-
spark-submit源码解析
先说背景。
spark工程要引入一个其他的包,就叫它polaris 。这个包含有一个protobuf-java-3.12.0.jar。
但是我们cdh6.3.2里含有的protobuf-java-2.5.0.jar 这里存在一个jar冲突。

现象。
我们打包的时候把polaris 包打入jar包。然后我们执行java-jar java -classpath xxx 的时候,一切正常。
但是我们如果在spark的代码里引用这个jar,就会出现类找不到,经查寻,就是这个3.12.0找不到。
解决办法。
1.spark/jars目录放如这个jar。 用client 放一台机器就行。cluster估计要全放。
2.--files protobuf-java-3.12.0.jar \ 试了
22/10/31 10:23:23 INFO yarn.Client: Uploading resource file:/data/share/dw_ia_portraitsearch/protobuf-java-3.12.0.jar -> hdfs://s2cluster/user/hive/.sparkStaging/application_1663836951091_3821/protobuf-java-3.12.0.jar
3.--jars protobuf-java-3.12.0.jar4.--packages xxxx:xxx \ --repositories url \
那么这几种有什么区别呢? 还是得搞源码。怎么入手呢?
spark-submit开始,下面一步步学习和研究spark-submit。
whereis spark-submit

#!/bin/bash
# Reference: http://stackoverflow.com/questions/59895/can-a-bash-script-tell-what-directory-its-stored-in
SOURCE="${BASH_SOURCE[0]}"
BIN_DIR="$( dirname "$SOURCE" )"
while [ -h "$SOURCE" ]
do
SOURCE="$(readlink "$SOURCE")"
[[ $SOURCE != /* ]] && SOURCE="$BIN_DIR/$SOURCE"
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
done
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
LIB_DIR=$BIN_DIR/../lib
export HADOOP_HOME=$LIB_DIR/hadoop --配置hadoophome# Autodetect JAVA_HOME if not defined --获取javahome
. $LIB_DIR/bigtop-utils/bigtop-detect-javahomeexec $LIB_DIR/spark/bin/spark-submit "$@" --再次把参数传递给另外一个spark-submit。
最后执行的是exec $LIB_DIR/spark/bin/spark-submit "$@"
我们定位到

