建议先阅读:Java 编码那些事(一)
现在说说编码在Java中的实际运用。在使用tomcat的时候,绝大部分同学都会遇到乱码的问题,查查文档,google一下解决方案啥的,都是设置这里,设置那里,或者在代码中添加编码方式,虽然最终问题解决了,但是你真的知道这是什么意思么?
在平时开发Java的时候,我们会遇到很多编码设置,其中包括:
-
Java文件的编码:
Java文件的编码表示编写代码得时候,.java文件本身的编码,这个编码的影响在于将你的写的代码源文件复制一份,使用其他编辑器打开,若两个编辑器的默认编码方式不一样,则打开源文件就会变成乱码。一般英文的影响不大,因为大多数编码都兼容ASCII编码,但是中文要是编码不正确,则会乱码。IDEA的设置在:Setting->Editor->File Encodings中设置 -
JVM编码:
JVM编码表示JVM在读取String类型的默认编码,可以使用Charset.defaultCharset().name()获取。可以在JVM启动参数中使用-Dfile.encoding=UTF-8进行设置。
一般需要区分的就是这两种编码。下面着重说下JVM编码的体现。
字节流与字符流
熟悉IO的同学应该都明白这两个流的区别。一般会出现字符乱码都在于需要与其他程序进行IO的时候。
先看看使用字节流进行读取文件的时候:

public static void main(String[] args){ String path="G:\\test.txt"; try(BufferedInputStream inputStream=new BufferedInputStream(new FileInputStream(path))) { for (byte bytes[] = new byte[1024]; inputStream.read(bytes) != -1; ) { String context = new String(bytes); System.out.println(context); } }catch (IOException e){ e.printStackTrace(); } }
然后再G盘新建一个文本文件,输入一段文字。使用默认的格式保存。
可以查看输出:
�����ļ��ļ�
乱码了,下面来分析一下:
首先这里是JVM运行时的编码,因此和JVM的编码设置有关。打印JVM目前的编码设置:
System.out.println(Charset.defaultCharset().name());
输出:UTF-8
找到刚刚新建的文件test.txt,点击另存为,可以发现默认编码为ANSI,前一篇文章中说过,ANSI作为windows系统中的特殊存在,它在简体中文编码的情况下默认为GBK编码。这便是乱码的原因,解决方案有两种:
- 设置
JVM启动项:-Dfile.encoding = GB2312 - 在编码
byte数组的时候,指定GB2312编码:String context = new String(bytes,"GB2312");
这里推荐第二种,毕竟UTF8更加通用
问题完美解决。
同理,网络IO也能通过以上方法解决。
看明白了上面的发现问题和解决问题的流程的同学,下次遇到文件编码的问题,相信应该能够独立解决问题。
实战
明白了各种编码问题,现在我们可以着手进行实战。
第一次使用IDEA开发Servlet的时候,大多数都会遇见乱码问题,包括:
-
控制台输出
Tomcat日志乱码 -
网页显示
Servlet返回的中文乱码
虽然各种Google后,终于解决了,但是可能依然不明白其中的缘由。下面我们来一探究竟
Tomcat日志
