-
【精炼易懂】字符集、编码、乱码问题、ASCII、GBK、Unicode、UTF-8详解+实例说明
我在本文使用到的编码转换与查询工具(点击即可进入对应网站):
🏠 汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode (qqxiuzi.cn)
1.相关基础概念
1.1 位(bit)
位是计算机存储数据的
最小单位,1或者0就表示1位,如10010010就表示8位的二进制数。1.2 字节(byte)
字节是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。
1 B = 8 bit (1字节等于8位) 1 KB = 1024 B = 1024 字节 1 MB = 1024 KB 1 GB = 1024 MB 1 TB = 1024 GB- 1
- 2
- 3
- 4
- 5
1.3 字符
字符是指计算机中使用的字母、数字、字和符号,是数据结构中最小的数据存取单位。如a、A、B、b、大、+、*、%等都表示一个字符。
常见的字符集有:
ASCII字符集、GBK字符集、Unicode字符集等。1.4 字符集与编码字符集
字符集是指各种文字和符号的集合,包括各个国家文字、标点符号、图形符号、数字等。编码字符集是所有字符以及对应代码值的集合。编码字符集中的每个字符都对应一个唯一的十进制代码值。这些代码值就称为码点值(码值)(code point),可以看做字符在编码字符集中的编号。
其实我们并不用对
字符集与编码字符集做太大区分,编码字符集在概念上只是比字符集多了一个与码值的对应关系,在后面的讲解中我们提到的字符集都是指的编码字符集。像我们的
ASCII字符集中的字符a,对应的码值就是97。常见的字符集有
ASCII字符集、GBK字符集、GBxxxx字符集、Unicode字符集等。字符与码点值的对应关系是通过编码字符集规定好了的。
1.5 编码与解码
- 编码:把字符按照指定字符集编码成字节
- 解码:把字节按照指定字符集解码成字符
🚩 字符在计算机中的存储与读取:
- 存储:字符 --> 码值 --> 二进制 --> 存储
- 读取:二进制 --> 码值 --> 字符 --> 显示
1.6 字符编码方式
编码字符集中只规定了字符的代码值并未规定具体如何存储,字符编码方式解决了字符在计算机中如何存储的问题。
是将编码字符集中的字符代码值转换为实际的存储字节序列的一种映射规则。
常见的字符编码方式有
ASCII字符编码、GBK字符编码、UTF-32字符编码、UTF-8字符编码等。1.7 编码字符集与编码方式间对应关系
每种编码字符集至少对应一种字符编码方式,也可以对应多种编码方式。
📝 常见字符集与字符编码的对应关系:
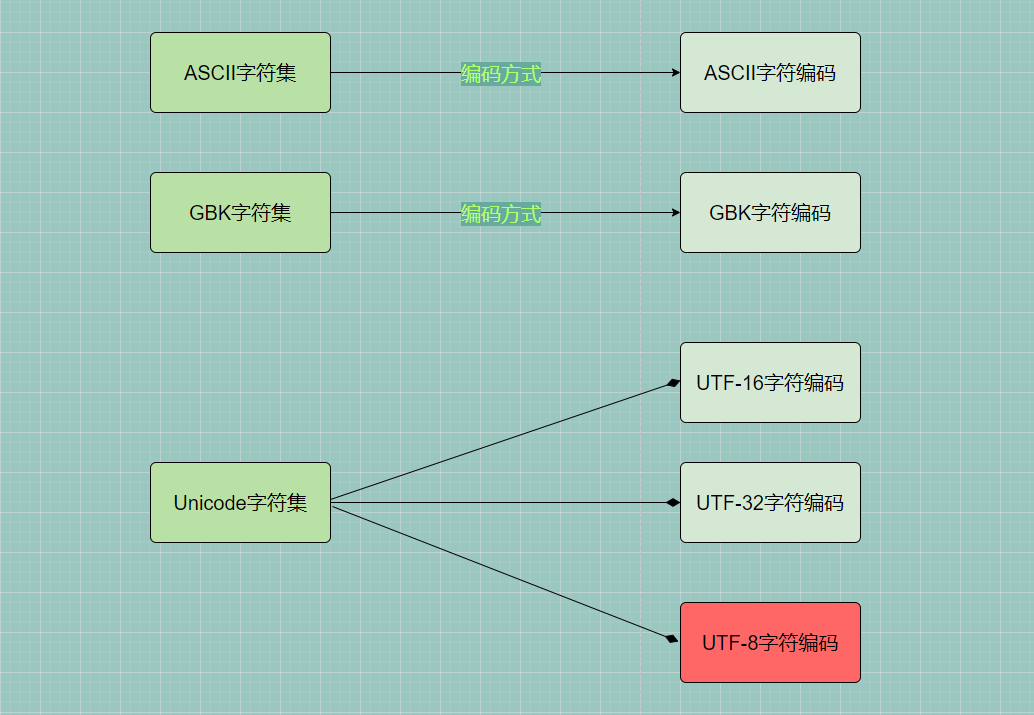
2.字符集的来历
计算机是美国人所发明,其目的是为了高效处理数据。但发明计算机时,必然面临一个问题——如何把他们国家的字符存放到计算机当中去。因为如果想让计算机处理信息,最起码要把自己的字符存到计算机中。那美国人要存放哪些字符呢?其实就是
英文字母(大小写)、数字、标点符号、特殊字符。❓ 但能够直接把这些字符存放到计算机底层吗?