#!/usr/bin/env bash
#
# 配置号spark_homeif [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0#执行这个脚本
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
简化为 /data/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
查看spark-class脚本
if [ -z "${SPARK_HOME}" ]; then --获取sparkhome
source "$(dirname "$0")"/find-spark-home
fi. "${SPARK_HOME}"/bin/load-spark-env.sh --加载spark-env环境
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then --javahome
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi# Find Spark jars. --注意这里获取sparkhome/jars下的所有文件
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fiif [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
build_command() { --重点啊 最后就是java -cp
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}# Turn off posix mode since it does not allow process substitution
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fiif [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fiCMD=("${CMD[@]:0:$LAST}")
echo CMD=${CMD[@]} --这里我们打印下就知道了
exec "${CMD[@]}"
最后的命令差不多就是
CLOUERA_HOME=/data/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib
CMD=/usr/local/jdk1.8.0_251/bin/java -cp ${CLOUERA_HOME}/spark/conf/:
${CLOUERA_HOME}/spark/jars/*: --这里就有我们上面提到的proto jar
${CLOUERA_HOME}/spark/jars/../hive/*:
${CLOUERA_HOME}/spark/conf/yarn-conf/:
/etc/hive/conf/:
${CLOUERA_HOME}/hadoop/client/accessors-smart-1.2.jar:
${CLOUERA_HOME}/hadoop/client/accessors-smart.jar:
${CLOUERA_HOME}/hadoop/client/asm-5.0.4.jar:
${CLOUERA_HOME}/hadoop/client/asm.jar:
${CLOUERA_HOME}/hadoop/client/avro.jar:
${CLOUERA_HOME}/hadoop/client/aws-java-sdk-bundle-1.11.271.jar:
${CLOUERA_HOME}/hadoop/client/aws-java-sdk-bundle.jar:
${CLOUERA_HOME}/hadoop/client/azure-data-lake-store-sdk-2.2.9.jar:
${CLOUERA_HOME}/hadoop/client/azure-data-lake-store-sdk.jar:
${CLOUERA_HOME}/hadoop/client/commons-beanutils-1.9.4.jar:
${CLOUERA_HOME}/hadoop/client/commons-beanutils.jar:
${CLOUERA_HOME}/hadoop/client/commons-cli-1.2.jar:
${CLOUERA_HOME}/hadoop/client/commons-cli.jar:
${CLOUERA_HOME}/hadoop/client/commons-codec-1.11.jar:
${CLOUERA_HOME}/hadoop/client/commons-codec.jar:
${CLOUERA_HOME}/hadoop/client/commons-collections-3.2.2.jar:
${CLOUERA_HOME}/hadoop/client/commons-collections.jar:
${CLOUERA_HOME}/hadoop/client/commons-compress-1.18.jar:
${CLOUERA_HOME}/hadoop/client/commons-compress.jar:
${CLOUERA_HOME}/hadoop/client/commons-configuration2-2.1.1.jar:
${CLOUERA_HOME}/hadoop/client/commons-configuration2.jar:
${CLOUERA_HOME}/hadoop/client/commons-io-2.6.jar:
${CLOUERA_HOME}/hadoop/client/commons-io.jar:
${CLOUERA_HOME}/hadoop/client/commons-lang-2.6.jar:
${CLOUERA_HOME}/hadoop/client/commons-lang.jar:
${CLOUERA_HOME}/hadoop/client/commons-lang3-3.7.jar:
${CLOUERA_HOME}/hadoop/client/commons-lang3.jar:
${CLOUERA_HOME}/hadoop/client/commons-logging-1.1.3.jar:
${CLOUERA_HOME}/hadoop/client/commons-logging.jar:
${CLOUERA_HOME}/hadoop/client/commons-math3-3.1.1.jar:
${CLOUERA_HOME}/hadoop/client/commons-math3.jar:
${CLOUERA_HOME}/hadoop/client/commons-net-3.1.jar:
${CLOUERA_HOME}/hadoop/client/commons-net.jar:
${CLOUERA_HOME}/hadoop/client/curator-client-2.12.0.jar:
${CLOUERA_HOME}/hadoop/client/curator-client.jar:
${CLOUERA_HOME}/hadoop/client/curator-framework-2.12.0.jar:
${CLOUERA_HOME}/hadoop/client/curator-framework.jar:
${CLOUERA_HOME}/hadoop/client/curator-recipes-2.12.0.jar:
${CLOUERA_HOME}/hadoop/client/curator-recipes.jar:
${CLOUERA_HOME}/hadoop/client/gson-2.2.4.jar:
${CLOUERA_HOME}/hadoop/client/gson.jar:
${CLOUERA_HOME}/hadoop/client/guava-11.0.2.jar:
${CLOUERA_HOME}/hadoop/client/guava.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-annotations-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-annotations.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-auth-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-auth.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-aws-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-aws.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-azure-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-azure-datalake-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-azure-datalake.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-azure.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-common-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-common.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-hdfs-client-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-hdfs-client.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-common.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-core.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-mapreduce-client-jobclient.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-api-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-api.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-client-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-client.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-common-3.0.0-cdh6.3.2.jar:
