉及时间变化的任务,例如变化检测)。
此外,本文设计了一种新颖的无监督学习方法,该方法 利用了地理位置信息,即关于图像拍摄地点的知识。更具体地说,本文考虑了 预测图像 来自世界何处的 前置任务,类似于 [10, 11]。这可以通过 鼓励 反映地理信息的表示 来 补充 自监督学习方法 通常使用的信息论目标,这在遥感任务中通常很有用。
最后,本文将两种提出的方法 整合到 一个 地理感知对比学习目标中。
由 高空间分辨率卫星图像 组成的 functional Map of the World [4] 数据集上的实验表明,本文显著改进了 MoCo-v2 基线。特别是,在图像分类上测试学习表示时,本文将其分类准确率提高了 8%,目标检测上的 AP 提高了 2%,语义分割上的 mIoU 提高了 1%,土地覆盖分类的 top-1 准确率提高了 3%。有趣的是,本文的地理感知学习 甚至可以 在时间数据分类上 优于监督学习方法约 2%。
为了进一步证明本文的地理感知学习方法的有效性,使用类似于 [6] 的 FLICKR API 提取 ImageNet 图像的地理位置信息,它为我们提供了 543,435 个地理标记的 ImageNet 图像的子集。本文将提出的方法扩展到 地理定位的 ImageNet,并表明 地理感知学习 可以将 MoCo-v2 在图像分类上的性能提高 2%,表明本文的方法 在任何地理标记数据集上的潜在应用。图 1 详细显示了本文的贡献。

Related Work:
自监督方法使用未标记的数据来学习可迁移到下游任务(例如图像分类、目标检测、语义分割)的表示。两种常见的自监督方法是 前置任务 和 对比学习。
前置任务:
当数据标签不可用时,基于前置任务的学习 [21、35、28、42、37、27] 可用于学习特征表示。 [8]旋转图像,然后训练模型来预测旋转角度。 [41] 训练网络对灰度图像进行着色。 [25] 将图像表示为网格,对网格进行排列,然后预测排列索引。本文 使用 地理定位分类 作为前置任务,以此 训练一个深度网络 来预测图像可能来自世界何处的粗略地理位置。
对比学习:
最近的自监督对比学习方法,如 MoCo [12]、MoCo-v2 [2]、SimCLR [1]、PIRL [21] 和 FixMatch [30] 已展示出卓越的性能,并已成为各种下游任务的先行者。这些方法背后的直觉是 通过 在隐空间中 将来自同一实例的正图像对拉得更近,同时将来自不同实例的负图像对推得更远来学习表示。另一方面,这些方法 在对比损失的类型、正负对的生成 和 采样方法上有所不同。
尽管在自监督学习领域发展迅速,但 对比学习方法尚未在大规模遥感数据集上进行探索。本文提供了一种有原则且有效的方法,用于 改进 使用 MoCo-v2 [12] 用于 遥感数据 以及地理定位的常规数据集的表示学习。
遥感图像中的无监督学习:
与传统的计算机视觉领域不同,遥感领域的无监督学习尚未得到全面研究。大多数研究使用 特定于一个小的地理区域 [3, 16, 29, 14, 18],一些类别 [24] 或 高度特定的模态,即高光谱图像 [22, 40] 的 小规模数据集。这些研究大多集中在 UCM-21 数据集 [39] 上,该数据集包含来自 21 个类别的不到 1,000 张图像。最近的一项研究 [33] 提出了使用 由 卫星图像 和 配对的地理定位维基百科文章 组成的多模态数据集 的大规模弱监督学习。这种方法虽然有效,但需要将每张卫星图像与其对应的文章配对,从而 限制了可以使用的图像数量。
地理感知的 计算机视觉:
地理定位数据 已在先前的工作中进行了广泛的研究。这些研究中的大多数 利用图像的地理位置 作为先验,以提高图像识别的准确性[31,13,23,19,5]。其他研究 [38, 10, 11, 36] 使用 地理标记的训练数据集来学习 如何在测试时 预测以前看不见的图像的 地理位置。在本文的研究中,利用 地理标签信息来 改进 无监督 和 自监督的学习方法。