肯定是不行的。因为计算机底层都是硬件,只能存储0和1二进制数据。为了让计算机能存储这些字符,于是对他们所用到的所有字符以
十进制方式进行编号,从0开始编,一直编到了127,总共128个字符。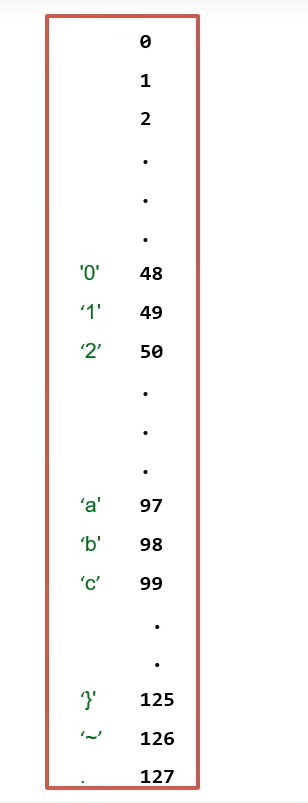
这些
编号我们又称为码点,将这套从0~127编码的字符集称为标准ASCII字符集。❓ 那 ASCII字符集 如何把这些字符存放到计算机底层呢?
实际上就是对这些码点(0~127)进行了
编码,实际上这个编码就是将码点转成二进制形式:
其实不难看出,码点从0~127只需要用
7位二进制数即可。而我们又知道,计算机底层最少是存储一个字节的,因此码点用了8位二进制数来表示,第8位(最高位)统一设置为 0。因此,ASCII字符集是使用一个字节来存储的。3.字符集与字符编码的发展
3.1 标准ASCII字符集
ASCII(American Standard Code for Information Interchange):美国信息交换标准代码,包括了英文、符号等。- 标准ASCII使用1个字节存储一个字符,首位是
0,总共可表示128个字符,对美国佬来说完全够用。
3.2 扩展ASCII
由于标准ASCII字符集字符有限,往往无法满足实际需求,因此国际标准组织制定了在与标准ASCII规范相兼容的前提下将ASCII字符集扩充为8位代码的方法。
每种扩充ASCII字符集可以扩充128个字符,这些扩充字符的编码均为最高位为1的8位代码。扩充的ASCII字符集即为扩展ASCII字符集,编码方式称为
扩展ASCII编码。编码方式:常见的一种扩展ASCII为ISO-8859-1(也称为
Latin-1)编码规范,用于支持部分欧洲语言。补充:在MySQL 8.0版本之前,默认字符集为
latin-1,utf8字符集指向的是utf8mb3。网站开发人员在数据库设计的时候往往会将编码修改为utf8字符集。如果遗忘修改默认的编码,就会出现乱码的问题。从MySQL 8.0开始,数据库的默认编码改为utf8mb4,从而避免了乱码问题。我们来看一下在
MySQL5.7中的默认字符集编码: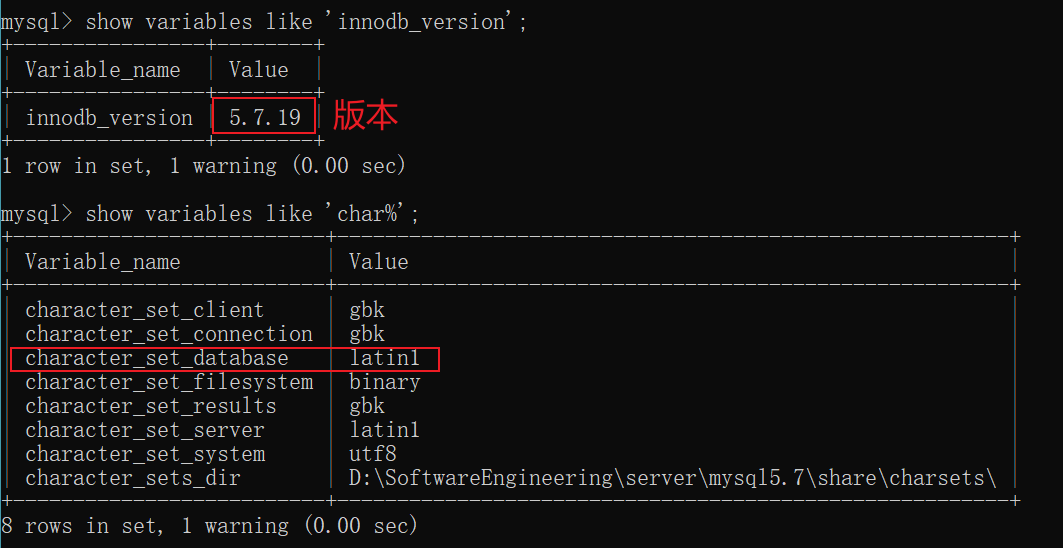
3.3 GBK字符集
但是随着计算机的普及,像我们中国人也开始使用字符集。但对于我们中国人而言,采用 ASCII 进行字符存储肯定是不够的,因为我们的中文字符实在是太多了,不是一个字节能表示的。
GBK编码(Chinese Internal Code Specification)是中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。GBK编码能够用来同时表示繁体字和简体字,而GB2312只 能表示简体字,GBK是兼容gb2312编码的。GBK是 汉字编码字符集,包含了2万多个汉字等字符,GBK中一个中文字符编码成两个字节的形式存储,一个英文字符编码成一个字节的形式。- 注意:GBK兼容了ASCII字符集。
📝 使用GBK编码将字符存储到计算机:“我a你”