首先解决Tomcat日志乱码的问题,首先要明白:Tomcat作为一个独立的进程,IDEA是怎么获取到Tomcat日志的呢?在IDEA控制台中的Tomcat启动日志中,我们可以找到一个日志记录:
-Dcatalina.base=C:\xxx\.IntelliJIdea2018.3\system\tomcat\xxx
复制选项中的路径,在文件夹中打开,进入logs文件夹,就可以发现这个是tomcat的日志文件输出路径,而IDEA正是读取了这个文件中的内容输出到控制台中,我们可以使用记事本打开日志文件,然后选择另存为,可以发现文件的默认编码是ANSI,也就说在简体中文下是GBK编码。
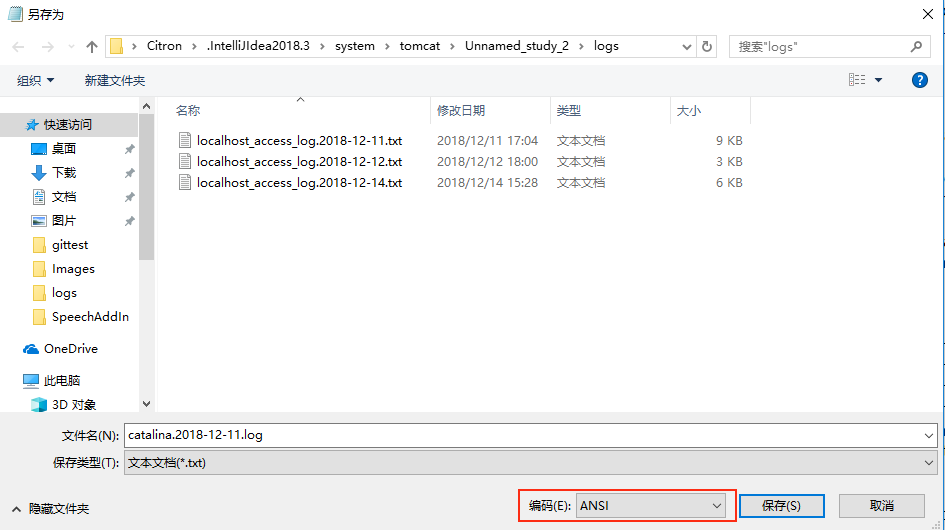
而读取文本文件内容一般有两种方式,第一种是字符流,第二种是字节流,字节流可以指定字符编码也可以通过的JVM启动参数-Dfile.encoding指定默认编码。
明白了上面的问题,我们就能知道为什么乱码了,这是因为IDEA的默认编码和这个日志文件的编码格式不统一导致的。
解决方案很简单,统一两个系统的编码,对于Tomcat的输出的日志文件,我们可以设置Tomcat启动的VM选项:Edit Configurations->Server-> VM options编辑添加:-Dfile.encoding=UTF-8
设置完Tomcat编码后,删除刚刚路径中的日志文件,重启Tomcat服务,再使用记事本打开刚刚的日志文件,另存为我们可以发现,编码已经变成了UTF-8。
IDEA
接下来设置IDEA的编码,IDEA默认编码暂时没有找到查找方式,我们也可以将其指定为UTF-8,找到IDEA的安装路径,在bin目录中可以发现一个名为idea.exe.vmoptions和idea64.exe.vmoptions选项,分别打开,添加-Dfile.encoding=UTF-8后,重启IDEA.
完成上面两步后,再次启动Tomcat服务,你会发现日志已经正常。
注:如果依然发现乱码,则可能是IDEA缓存了当前项目的编码设置,你可以在当前项目的
.idea文件夹中找到encoding.xml文件,删除所有不是UTF-8的编码设置,重启IDEA即可。
网页乱码
我们都知道,浏览器浏览的网页其实是从服务器发送的HTML文件到浏览器中显示,而发送的是通过字节流传输,这个过程就涉及到解码->编码的过程,在HTTP协议中,编码的协议通过Header中的charset中设置。
为什么放
header,因为HTTP请求会先解析header,而且header一般不会有ascii无法解析的字符,一般都是英文
网页乱码其实很好解决,如果发现在Servlet中,返回中文给浏览器的时候浏览器返回的是???
点击F12,抓包网络后,找到Response Body 中的charset选项,可以发现charset=ISO-8859-1
也就说默认的Tomcat使用的编码是ISO-8859-1,这是西欧的语言编码,它是不兼容中文的。如果你在Servlet返回的结果中添加一点法语:Ä ä或者德语什么的,你会发现会正常显示。
charset的意思便是Tomcat是以什么样的方式编码字节,而浏览器便会以这样的编码方式解码字节。
我们可以将charset修改为兼容中文的即可,比如UTf-8,GB2312等,建议使用UTF-8,在Servlet中,设置编码的方式为:
response.setCharacterEncoding("UTF-8");
也可以如下:
resp.setContentType("text/html;charset=UTF-8");
建议第一种方式。
到这里,所有的乱码问题都已经解决。
其实,乱码不可怕,可怕的是经历了这么多次乱码却依然不去了解它。
~~
微信搜索公众号:StackTrace,关注我们,不断学习,不断提升