-
深度学习入门(十四)数值稳定性和模型初始化
深度学习入门(十四)数值稳定性和模型初始化
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘数值稳定性和模型初始化
课件
1 数值稳定性
1.1 神经网络的梯度
考虑如下有d层的神经网络:

计算损失ℓ关于参数 W t W_t Wt的梯度

数值稳定性的常见两个问题
梯度爆炸、梯度消失:

1.2 例子:MLP
假如如下的MLP(为了简单省略了偏移)

1.2.1 梯度爆炸
使用RELU激活函数


1.2.2 梯度爆炸的问题
值超出值域(infinity)
- 对于16位浮点数尤为严重(数值区间6e-5 - 6e4)
- 对学习率敏感
- 如果学习率太大>大参数值->更大的梯度
- 如果学习率太小->训练无进展
- 我们可能需要在训练过程不断调整学习率
- #### 1.3 梯度消失 使用sigmoid作为激活函数 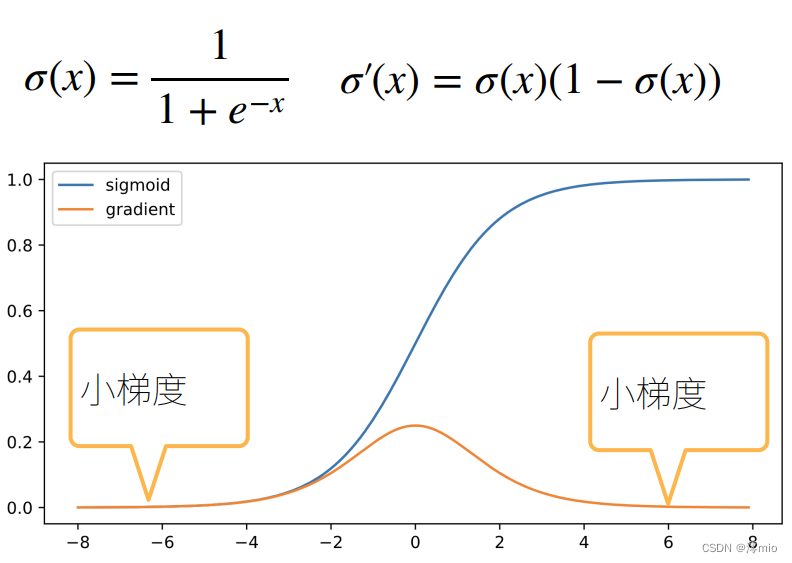 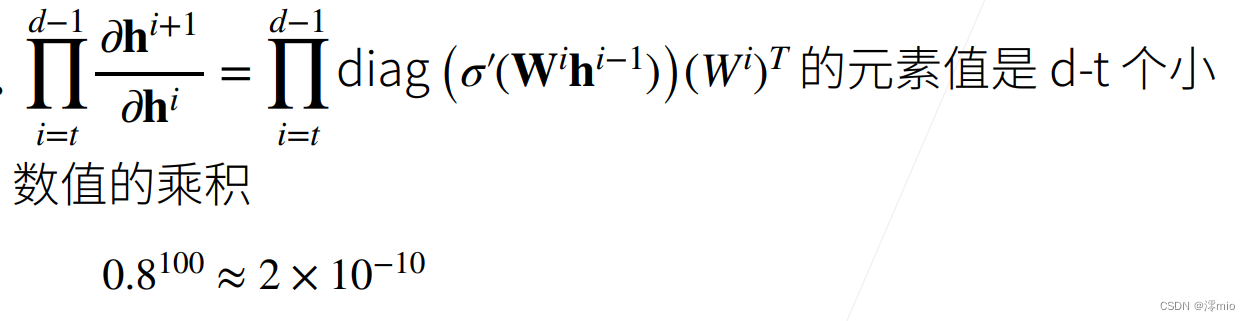 ##### 1.3.1 梯度消失的问题 梯度值变成0
- 对16位浮点数尤为严重
- 训练没有进展
- 不管如何选择学习率
- 对于底部层尤为严重
- 仅仅顶部层训练的较好
- 无法让神经网络更深
2 模型初始化和激活函数
2.1 让训练更加稳定
目标:让梯度值在合理的范围内
- 例如[1e-6,1e3]
- 将乘法变加法
- ResNet,LSTM
- 归一化
- 梯度归一化,梯度裁剪
- 合理的权重初始和激活函数
3 让每层的方差是一个常数
将每层的输出和梯度都看做随机变量
让它们的均值和方差都保持一致
(a和b都是常数)

