-
【分布式锁】redis设置分布式锁,redission设置分布式锁,常见面试题
分布式锁
一、redis设置分布式锁
1. 基本原理和实现方式对比
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
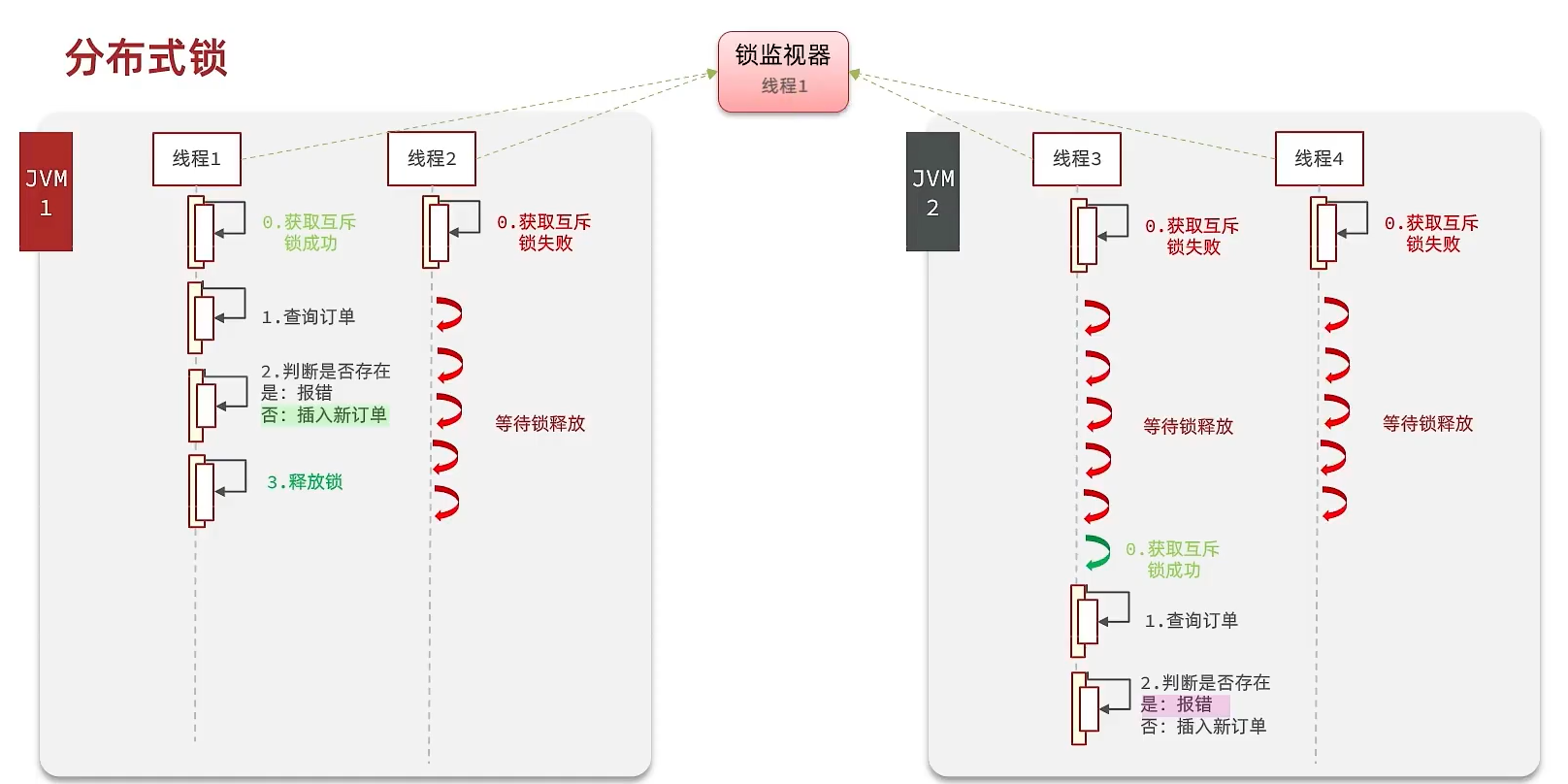
那么分布式锁他应该满足一些什么样的条件呢?
