-
天猫复购预测训练赛技术报告
天猫复购预测赛技术报告
小组成员:李xx、姚xx、黄xx、刘xxgithub地址:https://github.com/2017403603/Data_mining
一、问题描述
1.1 问题背景
商家有时会在特定日期,例如Boxing-day,黑色星期五或是双十一(11月11日)开展大型促销活动或者发放优惠券以吸引消费者,然而很多被吸引来的买家都是一次性消费者,这些促销活动可能对销售业绩的增长并没有长远帮助,因此为解决这个问题,商家需要识别出哪类消费者可以转化为重复购买者。通过对这些潜在的忠诚客户进行定位,商家可以大大降低促销成本,提高投资回报率。
1.2 数据描述
现在给定四个数据文件,分别为训练数据,测试数据,用户画像以及用户历史记录。训练数据提供纬度为用户、商家,以及该用户是否为该商家的重复购买者(即label)。用户画像数据集提供对应用户id的年龄和性别信息;用户历史记录提供用户过去六个月在不同店铺的多种活跃状态以及点击时间等;测试数据集为用户和商家的组合,用以预测该用户是否为该商家的重复购买者。
1.3 问题描述
根据给定的四个数据形式,在测试数据中给定了用户id和商家id的组合,需要预测该名用户在对应商家的重复购买概率值。
二、数据探索
2.1 加载数据集
train_data = pd.read_csv("../DataMining/data_format1/train_format1.csv") test_data = pd.read_csv("../DataMining/data_format1/test_format1.csv") user_info = pd.read_csv("../DataMining/data_format1/user_info_format1.csv") user_log = pd.read_csv("../DataMining/data_format1/user_log_format1.csv")- 1
- 2
- 3
- 4
2.2 查看用户画像中年龄和性别缺失率
(user_info.shape[0] - user_info["age_range"].count())/user_info.shape[0] (user_info.shape[0] - user_info["gender"].count()) / user_info.shape[0]- 1
- 2
其中年龄缺失率为0.52%,性别缺失率为1.5%。缺失比率较小,因此其对最终的分类结果影响较小。后面将直接将NaN(由-1代替)当作特征输入进模型进行训练和学习
2.3 查看用户信息数据的缺失—用户行为日志数据缺失
user_log.isna().sum()- 1

