-
acm拿国奖的第二关:栈和队列
目录
在数组中,可以通过索引访问随机元素。 但是,某些情况下,可能需要限制处理的顺序。
一,队列:先入先出的数据结构
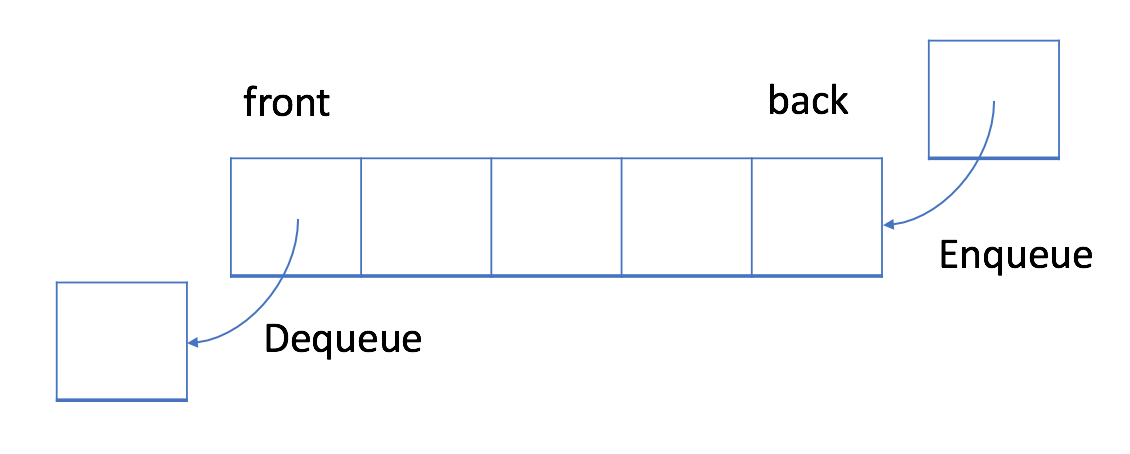
插入(insert)操作也称作入队(enqueue),新元素始终被添加在队列的末尾。 删除(delete)操作也被称为出队(dequeue)。 你只能移除第一个元素。
下面是我给出的关于队列入队出队的动图:
1,队列的实现:
为了实现队列,我们可以使用动态数组和指向队列头部的索引。
如上所述,队列应支持两种操作:入队和出队。入队会向队列追加一个新元素,而出队会删除第一个元素。 所以我们需要一个索引来指出起点。
- #include <iostream>
- class MyQueue {
- private:
- // store elements
- vector<int> data;
- // a pointer to indicate the start position
- int p_start;
- public:
- MyQueue() {p_start = 0;}
- /** Insert an element into the queue. Return true if the operation is successful. */
- bool enQueue(int x) {
- data.push_back(x);
- return true;
- }
- /** Delete an element from the queue. Return true if the operation is successful. */
- bool deQueue() {
- if (isEmpty()) {
- return false;
- }
- p_start++;
- return true;
- };
- /** Get the front item from the queue. */
- int Front() {
- return data[p_start];
- };
- /** Checks whether the queue is empty or not. */
- bool isEmpty() {
- return p_start >= data.size();
- }
- };
- int main() {
- MyQueue q;
- q.enQueue(5);
- q.enQueue(3);
- if (!q.isEmpty()) {
- cout << q.Front() << endl;
- }
- q.deQueue();
- if (!q.isEmpty()) {
- cout << q.Front() << endl;
- }
- q.deQueue();
- if (!q.isEmpty()) {
- cout << q.Front() << endl;
- }
- }
2,缺点
上面的实现很简单,但在某些情况下效率很低。 随着起始指针的移动,浪费了越来越多的空间。 当我们有空间限制时,这将是难以接受的。

让我们考虑一种情况,即我们只能分配一个最大长度为 5 的数组。当我们只添加少于 5 个元素时,我们的解决方案很有效。 例如,如果我们只调用入队函数四次后还想要将元素 10 入队,那么我们可以成功。
但是我们不能接受更多的入队请求,这是合理的,因为现在队列已经满了。但是如果我们将一个元素出队呢?