# 因为汉字占两个字节,英文占一个字节,因此编码方式为: # 我 a 你 xxxxxxxx xxxxxxxx | 0xxxxxxx | xxxxxxxx xxxxxxxx- 1
- 2
- 3
❓ 一个问题的思考:那计算机在解码的时候是如何区分要一起解析两个字节还是只解析一个字节呢
📍 GBK规定:汉字的第一个字节的第一位必须是 1
#那么以GBK编码,在计算机存储形式为: 1xxxxxxx xxxxxxxx | 0xxxxxxx | 1xxxxxxx xxxxxxxx- 1
- 2
有了这个规定:
- 计算机如果判断出第一位是
1,就认为是汉字字符,则会一次性解析两个字节(16位),即把它后面那一个字节也连起来作为整体进行解码 - 计算机如果判断出第一位是
0,就会当成ASCII字符集进行处理,则会只解析一个字节
3.4 Unicode字符集(统一码,也叫万国码)
介绍了我们中国可以针对自己国家的字符设置字符集并规定编码方式,那其他国家也是可以针对自己国家的字符进行字符集设置与规定编码方式。那这样,就有了很多种的字符集编码:巴基斯坦码、韩文码、岛国码、迪拜码等等。
有了这么多种字符集编码,当计算机在世界普及与信息互传的时候,就会带来很多的问题:比如使用韩文码进行编码,然后发给了迪拜,迪拜使用了迪拜码进行解码,就肯定会出现
乱码的问题。这时候就需要一个统一的字符集与编码方式,每个国家都遵循这个字符集与编码规范,信息就可以在世界互传了。
📍 Unicode字符集是统一码联盟为了统一所有语言的文字和符号而制定的编码字符集。编码方式包括:
UTF-8、UTF-16和UTF-32。3.4.1 UTF-16编码
UTF-16是变长编码方式,每个字符编码为2或4字节,是Unicode最早的编码方式。
在Java语言里,它使用的是Unicode字符集和UTF-16编码。也就是说Java能表示出全部Unicode字符集中规定了的字符,然后在内存中存储时,通过UTF-16中定义的规则将其转换成字节。例如“a”这个字母,在Unicode中规定要用十六进制下的
0x61来表示,但是实际存储的时候可不是直接存的0x61,而是查表,发现应该是0x0061。所以,Java中一个char类型在内存中占用两个字节,因为他们存储的是UTF-16编码后的字节,而UTF-16则是把所有Unicode字符都使用固定了两字节的方式进行编码。3.4.2 UTF-32编码
四个字节表示一个字符,确实做到了有容乃大,可以包含全世界所有的字符。但是这套编码方案并不被全世界所接纳,因为大家认为这种编码方式方式太过于
奢侈,一个字符要用四个字符来表示太占存储空间了,通讯效率会变低。- 比如使用
ASCII编码方式,原来一个字符只需要一个字节即可。而使用Unicode字符集下的UTF-32编码方式,是需要用四个字节的,这就意味着需要白白浪费三个字节,则相当于需要的存储空间是相当于ASCII编码用到的存储空间的三倍! - 比如使用
GBK编码方式,原来一个中文字符只需要两个字节。而使用UTF-32编码方式就会浪费多两个字节,这样存储空间相较于GBK的会多出一倍。
因此,Unicode字符集虽然是很好的思想,但这种UTF-32编码方案并没有被世界接纳,在很多业务场景下我们也不会使用到这套编码方案。