${CLOUERA_HOME}/hadoop/client/hadoop-yarn-common.jar:
${CLOUERA_HOME}/hadoop/client/htrace-core4-4.1.0-incubating.jar:
${CLOUERA_HOME}/hadoop/client/htrace-core4.jar:
${CLOUERA_HOME}/hadoop/client/httpclient-4.5.3.jar:
${CLOUERA_HOME}/hadoop/client/httpclient.jar:
${CLOUERA_HOME}/hadoop/client/httpcore-4.4.6.jar:
${CLOUERA_HOME}/hadoop/client/httpcore.jar:
${CLOUERA_HOME}/hadoop/client/javax.activation-api-1.2.0.jar:
${CLOUERA_HOME}/hadoop/client/javax.activation-api.jar:
${CLOUERA_HOME}/hadoop/client/jaxb-api-2.2.11.jar:
${CLOUERA_HOME}/hadoop/client/jaxb-api.jar:
${CLOUERA_HOME}/hadoop/client/jcip-annotations-1.0-1.jar:
${CLOUERA_HOME}/hadoop/client/jcip-annotations.jar:
${CLOUERA_HOME}/hadoop/client/json-smart-2.3.jar:
${CLOUERA_HOME}/hadoop/client/json-smart.jar:
${CLOUERA_HOME}/hadoop/client/jsp-api-2.1.jar:
${CLOUERA_HOME}/hadoop/client/jsp-api.jar:
${CLOUERA_HOME}/hadoop/client/jsr305-3.0.0.jar:
${CLOUERA_HOME}/hadoop/client/jsr305.jar:
${CLOUERA_HOME}/hadoop/client/jsr311-api-1.1.1.jar:
${CLOUERA_HOME}/hadoop/client/jsr311-api.jar:
${CLOUERA_HOME}/hadoop/client/kerb-admin-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-admin.jar:
${CLOUERA_HOME}/hadoop/client/kerb-client-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-client.jar:
${CLOUERA_HOME}/hadoop/client/kerb-common-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-common.jar:
${CLOUERA_HOME}/hadoop/client/kerb-core-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-core.jar:
${CLOUERA_HOME}/hadoop/client/kerb-crypto-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-crypto.jar:
${CLOUERA_HOME}/hadoop/client/kerb-identity-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-identity.jar:
${CLOUERA_HOME}/hadoop/client/kerb-server-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-server.jar:
${CLOUERA_HOME}/hadoop/client/kerb-simplekdc-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-simplekdc.jar:
${CLOUERA_HOME}/hadoop/client/kerb-util-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerb-util.jar:
${CLOUERA_HOME}/hadoop/client/kerby-asn1-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerby-asn1.jar:
${CLOUERA_HOME}/hadoop/client/kerby-config-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerby-config.jar:
${CLOUERA_HOME}/hadoop/client/kerby-pkix-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerby-pkix.jar:
${CLOUERA_HOME}/hadoop/client/kerby-util-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerby-util.jar:
${CLOUERA_HOME}/hadoop/client/kerby-xdr-1.0.0.jar:
${CLOUERA_HOME}/hadoop/client/kerby-xdr.jar:
${CLOUERA_HOME}/hadoop/client/log4j-1.2.17.jar:
${CLOUERA_HOME}/hadoop/client/log4j.jar:
${CLOUERA_HOME}/hadoop/client/nimbus-jose-jwt-4.41.1.jar:
${CLOUERA_HOME}/hadoop/client/nimbus-jose-jwt.jar:
${CLOUERA_HOME}/hadoop/client/okhttp-2.7.5.jar:
${CLOUERA_HOME}/hadoop/client/okhttp.jar:
${CLOUERA_HOME}/hadoop/client/okio-1.6.0.jar:
${CLOUERA_HOME}/hadoop/client/okio.jar:
${CLOUERA_HOME}/hadoop/client/paranamer-2.8.jar:
${CLOUERA_HOME}/hadoop/client/paranamer.jar:
${CLOUERA_HOME}/hadoop/client/protobuf-java-2.5.0.jar:
${CLOUERA_HOME}/hadoop/client/protobuf-java.jar:
${CLOUERA_HOME}/hadoop/client/re2j-1.1.jar:
${CLOUERA_HOME}/hadoop/client/re2j.jar:
${CLOUERA_HOME}/hadoop/client/snappy-java-1.1.4.jar:
${CLOUERA_HOME}/hadoop/client/snappy-java.jar:
${CLOUERA_HOME}/hadoop/client/stax2-api-3.1.4.jar:
${CLOUERA_HOME}/hadoop/client/stax2-api.jar:
${CLOUERA_HOME}/hadoop/client/wildfly-openssl-1.0.4.Final.jar:
${CLOUERA_HOME}/hadoop/client/wildfly-openssl.jar:
${CLOUERA_HOME}/hadoop/client/woodstox-core-5.0.3.jar:
${CLOUERA_HOME}/hadoop/client/woodstox-core.jar:
${CLOUERA_HOME}/hadoop/client/xz-1.6.jar:
${CLOUERA_HOME}/hadoop/client/xz.jar -Xmx1g org.apache.spark.deploy.SparkSubmit
/data/share/dw_ia_portraitsearch/anping-1.0-SNAPSHOT-jar-with-dependencies.jar--class xxxx --number-excutors xxx 。。。。。。
到这里了 我们还没看到spark的 -files 和--jars 那估计就是代码里的了