用户行为日志主要缺失特征为购买品牌的缺失,其他特征均无缺失。
2.4 查看用户画像和历史记录基本数据描述
user_info.describe()- 1

用户画像的基本数据分析显示用户的平均年龄在30岁左右,且方差较大。且购买者的性别主要为女性。
user_log.describe()- 1

2.5 查看样本label比例

样本不均衡,非重复购买者比例远远大于重复购买者,因此需要采取一定措施解决此类样本不平衡问题
2.6 对top 5店铺进行画图分析
train_data.merchant_id.value_counts().head(5) train_data_merchant["TOP5"]=train_data_merchant["merchant_id"].map(lambda x: 1 if x in[4044,3828,4173,1102,4976] else 0) train_data_merchant=train_data_merchant[train_data_merchant["TOP5"]==1] plt.figure(figsize=(8,6)) plt.title("Merchant VS Label")sax=sns.countplot("merchant_id",hue="label",data=train_data_merchant)- 1
- 2
- 3
- 4
- 5
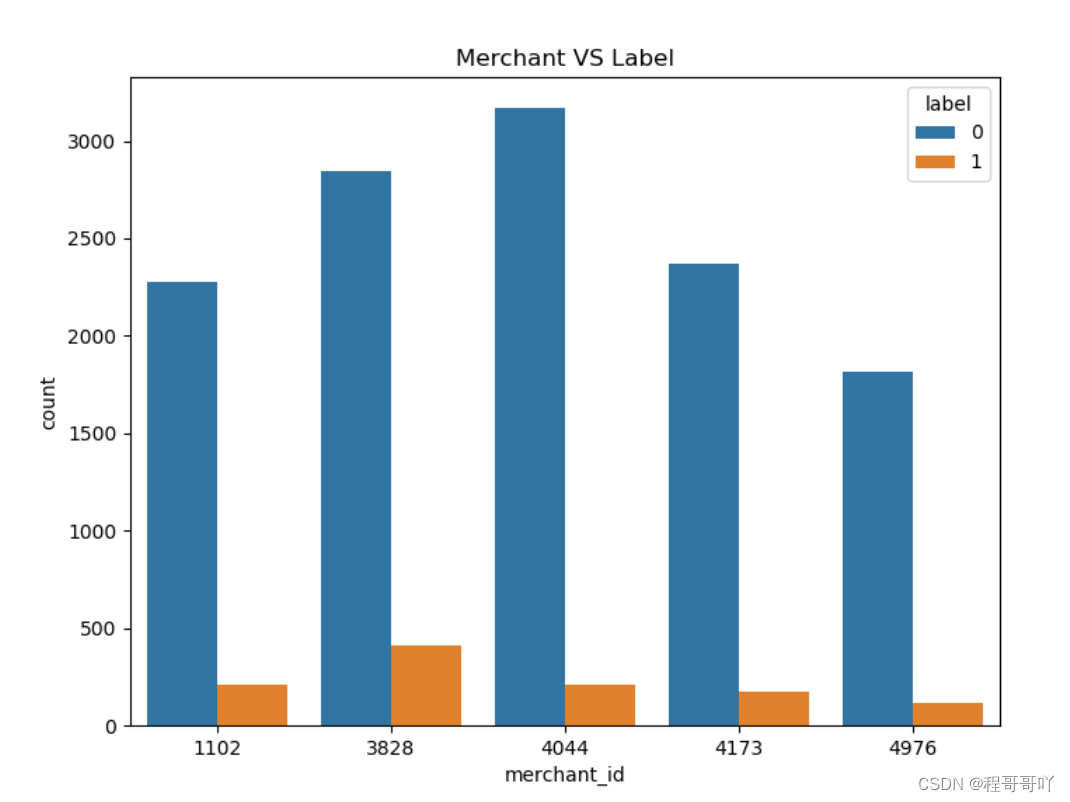
采用分布直方图对前五名店铺进行比例分析,可得前五名店铺占据了接近一半的数据量,且重复购买的比例都远远小于非重复购买
2.7 对商家的重复购买比例进行绘图分析
train_data.groupby(["merchant_id"])["label"].mean() merchant_repeat_buy=[rate for rate in train_data.groupby(["merchant_id"])["label"].mean() if rate<=1 and rate > 0] plt.figure(figsize=(8,4)) ax=plt.subplot(1,2,1) sns.distplot(merchant_repeat_buy,fit=stats.norm) ax=plt.subplot(1,2,2) res=stats.probplot(merchant_repeat_buy,plot=plt)- 1
- 2
- 3
- 4
- 5
- 6
- 7
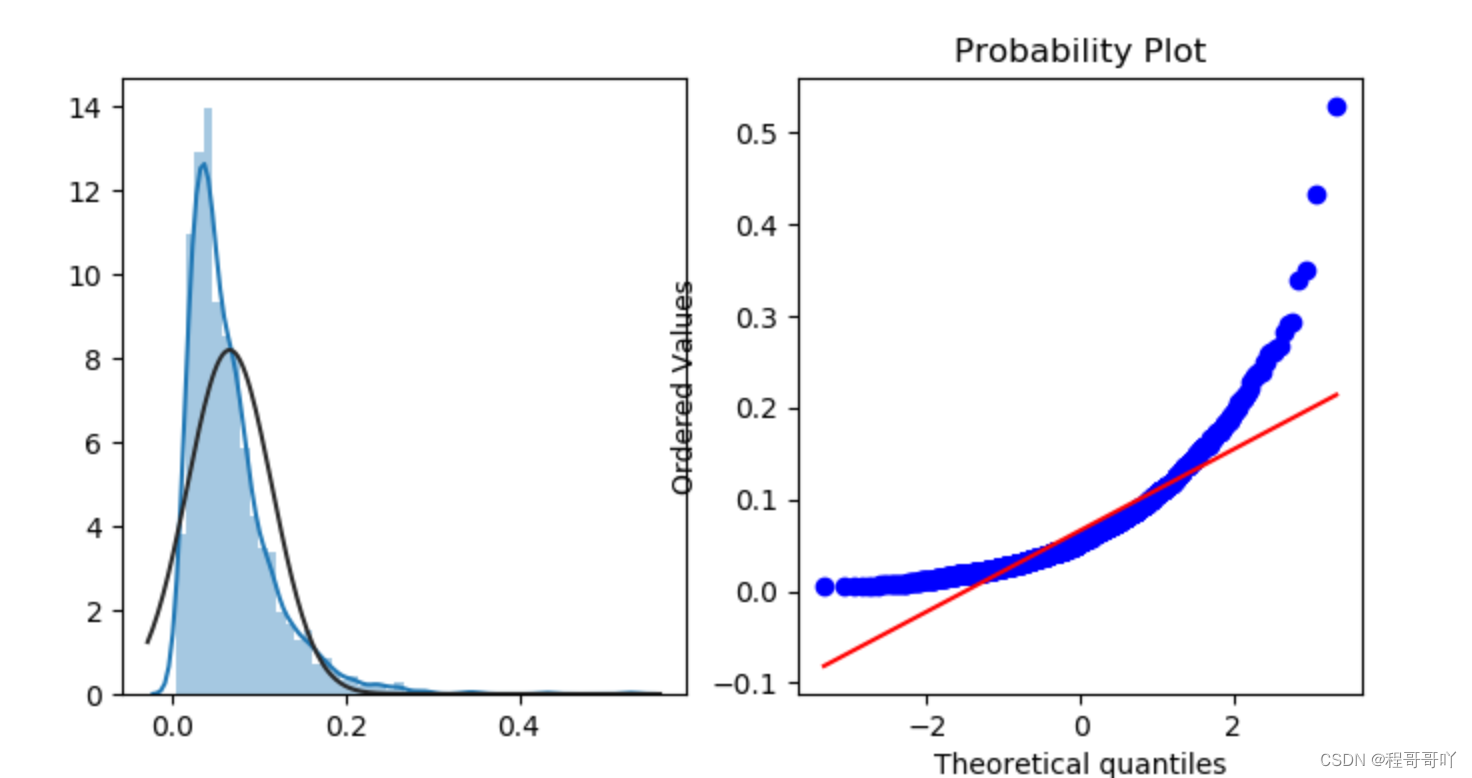
由于数据的特征维度并不具有连续性,无法使用插值法进行填补,并且空缺比率较小,因此我们直接将空缺数据视为一个特征,用-1填补并代表此类特征
三、特征工程
3.1 数据集合并
-
将训练集df_train和用户基本信息user_info_format.csv合并得到df_train,合并依据是用户user_id。
df_train = pd.merge(df_train,user_info,on="user_id",how="left")- 1
-
将df_train和用户行为日志user_log_format1.csv合并得到新的df_train,合并依据是用户user_id和商家merchant_id。
df_train = pd.merge(df_train,total_logs_temp,on=["user_id","merchant_id"],how="left")- 1
3.2 特征生成
-
通过简单合并生成特征
- 每个用户在每个商家交互过的商品总和(不分种类)。total_item_id
- 每个用户在每个商家交互过的商品种类总和。unique_item_id
- 每个用户在每个商家交互过的商品所属品类总和total_cat_id
- 每个用户在每个商家交互过的天数总和。total_time_temp
- 每个用户在每个商家点击次数总和。clicks
- 每个用户在每个商家加入购物车次数总和。shopping_cart
- 每个用户在每个商家购买商品次数总和。purchases
- 每个用户在每个商家收藏商品次数总和。favourites
-
通过分析生成特征
-
用户每月使用次数