3.4.3 UTF-8编码
它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节(2字节)储存,但UTF-16却无法兼容于ASCII编码。
由于UTF-32编码方案的弊端太过突出,于是国际组织又为Unicode字符集设计了一套改变字符苍生和世界的编码方案 ——
UTF-8编码方案- 是Unicode字符集的一种编码方案,采取
可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节 - 英文字符、数字等只占1个字节(兼容标准ASCII编码),汉字字符占用3个字节。
📝 使用UTF-8编码将字符存储到计算机:“a我m”
# 因为汉字占三个字节,英文占一个字节,因此编码方式为: # a 我 m 0xxxxxxx | xxxxxxxx xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx- 1
- 2
- 3
❓ 一个问题的思考:那计算机在解码的时候是如何区分要一起解析1个字节,或2个字节,3个字节,4个字节呢?
我们先来看下这三个字符的码点值对应的二进制数:
字符 码点值 二进制数 a 97 01100001 我 25105 110 001000 010001 m 109 01101101 🚩 UTF-8编码方式(二进制):
0xxxxxxx (ASCII码) #使用一个字节存储 110xxxxx 10xxxxxx #使用两个字节存储 1110xxxx 10xxxxxx 10xxxxxx #使用三个字节存储 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx #使用四个字节存储- 1
- 2
- 3
- 4
计算机通过
码点值的区间范围判断出应使用UTF-8编码方式的多少字节进行存储,比如知道字符a的码点值为97,因此计算机知道了应使用一个字节存储。又比如知道了字符我的码点值为25105,在三个字节存储对应的码点值区间范围,所以计算机会使用三个字节进行对字符我的存储。所以,使用UTF-8编码对字符
a我m的底层存储方式为:将码值对应的二进制数从后往前代替上面对不同字符的字节存储方式中的
xa -> 码值:97 -> 二进制数: 01100001 存储结构: 0xxxxxxx 实际存储: 01100001 我 -> 码值:25105 -> 二进制数: 110 001000 010001 存储结构: 1110xxxx 10xxxxxx 10xxxxxx 位置代替: 0110 001000 010001 实际存储: 11100110 10001000 10010001 m -> 码值:109 -> 二进制数:01101101 存储结构: 0xxxxxxx 实际存储: 01101101 #因此最终存储方式: a 我 m 01100001 11100110 10001000 10010001 01101101- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
❓ 编码的问题解决了,那计算机解码的时候又是如何识别的呢?
