-
Q学习与Sarsa
1 Q学习与Sarsa
从二者的更新公式中就可以发现端倪
- Q学习是一种离线学习,“就取最大的”
-
- Q学习总是以下一个状态的最大动作Q值来计算现实值
- Sarsa是一种在线学习,“说到做到”
-
- Sarsa以下一个状态所采取的真实动作的Q值来计算现实值

- Sarsa以下一个状态所采取的真实动作的Q值来计算现实值
2 Q学习的两个价值函数

3 学习方法
3.1 策略学习
- 利用策略函数π(a|s)根据状态s直接输出每个动作的概率
- 利用上述概率进行随机抽样,抽出动作a

3.2 价值学习-最优动作价值函数
- 根据Q值,那么就在状态S选可获得最大Q值的a

4 价值学习
4.1 深度Q学习
- 深度Q学习还是一种基于价值学习的,
- 只不过使用神经网络去拟合动作值函数
- 网络的更新使用梯度下降,就是损失函数的下降,
-
- 因为损失函数涉及到模型上的很多参数,对这些参数求偏导
-
- 然后计算出梯度,再更新模型上的这些参数,图上就是更新参数w的过程

- 然后计算出梯度,再更新模型上的这些参数,图上就是更新参数w的过程
4.2 TD算法-时间差分
- 比如我的模型可以预测A地-C地开车所需要花费的时间
- 那么现在我打算从A地开车出发跑到C地实际测试一下
- 可是我跑到中间 B地时花了时间但t车坏了,那么这时怎么利用跑到一半的实际值来更新模型呢
- 我门可以用模型预测A-C的时间t1,以及B-C的时间t2,
- 再拿实际值t去这两个t1与t2的差预测值来更新模型


5 策略学习

6 AC算法
6.1 两个网络:策略网络 和 价值网络
-
策略网络


-
价值网络
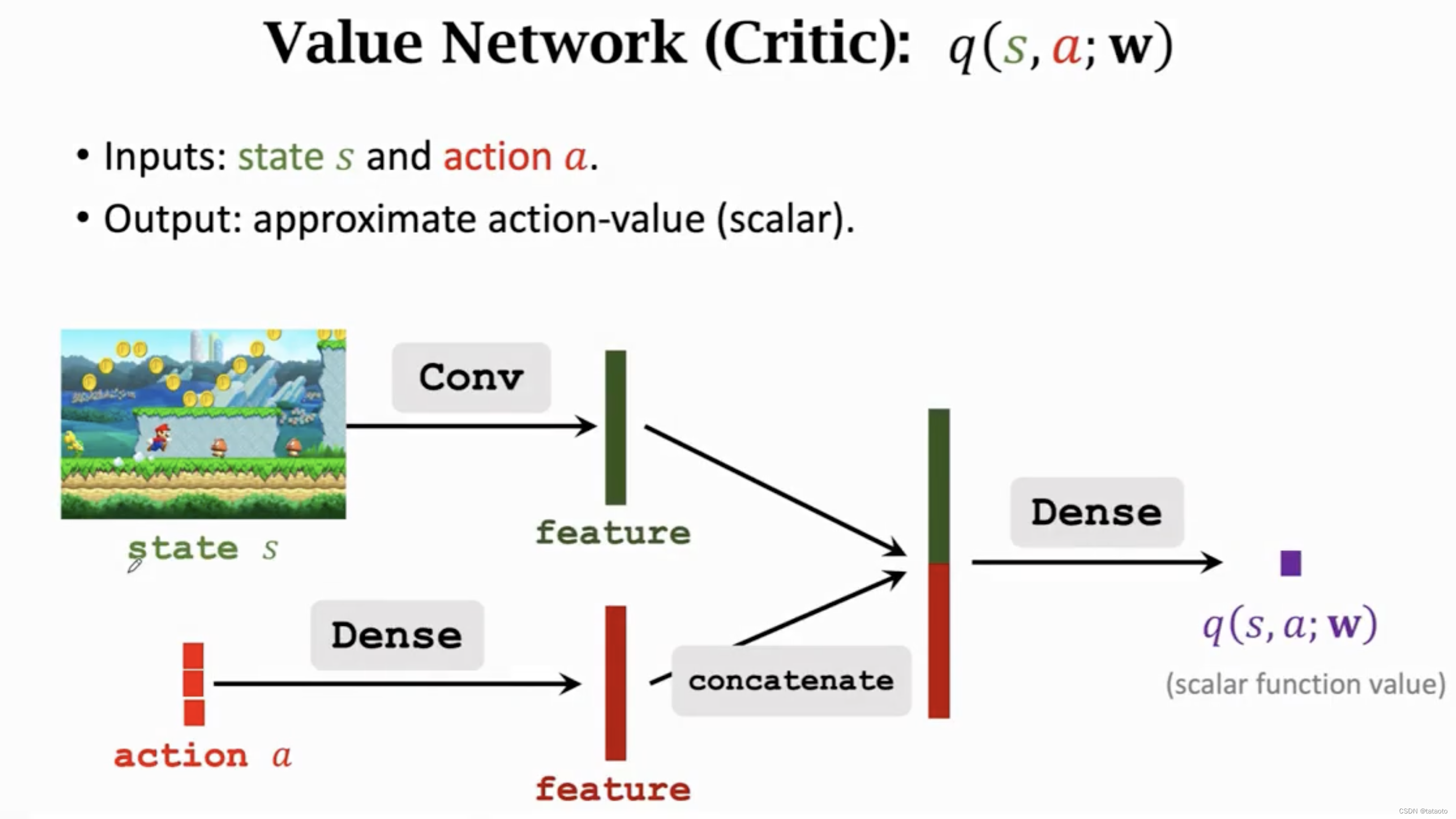

6.2
- 策略网络的更新
策略网络观察到状态S,采取一个动作a,
价值网络根据俄这个状态S和动作a,给出打分
策略网络根据价值网络的打分去更新其网络参数 - 价值网络的更新
环境会对智能体所做的动作进行反馈,即奖赏 r
价值函数就是根据这个奖赏r来更新网络参数的

6.3 迭代

-
相关阅读:
ROS 导航
goLang context组件学习笔记
第一篇文章 mybatis 综述
[datawhale202211]跨模态神经搜索实践:Jina生态
linux下nginx安装与配置说明
[SWPU2019]Web1
【计算机网络】 RTT和RTO
【Verilog】时序逻辑电路 -- 有限同步状态机[补充]
bugku渗透测试 1 writeup(无需VPS)
Java线程池和Spring异步处理高级篇
- 原文地址:https://blog.csdn.net/tataoto/article/details/127584555