-
梯度下降法公式推导+实战--以一元、多元线性回归为例-猛男技术控
梯度下降法
理论部分
梯度
设函数 z = f ( x , y ) z=f(x,y) z=f(x,y) 在平面区域 D D D内具有一阶连续偏导数,则对于每一点 p ( x , y ) ϵ D p\left ( x,y \right )\epsilon D p(x,y)ϵD,都可定出一个向量 ∂ f ∂ x i → + ∂ f ∂ y j → \frac{\partial f}{\partial x}\,\,\overrightarrow{i}+\frac{\partial f}{\partial y}\,\,\overrightarrow{j} ∂x∂fi+∂y∂fj ,这个向量称为函数 z = f ( x , y ) z=f(x,y) z=f(x,y) 在点 p ( x , y ) p ( x , y ) p(x,y)的梯度,记作 g r a d f ( x , y ) gradf(x,y) gradf(x,y),即
g r a d f ( x , y ) = ∂ f ∂ x i → + ∂ f ∂ y j → gradf(x,y) = \frac{\partial f}{\partial x}\,\,\overrightarrow{i}+\frac{\partial f}{\partial y}\,\,\overrightarrow{j} gradf(x,y)=∂x∂fi+∂y∂fj
设 e l → = c o s φ i → + s i n φ j → \overrightarrow{e_{l}} = cos\varphi\overrightarrow{i}+sin\varphi \overrightarrow{j} el=cosφi+sinφj 为 l l l方向的单位向量(其中 φ \varphi φ 为 x x x 轴到方向 l l l 的转角),则由方向导数的计算公式可知∂ f ∂ l = ∂ f ∂ x cos φ + ∂ f ∂ y sin φ = { ∂ f ∂ x , ∂ f ∂ y } ⋅ { cos φ , sin φ } = grad f ( x , y ) ⋅ e l
∂l∂f=∂x∂fcosφ+∂y∂fsinφ={∂x∂f,∂y∂f}⋅{cosφ,sinφ}=gradf(x,y)⋅el∂ f ∂ l = ∂ f ∂ x cos φ + ∂ f ∂ y sin φ = { ∂ f ∂ x , ∂ f ∂ y } ⋅ { cos φ , sin φ } = grad f ( x , y ) ⋅ e l
方向导数的大小为:
∣ ∂ f ∂ l ∣ = ∣ grad f ( x , y ) ∣ ⋅ cos [ grad f ( x , y ) ∧ , e l ] |\frac{\partial f}{\partial l}| =|\operatorname{grad} f(x, y)| \cdot \cos \left[\operatorname{grad} f(x,y)^{\wedge}, e_{l}\right] ∣∂l∂f∣=∣gradf(x,y)∣⋅cos[gradf(x,y)∧,el][ grad f ( x , y ) ∧ , e l ] [\operatorname{grad} f(x,y)^{\wedge}, e_{l}] [gradf(x,y)∧,el]表示梯度与 l l l 的夹角。
由于当方向I与梯度方向一致时, 有 c o s [ gradf ( x , y ) , e ] = 1 cos [\operatorname{gradf}(x, y), e]=1 cos[gradf(x,y),e]=1
所以当 l l l与梯度方向一致时, 方向导数 ∂ f ∂ l \frac{\partial f}{\partial l} ∂l∂f有最大值, 且最大值为梯度的模, 即
∣ grad f ( x , y ) ∣ = ( ∂ f ∂ x ) 2 + ( ∂ f ∂ y ) 2 |\operatorname{grad} f(x, y)|=\sqrt{\left(\frac{\partial f}{\partial x}\right)^{2}+\left(\frac{\partial f}{\partial y}\right)^{2}} ∣gradf(x,y)∣=(∂x∂f)2+(∂y∂f)2
因此说, 函数在一点沿梯度方向的变化率最大, 最大值为该梯度的模。所以,沿梯度方向的方向导数达到最大值,也就是说,梯度方向是函数 z = f ( x , y ) z=f(x,y) z=f(x,y) 在这点增长最快的方向。因此,可以得到如下结论:
函数在某点的梯度是一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