Problem Definition:
本文考虑一个地理标记的视觉数据集
 ,其中第 i 个数据点 由 在一个共享位置的 一系列图像
,其中第 i 个数据点 由 在一个共享位置的 一系列图像 组成 ,纬度和经度 分别等于
组成 ,纬度和经度 分别等于 和
和 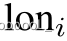 ,随着时间
,随着时间 。当 Ti > 1 时,指的是 数据集 具有时间信息或结构。
。当 Ti > 1 时,指的是 数据集 具有时间信息或结构。虽然 时域信息 在自然图像数据集(例如 ImageNet)中通常不可用,但在遥感中很常见。虽然 时间结构 与 传统视频 相似,但本文 在这项工作中 利用了一些 关键差异。
- 首先,本文考虑 相对较短 的时间序列,其中两个连续“帧”之间的时间差 可能从几个月到几年不等。
- 此外,与传统视频不同,本文考虑 在图像序列中 没有视角变化 的数据集。
鉴于本文的设置,我们希望获得图像
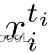 的视觉表示
的视觉表示 ,以便学习的表示 可以迁移到各种下游任务。我们不假设 可以访问任何标签 或 超出、地理标签的人工监督。表示的质量是通过它们在各种下游任务上的表现来衡量的。本文的主要目标是 通过利用 带有 遥感 和 传统计算机视觉图像的 地理标记数据集 的地理坐标 来提高自监督学习的性能。
,以便学习的表示 可以迁移到各种下游任务。我们不假设 可以访问任何标签 或 超出、地理标签的人工监督。表示的质量是通过它们在各种下游任务上的表现来衡量的。本文的主要目标是 通过利用 带有 遥感 和 传统计算机视觉图像的 地理标记数据集 的地理坐标 来提高自监督学习的性能。
Functional Map of the World:
Functional Map of the World (fMoW) 是一个大规模 公开可用的遥感数据集 [4],由 62 个高度精细的类别范畴中的 大约 363,571 个训练图像 和 53,041 个测试图像组成。它提供 随着时间的推移 来自同一位置的图像(时间视图)
 以及 每个图像的地理定位元数据
以及 每个图像的地理定位元数据 。
。
图 4 显示了 fMoW 数据集中 时间视图数量的直方图。可以看到 大部分区域都有多个时间视图,其中 Ti 的范围可以从 1 到 21,平均而言,一个区域的图像之间存在大约 2.5-3 年的差异。

此外,本文在图 2 中展示了 空间对齐图像的示例。如图 5 所示,fMoW 是一个全球数据集,由来自七大洲的图像组成,非常适合学习全球的遥感表示。这种表示 可以用于 不同区域的不同遥感任务的迁移学习。
GeoImageNet:
遵循 [6] ,本文使用 FLICKR API 为 ImageNet [7] 中的图像子集 提取地理坐标。更具体地说,本文使用 FLICKR API 在 ImageNet 中 搜索 地理标记的图像,并能够在 5150 个类别中 找到 543,435 张图像及其相关坐标
。这个数据集 比 ImageNet-1k 更具挑战性,因为它高度不平衡 并且 包含大约 5 倍以上的类。在本文的其余部分,将 ImageNet 的这个地理标记子集称为 GeoImageNet。发布后,本文将为研究社区公开发布 GeoImageNet 数据集。本文在图 3 中展示了来自 GeoImageNet 的一些示例。如图所示,对于某些图像,本文 具有可以 从视觉线索预测的 地理坐标。例如,可以看到在墨西哥拍摄了一张戴着阔边帽的人的照片。同样,在印度拍摄了一张印度大象的照片,那里有大量的印度大象。在它旁边,展示了非洲大象的图片(体型更大)。如果一个模型被训练来预测 图像是在世界的哪个地方拍摄的,它应该能够识别可迁移到其他任务的视觉线索(例如,区分印度大象和非洲大象的视觉线索)。图 5 显示了 GeoImageNet 数据集中的图像分布。