month_temp=user_log.groupby(['user_id','month']).size().reset_index().rename(columns={0:'cnt'}) month_temp=pd.get_dummies(month_temp, columns=['month'],prefix='user_mcnt') for i in range(5,12): month_temp['user_mcnt_'+str(i)]=month_temp['cnt']*month_temp['user_mcnt_'+str(i)] month_temp=month_temp.groupby(['user_id']).sum().drop(['cnt'],axis=1).reset_index()- 1
- 2
- 3
- 4
- 5
意义:用户每月使用天猫的次数可以反映用户行为在时间上的特征,用户在一年中不同的月份的消费表现可能不同,例如在年尾,春节,“双十一”等期间可能消费水平高一些,在夏冬两季的消费水平可能会低一些,通过统计每月使用次数可以有效反映出这些特征。
-
商家的特征
temp = groups.size().reset_index().rename(columns={0:'merchantf1'}) matrix = matrix.merge(temp, on='merchant_id', how='left') temp = groups['user_id', 'item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(columns={'user_id':'merchantf2', 'item_id':'merchantf3', 'cat_id':'merchantf4', 'brand_id':'merchantf5'}) matrix = matrix.merge(temp, on='merchant_id', how='left') temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'merchantf6', 1:'merchantf7', 2:'merchantf8', 3:'merchantf9'}) matrix = matrix.merge(temp, on='merchant_id', how='left')- 1
- 2
- 3
- 4
- 5
- 6
商家售出的某个商品、品牌的数量,能够反映某些商品或者品牌的受欢迎程度,一定程度上也可以导致顾客回购率。
-
商家与用户的综合特征
matrix['ratiof1'] = matrix['userf9']/matrix['userf7'] # 用户购买点击比 matrix['ratiof2'] = matrix['merchantf8']/matrix['merchantf6'] # 商家购买点击比- 1
- 2
用户点击或者该商家被点击最终转化为顾客购买的比率能够很好的反映物品的受欢迎程度
-
四、候选模型简介
- 逻辑回归[1](Logistic Regression,LR)是一种广义线性回归(Generalized Linear Model),在机器学习中是最常见的一种用于二分类的算法模型。
- 决策树[2](Decision Tree,DT)是一种基本的分类与回归方法,本文主要讨论分类决策树,决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。
- 随机森林[3](Random Forest,RF)指的是利用多棵决策树对样本进行训练并预测的一种分类器,可回归可分类,所以随机森林是基于多颗决策树的一种集成学习算法。
- 梯度提升树[4](Gradient Descent Decision Tree,GBDT),梯度提升树是以 CART 作为基函数,采用加法模型和前向分步算法的一种梯度提升方法。
- XGBoost[5]是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
五、候选模型预测对比
5.1 加载训练数据和测试数据
#读取数据 df_train = pd.read_csv(r'df_train.csv') #加载最终测试数据 test_data= pd.read_csv(r'test_data.csv') test_data- 1
- 2
- 3
- 4
- 5