4 权重初始化
在合理值区间里随机初始参数
训练开始的时候更容易有数值不稳定 - 远离最优解的地方损失函数表面可能很复杂
- 最优解附近表面会比较平
- 使用N(0,0.01)来初始可能对小网络没问题,但不能保证深度神经网络
5 例子:MLP

5.1 正向方差

5.2 反向均值和方差
跟正向情况类似

6 Xavier初始化

7 假设线性的激活函数

7.1 反向

8 检查常用激活函数

教材
到目前为止,我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。 你可能认为初始化方案是理所当然的,忽略了如何做出这些选择的细节。 你甚至可能会觉得,初始化方案的选择并不是特别重要。 相反,初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。 在本节中,我们将更详细地探讨这些主题,并讨论一些有用的启发式方法。 你会发现这些启发式方法在你的整个深度学习生涯中都很有用。
我们来讨论一下深度学习模型的数值稳定性问题以及模型参数的初始化方法。深度模型有关数值稳定性的典型问题是衰减(vanishing)和爆炸(explosion)。1 梯度消失和梯度爆炸
考虑一个具有 L L L层、输入 x \mathbf{x} x和输出 o \mathbf{o} o的深层网络。 每一层 l l l由变换 f l f_l fl定义, 该变换的参数为权重 W ( l ) \mathbf{W}^{(l)} W(l), 其隐藏变量是 h ( l ) \mathbf{h}^{(l)} h(l)(令 h ( 0 ) = x \mathbf{h}^{(0)} = \mathbf{x} h(0)=x)。 我们的网络可以表示为:
h ( l ) = f l ( h ( l − 1 ) ) 因此 o = f L ∘ … ∘ f 1 ( x ) . \mathbf{h}^{(l)} = f_l (\mathbf{h}^{(l-1)}) \text{ 因此 } \mathbf{o} = f_L \circ \ldots \circ f_1(\mathbf{x}). h(l)=fl(h(l−1)) 因此 o=fL∘…∘f1(x).
如果所有隐藏变量和输入都是向量, 我们可以将 o \mathbf{o} o关于任何一组参数 W ( l ) \mathbf{W}^{(l)} W(l)的梯度写为下式:
∂ W ( l ) o = ∂ h ( L − 1 ) h ( L ) ⏟ M ( L ) = d e f ⋅ … ⋅ ∂ h ( l ) h ( l + 1 ) ⏟ M ( l + 1 ) = d e f ∂ W ( l ) h ( l ) ⏟ v ( l ) = d e f . \partial_{\mathbf{W}^{(l)}} \mathbf{o} = \underbrace{\partial_{\mathbf{h}^{(L-1)}} \mathbf{h}^{(L)}}_{ \mathbf{M}^{(L)} \stackrel{\mathrm{def}}{=}} \cdot \ldots \cdot \underbrace{\partial_{\mathbf{h}^{(l)}} \mathbf{h}^{(l+1)}}_{ \mathbf{M}^{(l+1)} \stackrel{\mathrm{def}}{=}} \underbrace{\partial_{\mathbf{W}^{(l)}} \mathbf{h}^{(l)}}_{ \mathbf{v}^{(l)} \stackrel{\mathrm{def}}{=}}. ∂W(l)o=M(L)=def ∂h(L−1)h(L)⋅…⋅M(l+1)=def ∂h(l)h(l+1)v(l)=def ∂W(l)h(l).
换言之,该梯度是 L − l L-l L−l个矩阵 M ( L ) ⋅ … ⋅ M ( l + 1 ) \mathbf{M}^{(L)} \cdot \ldots \cdot \mathbf{M}^{(l+1)} M(L)⋅…⋅M(l+1)与梯度向量 v ( l ) \mathbf{v}^{(l)} v(l)的乘积。 因此,我们容易受到数值下溢问题的影响. 当将太多的概率乘在一起时,这些问题经常会出现。 在处理概率时,一个常见的技巧是切换到对数空间, 即将数值表示的压力从尾数转移到指数。 不幸的是,上面的问题更为严重: 最初,矩阵 M ( l ) \mathbf{M}^{(l)} M(l)可能具有各种各样的特征值。 他们可能很小,也可能很大; 他们的乘积可能非常大,也可能非常小。不稳定梯度带来的风险不止在于数值表示; 不稳定梯度也威胁到我们优化算法的稳定性。 我们可能面临一些问题。 要么是梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛; 要么是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
1.1 梯度消失
曾经sigmoid函数 1 / ( 1 + exp ( − x ) ) 1/(1 + \exp(-x)) 1/(1+exp(−x))很流行, 因为它类似于阈值函数。 由于早期的人工神经网络受到生物神经网络的启发, 神经元要么完全激活要么完全不激活(就像生物神经元)的想法很有吸引力。 然而,它却是导致梯度消失问题的一个常见的原因, 让我们仔细看看sigmoid函数为什么会导致梯度消失。
import torch from d2l import torch as d2l x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True) y = torch.sigmoid(x) y.backward(torch.ones_like(x)) d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()], legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

