-
经典论文《Efficient Estimation of Word Representations in Vector Space》学习笔记
阅读论文必备知识
论文
● 统计语言模型中的平滑操作
有一些词或词组在语料中没有出现过,但是这不能代表它不可能存在
平滑操作就是给那些没有出现过的词或者词组也给一个比较小的概率
● 平滑操作的问题
参数空间过大
数据稀疏严重
● 马尔科夫假设
下一个词的出现仅依赖于前面的一个词或几个词语言模型评价指标:困惑度语言模型是无监督的任务

●
softmax函数,指数操作,让数为正数,使它成为0到1之间
● batch问题,批次,补pad位,rnn可变长输入
● 语言模型评价指标

1.论文核心部分研读

1.1 word2vec的基本思想

1.2 skip-gram原理

首先映射成一个one-hot向量,与词向量矩阵相乘,得到1*D的词向量,再与周围词向量矩阵相乘,得到1*V向量,再经过softmax函数得到每个词的概率,通过索引知该词的概率,目标是要使该词的概率越大越好,再经过梯度反向传播,将w和w训练,一般取w或者w和w的平均值
输出层表达式: p ( w i − 1 ∣ w i ) = p(w_{i-1}|w_i)= p(wi−1∣wi)=
e x p ( u w i − 1 T v w i ) ∑ j = 1 V e x p ( u w T v w i ) \frac{exp(u_{w_{i-1}}^{T} v_{wi})}{\sum_{j=1}^{V} exp(u_{w}^{T}v_{wi} )} ∑j=1Vexp(uwTvwi)exp(uwi−1Tvwi)1.3 cbow原理(忽略词的顺序)

和上面过程类似,得到v个概率,再通过反向传播,进行梯度下降,得到词向量矩阵,
设e1,e2,e3,e4为上下文词,窗口为2 , v c , v j v_c,v_j vc,vj 为中心词向量,则 u 0 = s u m ( e 1 , e 2 , e 3 , e 4 ) u_0=sum(e_1,e_2,e_3,e_4) u0=sum(e1,e2,e3,e4)表示窗口内上下文词向量之和: p ( c ∣ o ) = p(c|o)= p(c∣o)=
e x p ( u 0 T v c ) ∑ j = 1 V e x p ( u 0 T v j ) \frac{exp(u_{0}^{T} v_c)}{\sum_{j=1}^{V} exp(u_{0}^{T}v_j )} ∑j=1Vexp(u0Tvj)exp(u0Tvc)1.4 word2vec关键技术:层次softmax和负采样
层次softmax:


2.previous model
2.1NNLM

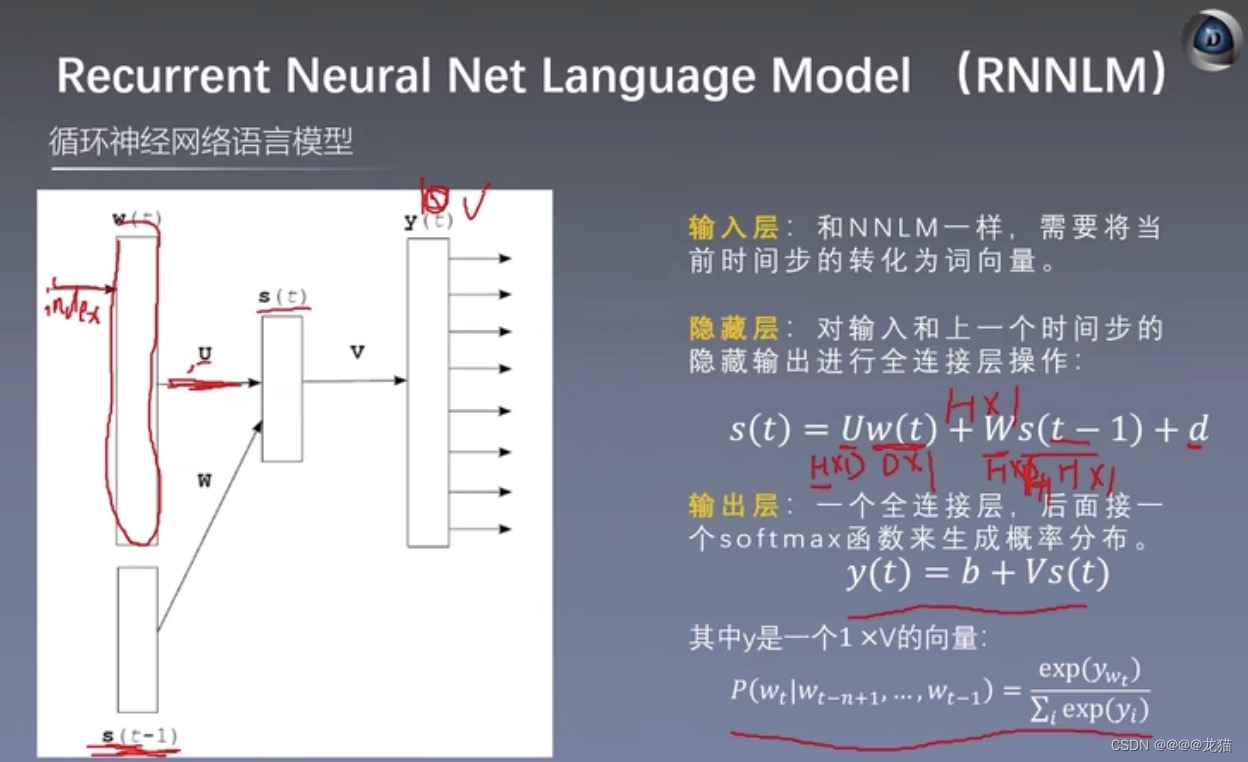
2.2RNNLM
-
相关阅读:
sequencer和sequence
数据结构与算法:二分查找(心得)
兼具高效与易用,融云 IM 即时通讯长连接协议设计思路
Go的性能优化建议
如何实现传统物业到智慧社区的转型?
公司招了一个腾讯拿30K的人,让我见识到了什么是天花板···
PMP模拟题 | 每日一练,快速提分
972信息检索 | 第七章 专类信息的检索
Greek Alphabet Letters & Symbols
OpenCvSharp从入门到实践-(06)创建图像
- 原文地址:https://blog.csdn.net/weixin_45768308/article/details/127453540