-
Spark系列—Spark SQL执行过程解析
今天来讲讲spark-sql的执行计划,有助于我们理解spark的运行原理。
一、简述
日常我们使用spark时,主要是通过写sql语句嵌套在Python或者Shell脚本中提交到spark集群,了解spark-sql的运行方式有助于我们更好的使用spark。
二、Spark-sql的运行流程
用户提交的Application程序,先经过SQL Parser解析SQL语句,然后由Catalyst优化器处理,最后转化成Spark的RDD提交到Spark Cluster进行执行。如下图。
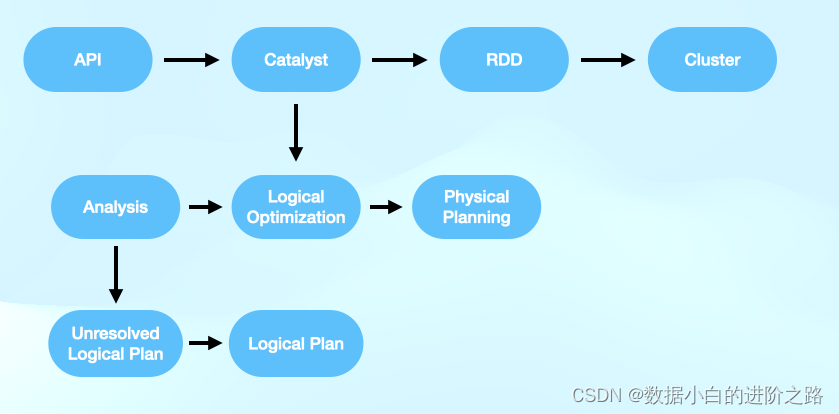
具体流程如下:
1、用户提交的Application首先会通过一些API读取SQL语句;
2、将读取的SQL代码经Antlr4解析,生成Unresolved Logical Plan。(个人理解Unresolved Logical Plan是指只是读取SQL代码并进行解析,并没有对SQL语法是否正确,表相关信息如列名,表名是否正确或存在并没有判断,因此被称为Unresolved);
3、访问Spark中Catalog存储的元数据信息验证表名、列名、语法、数据类型等信息是否正确,生成Resolved Logical Plan.
4、优化器Optimizer对Resolved Logical Plan优化,生成Optimized LogicalPlan;这个阶段的优化主要包括:
- 基于规则的优化(RBO)
基于规则的优化(RBO):
rule-base阶段的优化,主要是根据各种关系代数的优化规则对生成的Logical Plan进行优化,优化规则主要包括:简化布尔表达式、替换NULL值、常量折叠(Constant Folding)等。
5、Spark将Optimized LogicalPlan转换成Physical Plan;这一阶段的优化主要是:
- 基于代价的优化(CBO)
cost-base的优化,这一阶段会生成数个Physical Plan,通过cost model预估这些Physical Plan处理的性能,选择最优的一个Physical Plan。在这一步主要优化join操作,优化的逻辑是:在join时,会比较join两边的数据集的大小,以此选择使用MergeSort join、Broadcast join、Hash join等。
此时生成的的Physical Plan就是实际可执行的SparkPlan。
6、函数类prepareForExecution()将 Physical Plan 转换成 executed Physical Plan
7、execute()执行executed Physical Plan即物理执行计划,生成RDD,由Cluster运行。
总结:
Catalyst优化器是Spark SQL的核心;其优化原理主要分为以下几步:先对SQL代码进行解析,生成逻辑执行计划,然后使用Optimizer优化器对逻辑执行计划进行优化生成物理执行计划,最后生成可执行的代码提交spark集群以RDD的形式运行。
-
相关阅读:
华为手机安卓扫描安装包apk在哪
Tomcat运维以及优化
vue下载xlsx表格
宏offsetof的使用及其模拟实现
软件工程理论与实践 (吕云翔) 第十三章 软件测试方法与过程课后习题及其答案解析
助力交叉学科应用型数据科学人才培养,和鲸科技携手华为发布联合解决方案
git学习
ScrapeKit 和 Swift 编写程序
思科设备BGP配置命令
redis持久化之RDB (七)
- 原文地址:https://blog.csdn.net/weixin_37536446/article/details/127416533