这里先prepare环境参数了,然后就开始runmain方法
prepareSubmitEnvironment里
args: SparkSubmitArguments
我们看下这个类SparkSubmitArguments 是什么? 就是我们熟悉的各种spark-submit的参数

确定master是啥 也就是我们的--master
 确定部署模式是啥 --deploy-mode
确定部署模式是啥 --deploy-mode
master+deploy-mode两个是否冲突

这个也是 提示两个参数不要瞎搭配

把spark-defalut.conf的kv 放到spark-conf里

下面就是重头戏
客户端模式下。 childmainClass=new ArrayBuffer[string]()
先是=我们submit的主类
然后+ localPrimaryResource ;再加上localJars

childMainClass = args.mainClass --就是我们的--class com.chenchi.sparkjob这个类 localPrimaryResource = Option(args.primaryResource).map { downloadFile(_, targetDir, sparkConf, hadoopConf, secMgr)}.orNull 上面这个就是我们上面那个一大长串spark hadooop的jar。 localJars = Option(args.jars).map { downloadFileList(_, targetDir, sparkConf, hadoopConf, secMgr) }.orNull 上面这个就是 我们--jars里添加的jar现在就是把spark本身自己带的jar和我们自己添加的jar获取到了。现在我们来看rumain方法。

注意这里 上面的红框是啥 这个DRIVER_USER_CLASS_PATH_FIRST 顾名思义就是先加载用户的jar,然后再加载spark的jar。所以我怀疑就是这里出了问题。因为这个默认就是先加载spark的jar
private[spark] val DRIVER_USER_CLASS_PATH_FIRST = ConfigBuilder("spark.driver.userClassPathFirst").booleanConf.createWithDefault(false)然后把所有的jar都加入到classpath。然后知道如何百度了。就是根据这个参数
Spark依赖包冲突解决_dengqian2095的博客-CSDN博客
看到没 不读点源码 tm的百度都百度不到答案。

接着看如何执行我们的spark代码的

这里mainclass 然后new了一个javaMainApplication
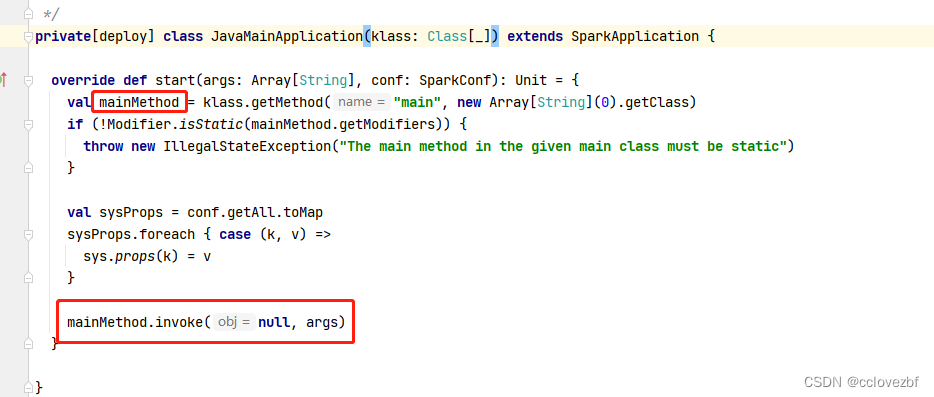
根据主类搞了一个实例 然后调用了main方法,同时把args传进去了。最后任务就跑起来。
由于能力有限,里面涉及到了各种类的加载,有些地方还不是特别透彻,但是大概意思了解了一些了。
-
相关阅读:
Kafka安装使用
【毕业设计】基于Spark的海量新闻文本聚类(新闻分类)
File类常用方法
uniapp 开发 之 如何给边框添加阴影效果
基于SpringBoot框架的网上购物商城系统的设计与实现
企业知识如何集中保护管理,杜绝信息外泄
02强化学习基本概念
spring boot项目上传头像
Hungarian algorithm
Python语法:如何使用requirements.txt文件在Python环境中安装依赖?
- 原文地址:https://blog.csdn.net/cclovezbf/article/details/127609946