一般来说,函数 z = f ( x , y ) z=f(x,y) z=f(x,y) 在几何上表示一个曲面,这个曲面被平面 z = c z=c z=c ( c c c是常数)所截得的曲线 l l l的方程为:
{ z = f ( x , y ) z = c{z=f(x,y)z=c{ z = f ( x , y ) z = c 这条曲线 l l l在 x O y xOy xOy平面上的投影是平面曲线 L ∗ L^{*} L∗ ,它在$xOy 平面直角坐标系中的方程为 平面直角坐标系中的方程为 平面直角坐标系中的方程为f(x,y)=c$。曲线 L ∗ L^{*} L∗上的任意点,函数值都是 c c c,所以称平面曲线 L ∗ L^{*} L∗为函数 z = f ( x , y ) z=f(x,y) z=f(x,y)的等高线。由于等高线 f ( x , y ) = c f(x,y)=c f(x,y)=c上任意点 ( x , y ) (x,y) (x,y)处的法线的斜率为:
− 1 d y d x = − 1 ( − f x f y ) = f y f x -\frac{1}{\frac{dy}{dx}}=-\frac{1}{\left ( -\frac{f_{x}}{f_{y}} \right )}=\frac{f_{y}}{f_{x}} −dxdy1=−(−fyfx)1=fxfy
所以梯度
g r a d f ( x , y ) = ∂ f ∂ x i → + ∂ f ∂ y j → gradf(x,y) = \frac{\partial f}{\partial x}\overrightarrow{i}+\frac{\partial f}{\partial y}\overrightarrow{j} gradf(x,y)=∂x∂fi+∂y∂fj
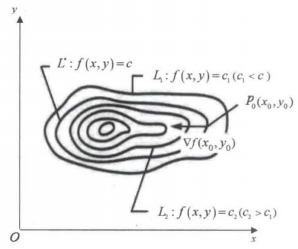
为等高线上点 ( x , y ) (x,y) (x,y) 处的法向量,因此可得到梯度与等高线的关系如下。如图所示,图中显示了6条等高线,在等高线 f ( x , y ) = c f(x,y)=c f(x,y)=c 上有一点 ( x 0 , y 0 ) \left ( x_{0},y_{0} \right ) (x0,y0)可以看出点 ( x 0 , y 0 ) \left ( x_{0},y_{0} \right ) (x0,y0) 的切线与法线垂直。图中 c 2 > c > c 1 c_{2}>c>c_{1} c2>c>c1
( x 0 , y 0 ) \left ( x_{0},y_{0} \right ) (x0,y0)点的法线方向与梯度 ▽ f ( x 0 , y 0 ) \triangledown f\left ( x_{0},y_{0} \right ) ▽f(x0,y0)相同。
我们求一元函数极小值时要先求一阶导数为0的点,然后带入就是极小值了(注意是极小值不是最小值)。
对于多元函数:设 n \mathrm{n} n元函数 f ( x ) f(\boldsymbol{x}) f(x) 对自变量 x = ( x 1 , x 2 , … , x n ) T \boldsymbol{x}=\left(x_{1}, x_{2}, \ldots, x_{n}\right)^{T} x=(x1,x2,…,xn)T 的各分量 x i x_{i} xi的偏导数 ∂ f ( x ) ∂ x i ( i = 1 , 2 , … , n ) \frac{\partial f(\boldsymbol{x})}{\partial x_{i}}(i=1,2, \ldots, n) ∂xi∂f(x)(i=1,2,…,n)都存在,则称函数 f ( x ) f(\boldsymbol{x}) f(x) 在 x \boldsymbol{x} x 处一阶可导, 并称向量
∇ f ( x ) = ( ∂ f ( x ) ∂ x 1 ∂ f ( x ) ∂ x 2 ⋮ ∂ f ( x ) ∂ x n ) \nabla f(\boldsymbol{x})=\left(
\right) ∇f(x)=⎝ ⎛∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)⎠ ⎞∂ f ( x ) ∂ x 1 ∂ f ( x ) ∂ x 2 ⋮ ∂ f ( x ) ∂ x n
为函数 f ( x ) f(\boldsymbol{x}) f(x) 在 x \boldsymbol{x} x 处的一阶导数或梯度, 记为 ∇ f ( x ) \nabla f(\boldsymbol{x}) ∇f(x)(列向量)梯度的本意是一个向量(一个函数的全部偏导数构成的向量),表示某一函数在该点处方向导数沿着该方向取得的最大值,即函数沿梯度的方向变化最快,变化率最大(为该梯度的模)。
在曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,即梯度下降最快的方向,这样可以有效的找到全局的最优解。
切线、法线、梯度区分
对于平面 F ( x , y ) = x 2 + y 2 F(x, y) = x^2+y^2 F(x,y)=x2+y2我们取 c = 4 c=4 c=4的一条等高线,画出其法向量(梯度)及切线。
红色箭头:法向量(梯度)
蓝色箭头:切线(图中只画出一个方向,蓝色箭头旋转180度也是切线方向)
梯度下降
凸优化问题同一表述为求函数极小值问题,遇到求极大值时,在目标函数前面加个负号,从而转为极小值问题求解。
目标函数的自变量x往往受到各种约束,满足约束条件的自变量x的集合称为自变量的可行域。
梯度下降是一种逐步迭代,逐步缩减损失函数值,从而使损失函数最小的方法。
在直观上,我们可以这样理解,看下图,一开始的时候我们随机站在一个点(初始化参数),把他看成一座山,每一步,我们都以下降最多的路线方向(负梯度方向)来下山,那么,在这个过程中我们到达山底(最优点)是最快的,而上面的a,它决定了我们“向下山走”时每一步的大小,过小的话收敛太慢,过大的话可能错过最小值)。这是一种很自然的算法,每一步总是寻找使J下降“陡”的方向(就像找最快下山的路一样)。
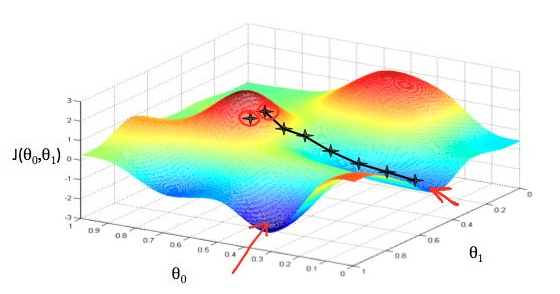
然后就是确定步长,下山的起始点和每一步的反向知到了,那么一步该走多长呢?
如果步长太大,虽然能快速逼近山谷,但可能跨过了山谷,造成来回震荡;如果太小则可能延长了到达山谷底部的时间。

每次走多大的距离,就是所谓的学习率,如何设置学习率需要反复调试很吃工程师的经验。
梯度下降的迭代公式如下:
θ 1 = θ 0 − α ∇ J ( θ ) \theta^1=\theta^0-\alpha \nabla J(\theta) θ1=θ0−α∇J(θ)
其含义是:任意给定一组初始参数值 θ 0 \theta ^0 θ0,沿着损失函数, J ( θ ) J(\theta) J(θ) 的梯度下降方向前进一段距离 α \alpha α,就可以得到一组新的参数值 θ 1 \theta^1 θ1,这里的 θ 0 , θ 1 \theta^0,\,\theta^1 θ0,θ1,对应到中就是指模型参数(如w和b)。具体求解
最常用的一个损失函数:均方误差
J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ) − y ) 2 J(\theta)=\frac{1}{2}\sum_{i=1}^{m}({h_\theta(x)-y})^2 J(θ)=21i=1∑m(hθ(x)−y)2其中 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 . . . . + θ n x n h_θ(x)=θ_0+θ_1x_1+θ_{2}x_2....+θ_{n}x_n hθ(x)=θ0+θ1x1+θ2x2....+θnxn ,对该函数进行优化。用最小二乘法我们在一元线性回归中已经推过了,这里用梯度下降法来解。
先求 θ j \theta_j θj的偏导数:
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j 1 2 ( h θ ( x ) − y ) 2 = 2 ⋅ 1 2 ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( h θ ( x ) − y ) = ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( ∑ i = 0 n θ i x i − y ) = ( h θ ( x ) − y ) x j∂θj∂J(θ)=∂θj∂21(hθ(x)−y)2=2⋅21(hθ(x)−y)⋅∂θj∂(hθ(x)−y)=(hθ(x)−y)⋅∂θj∂(i=0∑nθixi−y)=(hθ(x)−y)xj∂ ∂ θ j J ( θ ) = ∂ ∂ θ j 1 2 ( h θ ( x ) − y ) 2 = 2 ⋅ 1 2 ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( h θ ( x ) − y ) = ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( ∑ i = 0 n θ i x i − y ) = ( h θ ( x ) − y ) x j
这样就确定了下降的方向:
θ j + 1 = θ j + α ∑ i = 1 m ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) \theta_{j+1}=\theta_{j}+\alpha \sum_{i=1}^{m}\left(y^{(i)}-h_{\theta}\left(x^{(i)}\right)\right) x_{j}^{(i)}\\ θj+1=θj+αi=1∑m(y(i)−hθ(x(i)))xj(i)
设 J ( θ ) = θ 1 2 + θ 2 2 J(\theta)=\theta_1^2+\theta_2^2 J(θ)=θ12+θ22,显然这个函数在 ( 0 , 0 ) (0,0) (0,0)处取得最小值。假设起始值 θ 0 = ( 4 , − 2 ) \theta^0=(4,-2) θ0=(4,−2),学习率 α = 0.1 \alpha=0.1 α=0.1, ∇ J ( θ ) = ( 2 θ 1 , 2 θ 2 ) \nabla J(\theta)=(2\theta_1,2\theta_2) ∇J(θ)=(2θ1,2θ2)。历次迭代结果看多元函数梯度下降代码
一元线性回归梯度下降计算
损失函数: M S E = 1 2 n ∑ i = 1 n ( y i − ( a x i + b ) ) 2 M S E=\frac{1}{2n} \sum_{i=1}^{n}\left(y_{i}-\left(a x_{i}+b\right)\right)^{2} MSE=2n1∑i=1n(yi−(axi+b))2
求偏导: ∂ ∂ a = 1 n ∑ i = 1 n − x i ( y i − ( a x i + b ) ) \frac{\partial}{\partial a}=\frac{1}{n} \sum_{i=1}^{n}-x_{i}\left(y_{i}-\left(a x_{i}+b\right)\right) ∂a∂=n1∑i=1n−xi(yi−(axi+b))
求偏导: ∂ ∂ b = 1 n ∑ i = 1 n − ( y i − ( a x i + b ) ) \frac{\partial}{\partial b}=\frac{1}{n} \sum_{i=1}^{n}-\left(y_{i}-\left(a x_{i}+b\right)\right) ∂b∂=n1∑i=1n−(yi−(axi+b))
更新
a = a − l r ∗ ∂ ∂ a a= a- lr * \frac{\partial}{\partial a} a=a−lr∗∂a∂
b = b − l r ∗ ∂ ∂ b b= b - lr * \frac{\partial}{\partial b} b=b−lr∗∂b∂
# 自己随机生成一些数值,y在6x+8 加减2上下波动 x = np.linspace(-5, 5, 100) y = 6*x + 8 + np.random.rand(100)*4 - 2 # 6和8是我们要求的两个参数,先随机设两个 a = 9 b = 5 epoch = 2000 lr = 0.001 n = len(y) loss_s = [] for i in range(epoch): y_hat = a*x+b # 损失函数 loss = np.sum((y-a*x-b)**2)/(2*n) loss_s.append(loss) a_grad = -sum(x*(y-a*x-b))/n b_grad = -sum(y-a*x-b)/n a = a - a_grad*lr b = b - b_grad*lr if loss<0.1: break print(a,b,loss) plt.scatter(x,y) plt.plot(x,a*x+b,'r')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5.998694400518917 7.5501502371548375 0.7433293359973534 [] - 1
- 2
- 3
- 4
- 5
- 6
- 7

看另一个应用,求函数的最小值
# 自定义一个函数 y = (x-1)^2-1 plot_x = np.linspace(-10, 10., 200) plot_y = (plot_x-1)**2 - 1. # 当两次迭代的距离 小于epsilon时停止迭代 epsilon = 1e-5 # 学习率 eta = 0.1 # 原函数,最小值为 -1 def J(x): return (x-1)**2 - 1. # 梯度 def dJ(x): return 2*(x-1) # 初始化 x np.random.randint(-10,10) x = -8 # 记录每次的x x_history = [x] # 记录每次的loss loss_s = [] # 迭代 while True: # 求x点上的梯度值 gradient = dJ(x) last_x = x # 沿着梯度的反方向更新 