5.2 建模前预处理数据集
#建模前预处理 y = df_train["label"] X = df_train.drop(["user_id", "merchant_id", "label"], axis=1) X.head(10) #分割数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=8)- 1
- 2
- 3
- 4
- 5
- 6

5.3 候选模型预测:逻辑回归
#logistic回归 Logit = LogisticRegression(solver='liblinear') Logit.fit(X_train, y_train) Predict = Logit.predict(X_test) Predict_proba = Logit.predict_proba(X_test) print(Predict.shape) print(Predict[0:20]) print(Predict_proba[:]) Score = accuracy_score(y_test, Predict) Score- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

#逻辑回归最终结果获取 Logit_Ans_Predict_proba = Logit.predict_proba(test_data) df_test['prob']=Logit_Ans_Predict_proba[:,1] #最终答案保存 df_test.to_csv("Logit_Ans.csv",index=None)- 1
- 2
- 3
- 4
- 5
提交得到评分为:0.4564939
5.4 候选模型预测:决策树
#决策树 from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(max_depth=4,random_state=0) tree.fit(X_train, y_train) Predict_proba = tree.predict_proba(X_test) print(Predict_proba[:]) print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train))) print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

#决策树最终结果获取 Tree_Ans_Predict_proba = tree.predict_proba(test_data) df_test['prob']=Tree_Ans_Predict_proba[:,1] #最终答案保存 df_test.to_csv("Tree_Ans.csv",index=None)- 1
- 2
- 3
- 4
- 5
提交得到评分为:0.5833852
5.5 候选模型预测:随机森林
#随机森林 from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier(n_estimators=50,random_state=90,max_depth=5) rfc = rfc.fit(X_train, y_train) Predict_proba = rfc.predict_proba(X_test) print(Predict_proba[:]) print("Accuracy on training set: {:.3f}".format(rfc.score(X_train, y_train))) print("Accuracy on test set: {:.3f}".format(rfc.score(X_test, y_test)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