- 可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思
- 互斥:互斥是分布式锁的最基本的条件,使得程序串行执行
- 高可用:程序不易崩溃,时时刻刻都保证较高的可用性
- 高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能
- 安全性:安全也是程序中必不可少的一环
核心思路:
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可二、redission设置分布式锁
1. 分布式锁-redission功能介绍
基于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
超时释放: 我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。

那么什么是Redission呢
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。Redission提供了分布式锁的多种多样的功能

2. 引入依赖
<dependency> <groupId>org.redissongroupId> <artifactId>redissonartifactId> <version>3.13.4version> dependency>- 1
- 2
- 3
- 4
- 5
3. 配置Redisson客户端
@Configuration public class RedissonConfig { @Bean public Redisson redisson(){ Config config =new Config(); config.useSingleServer() .setAddress("redis://192.168.179.130:6379") .setPassword("123456") //redis默认有16个数据库 .setDatabase(0); return (Redisson) Redisson.create(config); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4. 使用Redission的分布式锁
package com.aaa.service.impl; import com.aaa.domain.Product; import com.aaa.mapper.ProductMapper; import com.aaa.service.ProductService; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import org.redisson.Redisson; import org.redisson.api.RLock; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.stereotype.Service; import java.util.concurrent.TimeUnit; /** * @author : 尚腾飞(838449693@qq.com) * @version : 1.0 * @createTime : 2022/10/27 23:17 * @description : */ @Service public class ProductServiceImpl extends ServiceImpl<ProductMapper, Product> implements ProductService { @Autowired private ProductMapper productMapper; @Autowired private Redisson redisson; @Autowired private StringRedisTemplate stringRedisTemplate; @Override public Integer buyById(int id) { //1.使用redis设置分布式锁 /*ValueOperations- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
里面带有redis解决设置分布式锁的步骤,只需要把关于redisson的三个步骤注释掉,把redis的两个步骤放开就可以了。
三、redis常见的面试题
1. redis支持的数据类型。常见的有五种
常用:
- string字符串类型 2.hash 哈希类型 3.list队列类型 4.set集合类型 5.sort set有序集合。
不常用: - stream流 HyperLogLog超文本日志类型(估算) Bitmaps
2. redis持久化方式。
- RDB:快照模式,在一定的时间间隔内,对redis数据进行快照存储。
- AOF:日志追加。当我们执行写操作时,通过write函数把写命令追加到日志中。
3. redis如何解决单机故障。—搭建redis集群。
- 主从模式
- 哨兵模式
- 网状模式。(三主三从)
4. redis淘汰策略。
如果redis内存满足,在添加新的数据。
- volatile-lru:从已设置过期时间的数据集(server. db[i]. expires)中挑选最近最少使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集(server. db[i]. expires)中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集(server. db[i]. expires)中任意选择数据淘汰。
- allkeys-lru:从数据集(server. db[i]. dict)中挑选最近最少使用的数据淘汰。
- allkeys-random:从数据集(server. db[i]. dict)中任意选择数据淘汰。
- no-enviction(驱逐):禁止,驱逐数据
5. redis如何实现分布式锁。
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可
6. redis实现分布式锁的缺陷。
Redis 分布式锁不能解决超时的问题,分布式锁有一个超时时间,程序的执行如果超出了锁的超时时间就会出现问题
7. redis的使用场景
- 作为缓存
- 可以完成分布锁
- 完成分布式session的共享。
8. 有没有碰到缓存穿透,如何解决缓存穿透。
- 什么是缓存穿透?
所谓的缓存穿透就是在数据库中不存在该数据,缓存中也不存在该数据,这时有大量的请求,访问这种数据,这样就是把所有的请求交于数据库处理,造成数据库压力过大。从而导致数据库宕机。 - 如何解决缓存穿透。
- 缓存一个空对象。而且该对象设置的过期时间不能太长。一般不能超过5分钟。
- 设置布隆过滤器。它就是一个很多的bitMaps数组,里面存放了数据库表中所有数据的id. 如果查询的数据在bitmap中不存在,则该数据一定不会存在。则无需再查询数据库。
//布隆过滤器钟存储的是数据库表钟对应的id String get(String key) { //先从缓存获取。 String value = redis.get(key); //缓存没有命中 if (value == null) { //查看布隆过滤器钟是否存在 if(!bloomfilter.mightContain(key)){ return null; }else{ //查询数据库 value = db.get(key); redis.set(key, value); } } return value; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
相关阅读:
【RabbitMQ】介绍及消息收发流程
Scala安装使用
excel表格转pdf格式的方法介绍
集群路径规划学习(一)之EGO-swarm仿真
生产业务环境下部署 Kubernetes 高可用集群的步骤
Hadoop相关
【hadoop】纠删码技术详解
Qt编写视频监控系统67-录像计划(支持64通道7*24录像设置)
【初阶与进阶C++详解】第十三篇:继承
Eureka详解
- 原文地址:https://blog.csdn.net/qq_60969145/article/details/127576199