x x = x - eta * gradient x_history.append(x) # 如果这组theta计算出的结果与真实结果相差很小,停止更新 loss = abs(J(x) - J(last_x)) # 这里损失用到L1范数,直接用绝对值 loss_s.append(loss) if(loss < epsilon): break plt.figure(figsize=(10,8)) plt.plot(plot_x, J(plot_x),) plt.plot(np.array(x_history), J(np.array(x_history)), color="r", marker='o') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42

多元线性回归的梯度下降法
公式推导中推出更新公式为:
θ j + 1 = θ j + α ∑ i = 1 m ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) \theta_{j+1}=\theta_{j}+\alpha \sum_{i=1}^{m}\left(y^{(i)}-h_{\theta}\left(x^{(i)}\right)\right) x_{j}^{(i)}\\ θj+1=θj+αi=1∑m(y(i)−hθ(x(i)))xj(i)# 加载数据并展示 def load_data(): data = pd.read_csv("多变量线性数据.csv") x1 = data.iloc[:,0] x2 = data.iloc[:,1] y = data.iloc[:,-1] return x1,x2, y x1,x2,y = load_data() # 可以看到两个变量和y呈线性关系,可以将模型看为二元线性回归 plt.scatter(x1,y) plt.scatter(x2,y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

# 随机定义w1 w2 b w1 = 1 w2 = 2 b = 3 # 学习率 eta = 0.1 # 原函数: y = w1 *x1+w2*x2+b n = len(y) # 记录每次的loss loss_s=[] lr=0.01 # 迭代 for _ in range(6000): y_hat = w1*x1 + w2*x2 + b # 计算损失 loss = np.sum((y -y_hat)**2)/(2*n) loss_s.append(loss) # 计算w1、w2、b的梯度 grad_w1 = -np.mean((y- y_hat)*x1) grad_w2 = -np.mean((y-y_hat)*x2) grad_b = -np.mean(y-y_hat) # 更新 w1 = w1 - lr*grad_w1 w2 = w2 - lr*grad_w2 b = b - lr*grad_b if(loss < 0.1): break print(w1,w2,b,loss)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.6655418442482928 2.3048272679297424 -28.614578205795805 0.09990036401069977- 1
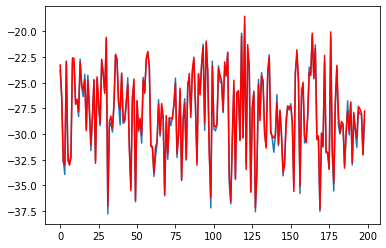
plt.plot(range(len(y)),y) plt.plot(range(len(y)),w1*x1 + w2*x2 + b,'r') # 可以看到训练出来的模型与真实值大致吻合,但精度不如用最小二乘法的好,当然加大训练次数,or修改lr效果会好一些- 1
- 2
- 3
本文档由jupyter notebook导出,获取notebook文档原码与相关数据集关注公众号:猛男技术控 回复
AI基础 -
相关阅读:
【环境配置】Windows10上的OpenFace安装与使用
快速串联 RNN / LSTM / Attention / transformer / BERT / GPT(未完待续)
typescript84-事件类型
RPC模型(未完成)
深入理解element-wise add与concat特征图的连接方式
ESP8266-Arduino编程实例-SHT31温度湿度传感器驱动
内网渗透代理转发详解及工具介绍
CAS号:1676104-79-2
【踩坑记录】centOS上部署的web环境本机能访问而其他机器访问不了
Linux中常用的软件:Squid
- 原文地址:https://blog.csdn.net/weixin_45755332/article/details/127552449