Method:
在本节中,简要回顾了无监督学习的对比损失函数,并详细介绍了本文提出的 用于地理定位数据的 改进 Moco-v2 [2] 的方法,这是一种最近的对比学习框架。
对比学习框架:
对比 [12, 1, 2, 32, 26] 方法 试图 以无监督的方式 学习 从原始像素
 到 语义上有意义的表示
到 语义上有意义的表示  的映射
的映射  。训练目标 鼓励 与先验已知语义相似的图像对(正对)相对应的表示 比 典型的不相关对(负对)更接近彼此。通过 点积 测量相似度,最近的对比学习方法 在对比损失的类型 和 正负对的生成 方面有所不同。本文专注于最先进的对比学习框架 MoCo-v2 [2],MoCo [12] 的改进版本,并研究 改进的方法 来构建 适合遥感应用的 正负对。
。训练目标 鼓励 与先验已知语义相似的图像对(正对)相对应的表示 比 典型的不相关对(负对)更接近彼此。通过 点积 测量相似度,最近的对比学习方法 在对比损失的类型 和 正负对的生成 方面有所不同。本文专注于最先进的对比学习框架 MoCo-v2 [2],MoCo [12] 的改进版本,并研究 改进的方法 来构建 适合遥感应用的 正负对。MoCo-v2 框架中使用的对比损失函数是 InfoNCE [26],对于给定的数据样本定义如下:

其中 z 和
 是通过将的两个增强视图(在图 1 中表示为 v 和 v')通过 分别由 θq 和 θk 参数化的 query 和 key编码器 fq 和 fk 而获得的 query 和 key表示。这里 z 和 形成一个正对。 N 个负样本,
是通过将的两个增强视图(在图 1 中表示为 v 和 v')通过 分别由 θq 和 θk 参数化的 query 和 key编码器 fq 和 fk 而获得的 query 和 key表示。这里 z 和 形成一个正对。 N 个负样本,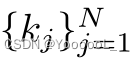 ,来自构建为队列的表示字典。本文建议读者参考 [12] 了解这方面的详细信息。 λ ∈ R+ 是温度超参数。
,来自构建为队列的表示字典。本文建议读者参考 [12] 了解这方面的详细信息。 λ ∈ R+ 是温度超参数。这里的关键思想是 鼓励正(语义相似)对的表示更接近,而 负(语义上不相关)对的表示相距很远,通过 点积 来衡量相似性。正负对的构建 在这个对比学习框架中起着至关重要的作用。 MoCo 和 MoCo-v2 都 使用 来自同一图像的扰动perturbation(也称为“数据增强”)来创建 正样本,并 使用来自不同图像的扰动 来创建负样本。常用的扰动包括 随机颜色抖动、随机水平翻转 和随机灰度转换。
Temporal Positive Pairs:
与许多常见的自然图像数据集不同,遥感数据集 通常具有额外的 时间信息,这意味着对于给定的位置
,存在一系列 随着时间的推移 空间对齐的图像  。与传统视频中 附近的帧 可能会经历内容的大变化(例如,从猫到树)不同,在遥感中,由于固定的视角,内容 通常随着时间的推移 更加稳定。例如,海洋上的一个地方可能会在几个月或几年内保持海洋状态,在这种情况下,在同一位置 跨时间拍摄的 卫星图像 应该具有高度的语义相似性。即使对于随着时间的推移 确实发生重大变化的位置,某些语义相似性仍然可能存在。例如,建筑工地的主要特征 可能会保持不变,即使外观 因季节性而发生变化。