实际上,在这种情况下,我们应该能够再接受一个元素。
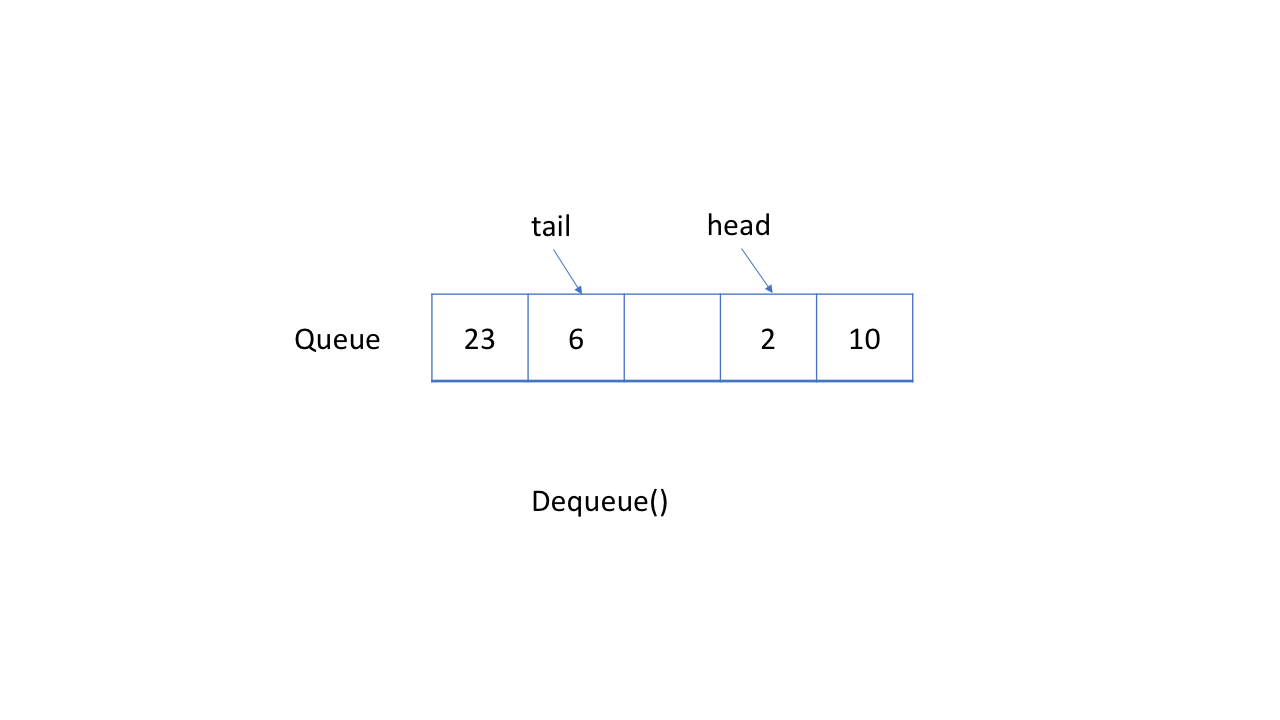
3,循环队列
此前,我们提供了一种简单但低效的队列实现。
更有效的方法是使用循环队列。 具体来说,我们可以使用固定大小的数组和两个指针来指示起始位置和结束位置。 目的是重用我们之前提到的被浪费的存储。
让我们通过一个动图来查看循环队列的工作原理。 你应该注意我们入队或出队元素时使用的策略。
4,循环队列的实现
- class MyCircularQueue {
- private:
- vector<int> data;
- int head;
- int tail;
- int size;
- public:
- /** Initialize your data structure here. Set the size of the queue to be k. */
- MyCircularQueue(int k) {
- data.resize(k);
- head = -1;
- tail = -1;
- size = k;
- }
- /** Insert an element into the circular queue. Return true if the operation is successful. */
- bool enQueue(int value) {
- if (isFull()) {
- return false;
- }
- if (isEmpty()) {
- head = 0;
- }
- tail = (tail + 1) % size;//此操作可以使tail从尾部到头部。
- data[tail] = value;
- return true;
- }
- /** Delete an element from the circular queue. Return true if the operation is successful. */
- //删除操作这里并不需要有删除的代码,因为循环队列的访问是从head到tail,后面会直接覆盖掉
- bool deQueue() {
- if (isEmpty()) {
- return false;
- }
- if (head == tail) {
- head = -1;
- tail = -1;
- return true;
- }
- head = (head + 1) % size;
- return true;
- }
- /** Get the front item from the queue. */
- int Front() {
- if (isEmpty()) {
- return -1;
- }
- return data[head];
- }
- /** Get the last item from the queue. */
- int Rear() {
- if (isEmpty()) {
- return -1;
- }
- return data[tail];
- }
- /** Checks whether the circular queue is empty or not. */
- bool isEmpty() {
- return head == -1;
- }
- /** Checks whether the circular queue is full or not. */
- bool isFull() {
- return ((tail + 1) % size) == head;
- }
- };
- /**