正如你所看到的,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。1.2 梯度爆炸
相反,梯度爆炸可能同样令人烦恼。 为了更好地说明这一点,我们生成100个高斯随机矩阵,并将它们与某个初始矩阵相乘。 对于我们选择的尺度(方差 σ 2 = 1 \sigma^2=1 σ2=1),矩阵乘积发生爆炸。 当这种情况是由于深度网络的初始化所导致时,我们没有机会让梯度下降优化器收敛。
M = torch.normal(0, 1, size=(4,4)) print('一个矩阵 \n',M) for i in range(100): M = torch.mm(M,torch.normal(0, 1, size=(4, 4))) print('乘以100个矩阵后\n', M)- 1
- 2
- 3
- 4
- 5
- 6
输出:
一个矩阵 tensor([[ 0.4382, -0.7687, 0.2731, -0.2587], [-0.1789, -0.2395, 1.4915, 0.2634], [-0.5272, 0.2403, 2.4397, -0.7587], [ 0.9805, 0.4166, -0.1906, -0.2581]]) 乘以100个矩阵后 tensor([[ 7.6616e+22, 4.2587e+22, -5.8065e+22, 1.2980e+23], [-2.3790e+21, -1.3224e+21, 1.8030e+21, -4.0304e+21], [-1.3796e+23, -7.6687e+22, 1.0456e+23, -2.3373e+23], [ 8.5987e+20, 4.7795e+20, -6.5167e+20, 1.4567e+21]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.3 打破对称性
神经网络设计中的另一个问题是其参数化所固有的对称性。 假设我们有一个简单的多层感知机,它有一个隐藏层和两个隐藏单元。 在这种情况下,我们可以对第一层的权重 W ( 1 ) \mathbf{W}^{(1)} W(1)进行重排列, 并且同样对输出层的权重进行重排列,可以获得相同的函数。 第一个隐藏单元与第二个隐藏单元没有什么特别的区别。 换句话说,我们在每一层的隐藏单元之间具有排列对称性。
假设输出层将上述两个隐藏单元的多层感知机转换为仅一个输出单元。 想象一下,如果我们将隐藏层的所有参数初始化为 W ( 1 ) = c \mathbf{W}^{(1)} = c W(1)=c, c c c为常量,会发生什么? 在这种情况下,在前向传播期间,两个隐藏单元采用相同的输入和参数, 产生相同的激活,该激活被送到输出单元。 在反向传播期间,根据参数 W ( 1 ) \mathbf{W}^{(1)} W(1)对输出单元进行微分, 得到一个梯度,其元素都取相同的值。 因此,在基于梯度的迭代(例如,小批量随机梯度下降)之后, W ( 1 ) \mathbf{W}^{(1)} W(1)的所有元素仍然采用相同的值。 这样的迭代永远不会打破对称性,我们可能永远也无法实现网络的表达能力。 隐藏层的行为就好像只有一个单元。 请注意,虽然小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
2 参数初始化
解决(或至少减轻)上述问题的一种方法是进行参数初始化, 优化期间的注意和适当的正则化也可以进一步提高稳定性。
随机初始化模型参数的方法有很多。在(线性回归的简洁实现)中,我们使用torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式。不过,PyTorch中nn.Module的模块参数都采取了较为合理的初始化策略(不同类型的layer具体采样的哪一种初始化方法的可参考源代码),因此一般不用我们考虑。2.1 默认初始化
前面的部分中,我们使用正态分布来初始化权重值。如果我们不指定初始化方法, 框架将使用默认的随机初始化方法,对于中等难度的问题,这种方法通常很有效。
2.2 Xavier初始化
让我们看看某些没有非线性的全连接层输出(例如,隐藏变量) o i o_{i} oi的尺度分布。 对于该层 n i n n_\mathrm{in} nin输入 w i j w_{ij} wij及其相关权重 w i j w_{ij} wij,输出由下式给出:
o i = ∑ j = 1 n i n w i j x j . o_{i} = \sum_{j=1}^{n_\mathrm{in}} w_{ij} x_j. oi=j=1∑ninwijxj.