。与传统视频中 附近的帧 可能会经历内容的大变化(例如,从猫到树)不同,在遥感中,由于固定的视角,内容 通常随着时间的推移 更加稳定。例如,海洋上的一个地方可能会在几个月或几年内保持海洋状态,在这种情况下,在同一位置 跨时间拍摄的 卫星图像 应该具有高度的语义相似性。即使对于随着时间的推移 确实发生重大变化的位置,某些语义相似性仍然可能存在。例如,建筑工地的主要特征 可能会保持不变,即使外观 因季节性而发生变化。鉴于这些观察结果,在构建正负对的同时 利用时间信息 进行遥感 是很自然的,因为它可以为我们 提供一个地方的 随着时间的推移 具有额外的语义意义的信息。
本文方法的具体流程:
更具体地说,给定在时间 t1 收集的图像
 ,我们可以随机选择 另一个与 空间对齐的图像
,我们可以随机选择 另一个与 空间对齐的图像  (即
(即  )。然后,我们将 MoCo-v2 中使用的扰动(例如 随机颜色抖动)应用于 空间对齐的图像对 和 ,为我们 提供了一个时间正对(在图 1 中表示为 v 和 v'),可用于训练对比学习框架,方法是将它们分别传递给 query 和 key编码器 fq 和 fk(见图 1)。请注意,当 t1 = t2 时,时间正对与 MoCo-v2 中使用的正对相同。
)。然后,我们将 MoCo-v2 中使用的扰动(例如 随机颜色抖动)应用于 空间对齐的图像对 和 ,为我们 提供了一个时间正对(在图 1 中表示为 v 和 v'),可用于训练对比学习框架,方法是将它们分别传递给 query 和 key编码器 fq 和 fk(见图 1)。请注意,当 t1 = t2 时,时间正对与 MoCo-v2 中使用的正对相同。给定一个数据样本
,本文的 TemporalInfoNCE 目标函数可以表述如下: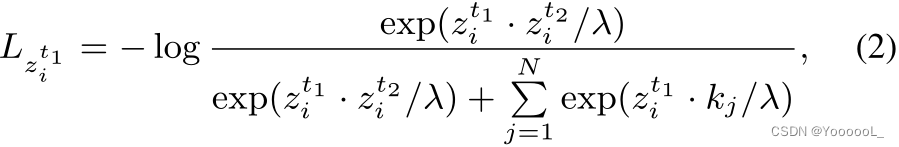
其中
 和
和  是 随机扰动的时间正对 , 的编码表示。与等式 1 类似,N 是负样本的数量,
是 随机扰动的时间正对 , 的编码表示。与等式 1 类似,N 是负样本的数量, 是编码的负对,λ ∈ R+ 是温度超参数。同样,本文建议读者参考 [12] 以了解有关构建这些负对的详细信息。
是编码的负对,λ ∈ R+ 是温度超参数。同样,本文建议读者参考 [12] 以了解有关构建这些负对的详细信息。请注意,与等式 1 相比,本文 使用 随着时间的推移 来自同一区域的两个真实图像 创建正对。本文相信,依靠真实图像 获得正对 可以鼓励网络 学习 比依赖合成图像 更好的 真实数据的表示。
另一方面,本文在等式 2 中的目标 强制 表示 随着时间的变化是不变的。根据目标任务,这种归纳偏差可能是可取的,也可能是不可取的。例如,对于变化检测任务,学习 对时间变化高度敏感的表示 可能更可取。然而,对于图像分类 或 目标检测任务,学习时间不变的特征 不应该降低下游性能。
地理定位分类作为前置任务:
在本节中,将探讨遥感图像的另一个方面,即 地理位置元数据 geolocation metadata,以进一步提高学习表示的质量。在这个方向上,本文为无监督学习 设计了一个前置任务。在本文的前置任务中,使用它们的坐标
对数据集中的图像 进行 聚类。本文使用聚类方法来构造 K 个聚类,并为坐标的区域 分配一个分类地理标签 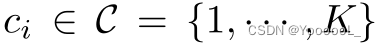 。然后,使用 交叉熵损失函数, 优化 地理位置预测器网络 fc 为:
。然后,使用 交叉熵损失函数, 优化 地理位置预测器网络 fc 为:
其中 p 表示 簇 k 代表 真实簇的概率,
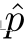 表示 K 个簇的预测概率。在本文的实验中,用由 θc 参数化的 CNN 来表示 fc。有了这个目标函数,本文的目标是 学习可以很好地迁移到不同下游任务的 位置感知表示。