其实很简单,我们再看一下对不同字符的字节存储方式:
0xxxxxxx (ASCII码) #使用一个字节存储 110xxxxx 10xxxxxx #使用两个字节存储 1110xxxx 10xxxxxx 10xxxxxx #使用三个字节存储 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx #使用四个字节存储- 1
- 2
- 3
- 4
📍 计算机在解析二进制数据时,看前几位(bit)的数值:
- 发现第一位为0,则说明计算机在编码的时候是将一个字符用用一个字节进行存储,因此只需要解析一个字节即可。比如将
01100001先转成十进制的码点值为97,再根据 Unicode字符集得到该码值对应的字符为a。 - 发现第一位不为0
- 如果前几位是
110,说明计算机在编码的时候是将一个字符用用两个字节进行存储,因此需要整体解析两个字节,舍去前缀一个110和一个10,其它位从左至右拼接组成二进制数。 - 如果前几位是
1110,说明计算机在编码的时候是将一个字符用用三个字节进行存储,因此需要整体解析三个字节,舍去前缀一个1110和两个10,其它位从左至右拼接组成二进制数。比如对于字符我的底层存储编码11100110 10001000 10010001,去掉前缀一个1110和两个10后,由其它位组成二进制数0110 001000 010001,将该二进制转成十进制码点值为25105,再根据Unicode字符集得到该码值对应的字符为我,就可以将该字符显示到计算机屏幕了。 - 如果前几位是
11110,说明计算机在编码的时候是将一个字符用用四个字节进行存储,因此需要整体解析四个字节,舍去前缀一个11110和三个10,其它位从左至右拼接组成二进制数。
- 如果前几位是
注意:技术人员在开发时都应该使用UTF-8编码
3.4.4 Unicode的三种编码比较
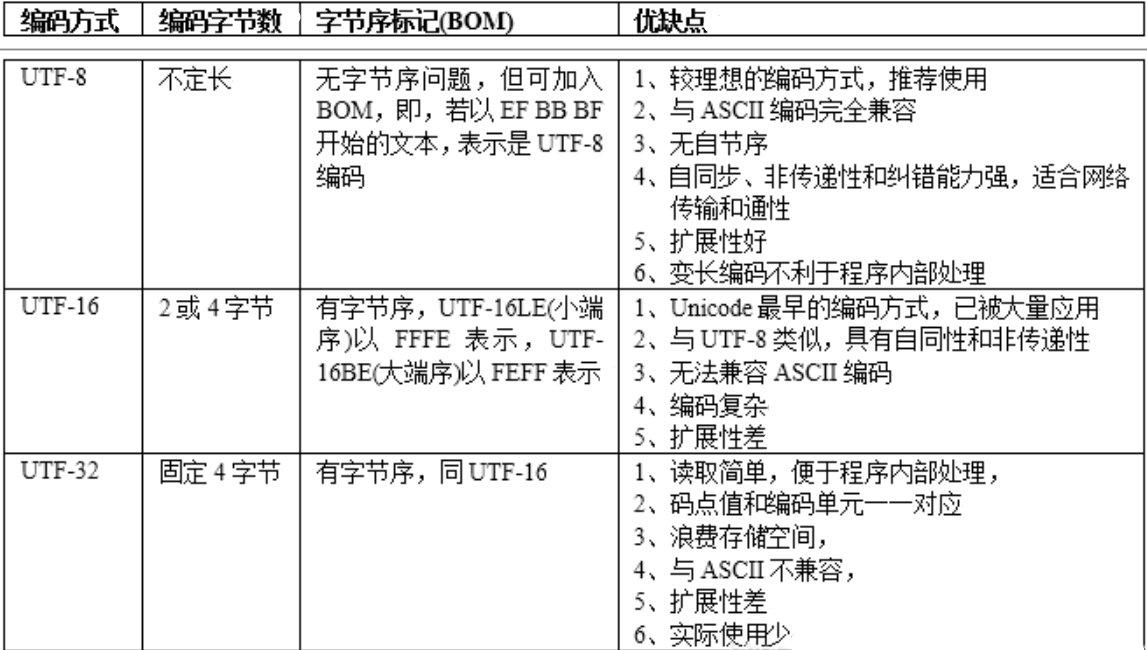
3.5 总结概述
- ASCIl字符集:只有英文、数字、符号等,占1个字节。
- GBK字符集:汉字占2个字节,英文、数字占1个字节。
- UTF-8字符集:汉字占3个字节,英文、数字占1个字节。
✏️ 注意:
- 字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码
- 英文,数字一般不会乱码,因为很多字符集都兼容了ASCII编码。
4.乱码问题
编码和解码时用了不同或者不兼容的字符集。
对应到真实生活中:就好比是一个英国人为了表示