- * Your MyCircularQueue object will be instantiated and called as such:
- * MyCircularQueue obj = new MyCircularQueue(k);
- * bool param_1 = obj.enQueue(value);
- * bool param_2 = obj.deQueue();
- * int param_3 = obj.Front();
- * int param_4 = obj.Rear();
- * bool param_5 = obj.isEmpty();
- * bool param_6 = obj.isFull();
- */
5,队列的操作
大多数流行语言都提供内置的队列库,因此您无需重新发明轮子。
如前所述,队列有两个重要的操作,入队 enqueue 和出队 dequeue。 此外,我们应该能够获得队列中的第一个元素,因为应该首先处理它。
- #include
- int main() {
- // 1. Initialize a queue.
- queue<int> q;
- // 2. Push new element.
- q.push(5);
- q.push(13);
- q.push(8);
- q.push(6);
- // 3. Check if queue is empty.
- if (q.empty()) {
- cout << "Queue is empty!" << endl;
- return 0;
- }
- // 4. Pop an element.
- q.pop();
- // 5. Get the first element.
- cout << "The first element is: " << q.front() << endl;
- // 6. Get the last element.
- cout << "The last element is: " << q.back() << endl;
- // 7. Get the size of the queue.
- cout << "The size is: " << q.size() << endl;
- }
6,循环队列的长度
(tail - front + maxsize)% maxsize
二,队列和广度优先搜索
先决条件:树的层序遍历
广度优先搜索(BFS)是一种遍历或搜索数据结构(如树或图)的算法。
如前所述,我们可以使用 BFS 在树中执行层序遍历。
我们也可以使用 BFS 遍历图。例如,我们可以使用 BFS 找到从起始结点到目标结点的路径,特别是最短路径。
我们可以在更抽象的情景中使用 BFS 遍历所有可能的状态。在这种情况下,我们可以把状态看作是图中的结点,而以合法的过渡路径作为图中的边。
本章节中,我们将简要介绍 BFS 是如何工作的,并着重关注队列如何帮助我们实现 BFS 算法。我们还将提供一些练习,供你自行设计和实现 BFS 算法。
1,队列和BFS
广度优先搜索(BFS)的一个常见应用是找出从根结点到目标结点的最短路径。在本文中,我们提供了一个示例来解释在 BFS 算法中是如何逐步应用队列的。
观看上面的动画后,让我们回答以下问题:
1)结点的处理顺序是什么?
在第一轮中,我们处理根结点。在第二轮中,我们处理根结点旁边的结点;在第三轮中,我们处理距根结点两步的结点;等等等等。
与树的层序遍历类似,越是接近根结点的结点将越早地遍历。
如果在第 k 轮中将结点 X 添加到队列中,则根结点与 X 之间的最短路径的长度恰好是 k。也就是说,第一次找到目标结点时,你已经处于最短路径中。
2)队列的入队和出队顺序是什么?