表示 K 个簇的预测概率。在本文的实验中,用由 θc 参数化的 CNN 来表示 fc。有了这个目标函数,本文的目标是 学习可以很好地迁移到不同下游任务的 位置感知表示。
结合地理位置和对比学习损失:
在上一节中,设计了一个前置任务,利用图像的地理位置元数据 来学习 独立设置中的 位置感知表示。在本节中,将地理位置预测 和 对比学习任务结合在一个目标中,以改进 仅对比学习 和仅地理位置学习任务。在这个方向上,本文首先使用 交叉熵损失函数 将地理位置学习任务集成到对比学习框架中,其中 地理位置预测网络 使用来自query编码器的特征
 :
:

在组合框架中(见图 1),fc 由 θc 参数化的 线性层 表示。最后,本文提出 联合学习的目标 是 TemporalInfoNCE 和 地理分类损失 的线性组合,系数 α 和 β 表示对比学习和地理位置学习损失的重要性:

通过结合两个任务,本文学习表示 以 联合 最大化时空正对之间的一致性,最小化负对之间的一致性 并 从正对 预测图像的地理标签。
Experiments:
本文对 fMoW 和 GeoImageNet 数据集执行无监督表示学习。然后,在各种下游任务上评估学习的表示/预训练模型,包括图像识别、目标检测和遥感和传统图像的语义分割基准。
无监督学习的实现细节:
对于对比学习:
类似于 MoCo-v2 [2],本文在所有实验中使用 ResNet-50 参数化 query 和key 编码器 fq 和 fk。在 MoCo-v2 预训练步骤中使用以下超参数:学习率为 1e-3,批量大小为 256,字典队列大小为 65536,0.2 的温度缩放和 SGD 优化器。本文对 fMoW 和 GeoImageNet 数据集使用类似的设置。最后,对于每个下游实验,本文报告 200 个 epoch 后学习到的表示的结果。
对于地理位置分类任务:
本文运行 k-Means 聚类算法 将 fMoW 和 GeoImageNet 聚类到 K = 100 个地理簇中,给定它们的纬度和经度对。本文在图 7 中显示了簇。

如图所示,虽然两个数据集具有相似的集群,但存在一些差异,尤其是在北美和欧洲。在图 8 中,分析了 GeoImageNet 和 fMoW 中的集群。

该图显示,GeoImageNet 上每个类的簇数 往往比 fMoW 偏向更小的数字,而 GeoImageNet 上每个簇的唯一类数具有 更均匀的分布。对于 fMoW,可以得出结论,每个cluster都包含来自大多数类的样本。最后,当将地理位置分类任务 添加到对比学习中时,本文将 α 和 β 调整为 1。
Methods:
将本文的无监督学习方法 与 图像识别任务的监督学习 进行比较。对于目标检测和语义分割,在对目标任务数据集进行微调时,将它们与 使用 (a) 监督学习 和 (b) 随机初始化 获得的预训练权重进行比较。最后,对于消融分析,使用本文方法的不同组合提供结果。当 仅将地理位置分类任务 或 时间正样本 附加到 MoCo-v2 中时,使用 MoCo-v2+Geo 和 MoCo-v2+TP。在将本文的两种方法添加到 MoCo-v2 中时,使用 MoCo-v2+Geo+TP。
Experiments on fMoW:
首先对 fMoW 图像识别任务 进行实验。类似于评估无监督预训练方法的通用协议 [2, 12],本文 冻结特征 并 训练有监督的线性分类器。然而,在实践中,更常见的是在下游任务中 端到端地微调特征。为了完整性 和 更好的比较,本文还报告了 62 类 fMoW 分类的端到端微调结果。报告了这项任务的 top-1 准确率和 F1 分数。
对单个图像进行分类:
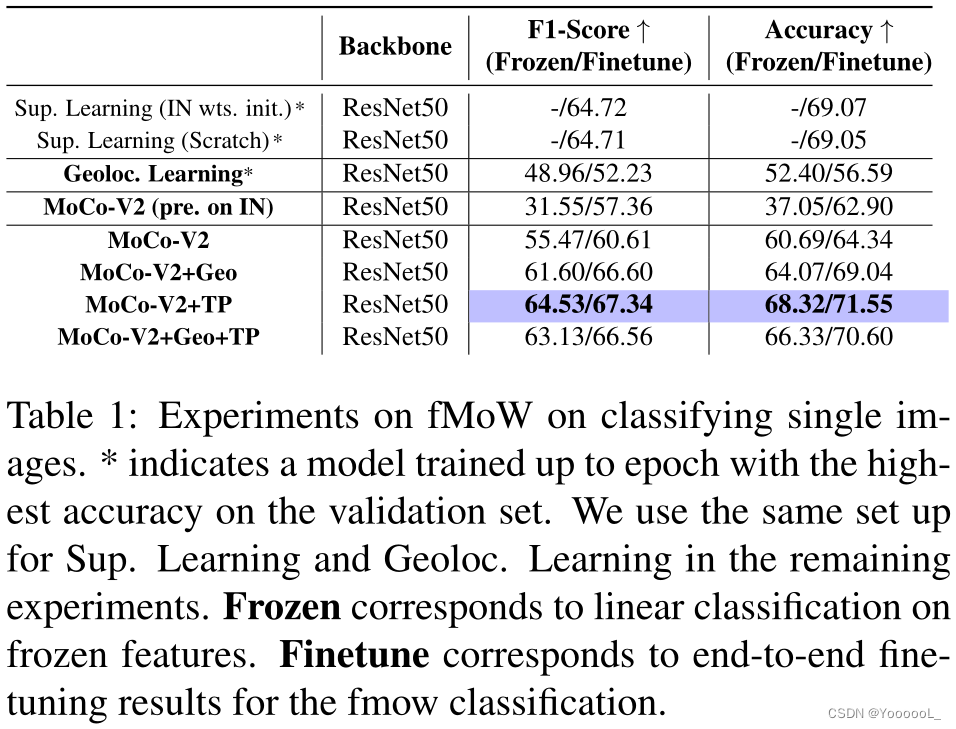