祝福在纸上写了bless(编码过程)。而一个法国人拿到了这张纸,由于在法语中bless表示受伤的意思,所以认为他想表达的是受伤(解码过程)。这个就是一个现实生活中的乱码情况。在计算机中也是一样:一个用UTF-8编码后的字符,用GBK去解码。由于两个字符集的字库表不一样,同一个汉字在两个字符表的位置也不同,最终就会出现乱码。
我们在这里举一个例子:
Unicode字符集有一个特殊的替换符号
�,专门用于表示无法识别或展示的字符。有些编辑器,会在以UTF-8方式进行解码时把无法识别或展示的字符自动替换为�,用于提示用户编码或解码有问题。#对于字符:a我m #使用 GBK 进行编码,字符与底层存储二进制数的对应关系为: a --> 01100001 我 --> 11001110 11010010 m --> 01101101 #则计算机存储时的二进制数据为: a 我 m 01100001 11001110 11010010 01101101 #编码后,我们用 UTF-8 进行解码 1. 首先判断出第一位是0,因此只解析一个字节: 01100001 ,转为码值参照字符集对应关系就得到了字符 a 2. 再解析第二个字节的前几位,发现第一位是1并且前几位是 110,则认为可能是使用两个字节存储,再看第三个字节前几位,发现并不是 10,所以就发生了无法按照两个字节进行的问题,那么计算机就视第二个字节为乱码,显示的字符为 � 3. 由于解析了第二个字节为乱码,所以又看第三个字节。发现第一位是1并且前几位是 110,则认为可能是使用两个字节存储,再看第四个字节前几位,发现并不是 10,所以就发生了无法按照两个字节进行的问题,那么计算机就视第三个字节为乱码,显示的字符为 � 4. 由于解析了第三个字节为乱码,所以又看第四个字节。判断出第一位是0,因此只解析一个字节: 01101101 ,转为码值参照字符集对应关系就得到了字符 m 因此,最终的字符解码显示结果为 a��m- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5.使用Java代码对字符进行编码与解码
5.1 Java代码完成对字符的编码
String提供了如下方法 返回值 说明 getBytes( ) byte[ ] 使用 平台的默认字符集将该String编码为一系列字节,将结果存储到新的字节数组中getBytes(String charsetName) byte[ ] 使用 指定的字符集将该String编码为一系列字节,将结果存储到新的字节数组中5.2 Java代码完成对字符的解码