#随机森林最终结果获取 RFC_Ans_Predict_proba = rfc.predict_proba(test_data) df_test['prob']=RFC_Ans_Predict_proba[:,1] #最终答案保存 df_test.to_csv("RFC_Ans.csv",index=None)- 1
- 2
- 3
- 4
- 5
提交得到评分为:0.6252815
5.6 候选模型预测:随机森林调参
# 调参,绘制学习曲线来调参n_estimators(对随机森林影响最大) score_lt = [] # 每隔10步建立一个随机森林,获得不同n_estimators的得分 for i in range(0,200,10): print("进度:",i) rfc = RandomForestClassifier(n_estimators=i+1,random_state=90,max_depth=8) rfc = rfc.fit(X_train, y_train) score = rfc.score(X_test, y_test) score_lt.append(score) score_max = max(score_lt) print('最大得分:{}'.format(score_max),'子树数量为:{}'.format(score_lt.index(score_max)*10+1)) # 绘制学习曲线 x = np.arange(1,201,10) plt.subplot(111) plt.plot(x, score_lt, 'r-') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

上图中横坐标为参数n_estimators的值,纵坐标为模型在测试集上的准确率,每迭代一次n_estimators增加10,画出每次迭代准确率的折线图,由图可知当n_estimators=100时随机森林模型的效果最好,经调参后提交得到评分为:0.6256826。
5.7 候选模型预测:XGboost
import xgboost as xgb def xgb_train(X_train, y_train, X_valid, y_valid, verbose=True): model_xgb = xgb.XGBClassifier( max_depth=10, # raw8 n_estimators=1000, min_child_weight=300, colsample_bytree=0.8, subsample=0.8, eta=0.3, seed=42 ) model_xgb.fit( X_train, y_train, eval_metric='auc', eval_set=[(X_train, y_train), (X_valid, y_valid)], verbose=verbose, early_stopping_rounds=10 # 早停法,如果auc在10epoch没有进步就stop ) print(model_xgb.best_score) print("Accuracy on training set: {:.3f}".format(model.score(X_train, y_train))) print("Accuracy on test set: {:.3f}".format(model.score(X_test, y_test))) return model_xgb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

#XGboost最终结果获取 model_xgb = xgb_train(X_train, y_train, X_valid, y_valid, verbose=False) prob = model_xgb.predict_proba(test_data) submission['prob'] = pd.Series(prob[:,1]) submission.drop(['origin'], axis=1, inplace=True) submission.to_csv('submission_xgb.csv', index=False)- 1
- 2
- 3
- 4
- 5
- 6
提交得到评分为:0.6562986
六、最终成绩及排名
小组成员:李xx、姚xx、黄xx、刘xx
七、天猫复购预测总结
本次比赛最终成绩和排名并不是很高,思考其原因主要还是在数据预处理和特征工程阶段没有做好,在数据集中,年龄和性别的缺失值差不多有九万个,巨大的特征值数据缺失是预测准确率不高的主要原因之一,其次是特征工程,我们抽取特征的方法还是使用传统的方法,相对比较简单,这也是导致模型预测准确率不高的原因之一;在选用模型上我们使用了逻辑回归、决策树、随机森林、Xgboost等热门模型,训练后这些模型在训练集上的表现区别并不明显,经比较Xgboost模型在测试集的效果最好,后期工作准备再重新做一下特征工程,在模型选取方面,计划使用bagging集成多种分类算法的思想对模型进行改进,进一步提高预测准确率。
八、参考
[1] https://www.cnblogs.com/phyger/p/14188712.html
[2] https://blog.csdn.net/qq_34807908/article/details/81539536
[3] https://blog.csdn.net/lovenankai/article/details/99966142
[4] https://www.jianshu.com/p/d1f696266814
[5] http://cran.fhcrc.org/web/packages/xgboost/vignettes/xgboost.pdf
-
相关阅读:
数据结构作业:时间复杂度和二叉树
SQL 部分解释。
北邮22级信通院数电:Verilog-FPGA(9)第九周实验(1)实现带同步复位功能、采用上升沿触发的D触发器
聊聊HttpClient的DnsResolver
学习C语言的好处:
企业快速开发平台Spring Cloud+Spring Boot+Mybatis+ElementUI 之浅谈代码语言的魅力
我们的第一个 Qt 窗口程序
windows彻底卸载unity
STL中sort 用的是快排吗? - 快排、堆排(heap sort)、插入排序
C#:实现折半插入排序算法(附完整源码)
- 原文地址:https://blog.csdn.net/weixin_42200347/article/details/127455760