在表 1 中,报告了 fMoW 上单个图像分类的结果。
想强调的是,在这种情况下,本文分别对每个图像进行分类。换句话说,本文不使用 同一区域上的多个图像
 具有相同标签
具有相同标签  的先验信息。为了评估,本文使用了 53,041 张图像。
的先验信息。为了评估,本文使用了 53,041 张图像。在这项任务上的结果(冻结特征的线性分类)表明,MoCo-v2 在大规模数据集上的表现相当不错,准确率为 60.69%,比监督学习方法低 8%。Sup. Learning (IN wts. init.) 和 Sup. Learning (Scratch) 对应于监督学习方法,分别从 imagenet 预训练的权重 和 随机权重 开始。该结果与 MoCo-v2 在 ImageNet 数据集 [2] 上的表现一致。
接下来,通过 将 地理位置分类任务 整合到 MoCo-v2 中,本文将 top1 分类精度提高了 3.38%。本文使用 时间正样本 进一步将结果提高到 68.32%,将 MoCo-v2 基线 和 监督学习之间的差距缩小到不到 1%。然而,当本文对分类任务执行端到端微调时,观察到 本文的方法超过了监督学习方法 2% 以上。为了完整起见,还包括在 Imagenet 数据集(表 1 中的第 4 行)上预训练的 MoCov2 的结果,并发现 Imagenet 和下游数据集之间的分布变化 导致性能欠佳。
对时间数据进行分类:
在下一步中,将更改 在不同时间 跨区域的 多个图像 执行测试的方式。在这种情况下,本文从一个区域的图像中 预测标签,即对每个
 ,并 对该区域的预测进行平均。然后,使用 置信度最高的类别 预测 来获得特定领域的类别预测。在这种情况下,本文评估了 11,231 个独特区域 的性能,这些区域 由不同时间的多张图像表示。
,并 对该区域的预测进行平均。然后,使用 置信度最高的类别 预测 来获得特定领域的类别预测。在这种情况下,本文评估了 11,231 个独特区域 的性能,这些区域 由不同时间的多张图像表示。
在表 2 中的结果表明,进行特定区域的推理 比 特定图像推理 提高了 4-8% 的分类精度。即使结合时间正例,也可以通过从 图像分类 切换到 时间数据分类 将准确率提高 6.1%。总体而言,本文的方法 比基线 Moco-v2 高 4-6%,监督学习高 1-2%。在这里,只报告冻结特征之上的时间分类。
迁移学习实验:
之前,本文在 fMoW 数据集上进行了预训练实验,并通过 监督训练 线性层 以 在 fMoW 上进行图像识别 来 量化表示的质量。在本节中,对不同的低级任务 进行迁移学习实验。
目标检测:
对于目标检测,本文使用 xView 数据集 [15],该数据集 由 使用 与 fMoW 数据集中类似的传感器 捕获的 高分辨率卫星图像组成。 xView 数据集由 846 张超大(~2000×2000 像素)卫星图像组成,带有边界框注释,用于 60 个不同的类别范畴,包括飞机、乘用车、海上船只、直升机等。
实施细节:
本文首先 将大图像集分为 700 个训练图像和 146 个测试图像。然后,通过随机采样小图像的边界框坐标 来处理大图像 以创建 416×416 像素的图像,并对每个大图像重复此过程 100 次。在此过程中,本文确保 来自同一图像的 任意两个边界框之间的重叠小于 25%。然后,本文 使用带有预训练 ResNet-50 主干的 RetinaNet [17],并在 xView 训练集上微调整个网络。为了训练 RetinaNet,本文 使用 1e-5 的学习率和 4 的批量大小和 Adam 优化器。
定性分析:
表 3 显示了 xView 上的 目标检测结果。本文通过在 MoCo-v2 中 添加时间正对 和 地理位置分类前置任务 来获得最佳结果。使用本文的最终模型,可以 比随机初始化的权重高 7% AP,比在 fMoW 上的监督学习高 3.3% AP。