String提供了如下方法(构造器方法) 说明 String(byte[] bytes) 通过使用 平台的默认字符集解码指定的字节数组来构造新的StringString(byte[] bytes,String charsetName) 通过 指定的字符集解码指定的字节数组来构造新的String5.3 代码测试
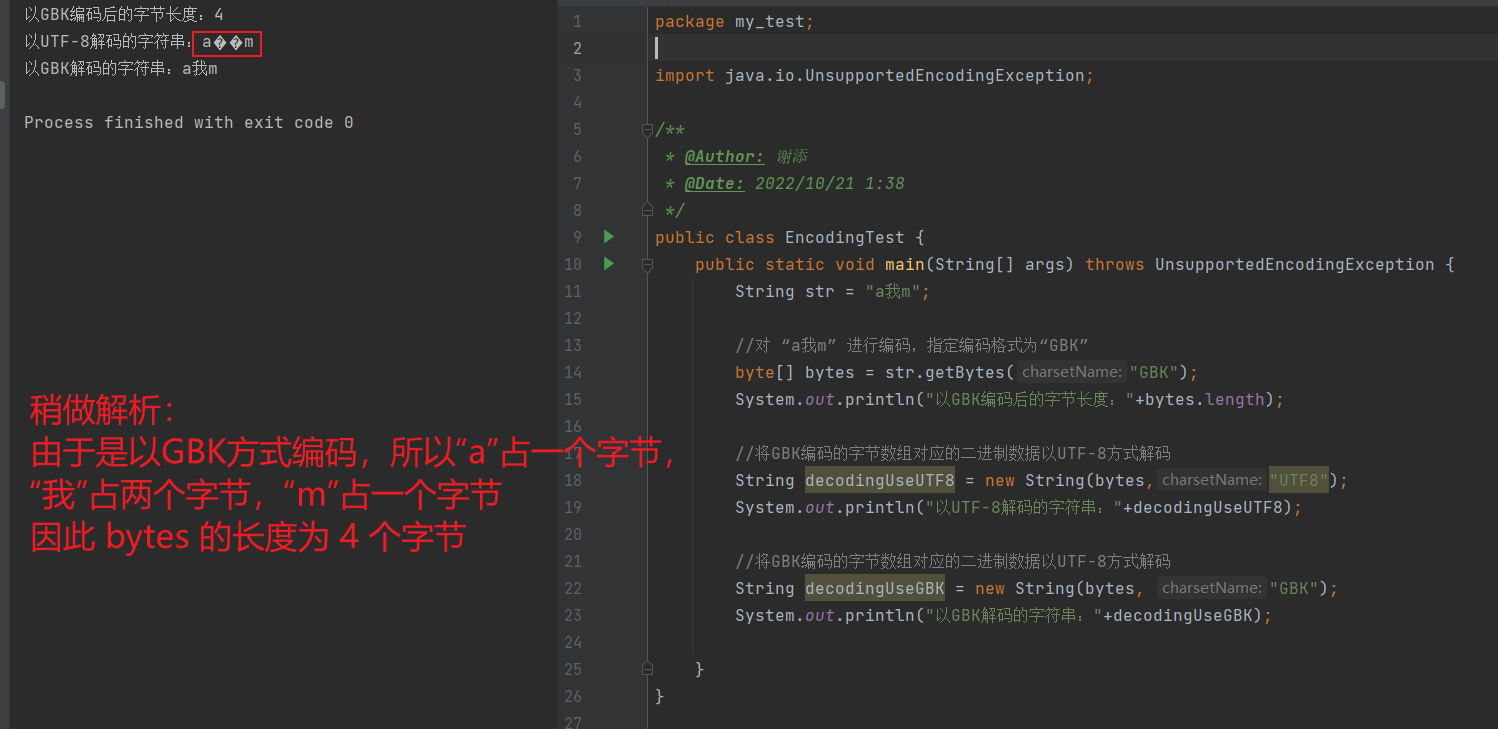
public class EncodingTest { public static void main(String[] args) throws UnsupportedEncodingException { String str = "a我m"; //对 “a我m” 进行编码,指定编码格式为“GBK” byte[] bytes = str.getBytes("GBK"); System.out.println("以GBK编码后的字节长度:"+bytes.length); //将GBK编码的字节数组对应的二进制数据以UTF-8方式解码 String decodingUseUTF8 = new String(bytes,"UTF8"); System.out.println("以UTF-8解码的字符串:"+decodingUseUTF8); //将GBK编码的字节数组对应的二进制数据以UTF-8方式解码 String decodingUseGBK = new String(bytes, "GBK"); System.out.println("以GBK解码的字符串:"+decodingUseGBK); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6.补充:乱码神兽锟斤拷的由来
6.1 锟斤拷的介绍
锟斤拷是一个常见的中华乱码,一般在UTF8和中文编码像GBK转换过程中产生。
6.2 锟斤拷是如何产生的
当我们出现乱码 �� 后,再以
UTF-8的方式进行编码存储到计算机底层。在Unicode字符集中,一个“�”是用三个字节进行存储的,底层二进制数据为:11101111 10111111 10111101。
因此两个 � 存储在计算机中就是 11101111 10111111 10111101 11101111 10111111 10111101
以UTF-8编码后,如果我们以 GBK 方式解码,对于那六个字节的字符集 11101111 10111111 10111101 11101111 10111111 10111101,由于一个汉字对应两个字节:
- 存储在计算机里的 11101111 10111111 转成码点值对应表中的 锟