如上面的动画所示,我们首先将根结点排入队列。然后在每一轮中,我们逐个处理已经在队列中的结点,并将所有邻居添加到队列中。值得注意的是,新添加的节点不会立即遍历,而是在下一轮中处理。
结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出(FIFO)。这就是我们在 BFS 中使用队列的原因。
2,BFS的实现
直接给例题:
例题1:岛屿数量
200. 岛屿数量 - 力扣(LeetCode)
 https://leetcode.cn/problems/number-of-islands/
https://leetcode.cn/problems/number-of-islands/
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 11,则将其加入队列,开始进行广度优先搜索。在广度优先搜索的过程中,每个搜索到的 11 都会被重新标记为 00。直到队列为空,搜索结束。
最终岛屿的数量就是我们进行广度优先搜索的次数。
- class Solution {
- public:
- int numIslands(vector
- int nr = grid.size();
- if (!nr) return 0;
- int nc = grid[0].size();
- int num_islands = 0;
- for (int r = 0; r < nr; ++r) {
- for (int c = 0; c < nc; ++c) {
- if (grid[r][c] == '1') {
- ++num_islands;
- grid[r][c] = '0';
- queue
- neighbors.push({r, c});
- while (!neighbors.empty()) {
- auto rc = neighbors.front();
- neighbors.pop();
- int row = rc.first, col = rc.second;
- if (row - 1 >= 0 && grid[row-1][col] == '1') {
- neighbors.push({row-1, col});
- grid[row-1][col] = '0';
- }
- if (row + 1 < nr && grid[row+1][col] == '1') {
- neighbors.push({row+1, col});
- grid[row+1][col] = '0';
- }
- if (col - 1 >= 0 && grid[row][col-1] == '1') {
- neighbors.push({row, col-1});
- grid[row][col-1] = '0';
- }
- if (col + 1 < nc && grid[row][col+1] == '1') {
- neighbors.push({row, col+1});
- grid[row][col+1] = '0';
- }
- }
- }
- }
- }
- return num_islands;
- }
- };
复杂度分析
时间复杂度:O(MN),其中 MM 和 NN 分别为行数和列数。
空间复杂度:O(min(M,N)),在最坏情况下,整个网格均为陆地,队列的大小可以达到 min(M,N)。
例题2:打开转盘锁
752. 打开转盘锁 - 力扣(LeetCode)
https://leetcode.cn/problems/open-the-lock/
我们可以使用广度优先搜索,找出从初始数字 0000 到解锁数字 target 的最小旋转次数。
具体地,我们在一开始将 (0000,0) 加入队列,并使用该队列进行广度优先搜索。在搜索的过程中,设当前搜索到的数字为 \textit{status}status,旋转的次数为 step,我们可以枚举 status 通过一次旋转得到的数字。设其中的某个数字为 next_status,如果其没有被搜索过,我们就将(next_status,step+1) 加入队列。如果搜索到了 target,我们就返回其对应的旋转次数。
为了避免搜索到死亡数字,我们可以使用哈希表存储deadends 中的所有元素,这样在搜索的过程中,我们可以均摊 O(1) 地判断一个数字是否为死亡数字。同时,我们还需要一个哈希表存储所有搜索到的状态,避免重复搜索。
如果搜索完成后,我们仍没有搜索到 target,说明我们无法解锁,返回 −1。
细节
本题中需要注意如下两个细节:
如果target 就是初始数字 0000,那么直接返回答案 0;
如果初始数字 0000 出现在 deadends 中,那么直接返回答案 −1。
- class Solution {
- public:
- int openLock(vector
& deadends, string target) { - if (target == "0000") {
- return 0;
- }
- unordered_set
dead(deadends.begin(), deadends.end()) ; - if (dead.count("0000")) {
- return -1;
- }
- auto num_prev = [](char x) -> char {
- return (x == '0' ? '9' : x - 1);
- };
- auto num_succ = [](char x) -> char {
- return (x == '9' ? '0' : x + 1);
- };
- // 枚举 status 通过一次旋转得到的数字
- auto get = [&](string& status) -> vector
{ - vector
ret; - for (int i = 0; i < 4; ++i) {
- char num = status[i];
- status[i] = num_prev(num);
- ret.push_back(status);
- status[i] = num_succ(num);
- ret.push_back(status);
- status[i] = num;
- }
- return ret;
- };
- queue
- q.emplace("0000", 0);
- unordered_set
seen = {"0000"}; - while (!q.empty()) {
- auto [status, step] = q.front();
- q.pop();
- for (auto&& next_status: get(status)) {
- if (!seen.count(next_status) && !dead.count(next_status)) {
- if (next_status == target) {
- return step + 1;
- }
- q.emplace(next_status, step + 1);
- seen.insert(move(next_status));
- }
- }
- }
- return -1;
- }
- };
三,栈:后入先出的数据结构

通常,插入操作在栈中被称作入栈 push 。与队列类似,总是在堆栈的末尾添加一个新元素。但是,删除操作,退栈 pop ,将始终删除队列中相对于它的最后一个元素。
1,栈的实现
- #include
- class MyStack {
- private:
- vector<int> data; // store elements
- public:
- /** Insert an element into the stack. */
- void push(int x) {
- data.push_back(x);
- }
- /** Checks whether the queue is empty or not. */
- bool isEmpty() {
- return data.empty();
- }
- /** Get the top item from the queue. */
- int top() {
- return data.back();
- }
- /** Delete an element from the queue. Return true if the operation is successful. */
- bool pop() {
- if (isEmpty()) {
- return false;
- }
- data.pop_back();
- return true;
- }
- };
- int main() {
- MyStack s;
- s.push(1);
- s.push(2);
- s.push(3);
- for (int i = 0; i < 4; ++i) {
- if (!s.isEmpty()) {
- cout << s.top() << endl;
- }
- cout << (s.pop() ? "true" : "false") << endl;
- }
- }
2,栈的用法
大多数流行的语言都提供了内置的栈库,因此你不必重新发明轮子。除了初始化,我们还需要知道如何使用两个最重要的操作:入栈和退栈。除此之外,你应该能够从栈中获得顶部元素。下面是一些供你参考的代码示例:
- #include
- int main() {
- // 1. Initialize a stack.
