-
python selenium参数详解和案例实现
无头模式添加,可以让selenium模拟登录,进入到后台运行
这里以登录打开公司内网下载数据为例,因为涉及私密问题,所以有些地方我们进行覆盖,还请谅解
先不添加无头模式,进行登录,并且下载文件
因为一般selenium使用的是之前版本的浏览器,所以会出现以下情况,需要进行安全认证,所以可以进行直接忽略认证书的错误

一般是在selenium的options进行添加options.add_argument('ignore-certificate-errors')- 1


可以看到上面有很多目录点击过来的,要求下载所有的含有日报的excel,需进行小框选择后,才会出现下载按钮

下载一般是直接下载到浏览器默认的地址,这里我们可以进行自主修改,还是在options里进行配置,函数如下
# 设置默认地址 prefs = {'download.default_directory': r'D:\desktop\test_download'} options.add_experimental_option('prefs', prefs)- 1
- 2
- 3
完整代码如下
# 导入所需要的库 import time import json import warnings from selenium import webdriver from sqlalchemy import create_engine from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 运行时terminal里面会出现好多警告,剔除警告 warnings.filterwarnings('ignore') class Download(): def __init__(self, url, year, path, chrome, username, password, elements): self.year = year self.url = url self.path = path self.chrome = chrome self.username = username self.password = password self.elements = elements # 浏览器设置 def web_sets(self): self.options = webdriver.ChromeOptions() # 因为我使用的是谷歌浏览器 self.c_service = Service(f'{self.chrome}') self.c_service.command_line_args() # 设置后端服务器开始,因为会在后台产生好多服务,为了后面的关闭 self.c_service.start() # 提供默认下载地址 self.prefs = {'download.default_directory': f'{self.path}'} self.options.add_experimental_option('prefs', self.prefs) # 设置忽略安全证书所带来的错误 self.options.add_argument('ignore-certificate-errors') # 一些小的设置 self.options.add_experimental_option('excludeSwitches', ["enable-automation"]) self.options.add_argument('--np-sanbox') self.options.add_argument('--disable-dev-shm-usage') # 加属性避免bug self.options.add_argument('disable-gpu') # 添加无头模式 self.options.add_argument('headless') self.br = webdriver.Chrome(f'{self.chrome}', chrome_options=self.options) self.br.implicitly_wait(3) def loginPage(self): """ 因为我是将所有元素保存在json文件里面,这样就不需要因为find_element而占用好多列 也为代码节省地方 这里需要强调的时find_element(By.XPATH)是最新selenium的使用方法,之前的使用会报错 """ self.br.get(self.url) time.sleep(4) self.br.find_element(By.XPATH, f'{self.elements[keys[2]]}').send_keys(self.username) time.sleep(2) self.br.find_element(By.XPATH, f'{self.elements[keys[3]]}').send_keys(self.password) time.sleep(2) self.br.find_element(By.XPATH, f'{self.elements[keys[4]]}').click() time.sleep(2) # 设置跳转到最后页面 def skipPage(self, url): self.br.get(url) time.sleep(2) # 下载文件 def download_excel(self): # 获取所有ul下面的li标签个数 ul2 = self.br.find_element(By.XPATH, f'{self.elements[keys[6]]}') # 获取li标签数目 lis2 = ul2.find_elements(By.XPATH, 'li') time.sleep(1) # 循环li标签 for j in range(len(lis2)): # 因为li的elements都是从1开始,python列表是从0开始,所以要+1 j+=1 # 获取li标签的text name = self.br.find_element(By.XPATH, f'{self.elements[keys[7]][1]}'%j).get_attribute('title') print(f'li标签name: {name}') if '日报' in name: print(f'第二遍过滤name: {name}') li_test = self.br.find_element(By.XPATH, f'{self.elements[keys[8]]}'%j) self.br.execute_script('arguments[0].click();',li_test) time.sleep(0.5) self.br.find_element(By.XPATH, f'{self.elements[keys[9]]}').click() time.sleep(0.5) li_test2 = self.br.find_element(By.XPATH, f'{self.elements[keys[8]]}'%j) time.sleep(1) # 设置点击覆盖,以防止报错 # 因为一直要模拟点击选择文件,然后进行下载文件,防止点击覆盖 self.br.execute_script("arguments[0].click();", li_test2) time.sleep(8) time.sleep(10) time.sleep(12) # 退出浏览器,推出后台服务 # c_service.stop()对应之前的c_service.stop() self.br.quit();self.c_service.stop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
JSON文件