权重 w i j w_{ij} wij都是从同一分布中独立抽取的。 此外,让我们假设该分布具有零均值和方差 σ 2 \sigma^2 σ2。 请注意,这并不意味着分布必须是高斯的,只是均值和方差需要存在。 现在,让我们假设层的输入 x j x_j xj也具有零均值和方差 γ 2 \gamma^2 γ2, 并且它们独立于 w i j w_{ij} wij并且彼此独立。 在这种情况下,我们可以按如下方式计算 o i o_i oi的平均值和方差:E [ o i ] = ∑ j = 1 n i n E [ w i j x j ] = ∑ j = 1 n i n E [ w i j ] E [ x j ] = 0 , V a r [ o i ] = E [ o i 2 ] − ( E [ o i ] ) 2 = ∑ j = 1 n i n E [ w i j 2 x j 2 ] − 0 = ∑ j = 1 n i n E [ w i j 2 ] E [ x j 2 ] = n i n σ 2 γ 2 .
E[oi]Var[oi]=j=1∑ninE[wijxj]=j=1∑ninE[wij]E[xj]=0,=E[oi2]−(E[oi])2=j=1∑ninE[wij2xj2]−0=j=1∑ninE[wij2]E[xj2]=ninσ2γ2.E [ o i ] = ∑ j = 1 n i n E [ w i j x j ] = ∑ j = 1 n i n E [ w i j ] E [ x j ] = 0 , V a r [ o i ] = E [ o i 2 ] − ( E [ o i ] ) 2 = ∑ j = 1 n i n E [ w i j 2 x j 2 ] − 0 = ∑ j = 1 n i n E [ w i j 2 ] E [ x j 2 ] = n i n σ 2 γ 2 . 保持方差不变的一种方法是设置 n i n σ 2 = 1 n_\mathrm{in} \sigma^2 = 1 ninσ2=1。 现在考虑反向传播过程,我们面临着类似的问题,尽管梯度是从更靠近输出的层传播的。 使用与前向传播相同的推断,我们可以看到,除非 n o u t σ 2 = 1 n_\mathrm{out} \sigma^2 = 1 noutσ2=1, 否则梯度的方差可能会增大,其中 n o u t n_\mathrm{out} nout是该层的输出的数量。 这使得我们进退两难:我们不可能同时满足这两个条件。 相反,我们只需满足: 1 2 ( n i n + n o u t ) σ 2 = 1 或等价于 σ = 2 n i n + n o u t .
21(nin+nout)σ2=1 或等价于 σ=nin+nout2.1 2 ( n i n + n o u t ) σ 2 = 1 或等价于 σ = 2 n i n + n o u t .
这就是现在标准且实用的Xavier初始化的基础, 它以其提出者 [Glorot & Bengio, 2010] 第一作者的名字命名。 通常,Xavier初始化从均值为零,方差 σ 2 = 2 n i n + n o u t \sigma^2 = \frac{2}{n_\mathrm{in} + n_\mathrm{out}} σ2=nin+nout2的高斯分布中采样权重。 我们也可以利用Xavier的直觉来选择从均匀分布中抽取权重时的方差。 注意均匀分布 U ( − a , a ) U(-a, a) U(−a,a)的方差为 a 2 3 \frac{a^2}{3} 3a2。 将 a 2 3 \frac{a^2}{3} 3a2代入到 σ 2 \sigma^2 σ2的条件中,将得到初始化值域:
U ( − 6 n i n + n o u t , 6 n i n + n o u t ) . U\left(-\sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}, \sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}\right). U(−nin+nout6,nin+nout6).
尽管在上述数学推理中,“不存在非线性”的假设在神经网络中很容易被违反, 但Xavier初始化方法在实践中被证明是有效的比较常用的随机初始化方法叫作Xavier随机初始化。 假设某全连接层的输入个数为aa,输出个数为bb,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布

