-
BF算法与KMP模式匹配算法(画图详解,C语言实现)
1.BF算法
1.1BF算法定义
BF算法,即暴力(Brute Force)算法。
基本思想:从主串S的第一个字符开始和模式T的第一个字符进行比较,若相等,则继续比较两者的后续字符;否则,从主串S的第二个字符开始和模式T的第一个字符进行比较,重复上述过程,直到T中的字符全部比较完毕,则说明本趟匹配成功;或S中字符全部比较完,则说明匹配失败。
如下图所示:

i 的回溯公式:i = i - j + 1
j 每次都会回溯到 0 的位置回溯完成后:

1.2BF算法举例
举例:主串S=“ababcabcacbab” 模式T=“abcac”
第一趟:

第二趟:
第三趟:
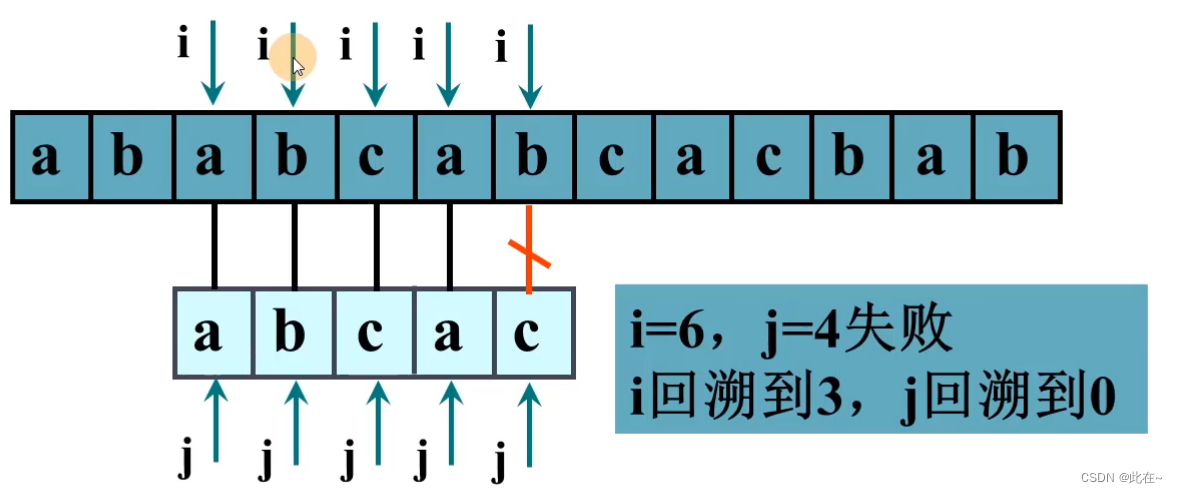
第四趟:

第五趟:

第六趟:

i=10, j=5, T中全部字符都比较完毕,匹配成功,返回位置( i - j)1.3BF算法代码实现
BF算法过程(伪代码)
- 在串S和串T(字串)中设比较的起始下标i和j
- 循环直到S或T(字串)的所有字符均未比较完(终止条件)
- 2.1如果S[i]=T[j],继续比较S和T的下一个字符;
- 2.2否则,将i和j回溯,准备下一趟比较;
- 如果T(字串)中所有字符均比较完,则匹配成功,返回匹配的起始比较下标;否则,匹配失败,返回-1;
代码实现:
//S是主串,T是子串 int BF(char S[], char T[]) { int i = 0; int j = 0; //循环直到S或T(字串)的所有字符均未比较完(终止条件) while (S[i]!='\0' && T[j]!='\0'){//也可以写为while(S[i]&&T[j]) if(S[i] == T[j]){//匹配主串和子串直接+1 i++; j++; } else{//不匹配回溯 i=i-j+1; j=0; } } //判断字串情况如果到最后则遍历完毕找到匹配位置 if(T[j]=='\0'){ return (i-j);//找到,返回下标 }else{ return -1;//找不到返回-1 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
1.4BF算法性能分析
设串S长度为n,串T长度为m,在匹配成功的情况下,考虑两种极端情况:
最好情况:不成功的匹配都发生在串T的第1个字符。
例如:
S=“aaaaaaaaaabcdccccc”
T=“bcd”设匹配成功发生在Si;处,则在 i - 1 趟不成功的匹配中共比较了 i -1次,第 i 趟成功的匹配共比较了m次,所以总共比较了 i -1+m次,所有匹配成功的可能情况共有n - m+1种,则:

最坏情况:不成功的匹配都发生在串T的最后一个字符。
例如: S=“0000000000000000000000000000000001”
T=" 00001"
模式前4个字符均为"0",又,主串中前40个字符均为"0",每趟比较都在模式的最后一个字符出现不等,此时需要将指针回溯到 i-3 的位置上,并从模式的第一个字符开始重新比较,整个匹配过程中指针 i 需回溯36(40-4)次,则循环次数为37*5, 可见,算法最坏的平均复杂度为O(n X m)设匹配成功发生在Si处,则在 i-1趟不成功的匹配中共比较了(i-1)X m次,第 i 趟成功的匹配共比较了m次,所以总共比较了 i X m次,
因此:

2.KMP算法
2.1KMP算法与BF算法的区别
KMP算法与BF算法类似,主要修改了回溯的方法
为什么BF算法时间性能低?
在每趟匹配不成功时存在大量回溯,没有利用已经部分匹配的结果。如何在匹配不成功时主串不回溯?
主串不回溯,模式就需要向右滑动一段距离。如何确定模式的滑动距离?
以BF算法举的第一个例子为例:
第一趟:
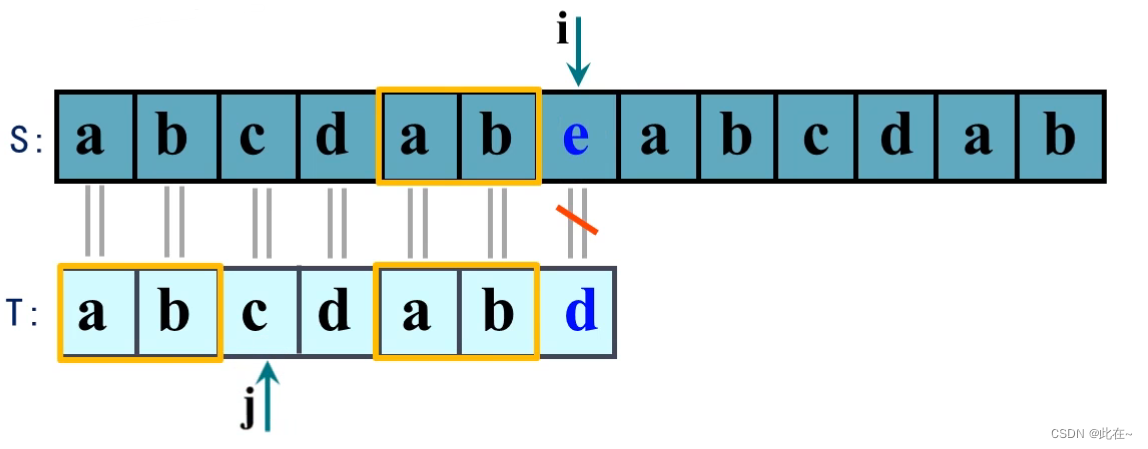
此时模式串T的移动位数为4
移动位数=模式串已匹配的字符数-失配位置前的最长前缀匹配字符数
第二趟:

过程解析:

结论:指向串S的变量 i 可以不回溯,模式串T向右滑动到的新比较起点k,并且k仅与模式串T有关!
KMP算法总结:
- 在失配字符d之前有最长两个字符ab能够与模式串;的前缀相匹配,那么当前的移动位数应当是4。
- 这样移动的理由是可以保证忽略尽量多的无用匹配而同时保证不丢失应该做匹配测试的所有可能位置。
2.2求KMP算法next数组
计算next[ j ]的方法:
-
当j=0时,next[ j ]=-1;
//next[ j ]=-1表示不进行字符比较 -
当j>0时,next[ j ]的值为: 模式串的位置从0到 j-1构成的串中所出现的首尾相同的子串的最大长度。
-
当无首尾相同的子串时next[j]的值为0。
//next[ j ]=0表示从模式串头部开始进行字符比较
求上例中的next数组:

得到的next数组:
//下标 0 1 2 3 4 5 6 next[j]={-1, 0, 0, 0, 0, 1, 2}- 1
- 2
2.3KMP算法的过程举例
利用上面得到的next数组
//下标 0 1 2 3 4 5 6 next[j]={-1, 0, 0, 0, 0, 1, 2}- 1
- 2
第一趟:

第二趟:

第三趟:

第四趟: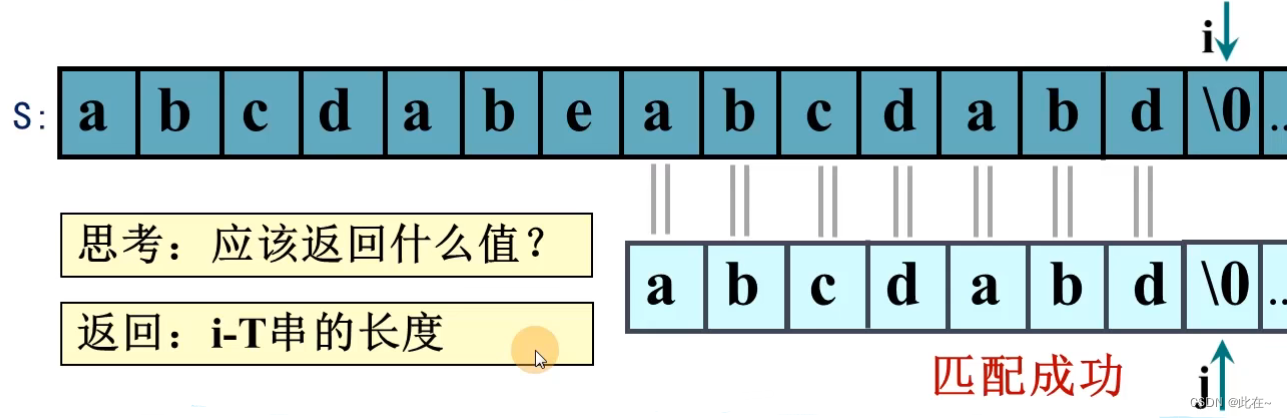
2.4KMP算法代码实现
KMP算法描述:
- 在串S和串T中分别设比较的起始下标i和j;
- 循环直到S或T的所有字符均未比较完
2.1如果S[ i ]=T[ j ],继续比较S和T的下一个字符;
2.2否则将 j 向右滑动到next[ j l位置,即j=next[ j ];
2.3 如果j = -1,则将 i 和 j 分别加1,准备下一趟比较; - 如果T中所有字符均比较完毕,则返回匹配的起始下标;
否则返回-1;
int KMP(char S[],char T[]){ int i = 0; int j = 0; int lenS = strlen(S); int lenT = strlen(T); while(i<lenS && j<lenT){//-1可能会导致数组越界,利用长度来求 if(j==-1||S[i]==T[j]){ i++; j++; }else{ j=next[j]; } } if(j==lenT) return (i-j); else return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
KMP算法时间复杂度分析:
KMP算法相对于BF算法改动不大,关键就是去掉了 i 值回溯的部分。对于getNext函数来说,若T的长度为m,因只涉及简单的单循环,其时间复杂度为O(m),而由于值的不回溯,使得KMP算法效率得到了提高,while循环的时间复杂度为O(n)。因此,整个算法的时间复杂度为O(n+m)。相较于朴素模式匹配算法的O((n-m+1)*m)来说,是要好一些。
这里也需要强调,KMP算法仅当模式与主串之间存在许多“部分匹配”的情况下才体现出它的优势,否则两者差异并不明显。
2.5求解next数组
next数组的递归求解思路:
如下图:j 表示前缀,i 表示后缀
各个对应的颜色表示已找到的对应匹配的部分
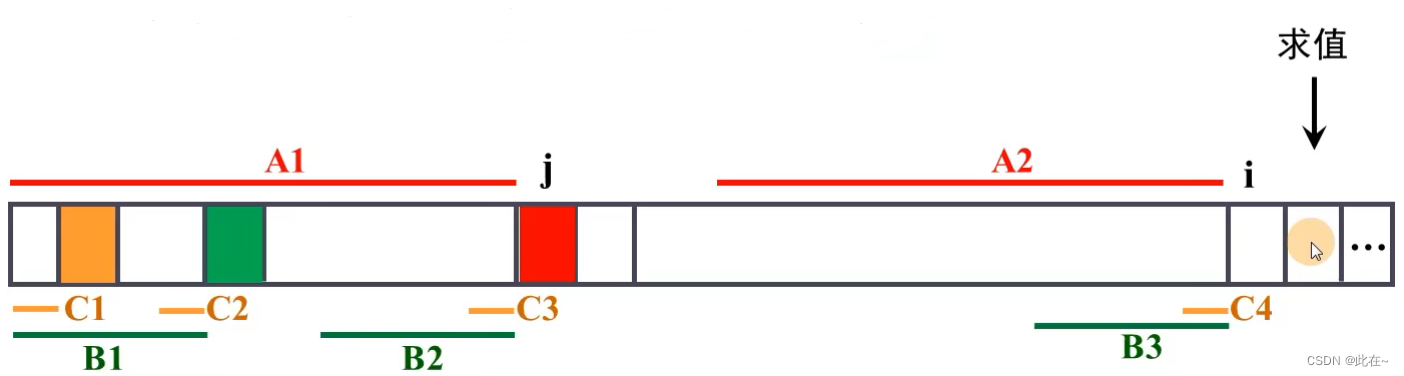
我们已知A1==A2,A1的长度为j,那么A1和A2分别往后增加一个字符后是否还相等呢?(1)如果T[ j ]== T[ i ]),很明显,我们的next[i+1]就填入新的匹配长度 j+1。用代码来写就是:
if( T[i]==T[j] ){ i++; j++; next[i] = j; }- 1
- 2
- 3
- 4
- 5
如下图所示:

(2)否则,(如果T[ j ]≠T[ i ]),那么我们只能从已知的,除了A1, A2之外,最长的B1,B3来继续考虑。代码是:
else{ j = next[j]; }- 1
- 2
- 3
如下图所示:

继续考虑:那么B1和B3分别往后增加一个字符后是否还相等呢?
以上过程的文字描述:
-
接下来,用上面得到的条件来推导如果第i+1位失配时,我们应该填写next[i+1]为多少?
-
next[ i+1]即是找str从0到 i 这个子串的最大前后缀:
-
#: (#:在这里是个标记,后面会用)我们已知A1==A2,那么A1和A2
分别往后增加一个字符后是否还相等呢?我们得分情况讨论: -
(1)如果str[ j ] == str[ i ], 很明显,我们的next[i+1]就直接等于j+1。
-
用代码来写就是next[++i] = ++j;
-
(2)如果str[ j ] != str[ i ], 那么我们只能从已知的,除了A1,A2之外,最长的B1,B3来继续考虑。
-
那么B1和B3分别往后增加一个字符后是否还相等呢?
-
由于next[j] ==绿色色块所在的索引,我们先让j = next[j],把j挪到绿色色块的位置,这样我们就可以递归调用"#: "标记处的逻辑了。
代码实现:
void getNext(char *T,int *next){ int j=-1;//前缀 int i=0;//后缀 next[0]=-1; while(i<T.length){ if(j==-1||T[i]==T[j]){ i++; j++; next[i]=j; }else{ j=next[j]; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
相关阅读:
C语言练习百题之#include应用
Ansible自动化运维工具
孙卫琴的《精通Vue.js》读书笔记-Vue组件的单向数据流
FPGA 图像缩放 千兆网 UDP 网络视频传输,基于B50610 PHY实现,提供工程和QT上位机源码加技术支持
Django笔记三十八之发送邮件
关于需求规范和需求评审的一点看法
vue实现一个鼠标滑动预览视频封面组件
科技云报道:云计算下半场,公有云市场生变,私有云风景独好
d为何用模板参数
ubuntu 18 虚拟机安装(3)安装mysql
- 原文地址:https://blog.csdn.net/m0_57105290/article/details/124083221