ul标签的展示

li标签下的title

在这里顺便讲下如何获取xpath的绝对路径或者相对路径


展示下ul标签相对路径和绝对路径xpath: //*[@id="main"]/div[2]/div/div[3]/div[1]/as-dataview/div[2]/ul full_xpath: /html/body/div[2]/div[1]/div[2]/div/div[1]/div[2]/div/div[3]/div[1]/as-dataview/div[2]/ul- 1
- 2
下图是没有c_service.stop(),后台运行服务,不能进行关闭

运行代码
if __name__ == '__main__': jsonFile = r'JsonFile\elements.json' with open(jsonFile, 'r') as f: row_data = json.load(f) # 获取所有json的键 keys = list(row_data.keys()) # 读取账号和密码 filename = row_data[keys[0]] # 获取账号和密码txt with open(filename, 'r') as f: data = f.read() data1 = data.split('\n') url = 'url' # chromedriver.exe chrome = r'chromedriver.exe' username = data1[0] password = data1[1] path = row_data[keys[1]] year = time.gmtime().tm_year start = Download(url, year, path, chrome, username, password, row_data) start.web_sets() start.loginWeb() e = row_data[keys[5]] start.skipPage(e) start.download_excel() time.sleep(15)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
为了展示出来 取消掉无头模式 这样可以看到浏览器进行下载
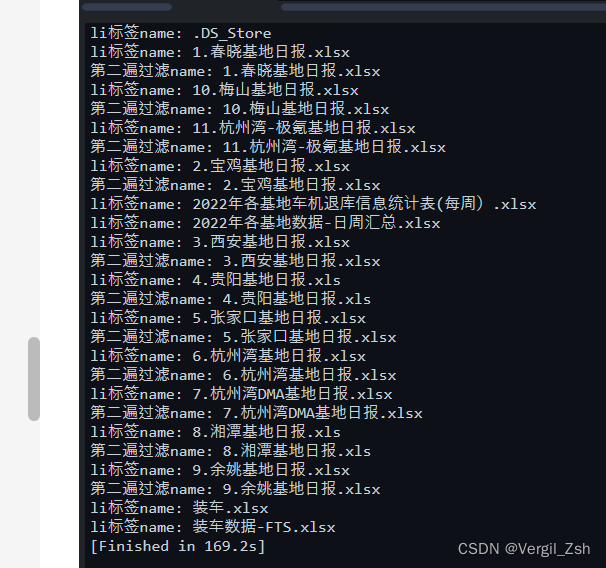

可以看到只有含有’日报’的数据被下载了,并且任务管理器里面没有刚才出现的Chrome32的服务

如果有不懂得欢迎随时来问,或者有不同见解的欢迎随时讨论 -
相关阅读:
Spring AOP:面向切面编程
qt 多语言版本 QLinguist使用方法
C++ 基础:指针和引用浅谈
Mac上使用FFmpeg
设计模式之迭代器模式
【Unity编辑器扩展】| GameView面板扩展
【索引】常见的索引、B+树结构、什么时候需要使用索引、优化索引方法、索引主要的数据结构、聚簇索引、二级索引、创建合适的索引等重点知识汇总
Java多线程【三种实现方法】
Bigemap软件在农业行业中的应用
判断期末挂科问题
- 原文地址:https://blog.csdn.net/KIKI_ZSH/article/details/127493820