它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。2.3 额外阅读
上面的推理仅仅触及了现代参数初始化方法的皮毛。 深度学习框架通常实现十几种不同的启发式方法。 此外,参数初始化一直是深度学习基础研究的热点领域。 其中包括专门用于参数绑定(共享)、超分辨率、序列模型和其他情况的启发式算法。 例如,Xiao等人演示了通过使用精心设计的初始化方法 [Xiao et al., 2018], 可以无须架构上的技巧而训练10000层神经网络的可能性。
2.4 小结
- 梯度消失和梯度爆炸是深度网络中常见的问题。在参数初始化时需要非常小心,以确保梯度和参数可以得到很好的控制。
- 需要用启发式的初始化方法来确保初始梯度既不太大也不太小。
- ReLU激活函数缓解了梯度消失问题,这样可以加速收敛。
- 随机初始化是保证在进行优化前打破对称性的关键。
- Xavier初始化表明,对于每一层,输出的方差不受输入数量的影响,任何梯度的方差不受输出数量的影响
- 深度模型有关数值稳定性的典型问题是衰减和爆炸。当神经网络的层数较多时,模型的数值稳定性容易变差。
-
相关阅读:
【开源】基于Vue和SpringBoot的电子元器件管理系统
[分布式]-Raft论文研读
期末复习【机器学习】
特征融合篇 | YOLOv8 引入中心化特征金字塔 EVC 模块 | 《Centralized Feature Pyramid for Object Detection》
log4j2.xml 获取当前系统属性
微服务学习(七):docker安装Mysql
华为新设备升级示例
【TypeScript】—1— 关于TypeScript你必须知道的一切
今年三下乡社会实践活动向媒体投稿我有了底气
4.7k Star!全面的C#/.NET/.NET Core学习、工作、面试指南
- 原文地址:https://blog.csdn.net/qq_52358603/article/details/127638233