- stack<int> s;
- // 2. Push new element.
- s.push(5);
- s.push(13);
- s.push(8);
- s.push(6);
- // 3. Check if stack is empty.
- if (s.empty()) {
- cout << "Stack is empty!" << endl;
- return 0;
- }
- // 4. Pop an element.
- s.pop();
- // 5. Get the top element.
- cout << "The top element is: " << s.top() << endl;
- // 6. Get the size of the stack.
- cout << "The size is: " << s.size() << endl;
- }
例题1:有效的括号
20. 有效的括号 - 力扣(LeetCode)
https://leetcode.cn/problems/valid-parentheses/
判断括号的有效性可以使用「栈」这一数据结构来解决。
我们遍历给定的字符串 s。当我们遇到一个左括号时,我们会期望在后续的遍历中,有一个相同类型的右括号将其闭合。由于后遇到的左括号要先闭合,因此我们可以将这个左括号放入栈顶。
当我们遇到一个右括号时,我们需要将一个相同类型的左括号闭合。此时,我们可以取出栈顶的左括号并判断它们是否是相同类型的括号。如果不是相同的类型,或者栈中并没有左括号,那么字符串 ss 无效,返回 \text{False}False。为了快速判断括号的类型,我们可以使用哈希表存储每一种括号。哈希表的键为右括号,值为相同类型的左括号。
在遍历结束后,如果栈中没有左括号,说明我们将字符串 s 中的所有左括号闭合,返回 True,否则返回 False。
注意到有效字符串的长度一定为偶数,因此如果字符串的长度为奇数,我们可以直接返回 False,省去后续的遍历判断过程。
- class Solution {
- public:
- bool isValid(string s) {
- int n = s.size();
- if (n % 2 == 1) {
- return false;
- }
- unordered_map<char, char> pairs = {
- {')', '('},
- {']', '['},
- {'}', '{'}
- };
- stack<char> stk;
- for (char ch: s) {
- if (pairs.count(ch)) {
- if (stk.empty() || stk.top() != pairs[ch]) {
- return false;
- }
- stk.pop();
- }
- else {
- stk.push(ch);
- }
- }
- return stk.empty();
- }
- };
复杂度分析
时间复杂度:O(n),其中 n 是字符串 s 的长度。
空间复杂度:O(n+∣Σ∣),其中 Σ 表示字符集,本题中字符串只包含 6 种括号,∣Σ∣=6。栈中的字符数量为 O(n),而哈希表使用的空间为 O(∣Σ∣),相加即可得到总空间复杂度。
四,栈和深度优先搜索
先决条件:树的遍历
与 BFS 类似,深度优先搜索(DFS)是用于 在树/图中遍历/搜索 的另一种重要算法。也可以在更抽象的场景中使用。
正如树的遍历中所提到的,我们可以用 DFS 进行 前序遍历,中序遍历 和 后序遍历。在这三个遍历顺序中有一个共同的特性:除非我们到达最深的结点,否则我们永远不会回溯 。
这也是 DFS 和 BFS 之间最大的区别,BFS永远不会深入探索,除非它已经在当前层级访问了所有结点。
通常,我们使用递归实现 DFS。栈在递归中起着重要的作用。在本章中,我们将解释在执行递归时栈的作用。我们还将向你展示递归的缺点,并提供另一个 没有递归 的 DFS 实现。
在准备面试时,DFS 是一个重要的话题。DFS 的实际设计因题而异。本章重点介绍栈是如何在 DFS 中应用的,并帮助你更好地理解 DFS 的原理。要精通 DFS 算法,还需要大量的练习。

观看上面的动画后,让我们回答以下问题:
1. 结点的处理顺序是什么?