图像分割:
在本节中,对 SpaceNet 数据集 [34] 上的语义分割任务进行下游实验。 SpaceNet 数据集由 5000 张高分辨率卫星图像和建筑物的分割掩码组成。
实施细节:
本文将 SpaceNet 数据集分为 4000 和 1000 张图像的训练集和测试集。使用带有 ResNet-50 主干的 PSAnet [43] 网络来执行语义分割。本文训练 PSAnet 网络,批量大小为 16,学习率为 0.01,100 个epochs,并使用 SGD 优化器。
定性分析:
表 4 显示了 SpaceNet 测试集上不同初始化骨干权重的分割性能。与目标检测类似,本文通过 添加时间正例 和 地理位置分类任务 来获得最佳的 IoU 分数。本文的最终模型 比随机初始化的权重和监督学习分别高出 3.58% 和 2.94% 的 IoU 分数。本文观察到,从图像识别 到 目标检测 和语义分割任务,最好和最差模型之间的差距缩小了。这与在 ImageNet 上预训练并在 Pascal-VOC 目标检测和语义分割实验 [12, 2] 上微调的 MoCo-v2 的性能一致。
土地覆盖分类:
最后,本文使用美国农业部的 国家农业影像计划 (NAIP) 获得的 高分辨率遥感图像 对 66 个土地覆盖类别 的土地覆盖分类 进行迁移学习实验。本文使用来自加利福尼亚中央山谷的 2016 年图像。本文的最终数据集包含 100,000 张训练图像和 50,000 张测试图像。表 5 显示本文的方法比随机初始化权重高 6.34%,监督学习高 3.77%。
GeoImageNet 上的实验:
在 fMoW 之后,采用本文 在 fMoW 上进行无监督学习的方法,以改进 GeoImageNet 上的表示学习。不幸的是,由于 ImageNet 不包含来自同一区域的图像,因此 本文无法 将时间正样本 整合到 MoCo-v2 目标中。然而,在本文的 GeoImageNet 实验中,表明可以 通过引入地理定位分类前置任务来改进 MoCo-v2。
定性分析:

表 6 显示了 GeoImageNet 测试集上的 top-1 和 top-5 分类准确度得分。令人惊讶的是,仅使用 地理位置分类任务,本文就可以达到 22.26% 的 top-1 准确率。使用 MoCo-v2 基线,本文得到 38.51 的准确率,比监督学习方法高出约 3.47%。通过添加地理位置分类,本文可以将 top-1 准确率进一步提高 1.45%。这些结果很有趣,MoCo-v2(200 epochs)在 ImageNet-1k 上的表现比监督学习差 8%,而它在本文 高度不平衡的 具有 5150 个类别的 GeoImageNet 上优于监督学习,大约是 ImageNet-1k 的 5 倍。
Conclusion:
本文 为遥感数据提供了一个自监督的学习框架,其中未标记的数据通常很丰富,但标记的数据很少。通过 利用 随着时间的推移 空间对齐的图像 在对比学习中 构建时间正对 和 在前置任务的设计中 利用地理位置,本文能够缩小 自监督和监督学习 在遥感和其他地理标记图像数据集上的 图像分类、目标检测和语义分割 之间的差距。
-
相关阅读:
c++之泛型算法
js基础笔记学习57-循环嵌套2
Redis新操作
WebServer 解析HTTP 响应报文
用户组的概念(linux篇)
5李欣频文案精华版
java 版本企业招标投标管理系统源码+功能描述+tbms+及时准确+全程电子化
无人车驾驶地面避障(Matlab代码实现)
记录get和post的理解误区
一文-学会es6的class类
- 原文地址:https://blog.csdn.net/YoooooL_/article/details/127568081