- 存储在计算机里的 10111101 11101111 转成码点值对应表中的 斤
- 存储在计算机里的 10111111 10111101 转成码点值对应表中的 拷
所以,当使用
UTF-8编码��后,再以GBK解码,就会生成字符串 锟斤拷6.3 Java代码模拟场景
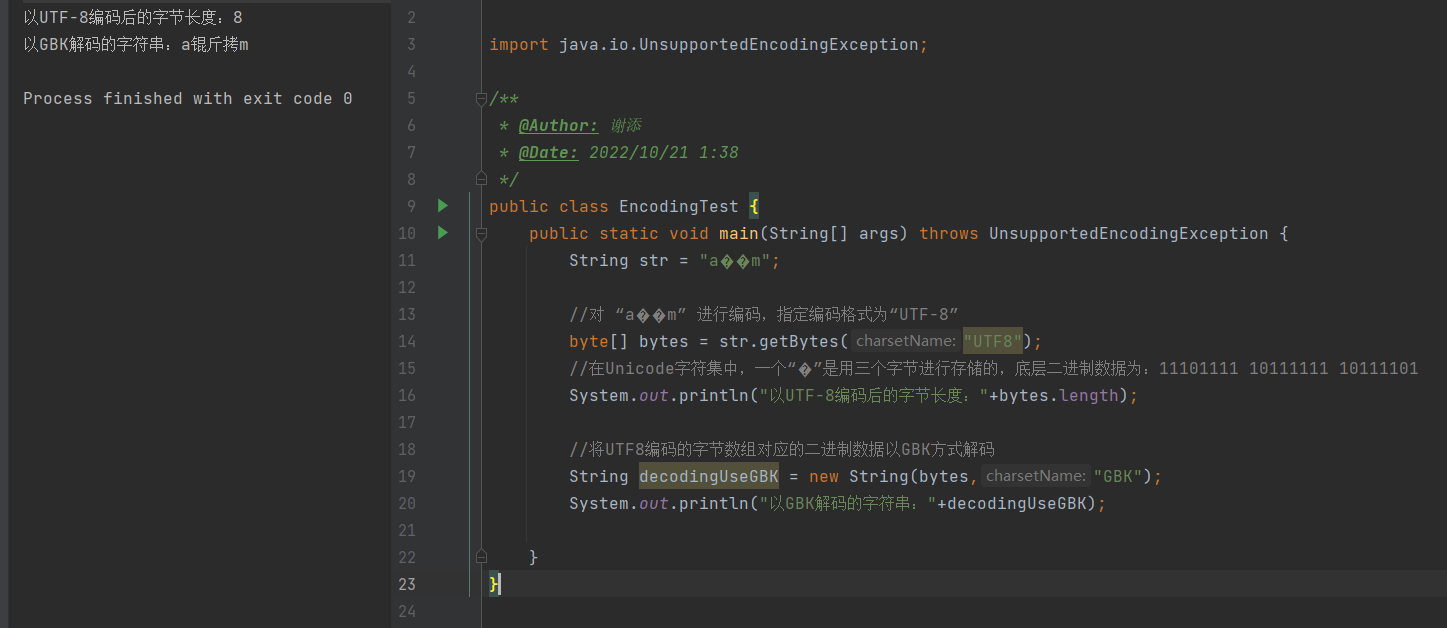
public class EncodingTest { public static void main(String[] args) throws UnsupportedEncodingException { String str = "a��m"; //对 “a��m” 进行编码,指定编码格式为“UTF-8” byte[] bytes = str.getBytes("UTF8"); //在Unicode字符集中,一个“�”是用三个字节进行存储的,底层二进制数据为:11101111 10111111 10111101 System.out.println("以UTF-8编码后的字节长度:"+bytes.length); //将UTF8编码的字节数组对应的二进制数据以GBK方式解码 String decodingUseGBK = new String(bytes,"GBK"); System.out.println("以GBK解码的字符串:"+decodingUseGBK); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
相关阅读:
软件界面常见的布局窗口基本布局和名字
IntelliJ IDEA禁止某些文件夹indexing
【从零开始的Java开发】1-6-4 Java输入输出流:File类、绝对路径和相对路径、字节流、缓冲流、字符流、对象序列化
NX二次开发-UFUN输入一个与矩阵关联的对象,得到矩阵的id UF_CSYS_ask_matrix_of_object
互联网摸鱼日报(2022-11-05)
HEAD: HEtero-Assists Distillation for Heterogeneous Object Detectors
UE5 C++ 使用TimeLine时间轴实现开关门
【python】基础语法(三)--异常、模块、包
【Python 千题 —— 基础篇】句子首字母要大写
忘记过滤.idea文件导致maven管理错误一系列操作...
- 原文地址:https://blog.csdn.net/qq_62982856/article/details/127440216