在上面的例子中,我们从根结点 A 开始。首先,我们选择结点 B 的路径,并进行回溯,直到我们到达结点 E,我们无法更进一步深入。然后我们回溯到 A 并选择第二条路径到结点 C 。从 C 开始,我们尝试第一条路径到 E 但是 E 已被访问过。所以我们回到 C 并尝试从另一条路径到 F。最后,我们找到了 G。
总的来说,在我们到达最深的结点之后,我们只会回溯并尝试另一条路径。
因此,你在 DFS 中找到的第一条路径并不总是最短的路径。例如,在上面的例子中,我们成功找出了路径 A-> C-> F-> G 并停止了 DFS。但这不是从 A 到 G 的最短路径。
2. 栈的入栈和退栈顺序是什么?
如上面的动画所示,我们首先将根结点推入到栈中;然后我们尝试第一个邻居 B 并将结点 B 推入到栈中;等等等等。当我们到达最深的结点 E 时,我们需要回溯。当我们回溯时,我们将从栈中弹出最深的结点,这实际上是推入到栈中的最后一个结点。
结点的处理顺序是完全相反的顺序,就像它们被添加到栈中一样,它是后进先出。这就是我们在 DFS 中使用栈的原因。
例题1:岛屿数量(同上)
我们可以将二维网格看成一个无向图,竖直或水平相邻的 1 之间有边相连。
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则以其为起始节点开始进行深度优先搜索。在深度优先搜索的过程中,每个搜索到的 1 都会被重新标记为 00。
最终岛屿的数量就是我们进行深度优先搜索的次数。
下面的动画展示了整个算法。
- class Solution {
- private:
- void dfs(vector<vector<char>>& grid, int r, int c) {
- int nr = grid.size();
- int nc = grid[0].size();
- grid[r][c] = '0';
- if (r - 1 >= 0 && grid[r-1][c] == '1') dfs(grid, r - 1, c);
- if (r + 1 < nr && grid[r+1][c] == '1') dfs(grid, r + 1, c);
- if (c - 1 >= 0 && grid[r][c-1] == '1') dfs(grid, r, c - 1);
- if (c + 1 < nc && grid[r][c+1] == '1') dfs(grid, r, c + 1);
- }
- public:
- int numIslands(vector<vector<char>>& grid) {
- int nr = grid.size();
- if (!nr) return 0;
- int nc = grid[0].size();
- int num_islands = 0;
- for (int r = 0; r < nr; ++r) {
- for (int c = 0; c < nc; ++c) {
- if (grid[r][c] == '1') {
- ++num_islands;
- dfs(grid, r, c);
- }
- }
- }
- return num_islands;
- }
- };
复杂度分析
时间复杂度:O(MN),其中 M 和 N 分别为行数和列数。
空间复杂度:O(MN),在最坏情况下,整个网格均为陆地,深度优先搜索的深度达到 MN。
-
相关阅读:
Springboot2.x开启跨域配置详解
springboot的自动配置原理步骤
传奇GOM引擎登录器配置教程
达梦数据库整合在springboot的使用教程
金融的本质是什么?
Arch Linux 安装简明流程
2022级大学新生-电脑推荐
javaweb高校实验室管理系统ssm
Shopee活动名称怎么填写好?Shopee活动名称设置注意事项——站斧浏览器
redis List常用命令整理
- 原文地址:https://blog.csdn.net/m0_63309778/article/details/127532221
 https://pic.leetcode-cn.com/44b3a817f0880f168de9574075b61bd204fdc77748d4e04448603d6956c6428a-%E5%87%BA%E5%85%A5%E9%98%9F.gif
https://pic.leetcode-cn.com/44b3a817f0880f168de9574075b61bd204fdc77748d4e04448603d6956c6428a-%E5%87%BA%E5%85%A5%E9%98%9F.gif
 https://pic.leetcode-cn.com/Figures/circular_queue/Slide60.png
https://pic.leetcode-cn.com/Figures/circular_queue/Slide60.png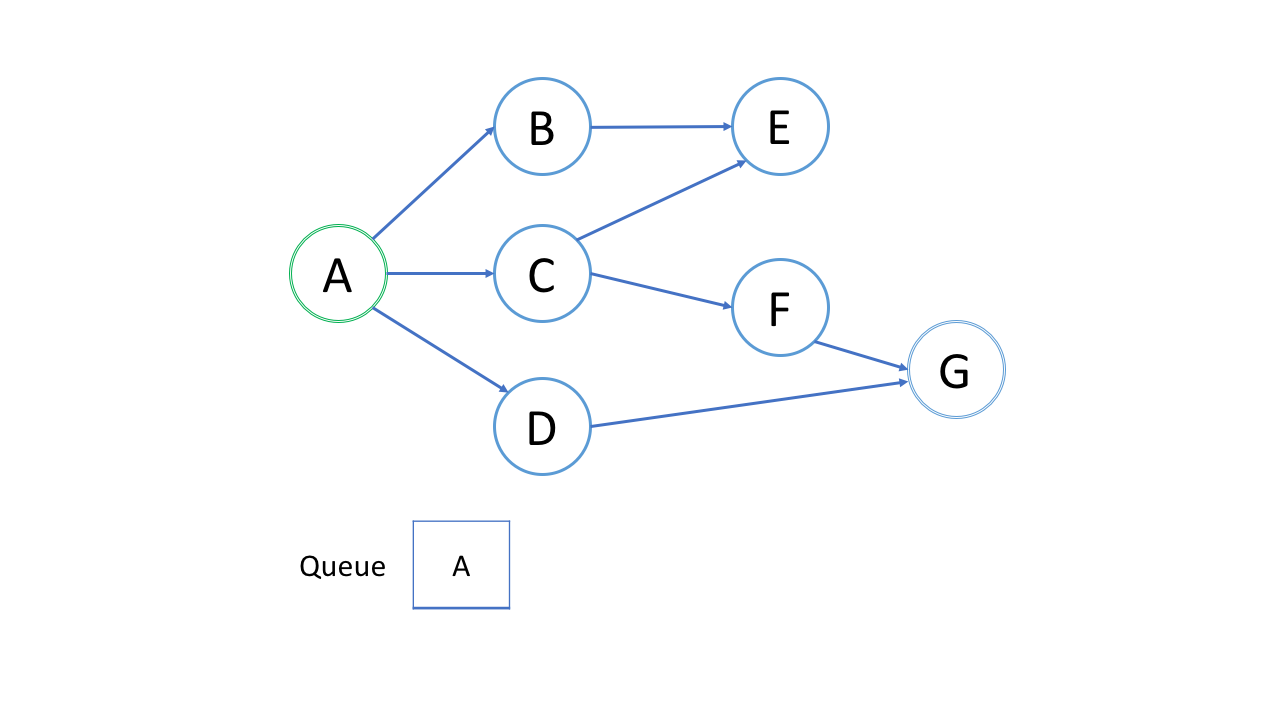 https://pic.leetcode-cn.com/Figures/bfs/Slide01.png
https://pic.leetcode-cn.com/Figures/bfs/Slide01.png https://pic.leetcode-cn.com/691e2a8cca120acb18e77379c7cd7eec3835c8c102d1c699303f50accd1e09df-%E5%87%BA%E5%85%A5%E6%A0%88.gif
https://pic.leetcode-cn.com/691e2a8cca120acb18e77379c7cd7eec3835c8c102d1c699303f50accd1e09df-%E5%87%BA%E5%85%A5%E6%A0%88.gif https://pic.leetcode-cn.com/5dae0de2a06f4eae5113f9cadfa5c51bbcf0b9347c5861aa73c93d7bc1d50b34-image.png
https://pic.leetcode-cn.com/5dae0de2a06f4eae5113f9cadfa5c51bbcf0b9347c5861aa73c93d7bc1d50b34-image.png